概要
Twitterでは,新型コロナウィルスに関して日夜活発に議論されています.
これらのツイートを分析することで,Twitterユーザの傾向として意義あるものが掴めないかと思ました.
そこで,本記事では,Twitterに投稿された新型コロナウィルスに関するツイートを収集し,簡単に分析をしていきます.
誤りや見づらい箇所,アドバイス等ございましたら,どうぞご気軽にご指摘ください.よろしくお願いします.
データの詳細
本記事で用いるツイートデータは,2020年1月1日~2020年4月1日までの間に投稿された,「コロナ」「COVID-19」「感染症」のいずれかを含むツイートです.
ただし,日本語ツイートに限定し,RT数が100を越えているツイートのみを用います.
結果として,47041件のツイートからなるデータセットを構築しました.
ツイートデータは以下のような連想配列で保存しました.
{
'text': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'date': datetime.datetime(2020, 1, 1, 1, 0, 1),
'retweets': 123,
'favorites': 456,
'user_id': 7890123,
'hashtags': ['# yyy', '# zzz'],
'url': ['https://aaaaaa.com', 'http://bbb.com']
}
探索的データ分析 (Explanatory Data Analysis: EDA)
本記事で用いるデータからは,テキストの長さ,投稿時間,RT数,いいね数,ハッシュタグの有無,URLの有無といった,いくつかの量が得られます.
そこで,これらの量を活かしてデータの特性を読み取ります.
※以下すべてpython3 + Jupyter Notebookを用いて処理しています.
import os, sys, json, re
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from datetime import datetime
import datetime as dt
%matplotlib inline
文字数,RT数,いいね数,URLの有無,ハッシュタグの有無
文字数
tweet_len = tweets["text"].str.len()
tweets["text_len"] = tweet_len
tweets["text_len"].hist(bins=range(0, 141, 5))
plt.xlabel("len. of text")
plt.ylabel("num. of tweets")
plt.title("Histgram on length of texts in tweets")
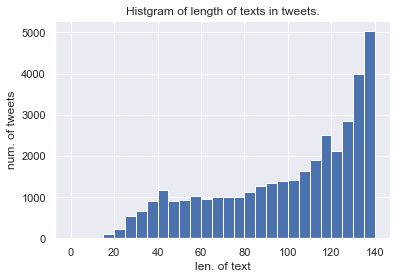
データ取得の時点では,140字を越えるツイートが少数見られましたが(なんで?),図の見やすさのために省きました.
データセット内の多くのツイートが,多くの文字(≒情報)を含むようです.
本データセットには10RTを越えるツイートのみを採用しているので,もしかしたら文字数が増加するほどRT数が増加する傾向にあるのかも知れません.(この点は下で検証しています.)
RT数,いいね数
tweets["retweets"].hist(bins=range(0,4001,100))
plt.xlabel("num. of RT")
plt.ylabel("num. of tweets")
plt.title("Histgram on the number of RT.")
-------------------------------------------------
tweets["favorites"].hist(bins=range(0,4001,100))
plt.xlabel("num. of favorites")
plt.ylabel("num. of tweets")
plt.title("Histgram on the number of favorites.")
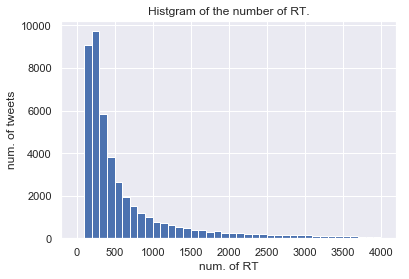
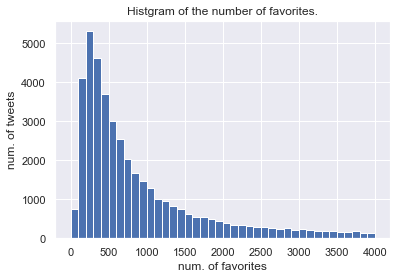
実際には10万RT/いいねを越えるツイートもあるのですが,図の見やすさのためにこのように範囲を設定しています.
両者とも減衰がみられますが,RT数で~300程度まではツイート数が上昇傾向にあることから,いったんRTされはじめたツイートはある一定のラインまではRT数が伸び続ける傾向にあるのでは無いかと推測できます.
ここで,RT数と文字数の相関関係を見てみます.
fig, ax = plt.subplots()
ax.scatter(tweets["text_len"], tweets["retweets"], s=1)
plt.xlim(0, 140)
plt.ylim(0, 5000)
plt.xlabel("len. of texts in tweets")
plt.ylabel("num. of RT")
plt.title("Scatter plot of RT and len. of texts.")
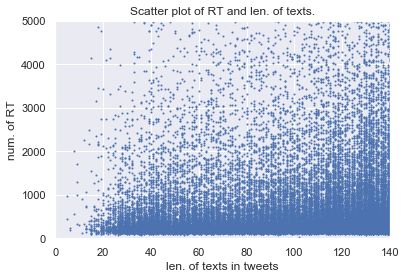
相関係数: 0.022
図を見ると文字数が140に近い所ではRT数も大きいツイートが多いように見えるのですが,相関関係は無いようです.
したがって,「たくさんRTされるツイートは,文字数が多い傾向にある」といったことやその逆は言えないようです.
ハッシュタグ/URLの有無
tweets.loc[tweets["hashtags"].str.len() > 0, "has_hashtag"] = 1
tweets.loc[tweets["hashtags"].str.len() <= 0, "has_hashtag"] = 0
tweets["has_hashtag"].hist()
plt.xlabel("has hashtag (1) or not (0)")
plt.ylabel("num. of tweets")
plt.title("Histgram of whether tweets have hashtag(s) or not.")
----------------------------------------------------------------
tweets.loc[tweets["url"].str.len() > 0, "has_url"] = 1
tweets.loc[tweets["url"].str.len() <= 0, "has_url"] = 0
tweets["has_url"].hist()
plt.xlabel("has URL (1) or not (0)")
plt.ylabel("num. of tweets")
plt.title("Histgram of whether tweets have URL(s) or not.")
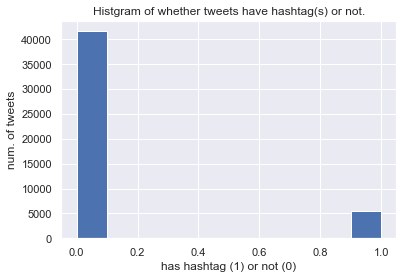
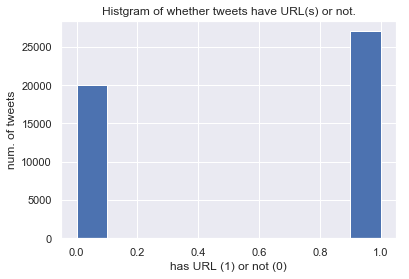
このデータセットでは,ハッシュタグが付与されたツイートは少なく,URLが付与されたツイートが多いようです.
半数以上のツイートにURLが付与されていることから,RT数が10以上のツイートの多くは本文だけで無く,URLによっても情報を付与していることがわかります.
ここまでのまとめ
このあたりは一般のツイートと同様な特性が見られるようです.
(実際には一般のツイートでデータセットを作り,同様の量をだして比較する必要がありますが・・・)
データセットのツイートには,本文が長く,ハッシュタグよりもURLによって情報を付加する傾向にあります.
RT数,いいね数に関してもキレイに減衰する傾向がみられ,これは一般のツイートでも同様であると考えられます.
時系列を用いた分析
以降では,1/1から4/1までの92日間での種々の量の変遷をみていきます.
日ごとのツイート数
sns.set()
fig, ax = plt.subplots(figsize=(16.0, 8.0))
ax.bar(df.index, df["tweets"], color='#348ABD')
ax.plot(df.index, df["kansen"], color="blue")
ax.set_xticks([1,32,61,92])
ax.set_xticklabels(["01/01", "02/01", "03/01", "04/01"])
ax.set_xlabel("date")
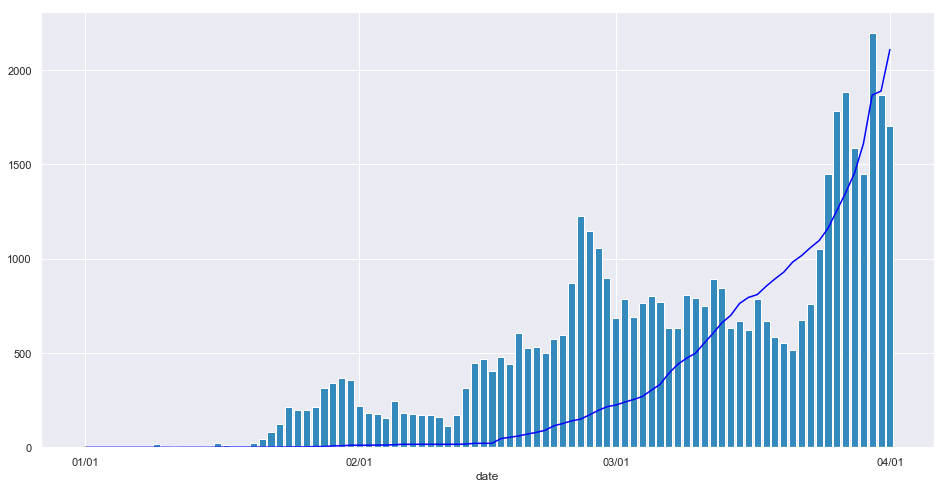
横軸は日付です.
ヒストグラムが日ごとのツイート数を表し,折れ線が日ごとの国内での新型コロナウィルス感染判明数1を表します.
縦軸の目盛りは両者に共通です.
上図ではいくつかのピークが確認できます.
各ピークに関して,1日だけ飛び抜けるわけではなく,2,3日に渡ってツイート数が増加しています.
このことから,こうしたピークは外れ値ではなく,この期間にはユーザの関心を強く引く事柄が存在したと予想されます.
また,感染判明数もついでに載せましたが,ツイート数とはそれほど相関がないようです.苦労したのに
このことから,ユーザは新型コロナウィルスの患者数増加(感染拡大)よりも,その結果もたらされる他の事象(例えば政治的判断やイベントの中止など)に強く反応すると予想されます.
では,各ピークは何が原因で生じているか分析します.
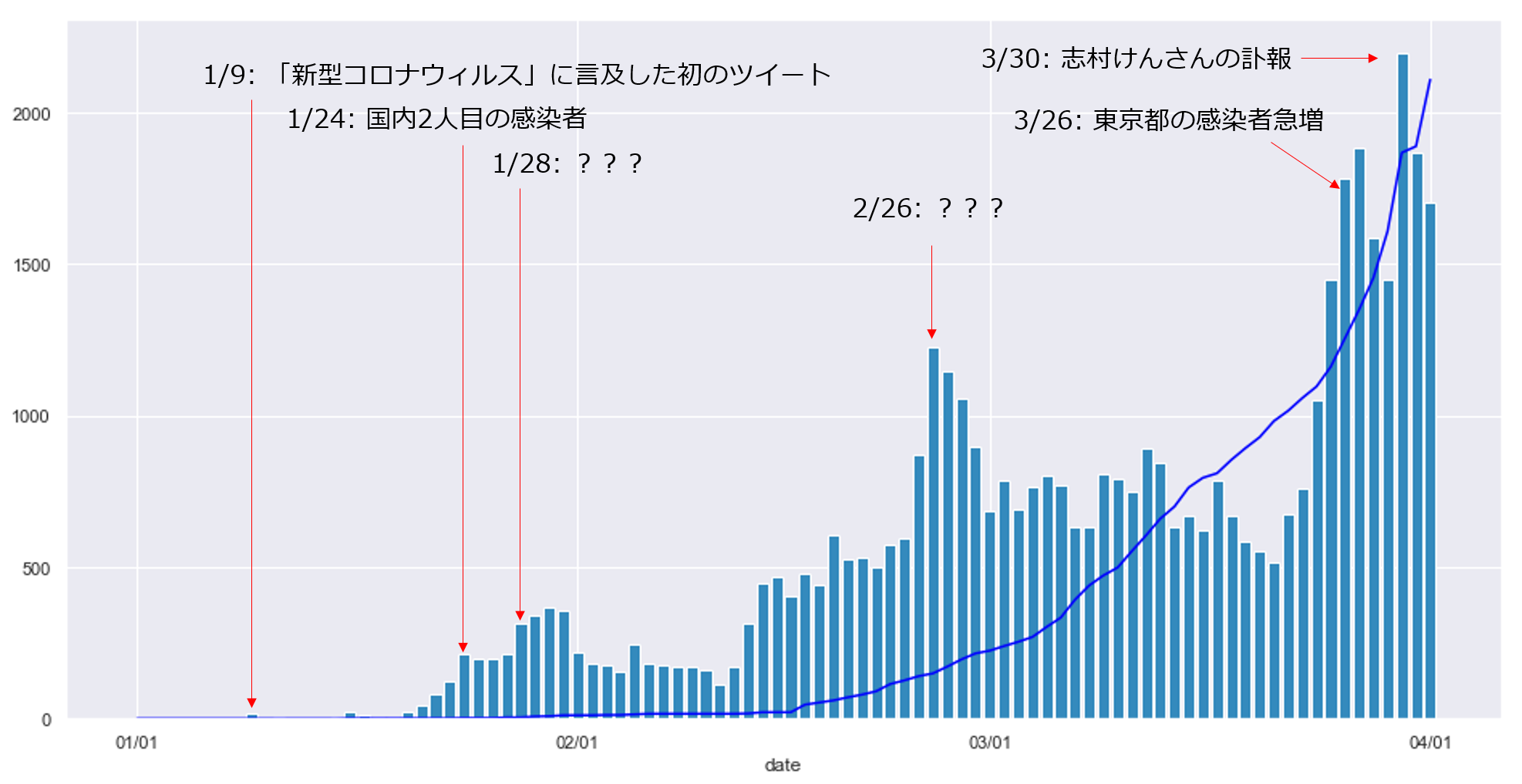
この図は,先ほどの図のピークや個人的に気になる日に関して,実際のツイートの内容や厚労省の発表等を調査し,ピーク等の事象の原因になったと思われる内容を付与したものです.
肝心の1/28付近と2/26付近に関して,いずれもデータセット内の100件以上のツイートに目を通しましたが,一貫性が無く,何がピークの原因となっているかは確認できませんでした.
こちらは,後ほど頻出語やRT数に関する分析を行う際に,詳細に確認します.多分
日ごとの累計RT数
sns.set_style("dark")
fig, ax1 = plt.subplots(figsize=(16.0, 8.0))
ax1.bar(df.index, df["retweets"], color='#348ABD')
ax2 = ax1.twinx()
ax2.plot(df.index, df["kansen"], color="blue")
ax2.set_ylim(0,2500)
ax1.set_xticks([1,32,61,92])
ax1.set_xticklabels(["01/01", "02/01", "03/01", "04/01"])
ax1.set_xlabel("date")
ax1.set_ylabel("num. of retweets")
ax2.set_ylabel("num. of infected people")
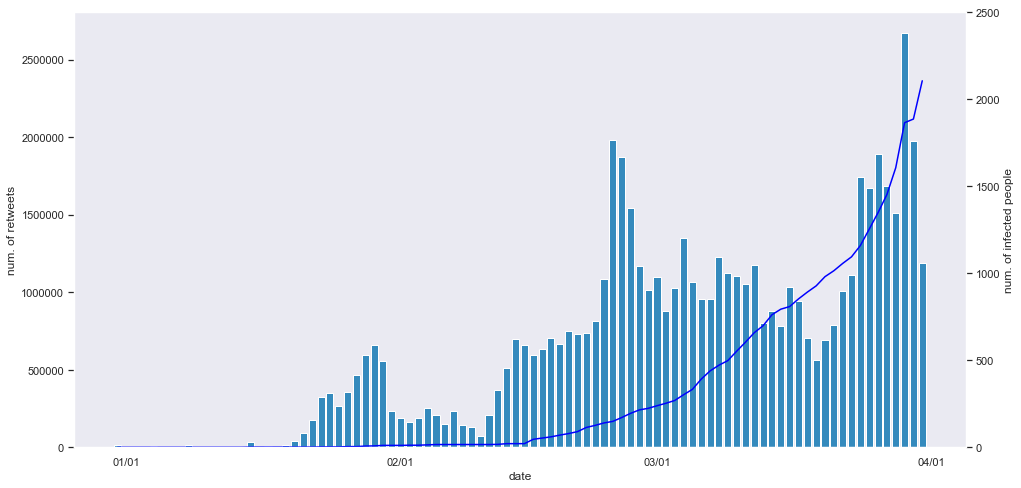
上図で,ヒストグラムと左縦軸は日ごとの累計RT数を表し,折れ線と右縦軸が日ごとの感染判明数を表します.
日ごとのツイート数と同じようなグラフが出てきました.
やはり,日ごとの感染判明数とは関連が無さそうです.
では,日ごとのツイート数と日ごとのRT数を比較してみます.
sns.set_style("dark")
fig, ax1 = plt.subplots(figsize=(16.0, 8.0))
ax1.bar(df.index, df["tweets"], color='#348ABD', alpha=0.7)
ax2 = ax1.twinx()
ax2.plot(df.index, df["retweets"], color="red")
ax2.set_ylim(0,3000000)
ax1.set_xticks([1,32,61,92])
ax1.set_xticklabels(["01/01", "02/01", "03/01", "04/01"])
ax1.set_xlabel("date")
ax1.set_ylabel("num. of tweets")
ax2.set_ylabel("num. of retweets")
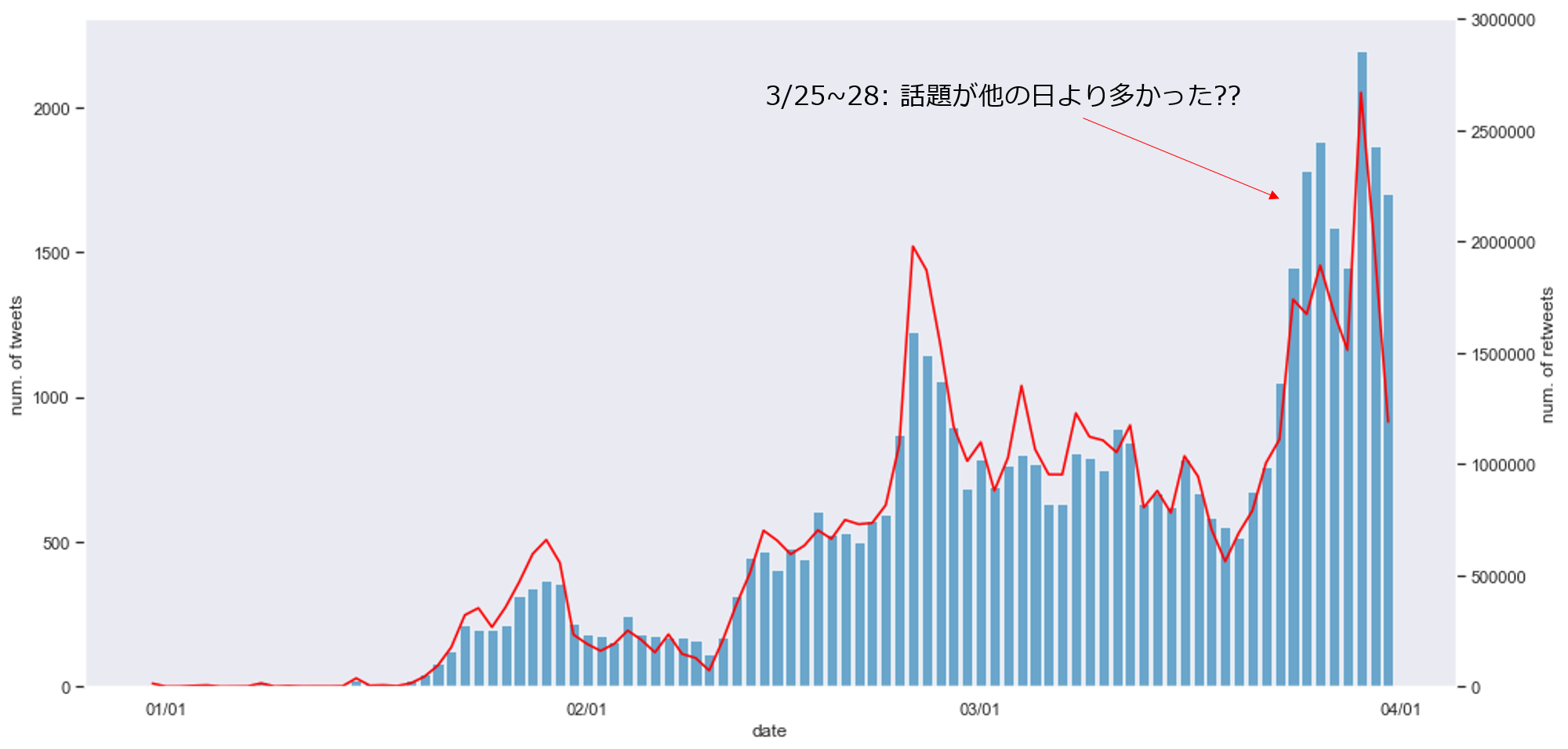
上の図で,ヒストグラムと左縦軸が日ごとのツイート数を表し,赤の折れ線と右縦軸が日ごとの累計RT数を表します.
日ごとのツイート数と日ごとのRT数は,ほとんどの日で相関関係にあるようです.
ここで,3/25~28付近だけ,他とは異なる様相を呈しています.
他の人比較して(10RT以上された)ツイート数がRT数を上回る原因として,この期間だけ,他の期間と比較して新型コロナウィルスに関する話題が多く,ユーザが話題を追い切れなかった(RTできなかった)ことが考えられます.
今後
さっさと投稿したかったので上記を踏まえ,今後やることを書いていきます.
- 頻出語の分析
- 1/24,2/26あたりになぜピークがあるのか.
- WindowsのMeCabがなぜかうまくいかない.
- ツイートのクラスタリング
- 例えば日ごとにツイートをクラスタリングすることで,その日の話題の数が定量化でき,ツイートの内容もまとまってより分析しやすくなると期待できます.
- RT数予測モデルの構築
- 適当な回帰モデルを組んで,「どういう性質のツイートがRTされやすい(≒人の興味を引く)か」といったことを分析できるかも...?
- 問題を分類にしても良さそう.
- ユーザ情報の活用
- 例えば専門家のツイートは,そうでないユーザよりRT数が多くなるでしょう.このように,投稿者の情報を活用することで,より詳細に新型コロナウィルスに関するTwitterユーザの動向が分析できる可能性があります.
おわりに
はじめてQiitaに投稿します.
分析として,なにか革新的な知見が得られた訳ではありませんでしたが,今後このデータセットについて掘り進める方針が掴めた気がします.
EDAは,こうした方向性を決めるためにも重要なのですね.
本当はしっかり予測モデルまで構築して,評価・モデルの性質の分析までしたかったのですが,はよ投稿したいという気持ちが強く,次回に回すことにしました.
ここまで読んで頂き,ありがとうございました.
拙い分析・文章で恐縮ですが,ご指摘・ご意見,アドバイス等お気軽にして頂ければと思います.