はじめに
Seleniumでは、対象ページのHTMLソースコードの情報を利用して要素を指定し、クリックや文字入力などの操作を行います。
今回はChromeでHTMLソースコードを表示する方法と、表示したHTMLソースコードをSeleniumで利用する例を紹介いたします。
ChromeでHTMLソースコードを表示する
まず、HTMLソースコードを表示したいページを開いた状態で右クリックします。
表示されたメニューから「検証」をクリックします。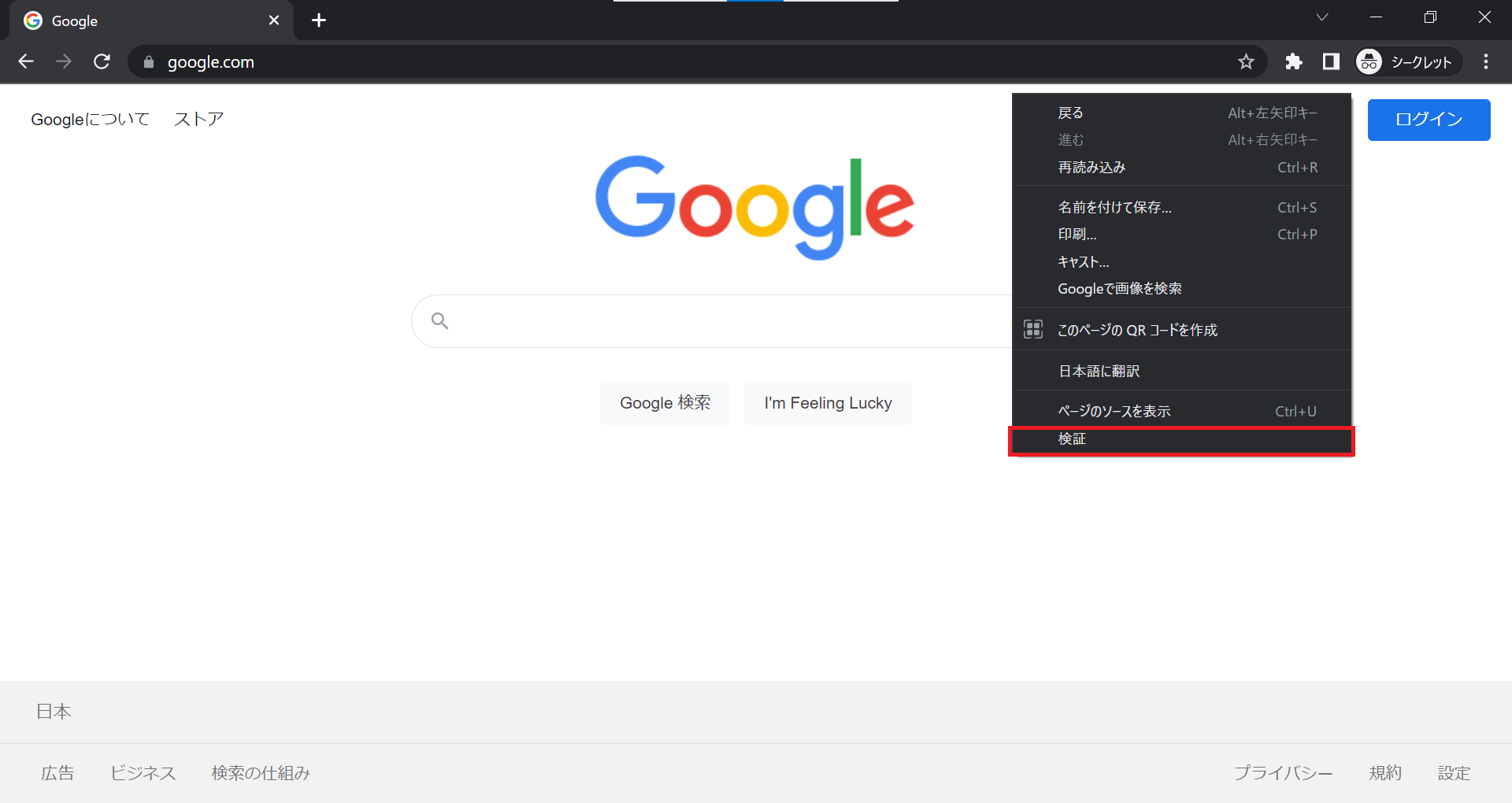
ブラウザの右側に検証画面が表示されます。
赤枠で囲っている部分がHTMLソースコードになります。
また、赤丸で囲っているアイコンをクリック後HTMLソースコード上でどこにあるか確認したい部分をクリックすると、HTMLソースコードがハイライトされます。
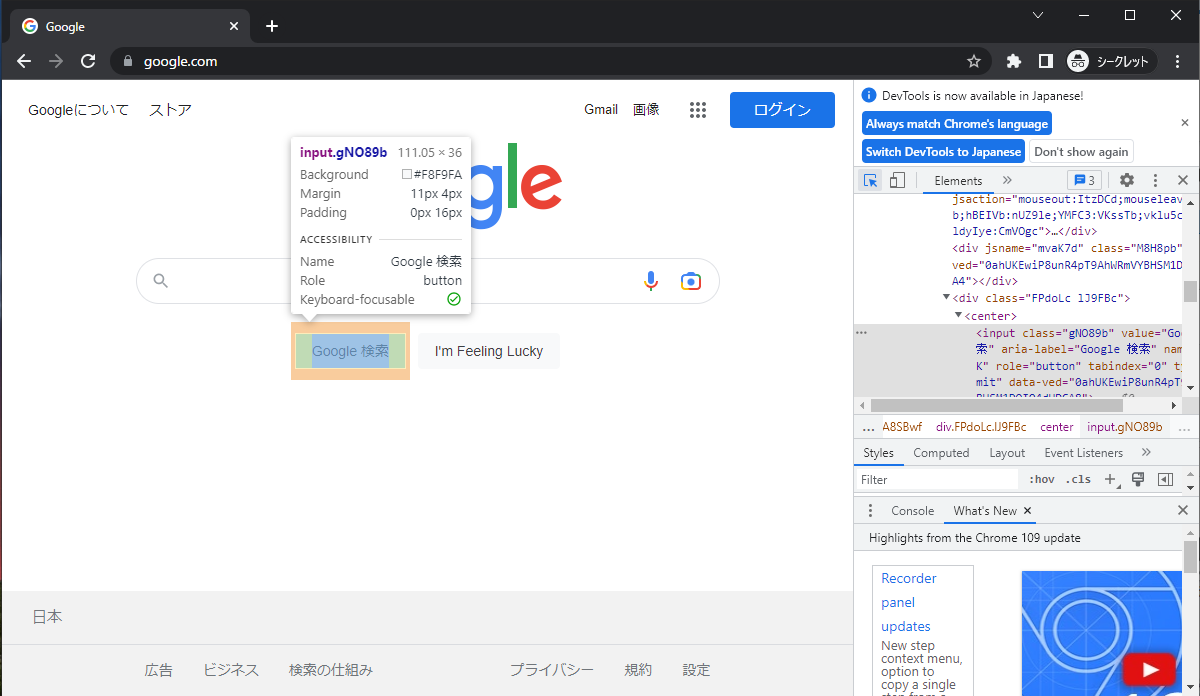
画像はGoogleのトップページにて、「Google 検索」の部分を確認しようとした場合のものになります。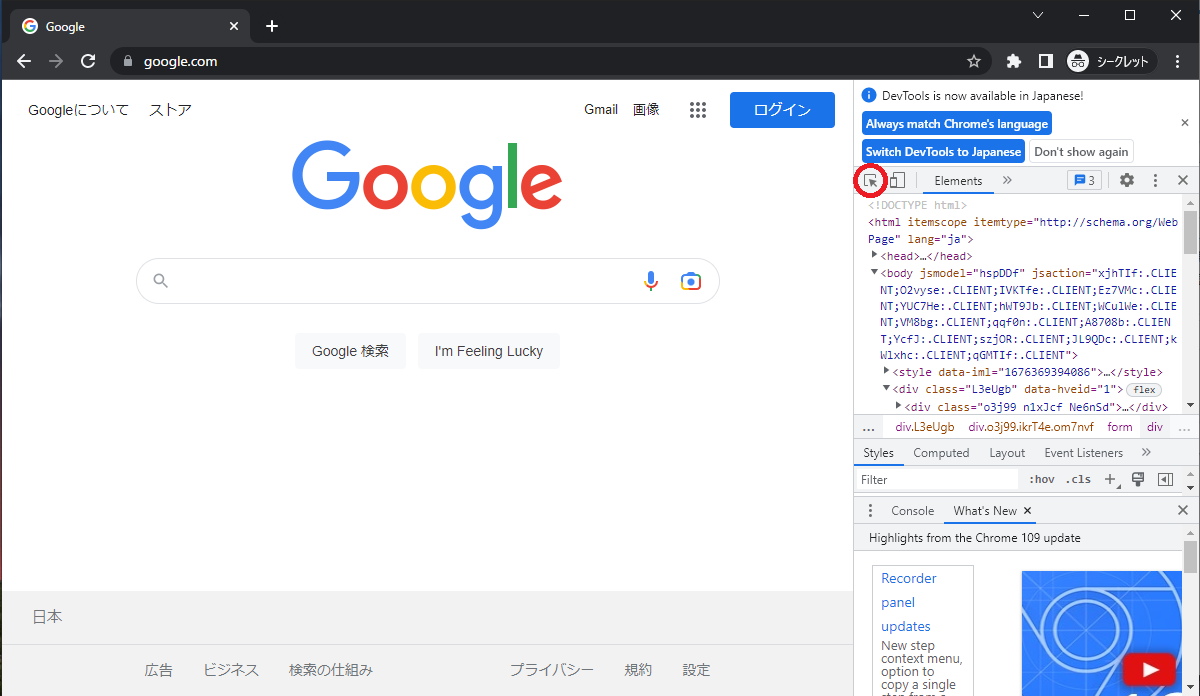

表示したHTMLソースコードをSeleniumで利用する例
今回は前章を参考に、「Google 検索」をクリックする操作をPython + Seleniumで実装するコード例を記載します。
まずクリックする要素について、XPATHの情報を取得します。
前章でハイライトされた部分で右クリックし、「Copy > Copy XPath」をクリックします。
ちなみに「Copy full XPath」の方でも問題ないです。
上記操作で得たXPATH情報がこちらになります。
/html/body/div[1]/div[3]/form/div[1]/div[1]/div[4]/center/input[1]
SeleniumにてXPATH情報から要素を取得するためには、find_element_by_xpathを利用します。
そのため、今回は要素取得のコードが以下のようになります。
driver.find_element_by_xpath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[4]/center/input[1]")
後はシンプルに、取得した要素の後ろに.click()をつけることで、要素に対してクリックする動作をさせることができます。
driver.find_element_by_xpath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[4]/center/input[1]").click()
サンプルコード
前章で紹介した例を使用しているサンプルコードを載せておきます。
動作内容は、Googleのトップページにて検索欄で「chrome」と入力後「Google 検索」ボタンをクリックする、というものになっております。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.google.com")
sleep(3)
driver.find_element_by_xpath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input").send_keys("chrome")
sleep(3)
driver.find_element_by_xpath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[4]/center/input[1]").click()
sleep(3)
driver.quit()
最後に
Seleniumで自動ブラウザ操作を実装する際に、HTMLソースコードから情報を取得することはほぼ必須で行う作業になると思いますので、ぜひ活用してください。
また今回はXPATH情報を取得した例を挙げてますが、他にもIDやNAME情報を利用して要素を取得することもできます。
他の情報を利用した要素取得についてはこちらのサイトが参考になると思います。
最後まで読んでいただき、ありがとうございました。