これはfairseq+sentencepieceで翻訳モデルを作成する実験中の備忘録です。
環境はNVIDIA Jetson AGX Xavier 16GBを使用しています。
先日OpenNMTを試したのですがハイパーパラメータを設定すると途端にうまく動きません。
どうも実装側に問題があるようで、諦めてfairseqを触ることにしました。
fairseqもバージョンによっては動かないことがあり、0.12.2ではトレーニングはできるがジェネレートに失敗する。
0.10.2は動かない。0.10.0はトレーニングとジェネレートの両方で動きました。
これはPythonのバージョンを調整するなりで何とかなりそうですが一旦動くバージョンもありましたので0.10.0を触っていくことにします。
現在は勉強を兼ねて幾らか大きめの学習データでトレーニングを試しています。
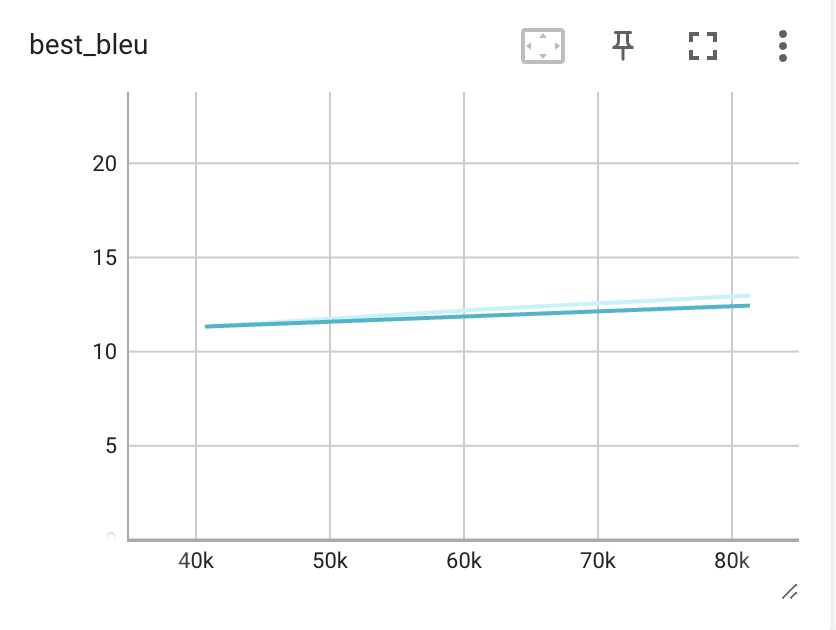
ちなみに現在の進捗状況ですが、1エポックのトレーニングに3時間かかるので、まだ4エポックしか進んでいません。
lossを見る限り学習はしているようです。

Xavierは30Wと低消費電力ですので、高効率のシーリングライトを点けたままと変わりませんので気にせずぶん回せるところがメリットです。
それでも100エポック回すと1週間かぁ…
参照
参考にした手順
利用したデータ
「無償配布の日本語・英語対訳コーパスのデータを綺麗にする」のコードを流用して学習データを作成しました。
出力結果として、mixed_1.3M_ja.txtと、mixed_1.3M_en.txtの学習データができます。
適当にheadコマンドでデータを見ると、なんだか微妙な訳が出てきました。
綺麗な学習データを用意するにはまだまだ頑張る必要がありそうです。
$ head mixed_1.3M_ja.txt
農場、又はビジネス、又は銀行が再び支払い能力があるようになることができるまで、状況は無視された、そして、全てはほっとため息をついた。
先生とグレーと僕で一組、大地主さんとハンターとジョイスでもう一組。みんな疲れはててはいたけれど、2人がたきぎ集めに、他の2人がレッドルースの墓を掘りに行かされ、先生はコックを命ぜられ、
すっぽんで降りてきた棺は、ここで、空の棺と、すり替えられ
プッシュアップはしばしばタイプから見落とされ、男性のための多くのトレーニングプログラムに含まれる価値のない演習と考えられています。
...
The situation was ignored, until the farm or business or bank could become solvent again, and all breathe a sigh of relief.
The doctor and Gray and I for one; the squire, Hunter, and Joyce upon the other. Tired though we all were, two were sent out for firewood; two more were set to dig a grave for Redruth; the doctor was named cook;
the coffin brought down via the trap is switched with an empty one here.
Push ups are often overlooked from the type and are considered an unworthy exercise for inclusion in many training programs for men.
SentencePieceのモデルを作成する
Pythonで実行するととても時間がかかります。
import sentencepiece as spm
spm.SentencePieceTrainer.Train(
input=["mixed_1.3M_en.txt","mixed_1.3M_ja.txt"],
vocab_size=16000,
character_coverage=1,
num_threads=8,
max_sentence_length=256,
model_type="unigram",
model_prefix="spm",
bos_id=0,
pad_id=1,
eos_id=2,
unk_id=3,
train_extremely_large_corpus=True
)
メモリに余裕があるならコマンドラインから処理を実行した方が早いです。
単体で16GBメモリを消費するので要注意です。
% git clone https://github.com/google/sentencepiece.git -b v0.2.0
% cd sentencepiece
% mkdir build
% cd build
% cmake ..
% make -j $(nproc)
% sudo make install
% sudo ldconfig -v
$ sentencepiece/build/src/spm_train \
--input="mixed_1.3M_en.txt,mixed_1.3M_ja.txt" \
--vocab_size=16000 \
--character_coverage=1 \
--num_threads=8 \
--max_sentence_length=256 \
--model_prefix="spm" \
--model_type=unigram \
--bos_id=0 --pad_id=1 --eos_id=2 --unk_id=3
実行すると、spm.vocabとspm.modelを出力しました。
Fairseq formatの辞書を作成する
spm.vocabからFairseqの辞書を作成します。
$ cut -f1 spm.vocab | tail -n +5 | sed "s/$/ 100/g" > dict.txt
サブワードを作成
全てのデータセット、validation,testを含むデータの全てを使ってサブワードを作成します。
$ sentencepiece/build/src/spm_encode --model="spm.model" --output_format=piece < "mixed_1.3M_en.txt" > train.en-ja.spm.en
$ sentencepiece/build/src/spm_encode --model="spm.model" --output_format=piece < "mixed_1.3M_ja.txt" > train.en-ja.spm.ja
データの分割
トレーニング、バリデーション、テストデータに分割してdataフォルダに保存します。
分割するデータサイズもどれくらいが良いのか悩みますね。
import os
with open("train.en-ja.spm.en", "r", encoding="utf-8") as f:
input_en = f.readlines()
with open("train.en-ja.spm.ja", "r", encoding="utf-8") as f:
input_ja = f.readlines()
train_en = input_en[:4700000]
val_en = input_en[4700000:4770000]
test_en = input_en[4770000:]
train_ja = input_ja[:4700000]
val_ja = input_ja[4700000:4770000]
test_ja = input_ja[4770000:]
os.makedirs("data", exist_ok=True)
with open("data/train.en-ja.spm.en", 'w') as f:
f.writelines(train_en)
with open("data/train.en-ja.spm.ja", 'w') as f:
f.writelines(train_ja)
with open("data/valid.en-ja.spm.en", 'w') as f:
f.writelines(val_en)
with open("data/valid.en-ja.spm.ja", 'w') as f:
f.writelines(val_ja)
with open("data/test.en-ja.spm.en", 'w') as f:
f.writelines(test_en)
with open("data/test.en-ja.spm.ja", 'w') as f:
f.writelines(test_ja)
前処理の実行
dataに保存した学習データを読み込んでbinに保存します。
$ fairseq-preprocess \
--trainpref "data/train.en-ja.spm" \
--validpref "data/valid.en-ja.spm" \
--testpref "data/test.en-ja.spm" \
--destdir "bin" \
--joined-dictionary \
--srcdict "dict.txt"\
--source-lang "en" \
--target-lang "ja" \
--bpe sentencepiece \
--workers 8
トレーニング
時間がかかりそうなので元のコードからレイヤーを減らしました。
デフォルトのレイヤーの6からencoder-layers 4とdecoder-layers 2にしてます。
また、進捗がわからないので--log-format tqdmに変更しました。
$ fairseq-train \
"bin" \
--fp16 \
--encoder-layers 4 --decoder-layers 2 \
--arch transformer_wmt_en_de \
--share-all-embeddings \
--optimizer adam \
--adam-betas '(0.9, 0.98)' \
--clip-norm 0.0 \
--lr 5e-4 \
--lr-scheduler inverse_sqrt \
--warmup-updates 4000 \
--warmup-init-lr 1e-07 \
--dropout 0.1 \
--weight-decay 0.0 \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.1 \
--save-dir "model_output" \
--log-format tqdm \
--log-interval 100 \
--max-tokens 8000 \
--max-epoch 100 \
--patience 5 \
--seed 3921 \
--eval-bleu \
--eval-bleu-args '{"beam": 5, "max_len_a": 1.2, "max_len_b": 10}' \
--eval-bleu-detok space \
--eval-bleu-remove-bpe sentencepiece \
--eval-bleu-print-samples \
--best-checkpoint-metric bleu \
--maximize-best-checkpoint-metric \
--tensorboard-logdir runs
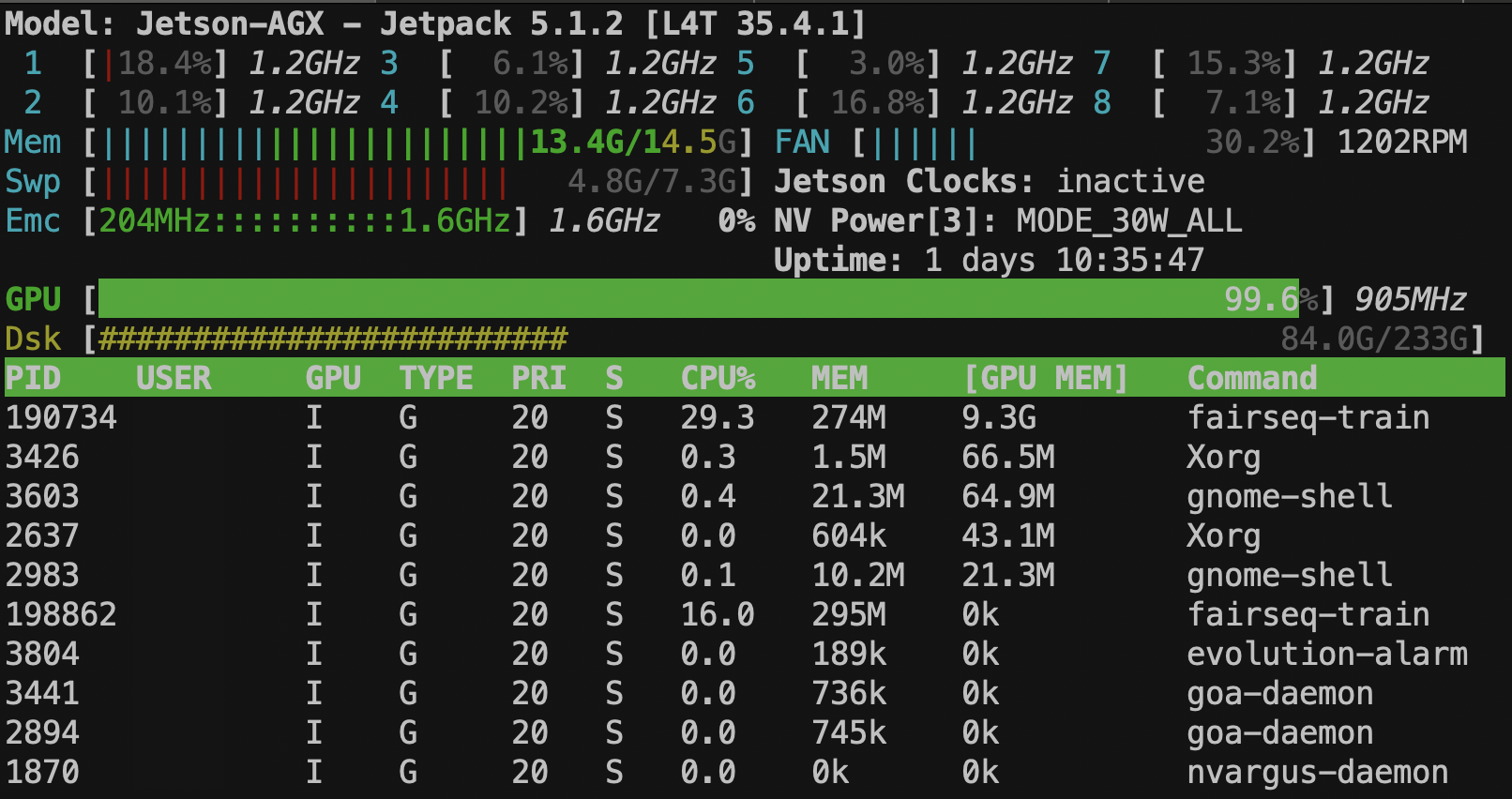
トレーニングを実行するとXavierのメモリがカツカツです。
CPUとGPUはメモリが共有というものありますが、GPUだけで10GB近く消費しています。
トレーニング結果の確認
$ fairseq-generate data \
--path model_output/checkpoint_best.pt \
--batch-size 128 --beam 5 | tee output.txt
$ grep "^H" output.txt | LC_ALL=C sort -V | cut -f3-
Pythonで結果を出力
何故かeval_bleu_detok_argsにNoneが入っていてエラーになるのでパラメータを設定。
from logging import getLogger, WARNING
from fairseq.models.transformer import TransformerModel
import warnings
getLogger('fairseq').setLevel(WARNING)
warnings.simplefilter('ignore')
en2ja_model = TransformerModel.from_pretrained(
'checkpoints',
checkpoint_file='checkpoint_best.pt',
data_name_or_path='bin',
bpe='sentencepiece',
sentencepiece_model="tmp/spm.model",
eval_bleu_detok_args='{}',
)
print(en2ja_model.translate('Hello World'))
Pythonの実行に必要なファイル構成の確認
en2ja_model = TransformerModel.from_pretrained(
'models','checkpoint_best.pt',
data_name_or_path='models',
bpe='sentencepiece',
sentencepiece_model="models/spm.model",
eval_bleu_detok_args='{}',
)
models
├── checkpoint_best.pt
├── dict.en.txt
├── dict.ja.txt
└── spm.model
終わりに
以上でトレーニングは動くようになりました。
学習データをいい感じに綺麗にしてそれっぽい出力が出るところまで頑張ってみたいと思います。
Tips
GiNZA
ja_ginzaで形態素解析をすることにしました。
ja_ginza_bert_large、ja_ginza_electraは重たくて諦めました。
Xavierは$ pip install spacy[cuda11x]でGPU動いたのだけどとても遅いです。
M1 Macだとかなり高速に動きます。
あと、jumanppはマルチスレッド化が手間で普通に動かすと遅いので諦めました。
ginzaはマルチスレッドで動いてくれて早いことは早いのですが、控えめなリソースで動きます。
もっとリソース消費していいので「はよっ」と思います。
nymwa/light_enja2
fairseqの前処理から揃っていて便利。
en + \t + jaのデータ放り込めばいい感じに綺麗なデータ作ってくれます。
フィルタのlengthの範囲は狭いので広げて使っています。
Sentencepiece
Sentencepieceのモデルはunigramよりもbpeのが良さげ。