この文書ではC++のメモリオーダリング指定についてその必要性と使い方について述べる。
マルチスレッドでおきること
x86-64アーキテクチャにおいて基本的にint変数への代入、読み取りはアトミックである。(もちろんこれはC++の仕様ではなくプラットフォーム依存の挙動である。)
以下のようなコードが考えてみる。
#include <future>
#include <cassert>
static int a = 0;
static int b = 0;
void func() {
for(;;) {
if (b == 20) {
assert(a == 10);
break;
}
}
}
int main(int argc, char *argv[])
{
for (;;) {
auto future = std::async(std::launch::async, []{func();});
a = 10;
b = 20;
future.wait();
a = 0;
b = 0;
}
return 0;
}
b==20となるまで待ち続けるfunc()を別スレッド(以下「スレッド1」)で実行する。その後a=10,b=20の順番で代入する。
普通に考えればb==20であればそれより前にaに10が代入されているはずであり、assert()に引っかかるはずはない。
しかし実際はこうだ。
$ g++ -O2 -o main main.cpp
$ ./main
main: main.cpp:11: void func(): Assertion `a == 10' failed.
[1] 2528160 IOT instruction ./main
つまり、メインスレッドからはb==20かつa==0と見える可能性があるということだ。これが「メモリオーダリング」と呼ばれる問題領域である。
補足:アトミックとは
ここでアトミックについて簡単ににおさらいしておこう。
static std::atomic<int> a = 0;
void thread1() {
a = 10;
}
void thread2() {
a = 20;
}
thread1(),thread2()がマルチスレッドや割り込み等でどのように実行されたとしてもaを読み取ったとき値が0,10,20以外の値になることはない。これを「変数aは代入、読み取りにたいしてアトミックである」という。
逆に言うとaがアトミックでないなら場合によっては0,10,20以外の値を取りうるということである。
手っ取り早い解決策
C++においてこの問題を解決するのは非常に簡単である。intをstd::atomic<int>に変えれば解決だ。
#include <atomic>
static std::atomic<int> a = 0;
static std::atomic<int> b = 0;
しかし、上の例では一体何が起きたのか。そしてなぜstd::atomicを使うと解決するのか、以下で解説していく。
プログラムは書いたとおりに実行されない
現代のコンパイラ、プロセッサ環境において以下にあげる要因によって書いた命令がそのままの順番では実行されない可能性がある。
- コンパイラ要因: コンパイラが最適化の過程で命令の順番を入れ替える可能性がある。
- プロセッサ要因: プロセッサが命令実行時に「OOO(Out of Order)実行」といって記述された順序とは異なる順序で命令を実行する可能性がある。
とはいえシングルスレッド、割り込みなしで動作している限りプログラマが上記要因を気にする必要は一切ないので安心してほしい。
(コンパイラ最適化においてもプロセッサ最適化においてもシングルスレッド内の挙動が変わってしまうような最適化は決して行われない。)
問題はマルチスレッドや割り込み環境においてである。マルチスレッドや割り込み環境では上記に上げた要因により冒頭で示して例のような自体が発生し得るのである。
メモリモデル
上記状況に対してC++ではスレッド間でのメモリアクセスの順序を明確にするためにメモリモデルを導入した。これにより、異なるスレッドが共有データにアクセスする際の順序を制御し、一貫性を保つことが可能になる。
たとえばstd::atomicであれば代入・参照動作に様々な順序に関する制約をかけることができる。(メモリオーダー指定)
std::atomicの代入・参照操作
std::atomicにおける代入(例: a=10)は実際は以下メソッド呼び出しのシンタックスシュガーである。
a.store(10, std::memory_ordering_seq_cst)
2つ目の引数はメモリオーダー指定と呼ばれstd::memory_ordering_seq_cstは最も強い制約の指定となっている。
つまり裏を返すと制約を必要最小限に弱めることで最適化により速度が向上する余地が大きくなるということであり、そしてバグが入り込む余地も大きくなるということである。
以下でメモリオーダー指定にどのようなものがあるか見ていこう。
Relaxed オーダリング
1つの変数について順序を保証するオーダリングである。
static std::atomic<int> a=0;
void thread1() {
a.store(10, std::memory_order_relaxed);
a.store(20, std::memory_order_relaxed);
}
つまり変数aを別のスレッドから観察したときa==10を観察したのであれば、いつかは必ずa==20になるということである。
当たり前のように感じるかもしれないが、実は単純なstatic int aでは仕様上はこの保証すら無いことに注意が必要である。
Release/Acquire オーダリング
冒頭の例をstd::atomicのデフォルトメモリーダーであるSequentially Consistent(後述)よりもゆるい制約でassert()に引っかからないコードに書き直すにはRelease/Acquireオーダーを使用することになる。
#include <atomic>
#include <future>
#include <cassert>
static std::atomic<int> a = 0;
static std::atomic<int> b = 0;
void func() {
for(;;) {
if (b.load(std::memory_order_acquire) == 20) {
assert(a.load(std::memory_order_relaxed) == 10);
break;
}
}
}
int main(int argc, char *argv[])
{
for (;;) {
auto future = std::async(std::launch::async, []{func();});
a.store(10, std::memory_order_relaxed);
b.store(20, std::memory_order_release);
future.wait();
a = 0;
b = 0;
}
return 0;
}
Release/Acquireによる制約は意外とシンプルである。
- Releaseより前にあるメモリ操作をRelease後にリオーダすることはできない。
- Acquireより後にあるメモリ操作をAcquire前にリオーダすることはできない。
この2つにより、下図のようにb==20であればかならずa==10で有ることが保証される。
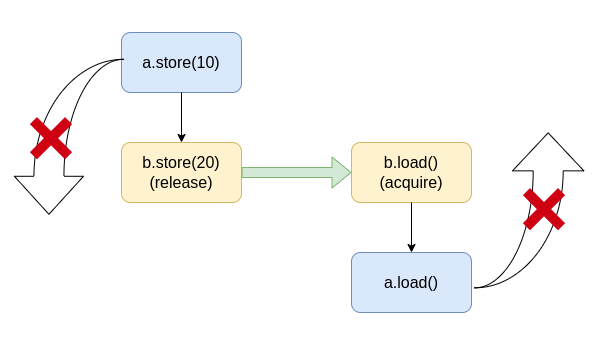
なお上図にあるようにb.store(20)とb.load()がまるで通信でもしているかのように矢印で接続されている図をよく見かけるが、store(), load()が特定の相手と通信するなどということは一切ないことに注意が必要である。
あくまで「もしbが20であることが観測できたらaは必ず10と観測される」ことが保証されるだけである
Sequentially Consistent オーダリング
Sequentially Consistent オーダリングは最も強い制約を課す。つまり、
- 全てのスレッドについてSequentially Consistent オーダリングの操作は同じ順番に見えることが保証されている。
冒頭の例でaをstd::atomic<int>に変更することで解決したのはこの性質のためだ。しかし最も最適化が制限されるオーダリングであるためパフォーマンスに敏感なプロジェクトでは使用に注意が必要な可能性もある。
タネ本紹介
今回の記事は以下の書籍を参考にして記述した。Rustに関する書籍であるがメモリオーダリングに関してはRustとC++はほぼ一緒であるためRustについて学びつつC++についても理解を深められる。