「関数でデータを整理したい」「関数でカテゴリーごとに仕分けたい」
だけど元データはとてもシンプルで、カテゴリーごとに使っている行数も違う・・・
そしてそのデータは日々変化する。
そんなデータを私がどう分割して整理したかを備忘録としてまとめます。
・手始めに元データの特徴をみつける
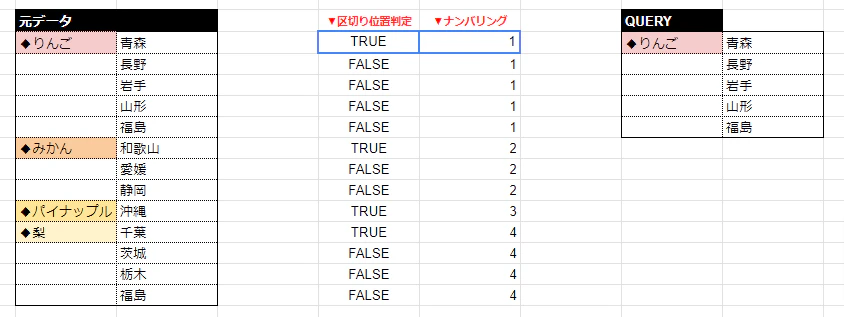
今回扱ったデータは以下のように一列に隙間なく情報が羅列されたものでした。
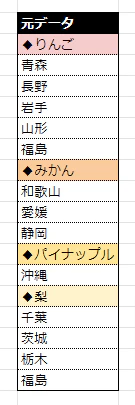
このデータを「りんご」「みかん」「パイナップル」…と品種のカテゴリーごとに分割を目指します。
そのためにはまず、その行に書かれたテキストが「品種かそうでないか」を見分ける仕組みを用意しなければなりません。
幸いにも今回のデータには「品種名の前には必ず◆記号が入力されている」という特徴がありました。
「◆りんご」「◆みかん」「◆パイナップル」…
ではこれを判別できる関数を用意しましょう。
・特徴を条件に変換する
私が用意したのは以下の関数です。
=ARRAYFORMULA(REGEXMATCH(元データの範囲,"^◆"))
REGEXMATCH関数という「正規表現で指定した条件に一致するテキストを検索する関数」を使用し、「^」=先頭に、「◆」があるテキストを検索しました。
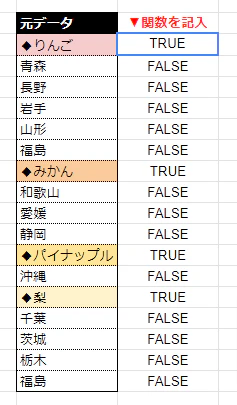
この関数を元データの右隣に書いてみます。
すると、品種の書かれた行は「TRUE」そうでない行は「FALSE」となりました。判別の成功です。
・条件に一致した行で区切られる数列を作る
ここからが少し特殊な考え方になります。
数学的な関数を使い、条件に一致したかどうかの判定に影響を受ける数列を作成します。
使用するのは「SCAN関数」です。
簡潔に「どんな事ができる関数なのか」を解説すると。
・任意の計算式を自分で設定できる。
・その計算式で、指定した範囲を上から順番に計算する事ができる。
と言った関数です。
そして、
・1つの計算を終えて次の計算に移る時、1つ前に行った計算結果を引数として参照する。
という特徴を持ちます。
例を挙げます。
数字の「1~5」が縦に並んだ表があったとします。
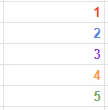
もし、この数列を上から順番に足していきたいとなった時、以下のように関数を書きます。
=SCAN(初期値,範囲,LAMBDA(a,b,a+b))
初期値には「0」、範囲には「1~5が並んだ列の範囲」を指定します。
すると、
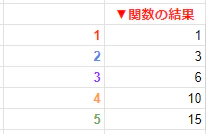
1~5までの数字を上から順番に足していった数が出力されました。いわゆる 三角数 です。
関数の内部で何が行われたかを右隣の列に書くとこのような形です。
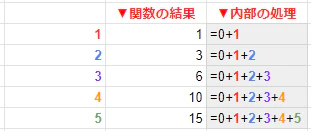
「0」という初期値に対し、1行目の1を足した値が関数の戻り値である1行目の「1」です。
次の2行目では1行目で行った計算の結果に2行目の2を足した値が関数の戻り値になり「3」
次の3行目では2行目で行った計算の結果に3行目の3を足した値が関数の戻り値になり「6」
これが先程書いた
・1つの計算を終えて次の計算に移る時、1つ前に行った計算結果を引数として参照する。
という本関数の特徴なのです。
この関数のより正確な解説はGoogle スプレッドシートの関数リストや他のサイトが詳しいかと思います。
SCAN関数
・この数式をどのように応用するのか
先程行った元データへの処理を改めて見てみましょう。
品種の書かれた行は「TRUE」そうでない行は「FALSE」に判別されています。
これと先に書いた数式がどう関わってくるのか。
普段から関数を書かれている方はもしかしたらピンと来るかもしれませんが、
「TRUE」は「1」であり、
「FALSE」は「0」なのです。
スプレッドシートではこの変換をきちんと自動で行ってくれます。
例えば「TRUE」と書かれたセルに対し数字を足したり掛けたりすると、ちゃんと1として扱った結果が返ってきます。
では、この「TRUE」と「FALSE」の並んだ列に対し、先程と同じ上から順番に数を足していくSCAN関数を適用してみます。
=SCAN(初期値,範囲,LAMBDA(a,b,a+b))
//初期値には0、範囲には「TRUE」と「FALSE」の並んだ列を指定
するとどうでしょう
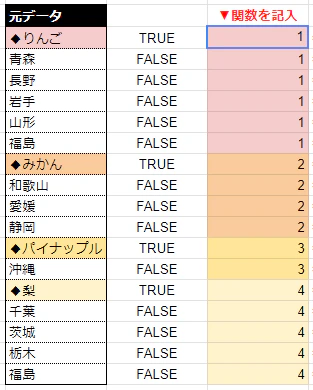
なんと「TRUEを通過したときのみ+1加算される数列」が出力されました。
そして結果としてこれが「品種名でデータを区切る」という要件を満たすことにもなります。
なぜなら、この戻り値は品種名の切り替わりに応じて数字の増えるナンバリングの役割を果たすからです。
なぜこのように「TRUEを通過したときのみ+1加算される数列」が生み出されるかは、
以下画像に書いた「内部の処理」の数式を見てみると分かりやすいです。
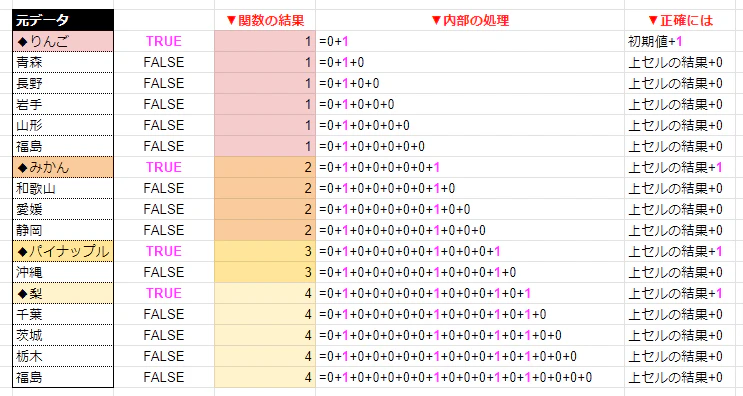
1つ上のセルの値を順番に足していくため、0であるFALSEでは増えず、1であるTRUEで増えるというのが視覚的に分かりやすくなったのではないでしょうか。
※正確には「1つ上のセルの計算結果を順番に足していく」ため、上記の画像に書いたような行を進むごとに長くなる計算式が実際に生成されるわけではないため、本関数の使用でスプレッドシートの動作が重くなるような心配は一旦ありません。
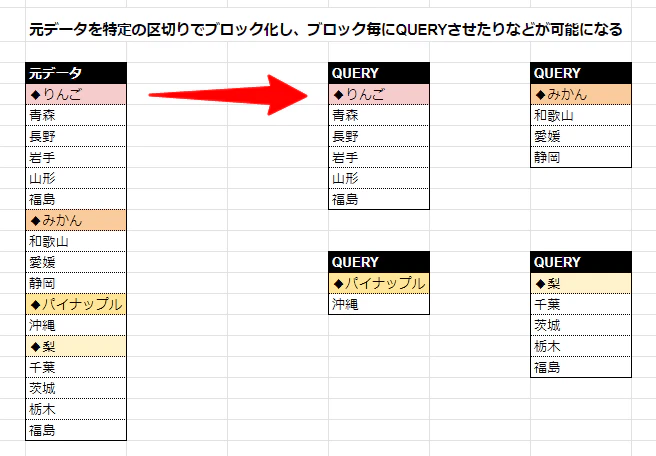
ここまでお膳立てをしてしまえば後はそう苦労もありません。
もし品種「みかん」でカテゴリーされたデータを抽出したいとなった場合、特別な作業は必要なく、QUERY関数などで隣接するセルの値が「2」である行を条件として指定すれば、そのデータが呼び出せることでしょう。

このナンバリングさえ活用できれば後のデータの処理は個々のお好みでかなり自由に取り扱えるかと思います。
レイアウトも思いのままに行えるでしょう。
本件は以上となります。
今回は備忘録的な記事なので短いですが、最後に私がこの関数を使用して行った処理の例を記載しておきます。
細かなカスタムはそれぞれの実務において千差万別かと思いますが一助になれば幸いです。
最後までお付き合いいただき、ありがとうございます。
あとがき:使用例
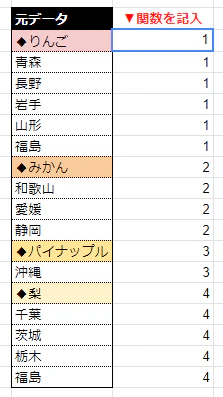
1.「TRUE / FALSE」の判定をSCAN関数内に入れ込んでしまうのも楽。
=ARRAYFORMULA(SCAN(0,REGEXMATCH(元データの範囲,"^◆"),LAMBDA(a,b,a+b)))
2.SCAN関数で行ったナンバリングをデータ化しておくと楽。
サクッとFILTERなりで品種名だけを別の場所に抽出し、隣に連番を振ればカテゴリーのID表になる。
=ARRAYFORMULA(FILTER(元データの範囲,REGEXMATCH(元データの範囲,"^◆")))
&
=SEQUENCE(COUNTA(↑の関数の列範囲))

3.重要なのは区切り位置の判定をどう行うかであり、
それさえ突破できればどのような形の元データにも対応できると期待しています。