業務で姿勢推定の利用を考えたときに精度の影響を調べるタスクが出ました。
姿勢推定でよく使われている指標には、COCO test-devだとmAP、MPIIのPCKHが指標としてよく用いられています。
MPIIはご存知の方も多いですがもう何年も前からPCKHが90%を超えて飽和状態です。
COCOについては2016年のCOCO Challengeで60.5から2017年には72.1と急速に伸びた後はゆっくり上昇しており、2022年12月の現在はViTPoseが81.1でSOTA(State Of The Art)となっている状況です。
公開されている数値だけではモバイル用にコンバートした時の精度(数値の変化、基本的に下がる)を測ることができません。
MPIIは用途によっては重要ですが、今回はPCKHはそこまで重要視していないこともあり、お手軽に試せるCOCO val2017を使って評価していくことにしました。
この記事を読む前に必要そうな知識
この記事では主に、OpenPose、SimpleBaseline、ViTPoseの三つについて書きます。
OpenPoseはボトムアップ方式、SimpleBaseline、ViTPoseはトップダウン方式です。
両者の違いは表を参照ください。
| 方式 | トップダウン | ボトムアップ |
|---|---|---|
| 手法 | 予め人の位置を予測したうえで姿勢を求める | 関節位置から姿勢を求める |
| 特性 | ひとりずつ切り出して処理する都合、小さい人物でも精度が良い。 人数が多いと処理回数が増えるため遅くなる |
全体を捉える都合トップダウンより精度が低い傾向 複数人を同時に処理するのに向いている。 |
手始めにOpenPoseをVal2017で評価してみた
OpenPoseではCOCO val setを評価するコードを提供していません。
そこでOpenPoseのPythonAPIでせっせと作成しまして、body_25をcocoのキーポイントに調整、またcocoで提供しているモデルを評価しました。
下記はValTestの結果
COCO
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.343
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.591
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.338
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.396
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.370
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.544
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.766
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.572
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.442
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.687
0.34293313729687536
BODY25
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.377
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.625
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.386
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.440
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.398
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.575
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.789
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.612
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.482
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.708
0.3769772571475063
あれ?何か失敗した?
COCO test-devではOpenPoseの2018年(v1.5系)はmAP 64.2と論文で公開していますので、この精度になるのは不思議です。
早速何かやらかしたのかと思いキーポイントをビジュアライズしたり、OpenPoseをv1.7.0にアップデートをかけたりしましたが変わりませんでした。
結論としてはtest-devの公開しているモデルは何かしら違う、このモデルも調整すればきっと精度が出るに違いないと考えました。
OpenPoseをモバイルで評価していく
さて、次はモバイルで評価するにあたり、画像サイズを可変から368x368の固定にしてBODY25を実施しました。
BODY25 368x368
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.323
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.578
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.308
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.330
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.395
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.515
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.742
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.536
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.374
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.712
0.3230332757734204
CoreML 368x368
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.205
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.391
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.183
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.268
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.233
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.458
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.682
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.462
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.313
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.660
0.20462973795675357
固定サイズで実行したところPythonAPIでのAPは32.3となりました。
OpenPoseモデルをCoreMLにコンバートして、これまた自前で用意したiOSコードでキーポイントを取得してValTestを実施したところ20.5となりました。
散々な結果となりましたが、OpenPose CloneなIssueでもVal setは35.3までしか出ない状況ですが、開発者は57.7を出したとREADMEに書いてあるので何かとっておきのテクニックがあるのかも知れませんね。知らんけど。(どないなってるんや。ほんまわからんぞ)
さて、次を試していきます。
SOTAのViT Poseを評価
今年 2022年のCOCO ChallengeでSOTAを取ったViTPoseです。
ViT Poseの実装について説明は省きます。
ViT PoseはCOCOのValidation Test用のコードがあります。
先ずは一番軽量なシングルタスクトレーニングのViTPose-B 256x192のval setを試すと 75.8と出ました。なかなか良い結果です。
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.758
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.907
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.832
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.723
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.826
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.811
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.946
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.877
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.770
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.870
ViT Poseはトップダウン方式ですのでBounding Boxが必要となります。
val setに使われるbboxはSimplebaselineで提供しているbboxと同じデータ(COCO_val2017_detections_AP_H_56_person.json)のようです。
Simplebaselineの論文を見たかぎり、FPN-DCNのパブリックなモデル(mAP 35.7)で作ったのではないかと思われます。
次にViTPose-Lを試。。そうと思いましたがデータサイズが1GBを超えてきます。
ViTPose-Bも300MB超と言うこともあり、あとでiOSに利用するのは中々悩ましいところです。
SimpleBaselineを評価
ViTPoseは一旦置いておいて2018年頃のSimpleBaselineが気になったので試してみます。
Vision Transformの前の流行りとして超解像度のHR(high resolution)がSOTAを取ったのですが、これはとてもパフォーマンスが悪いので今回は見送ろうと思っています。
SimpleBaselineではValidation Test用のコードが用意してあり、実行すると下記の用にMarkdownに貼れる形式の結果が出てきました。
| Arch | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
|---|---|---|---|---|---|---|---|---|---|---|
| 256x192_pose_resnet_50_d256d256d256 | 0.724 | 0.915 | 0.804 | 0.697 | 0.765 | 0.756 | 0.930 | 0.823 | 0.723 | 0.804 |
| 384x288_pose_resnet_152_d256d256d256 | 0.766 | 0.926 | 0.836 | 0.737 | 0.813 | 0.793 | 0.940 | 0.853 | 0.759 | 0.845 |
表の通り、256x192 resnet50と、384x288 resnet152を評価しました。
なぜかREADMEに書いている精度よりも高い結果となりました。ちょっとよくわからない。
256x192 resnet50: 70.4 -> 72.4
384x288 resnet152: 74.3 -> 76.6
ViTPoseが81.1でSimpleBaselineが76.6とすると、2018年から2022年の4年間に4.5しか上昇しなかったこともあり、1.0の重さはすごく重要と思うのですが、READMEに書いてある値より2.0増えるのは中々闇を感じますね。
更に言うとSimpleBaseline後継であるpose_hrnet_w48のval setは76.3なので後継の方が精度出ないし、パフォーマンスも悪く、トレーニングコストも高いことになりますので、あーこれは何かみてはいけない数値見てしまったのではという気になります。
闇が深いところは置いておいて、SimpleBaselineはCPUでも推論がサクサク動くので期待感があります。
構造はアワーグラスよりも簡単な構造。
| Hourglass | SimpleBaseline |
|---|---|
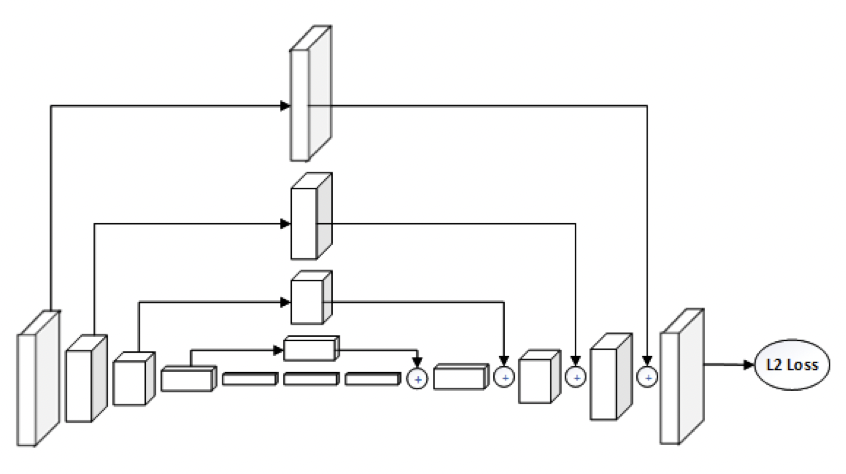 |
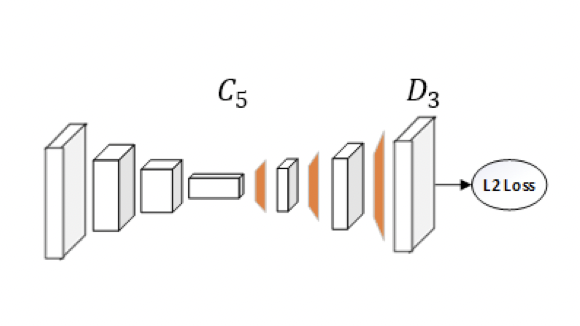 |
アプローチは既存のセグメンテーションのアップサンプリングの手法を参考にしたので新規性はないと控えめ。
数年前の手法でSOTAと大きな遜色なくてパフォーマンス良いのはすごいですね。
iOSでValTestを実施していく
iOSで推論して出力したKyepointをPythonで評価しました。
| DataSet | Model | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|---|
| Val Set | SimpleBaseline | 44.1 | 61.7 | 49.5 | 43.9 | 49.1 |
| SimpleBaseline288x384 | 50.0 | 65.3 | 56.2 | 49.3 | 57.1 | |
| vitpose-b | 45.2 | 65.9 | 50.9 | 43.8 | 51.1 | |
| vitpose-l | 49.4 | 67.7 | 56.6 | 48.1 | 57.2 |
※ bboxはCOCO_val2017_detections_AP_H_56_person.jsonを利用
※ Keypointのデコードの方法は色々ありますが、simplebaselineの手法で実装
※ ViTPoseもsimplebaselineの手法でデコード
ここで残念な結果、simplebaselineはシュミレーターでは何もエラー出なかったのですが、実機だと動くことは動くのですがメモリエラーが出ました。(パラメータを変えると速度は上がったがエラーは変わらず)
ANE(Apple Neural Engine)の仕様はわからんのでコンボリューションの計算量減らすしかなさそうです。
モバイル用のモデルにするとか検討が必要かもしれません。
結果的にViTPose-Bが何も問題なく動きますのでこちらを使っていきましょう。
仕上げにbboxの導入
物体検出の面倒な実装はPipelineで既に実装済みのYolov5sが公開してあったのでこちらを利用しまして、それを元に作ったと思われるYolov7もありましたのでこちらを利用して、評価を実施しました。
| DataSet | Model | AP | AP50 | AP75 | AP(M) | AP(L) | 秒 |
|---|---|---|---|---|---|---|---|
| Val Set | VitPose-B + Yolov5s | 44.7 | 64.1 | 49.7 | 41.4 | 50.7 | 152.6 |
| VitPose-B + Yolov7-tiny | 45.3 | 65.0 | 51.7 | 42.0 | 51.3 | 131.3 | |
| VitPose-B + Yolov7 | 47.0 | 67.7 | 52.8 | 44.5 | 52.5 | 253.2 |
※ 秒はValTestの実行時間です。画像に何人いたか取得していなかったのでfpsは出ないです。
直前に用意していたbbox(COCO_val2017_detections_AP_H_56_person.json)を使ったVitPose-Bが45.2だったと言うことは、Yolov7-tinyでbboxファイルの精度を超える45.3が出たのは中々良い結果ではないでしょうか。
最後に
主に三つの姿勢推定を試しましたが、自分でやっただけでは解らない点はいくつか出ました。
今後は、Issueを見たり質問したりで解消していければと思います。
iOSに変換すると精度は落ちますが、ValTestを試すことで、それなりの精度やパフォーマンスの評価に繋がることが解りました。
また、論文やREADMEで公開している数値よりも実際に動かさないと本当の数値が出ないことも確認できました。自分もまさか試した3つのうち2つも想定した数値が出ないとは思いませんでしたが。
後は、CoreMLモデルにしたときの精度落ちるのをどうにか出来ればいいのですが、ANEの仕様は解りませんし、どうしようもないですね。
思ったような結果にならず疑問も増えましたが、今後の皆さんの参考になればと思います。
おまけ
VitPose-b + Yolov7-tinyの動作するコードはこちらで公開しています。
SimpleBaselineのPythonコードを参考にopen-mmlab/mmdetectionのC++コードを改修して作成しました。
iPhone14Proでひとりの人物の動画を処理して30fps近く出てなかなか高速です。(サンプルは画像ファイルの処理だけです)
https://github.com/mbotsu/TopDownPoseExample
Yolov7がGPL3なのでライセンスはGPL3としてます。
回避方法があればApache2にしたいところです。