One Model to Rig Them All: Diverse Skeleton Rigging with UniRig(ZHANG, 2025)

3行要約
- 🤖 UniRigは、大規模自己回帰モデルと独自のSkeleton Tree Tokenization、およびBone-Point Cross Attentionメカニズムを組み合わせることで、多様な3Dモデルに対し高品質なスケルトンとスキニングウェイトを自動生成する統一フレームワークである。
- 🚀 本手法は、Rig-XLとVRoidという大規模データセットで訓練され、従来の自動リギングが苦手とする複雑な形状や非標準的なトポロジーを持つモデルに対しても、高いリギング精度とモーション精度を達成した。
- ✨ UniRigは、手動リギングのボトルネックを解消し、人間の修正を許容する設計とリアルなスプリングボーンシミュレーションにより、アニメーション制作パイプラインの効率化と品質向上に貢献する。
Q:何が問題で、それをどのように解決したのか、わかりやすく説明してください
A:
UniRigが解決した問題と解決策
想像してみてください。あなたはゲームや映画で使うための、たくさんの色々な形の3Dキャラクターを持っています。普通の人間型もいれば、変な形のエイリアン、足が何本もある動物、フワフワした髪のキャラクターもいます。
【問題】キャラクターを動かしたい!でも、動かす準備がすごく大変!
これらのキャラクターを動かすためには、「リグ」という骨組みと、皮膚を骨に結びつける設定が必要です。でも、このリグを作る作業が、今までは次の点でとても大変でした。
-
キャラクターの形が多様すぎると、骨組みを作るのが難しい!
- 人間型のキャラクターなら、どの骨をどこに置けばいいか大体分かります。でも、変な形のエイリアンや足が8本あるクモのようなキャラクターだと、どこにどんな骨を配置して、どう繋げばいいか、毎回アニメーターが頭を悩ませていました。
- 特に、骨の繋がり方(トポロジー)がデタラメだと、キャラクターが不自然に折れ曲がったり、アニメーションが破綻したりします。
-
骨と皮膚を自然に結びつけるのがすごく大変!
- 皮膚(メッシュ)を骨に結びつける「スキニングウェイト」という作業も、非常に細かくて職人技が必要でした。特に、関節部分の皮膚が自然に曲がるように設定するのは、熟練のアニメーターでも時間がかかります。
- フワフワした髪やスカートなど、物理法則に従って動く「スプリングボーン」の設定も、手作業では大変でした。
-
結局、ほとんど手作業で時間がかかる!
- 既存の自動化ツールは、特定のキャラクター(例えば人間型だけ)には強いものの、多様なキャラクターには対応できなかったり、結局は手動で大量に修正が必要だったりしました。つまり、「自動」と言いつつ、結局は「半自動」で、アニメーション制作のボトルネックになっていたのです。
【解決策】UniRigが「AIの力」と「賢いデータ表現」で、全部自動で解決!
UniRigは、これらの問題を解決するために、大きく分けて2つの賢いアプローチと、それを支える工夫をしました。
-
AIに「骨組みの作り方」を学習させる(多様な骨組みを自動生成)
- 賢いデータ表現(Skeleton Tree Tokenization): まず、UniRigは、どんなに複雑なキャラクターの骨組み(スケルトンツリー)でも、コンピューターが理解しやすいように「トークン」という小さな情報のかたまりに分解して順番に並べ替える新しい方法を考えました。まるで、骨組みの「設計図」をAIが読みやすいようにデジタル化したようなものです。
- 自己回帰モデル(Autoregressive Model): そして、この「設計図」を、文章を自動生成するAI(大規模言語モデルのようなもの)と同じような仕組みのAIに学習させます。キャラクターの3D形状を入力すると、AIはまるで文章を紡ぐように、過去に生成した骨の情報を使って「次に来る骨はこれ、その次はこれ」と順番に予測していき、最終的に「トポロジー的に正しい」完璧な骨組みを自動で生成できるようになりました。
-
AIが「皮膚と骨の結びつき」を学習させる(自然なスキニングウェイトを自動生成)
- 骨とポイントの連携AI(Bone-Point Cross Attention): AIが生成した骨組みと、キャラクターの3D形状(点群)を両方見て、どの骨がどの皮膚にどれくらい影響を与えるかを自動で予測する仕組みを開発しました。これにより、複雑な関節の周りでも、肉が不自然に伸び縮みせず、自然に変形するスキニングウェイトを生成できるようになりました。
- 物理シミュレーションによる訓練: さらに、フワフワした髪やスカートのような「スプリングボーン」の動きが、より自然になるように、物理シミュレーションの結果をAIの学習に組み込むことで、よりリアルな動きができる設定を自動で予測できるようにしました。
結果として、UniRigは…
- どんなに多様な形をした3Dキャラクターでも、自動で正確な骨組みを作り、しかもトポロジー的に破綻しないようになりました。
- 骨と皮膚の結びつきも非常に自然で高品質になり、手作業での修正がほとんど不要になりました。
- これにより、キャラクターをアニメーションさせるための準備が、圧倒的に速く、効率的になったのです。
Q:この論文の概要を教えてください
A:
本論文は、大規模な自己回帰モデルとボーン-ポイント交差アテンション機構を活用し、高品質なスケルトンとスキニングウェイトを生成する、自動リギングのための新規かつ統一的なフレームワーク「UniRig」を提案しています。これまでの手法が複雑な、あるいは非標準的なトポロジーに対応するのに苦労していた点に対し、UniRigは「Skeleton Tree Tokenization」という新しい手法を用いることで、トポロジー的に有効なスケルトン構造を正確に予測することを可能にしています。
本研究は、特に以下の主要な貢献を行っています。
- スケルトン構造を効率的にエンコードする新規な「Skeleton Tree Tokenization」手法の提案。これにより、自己回帰モデルがトポロジー的に有効で、かつ構造化されたスケルトンを生成できます。
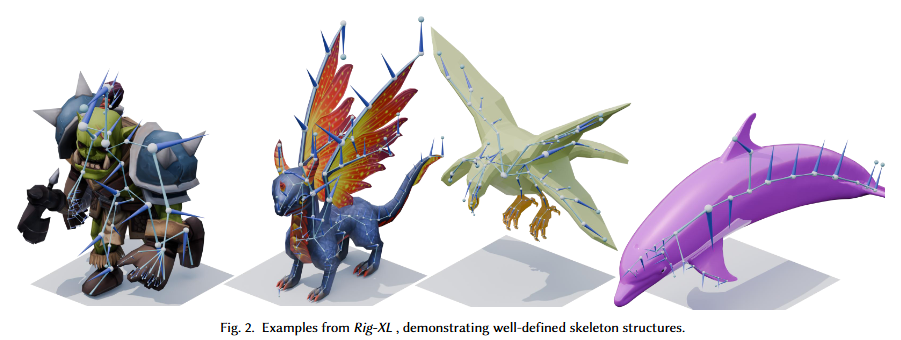
- 高品質で多様な3Dリグモデルからなる大規模な新規データセット「Rig-XL」の構築。このデータセットは慎重にクリーニングされており、その後の自動リギングタスクのための高品質で汎化されたリソースを提供します。
- 自己回帰モデルによるスケルトン予測とボーン-ポイント交差アテンション機構によるスキンウェイト予測を組み合わせた統一的な自動リギングフレームワーク「UniRig」の導入。本フレームワークは、幅広いオブジェクトカテゴリとスケルトン構造において、スケルトン予測とスキンウェイト予測の両方で既存の手法を凌駕する最先端の結果を達成しています。
データセット
UniRigの訓練と評価のために、2つのデータセットが構築されています。
- VRoidデータセット: アニメスタイルの3D人間モデル2,061体から構成され、VRMフォーマットの標準化されたヒューマノイドスケルトン定義(Mixamo互換)と、物理シミュレーションを可能にする「春ボーン(spring bones)」をサポートしています。
-
Rig-XLデータセット: Objaverse-XLデータセットから派生した14,611体の多様な3Dモデルを含みます。このデータセットは、以下の厳密な前処理パイプラインを経て構築されました。
- スケルトンベースのフィルタリング: ボーン数が10〜256の範囲内にあり、単一で接続されたスケルトンツリーを持つモデルのみを保持。ルートノードの不適切な接続など、不合理なトポロジーを持つデータは、子のサイズや最小全域木(MST)に基づいて修正されました。
- 自動カテゴリ分類: レンダリングされた画像の知覚ハッシュ値による重複排除後、視覚言語モデル(ChatGPT-4o)を用いてモデルを8つのカテゴリ(Mixamo, Biped, Quadruped, Bird & Flyer, Insect & Arachnid, Water Creature, Static, Other)に分類。
- 手動検証と改善: 各モデルをスケルトン付きで再レンダリングし、手動で目視確認と修正を実施。
自己回帰型スケルトンツリー生成
本ステージでは、3Dメッシュから有効で整形式なスケルトンツリーを正確に予測します。
- 入力メッシュの処理: 入力メッシュ $M = {V \in \mathbb{R}^{V \times 3}, F}$ から$N=65536$点の点群 $X \in \mathbb{R}^{N \times 3}$ と対応する法線ベクトル $N \in \mathbb{R}^{N \times 3}$ をサンプリングし、$[-1, 1]^3$ に正規化します。これらは3DShape2Vecset表現に基づく幾何学的エンコーダ $E_G: (X, N) \mapsto F_G \in \mathbb{R}^{V \times F}$ に通され、幾何学的埋め込み $F_G$ が生成されます。
-
自己回帰モデル: OPTアーキテクチャに基づくデコーダオンリーTransformerが、スケルトンツリー ${J, P}$ を離散シーケンス $S$ として順次生成します。モデルは、先行トークンと幾何学的埋め込み $F_G$ に基づいて次トークンを予測するように学習されます。学習には次トークン予測 (NTP) ロスが用いられます。
$$L_{NTP} = -\sum_{t=1}^{T}\log P(s_t | s_1, s_2, \dots, s_{t-1}, F_G)$$
ここで $T$ はシーケンス長、$S = {s_1, s_2, \dots, s_T}$ です。
Skeleton Tree Tokenization
スケルトンツリーの構造をTransformerモデルに適したシーケンシャルな形式で表現するため、新規なトークン化スキームが導入されています。
-
連続座標の離散化: 正規化されたボーン座標 $[-1, 1]$ は、$D=256$ の離散トークンに量子化されます。
- 写像関数: $M : x \in [-1, 1] \mapsto d = \lfloor \frac{x+1}{2} \times D \rfloor \in \mathbb{Z}_D$
- 逆写像関数: $M^{-1} : d \in \mathbb{Z}_D \rightarrow x = \frac{2d}{D} - 1 \in [-1, 1]$
-
構造情報のエンコード:
- 特殊な「タイプ識別子」トークン(例:
<spring_bone>,<mixamo:body>)が導入され、ボーンのタイプ(春ボーン、テンプレートボーンなど)を示します。 - クラストークン
<cls>がシーケンスの先頭に追加されます。 - 一般のケースでは、Depth-First Search (DFS) アルゴリズムを用いて線形ボーンチェーンを抽出し、それらを
<branch_token>でプレフィックスします。 - 各ジョイントの子は、レストポーズにおけるそのテール座標($z, y, x$ の順)に基づいてソートされます。
- 特殊な「タイプ識別子」トークン(例:
-
デトークン化: デコードされた座標が所定の距離閾値内にあるジョイントをマージすることで、異なるボーンチェーン間の接続が確立され、完全なスケルトンツリーが再構築されます。
この最適化されたトークン化により、シーケンス長が大幅に短縮され(平均で27〜30%削減)、トレーニング時のメモリ消費量削減と推論の高速化が実現されます。
スキンウェイト予測とボーン-ポイント交差アテンション
スケルトンツリーが予測された後、メッシュ変形を司るスキニングウェイト $W \in \mathbb{R}^{N \times J}$($N$は頂点数、$J$はボーン数)と、ばね係数や重力係数といったボーン属性 $A \in \mathbb{R}^{J \times B}$ を予測します。
-
特徴抽出:
- ボーンエンコーダ $E_B$: MLPと位置エンコーディングを用いて、各ボーンのヘッド/テール座標 $(J^P, J) \in \mathbb{R}^{J \times 6}$ からボーン特徴 $F_B \in \mathbb{R}^{J \times F}$ を生成します。
- ポイント単位エンコーダ $E_P$: 事前学習済みのPoint Transformer V3(SAMPart3Dのアーキテクチャと重み)が、入力点群 $X \in \mathbb{R}^{N \times 3}$ からポイント特徴 $F_P \in \mathbb{R}^{N \times F}$ を生成します。
-
クロスアテンション機構: ボーン特徴とポイント特徴間の複雑な相互作用をモデル化します。
- ポイント特徴 $F_P$ はクエリ $Q_W$ に、ボーン特徴 $F_B$ はキー $K_W$ とバリュー $V_W$ にそれぞれ射影されます。
- アテンション重み $F_W \in \mathbb{R}^{N \times J \times H}$ は次のように計算されます: $F_W = \text{softmax}\left(\frac{Q_W K_W^T}{\sqrt{F}}\right)$。
- さらに、各頂点と各ボーン間のボクセル測地線距離 $D \in \mathbb{R}^{N \times J}$ をアテンション重み $F_W$ に連結します。
- 最終的なスキニングウェイト $W$ は、連結された特徴をMLP $E_W$ とsoftmax層に通すことで得られます。
$$W = \text{softmax}\left(E_W \left(\text{concat}\left(\text{softmax}\left(\frac{Q_W K_W^T}{\sqrt{F}}\right), D\right)\right)\right)$$ - ボーン属性 $A$ の予測では、ボーン特徴 $F_B$ をクエリに、ポイント特徴 $F_P$ をキー/バリューに逆転させてクロスアテンションを適用し、別のMLP $E_A$ で予測します: $A = E_A(\text{cross_attn}(F_B, F_P))$。
- ロス関数: 予測されたスキニングウェイトとグラウンドトゥルースの間のKullback-Leibler (KL) ダイバージェンスと、予測されたボーン属性とグラウンドトゥルースの間のL2ロスを組み合わせます: $\lambda_W L_{KL}(W, W_{pred}) + \lambda_A L_2(A, A_{pred})$。
-
スケルトン同等性に基づくトレーニング戦略: 学習の不均衡を解消するため、以下の2つの主要な変更を導入します。
- ランダムなボーンフリーズ: トレーニング中に確率 $p$ でボーンの一部をフリーズし、その勾配計算を行いません。これにより、疎な領域のボーンも学習機会を得ます。
- ボーン中心のロス正規化: ロスを全頂点平均ではなく、各ボーンが影響を与える頂点数で正規化します。
$$\frac{1}{J} \sum_{i=1}^J \frac{\sum_{k=1}^N [W_{k,i} > 0] L_2^{(k)}}{\sum_{k=1}^N [W_{k,i} > 0]}$$
ここで $J$ はボーン数、$N$ は頂点数、$L_2^{(k)}$ は$k$番目の頂点の再構築ロス、$[W_{k,i} > 0]$ は指示関数です。
-
物理シミュレーションによる間接的教師あり学習: より現実的な動きを保証するため、微分可能なVerlet積分ベースの物理シミュレーションを導入します。予測されたスキニングウェイトとボーン属性を用いてシミュレートされた頂点位置 $X^{M_{pred}}$ とグラウンドトゥルース $X^M$ の間のL2距離を再構築ロスとして追加します。
$$ \lambda_W L_{KL}(W, W_{pred}) +\lambda_A L_2(A, A_{pred}) +\lambda_X \sum_{i=1}^T L_2 (X^M_i, X^{M_{pred}}_i) $$
この総合ロス関数により、モデルは物理的に現実的な動きを生成するスキニングウェイトとボーン属性を予測するように促進されます。
実験結果
UniRigは、既存の学術的手法(RigNet、NBS、TA-Rig)や商用ツール(Meshy、Anything World、Accurig、Tripo)と比較して、ボーン予測精度(Joint-to-Joint Chamfer Distance: J2Jなど)およびスキンニングウェイト予測精度(頂点ごとのL1ロス)において大幅な改善を達成しています。特に、メッシュ変形のロバストネス(アニメーション下での再構築L2ロス)において、UniRigは春ボーンによる動的シミュレーションを含め、優れた性能を発揮します。アブレーションスタディにより、提案するトークン化戦略、物理シミュレーションに基づく間接的教師あり学習、スケルトン同等性に基づくトレーニング戦略の各コンポーネントが、モデル性能の向上に大きく寄与していることが確認されました。
応用
UniRigは、人間支援型自動リギングを可能にし、ユーザーが予測されたスケルトンツリーを編集し、変更された部分を再生成できる柔軟性を提供します。また、VRM互換モデルの生成能力により、VTubingなどのキャラクターアニメーションアプリケーションにおいて、リアルで表現豊かな春ボーンモーションを実現し、アニメーションパイプラインを効率化します。
結論
UniRigは、3Dモデルの自動リギングにおいて、統一された学習ベースのフレームワークとして画期的な進歩を遂げました。その多様なオブジェクトカテゴリへの対応能力、人間による編集との連携、そして現実的なアニメーション生成へのサポートは、3Dコンピュータグラフィックス分野の研究者と実務家の双方にとって強力なツールとなる可能性を秘めています。今後の課題としては、訓練データの質と多様性に依存する限界を克服するため、さらに広範なスケルトン構造とオブジェクトカテゴリを取り込み、より洗練された物理シミュレーション技術を統合することが挙げられます。
Q:提案手法の処理の流れを順序だてて説明してください
A:
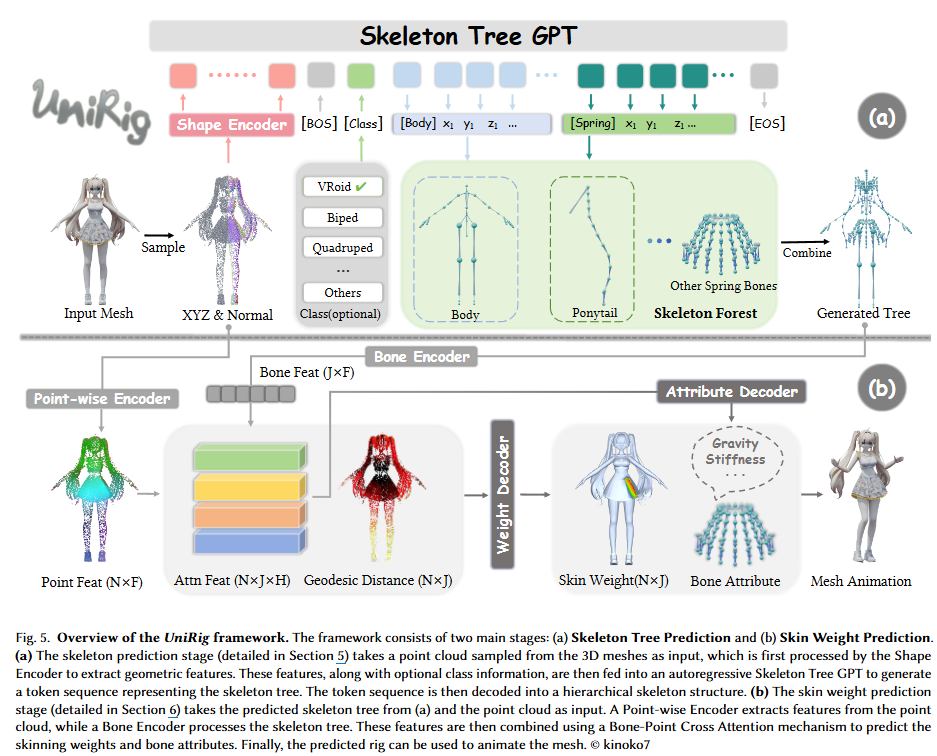
UniRigは、多様な3Dモデルに対して高精度なスケルトンとスキニングウェイトを自動的に生成する、統一された学習ベースのフレームワークです。その処理フローは、大きく分けて以下の段階で構成されます。
-
入力処理と幾何学的特徴抽出 (Input Processing and Geometric Feature Extraction)
- 3Dメッシュの点群化: まず、入力された3Dメッシュデータ(頂点と面)から、高密度な点群(例:65536点)をサンプリングします。この点群は、メッシュの幾何学的詳細と全体的な形状情報を捉えるために使用されます。各点には法線ベクトルも付与されます。
- 正規化とエンコーディング: サンプリングされた点群は、特定の座標範囲(例:$[-1, 1]^3$)に正規化されます。その後、3DShape2Vecsetフレームワークに基づいた幾何学的エンコーダー ($E_G$) を用いて、この点群から幾何学的特徴(geometric embedding $F_G$)が抽出されます。この特徴は、後続のスケルトン生成プロセスのコンテキストとして機能します。
-
自己回帰的スケルトンツリー生成 (Autoregressive Skeleton Tree Generation)
- 目的: この段階の核心は、入力メッシュに適合し、トポロジー的に有効なスケルトン構造(ジョイントの位置 $J$ と親子関係 $P$)を予測することです。
-
Skeleton Tree Tokenization: スケルトンツリーの複雑な階層構造を、Transformerベースのモデルが扱える離散的なシーケンス形式に変換するために、独自の「Skeleton Tree Tokenization」手法が用いられます。この手法では、連続的なボーン座標を離散化し、
<spring_bone>や<mixamo:body>のような特殊なタイプ識別子トークンを導入して、異なる種類のボーンシーケンス(例:スプリングボーン、テンプレートボーン)を効率的かつコンパクトに表現します。これにより、構造的な制約が明示的にエンコードされ、生成されるスケルトンのトポロジー的な妥当性が保証されます。 - 自己回帰モデルによる予測: OPTアーキテクチャ(decoder-only Transformer)に基づく自己回帰モデル(Skeleton Tree GPT)が、幾何学的埋め込み $F_G$ をコンテキストとして利用し、先行するトークンに条件付けながら、スケルトンツリーのトークンシーケンスを逐次的に予測します。
- スケルトンのデコード: 生成されたトークンシーケンスは、デトークン化プロセスを通じて、最終的な階層的なスケルトン構造に再構築されます。
-
Bone-Point Cross Attentionによるスキニングウェイト予測 (Skin Weight Prediction via Bone-Point Cross Attention)
- 目的: スケルトンツリーが予測された後、この段階では、メッシュの各頂点がどのボーンによって影響を受けるかを定義するスキニングウェイト ($W$) と、リアルな物理シミュレーションに必要なボーン属性(例:剛性、重力係数)($A$) を予測します。
- 特徴の生成: 予測されたスケルトンツリーから、各ボーンのヘッドとテールの座標をBone Encoder ($E_B$) に通し、ボーン特徴 ($F_B$) を抽出します。同時に、入力点群は、事前学習済みのPoint Transformer V3に基づくPoint-wise Encoder ($E_P$) によって、点ごとの特徴 ($F_P$) に変換されます。
- クロスアテンションメカニズム: スキニングウェイトの予測には、ボーン特徴と点ごとの特徴間の複雑な関係をモデル化するために、Bone-Point Cross Attentionメカニズムが利用されます。点ごとの特徴がクエリとなり、ボーン特徴がキーとバリューとなることで、各頂点と各ボーン間の影響度合いが計算されます。
- 測地線距離の組み込み: さらに、各頂点と各ボーン間のボクセル測地線距離 ($D$) が、空間的な近接性に関する貴重な情報としてアテンション重みに結合されます。
- ウェイトと属性の出力: 結合された特徴は、MLPを通じて最終的なスキニングウェイト(softmax正規化後)として出力されます。ボーン属性については、同様にクロスアテンションメカニズム(ボーン特徴がクエリとなる)を介して、別のMLPによって予測されます。
訓練戦略の補足:
これらの2つの主要段階は、Next Token Prediction (NTP) ロス、Kullback-Leibler (KL) ダイバージェンス、L2ロスを組み合わせた統合された損失関数によって共同で訓練されます。特に、VRoidデータセットのスプリングボーンを活用した物理シミュレーションを通じた間接的な教師あり学習は、より物理的に現実的なモーションを生成するための重要なシグナルを提供します。また、各ボーンが訓練目標に均等に貢献するよう、ランダムなボーンのフリーズやボーン中心の損失正規化といった「スケルトン等価性に基づく訓練戦略」が採用され、モデルの汎化能力とロバスト性が向上しています。
この包括的なアプローチにより、UniRigは多様な3Dモデルに対して、高精度かつアニメーションに適したリグを自動生成することを可能にします。
Q:関連手法との比較について詳しく説明してください
A:
UniRigは、既存の自動リギング手法の限界を克服するために開発された画期的なフレームワークです。その優位性は、競合する様々なアプローチと比較することでより明確になります。
1. スケルトンフリー/頂点変形ベースの手法 (例: SfPT, HMC, TapMo, ZPT) との比較
- 競合手法の概要と限界: これらの手法(Section 2.1.1, 2.1.2参照)は、明示的なスケルトン構造を持たずに、メッシュを直接変形させたり、頂点変形を予測したりします。これにより、従来の「リギング」プロセスを回避します。しかし、多くの場合、既存のモーションデータに大きく依存するため、新しい未見のモーションに対する汎化性が低いという課題があります。また、既存のアニメーション業界のパイプラインはスケルタルアニメーションに大きく依存しているため、これらの手法との互換性が低いという問題も抱えています。
- UniRigの優位性: UniRigは、スケルトンをバイパスするのではなく、高精度なスケルトンとスキニングウェイトを自動生成することで、既存の業界標準とシームレスに連携します。これにより、汎用性と既存のワークフローへの適合性を両立させています。
2. 伝統的な幾何学ベースのリギング手法 (例: Pinocchio, Voxel Cores, LazyBones) との比較
- 競合手法の概要と限界: これらの初期の手法(Section 2.2.1参照)は、メディアルサーフェスやボクセルコアのような幾何学的な特徴を利用してスケルトンを予測します。複雑なトポロジーのオブジェクトにも対応できますが、しばしば産業界のパイプラインにおいて、アニメーターによる大規模な手動調整が必要となります(例: LazyBones)。これは時間と専門知識を要するボトルネックです。
- UniRigの優位性: UniRigは、そのプロセスの「自動化レベル」において優れています(Table 1参照)。手動による微調整の必要性を大幅に削減し、リギングプロセスを迅速化します。人間によるアシスト付きリギング(Section 8.1)もサポートしますが、それは主に自動生成されたリグの微修正やカスタマイズのためであり、ゼロからの大規模な手動介入とは異なります。
3. ディープラーニングベースの自動リギング手法との比較
このカテゴリはさらに、テンプレートベースとテンプレートフリーに分けられます。
3.1 テンプレートベースの手法 (例: NBS, TaRig, SMPLベースの手法)
- 競合手法の概要と限界: これらのアプローチ(Section 2, 2.2.2参照)は、SMPLのような事前定義されたスケルトンテンプレートに依存しており、そのテンプレート内の骨の位置予測においては高い精度を達成します。しかし、特定のスケルトントポロジーに限定され、テンプレートから逸脱したモデル(例: 多様な動物、架空のキャラクター、非標準的な形状)には対応が困難です。
- UniRigの優位性: UniRigは「多カテゴリ」への対応能力に優れています(Table 1参照)。VRoidデータセット(アニメ風キャラクター)と、多様なオブジェクトカテゴリを含む大規模なRig-XLデータセット(Section 4.2)をキュレートし、訓練することで、人間型に限らず、動物、昆虫、水生生物、さらには静的なオブジェクトまで、幅広いモデルに対応できます(Figure 1, Figure 10参照)。UniRigの「Skeleton Tree Tokenization」は、テンプレートの情報を利用しつつも、より汎用的な階層構造のエンコーディングを可能にし、テンプレートに縛られない柔軟性を提供します。
3.2 テンプレートフリーの手法 (例: RigNet, MoRig, DRiVE)
- 競合手法の概要と限界: これらの手法(Section 2, 2.2.2参照)は、テンプレートに依存せずにジョイントの位置と接続性を予測するため、より柔軟性があります。しかし、しばしば結果が不安定になり、トポロジー的に不自然なスケルトン(例: 不適切な接続、断片化したボーン)を生成する可能性があります。特にRigNetは、予測されたジョイントからMinimum Spanning Tree(MST)アルゴリズムを用いてボーン接続を推論する別のステップが必要ですが、これがトポロジーエラーを招く可能性があります。
-
UniRigの優位性:
- トポロジーの正確性: UniRigは、新しく提案された「Skeleton Tree Tokenization」と「自己回帰モデル」を組み合わせることで、この大きな課題を克服します(Section 5参照)。スケルトンツリーをトポロジー的にソートされた順序で順次生成するため、トポロジー的に常に有効で、かつ構造的に整合性の取れたスケルトンが保証されます。
- 骨予測の精度: Table 3(J2J Chamfer Distance)、Supplementary Table 9(J2B, B2B Chamfer Distance)に示されるように、UniRigはRigNet、NBS、TA-Rigといった既存のSOTA学術手法と比較して、すべてのデータセットにおいてジョイント位置予測の精度が大幅に優れています。特にJ2Jでは、従来の215%の改善(Abstract参照)を達成しています。
- 視覚的品質: Figure 7およびSupplementary Figure 13の視覚的な比較でも、UniRigがより詳細で正確なスケルトンを生成していることが確認できます。
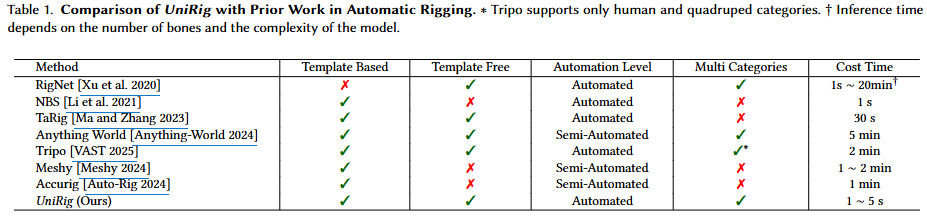
4. 商用ツール (例: Meshy, Anything World, Accurig, Tripo) との比較
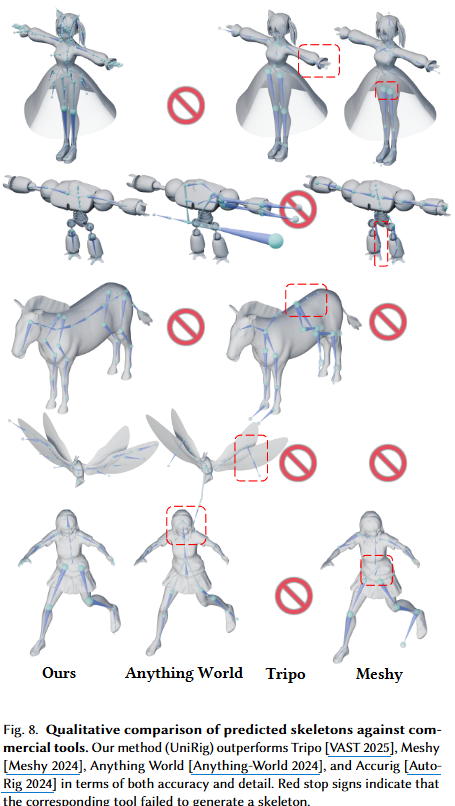
- 競合手法の概要と限界: これらの商用ツール(Table 1参照)は、ある程度の自動化を提供しますが、多くは「半自動(Semi-Automated)」であり、特定のモデルカテゴリに限定されたり、手動での介入が必要とされたりします。また、複雑なモデルや非標準的なモデルに対しては、スケルトンの生成に失敗することがあります(Figure 8の赤い停止マーク)。
-
UniRigの優位性:
- 高い自動化レベル: UniRigは完全に「自動化(Automated)」されており、より広範なカテゴリのモデルに対応します(Table 1参照)。
- 優れた精度と詳細性: Figure 8に示される質的な比較では、UniRigがこれらの商用システムと比較して、多様なメッシュタイプに対してはるかに優れた精度と、より完全なスケルトンを提供していることが分かります。
- スキニングウェイトと変形のロバスト性: Table 4(スキニングウェイトのL1ロス)およびTable 5(モーション下の再構築ロス)が示すように、UniRigはスキニングウェイトの予測精度、および予測されたリグによるメッシュ変形のロバスト性においても、他の学術手法や商用ツールを凌駕しています。特に、スプリングボーンによる動的なシミュレーション(Figure 9, Figure 6)においても、よりリアルな変形を生成する能力を示しています。
まとめ
UniRigは、大規模なデータセット(Rig-XL)と革新的な「Skeleton Tree Tokenization」、そして自己回帰モデルおよびBone-Point Cross Attentionを組み合わせることで、既存手法が抱えていた「多様性への対応不足」「トポロジー的制約の欠如」「精度と安定性の課題」「手動介入の必要性」といった主要な課題を包括的に解決しています。これにより、単にスケルトンとウェイトを生成するだけでなく、アニメーションの汎用性と品質を大幅に向上させることを可能にしました。
この分析を通じて、UniRigが3Dコンテンツ制作のボトルネックであるリギングプロセスを、より効率的かつ高品質に自動化するための重要な一歩であることを深く理解できるかと思います。
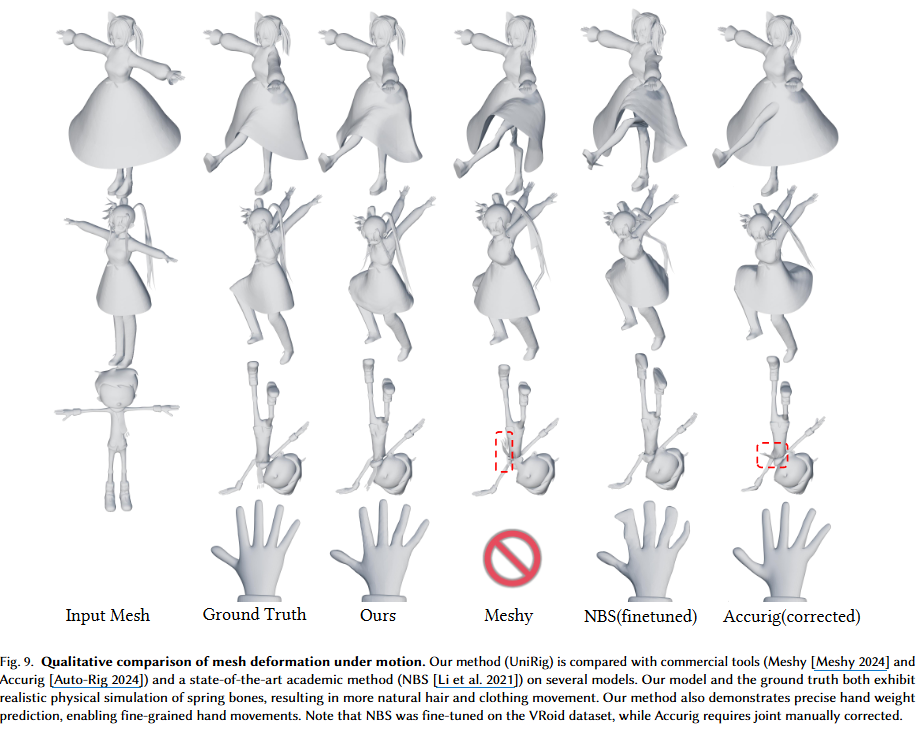
Q:提案手法の限界と今後の課題はなんですか?
A:
UniRigは、その画期的な性能にもかかわらず、他の学習ベースの手法と同様にいくつかの限界を抱えており、それらが今後の研究の方向性を示しています。
提案手法の限界 (Limitations)
-
訓練データへの依存性:
- 課題: UniRigは学習ベースの手法であるため、その性能は訓練データの質と多様性に本質的に依存します。論文中で言及されているように、Rig-XLは大規模で多様なデータセットですが、現実世界に存在するあらゆるスケルトン構造やオブジェクトカテゴリを完全に網羅しているわけではありません。
- 具体例: 訓練データから大きく逸脱したオブジェクト、例えば、抽象的あるいは非常に様式化されたキャラクターに見られるような「非常に珍しいスケルトン構造」に対しては、UniRigの性能が最適ではない可能性があります。これは、未知のトポロジーや形状パターンに直面した場合に、予測の精度が低下する可能性を示唆しています。
今後の課題・方向性 (Future Work)
論文では、上記の限界を克服し、UniRigの能力をさらに拡張するためのいくつかの明確な方向性が示されています。
-
ユーザー編集の活用とデータセットの継続的な拡張:
- 方向性: セクション8.1で述べられているように、人間によるアシスト付きリギングの過程でユーザーが行う修正(例:ボーンの追加・削除、位置の調整)は、モデルをさらに洗練させるための非常に価値あるデータソースとなります。
- インパクト: ユーザーからのフィードバックをUniRigの訓練データセットに継続的に組み込むことで、モデルのロバスト性と汎化能力を絶えず改善していくことが可能になります。これは、実用的なツールとしての価値を高めるだけでなく、より広範で「珍しい」オブジェクトへの対応力を高めることにも繋がります。
-
異なるモダリティ(画像や動画)の入力としての探索:
- 方向性: 現在のUniRigは3Dメッシュからの点群を入力としていますが、将来的には、画像や動画など、異なるモダリティをリギングプロセスの入力として探索することが考えられます。
- インパクト: これにより、リギングの適用範囲が飛躍的に広がる可能性があります。例えば、単一の静止画像や動画クリップから直接キャラクターをリギングできるようになれば、3Dモデルが手元にないユーザーでも容易にキャラクターアニメーションを生成できるようになり、コンテンツ制作の民主化に大きく貢献するでしょう。
-
より洗練された物理シミュレーション技術の統合:
- 方向性: UniRigは既にVerlet積分に基づくスプリングボーンシミュレーションを導入し、アニメーションのリアルさを向上させていますが、さらに高度な物理シミュレーション技術を組み込むことで、生成されるアニメーションのリアルさを一層高めることができます。
- インパクト: 例えば、複雑な布のダイナミクス、剛体衝突、より多様な物理特性(例:弾性、摩擦)のモデリングなどが考えられます。これにより、キャラクターの動きだけでなく、髪や衣服、アクセサリーなどの付随する要素の挙動も、一層自然で説得力のあるものになるでしょう。これは、特にVTuberやVR/ARアプリケーションなど、高品質なリアルタイムキャラクターアニメーションが求められる分野で大きな価値を発揮します。
これらの限界と今後の方向性は、UniRigが既に達成した進歩の上に、さらに汎用性、リアルタイム性、そして現実感を追求し続けるという、研究の飽くなき探求心を示しています。
Q:関連研究の中で特に重要なものを3つ挙げてください
A:
UniRigの関連研究の中で、特に重要とみられるものを3つ挙げ、その重要性とUniRigとの関係を説明します。
1. RigNet: Neural Rigging for Articulated Characters [Xu et al. 2020]
- 重要性: RigNetは、ディープラーニングを用いた自動リギングの分野における先駆的な研究の一つです。従来の幾何学ベースの手法とは異なり、アニメーションキャラクターのデータからジョイントのヒートマップを予測し、Minimum Spanning Tree(MST)アルゴリズムを用いてジョイントを接続することで、様々なオブジェクトに対する自動スケルタルリギングを実現しました。テンプレートに依存しないアプローチであるため、幅広いオブジェクトカテゴリへの適用可能性を示しました。
- UniRigとの関係: UniRigにとって、RigNetは最も重要な比較対象であり、直接的な競合研究の一つです。UniRigは、RigNetが抱えていた「ジョイントからボーン接続を推論する際にトポロジーエラーを導入する可能性がある」という課題を、「Skeleton Tree Tokenization」と自己回帰モデルによって克服しています。これにより、UniRigはRigNetよりもはるかに高精度で、トポロジー的に妥当なスケルトンを生成できることを、論文中の多くの定量評価(Table 3, 4, 9, 10)や質的比較(Figure 7, 13, 14)で示しています。
2. Learning Skeletal Articulations with Neural Blend Shapes (NBS) [Li et al. 2021]
- 重要性: NBSは、従来のLinear Blend Skinning (LBS) システムでよく見られるアーティファクト(不自然な変形)に対処するため、残差変形ブランチを導入してジョイント領域の変形品質を向上させた点で重要です。スキニングウェイトの予測にも焦点を当てています。しかし、テンプレートベースのアプローチであるため、特定のスケルトントポロジー(主に人間型)に限定されるという側面があります。
- UniRigとの関係: NBSもまた、UniRigの主要な比較対象の一つです。UniRigは、NBSが主にテンプレートベースであることに対し、より多様なスケルトン構造に対応できる汎用性を持っています。また、スキニングウェイトの予測精度においても、UniRigはNBSを大きく上回る結果を示しています(Table 4)。さらに、UniRigはNBSのように変形品質を改善するだけでなく、スプリングボーンの物理シミュレーションを統合することで、よりダイナミックでリアルなキャラクターアニメーションを実現しています(Table 5, Figure 9)。
3. MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers [Siddiqui et al. 2024]
- 重要性: MeshGPTは、3Dオブジェクトのメッシュ生成において、Transformerのデコーダーオンリーアーキテクチャとトークン化手法を用いることで、高品質なメッシュを生成できることを示した非常に新しい研究です。これは、3D形状を離散的なトークンシーケンスとして表現し、それを自己回帰的に生成するという、より広範な3D生成モデルのトレンドを代表するものです。
- UniRigとの関係: UniRigは、その「Skeleton Tree Tokenization」手法と自己回帰的なスケルトン生成アプローチにおいて、MeshGPTを含む最近の3D生成モデルの研究からインスピレーションを受けていることを明記しています(Section 5, Section 7.3.1)。MeshGPTがメッシュ全体をトークン化して生成するのと同様に、UniRigはスケルトンの階層構造を効率的なトークンシーケンスに変換し、Transformerを用いて予測します。この技術的な共通性は、UniRigが単なるリギング手法の改善にとどまらず、より汎用的な3D構造生成の最先端技術を取り入れていることを示しており、その技術的革新性を裏付けています。
これらの3つの研究は、それぞれ「自動リギングの柔軟性(RigNet)」「スキニング品質とテンプレート適用(NBS)」「3D構造生成の新しいパラダイム(MeshGPT)」という異なる側面から、UniRigの独自性と優位性を際立たせる上で非常に重要です。
Q:そもそもrigってなんですか?3DCGの知識がほとんどない人にもわかるように説明してください
A:
かしこまりました。3DCGの知識がほとんどない方にも「リグ(rig)」が何であるか、そしてなぜそれが重要なのかを、アニメーションを例にとって説明しますね。
「リグ(Rig)」ってなあに?
想像してみてください。あなたが粘土でかわいいキャラクターを作りました。このキャラクターを歩かせたり、ジャンプさせたり、手を振ったりさせたいとします。でも、粘土のままでは、どこをどう動かせば良いか分かりませんし、関節の繋がりも表現できませんよね?
ここで登場するのが「リグ(Rig)」です。
「リグ」とは、3Dのコンピューターグラフィックスの世界で、キャラクターや生き物(例えば人間、動物、ロボットなど)を動かすための「骨組み」と「操作装置」をまとめたものです。
もう少し具体的に言うと…
-
「骨(ボーン)」の設置:
- あなたの粘土キャラクターに、実際の生き物のように「骨」を入れます。腕の骨、脚の骨、指の骨、背骨、頭の骨など、キャラクターの動きに必要な関節の数だけ骨を配置します。
- これらの骨は、親と子の関係(例えば、腕の骨の先には手の骨が繋がっている、といった階層構造)を持っています。
-
「肉(メッシュ)」と「骨」の結びつけ(スキニング・ウェイト):
- 骨を入れただけでは、まだ粘土の「肉」は骨に付いていません。次に、キャラクターの見た目(3Dモデルの表面、これを「メッシュ」と呼びます)を、この骨組みに「結びつけ」ます。
- この結びつけ方を「スキニング(Skinning)」と呼びます。特に重要なのは「スキニングウェイト(Skinning Weight)」という考え方です。
- これは、「この部分のメッシュ(肉)は、どの骨にどれくらいの強さで引っ張られるか」という影響度合いを設定することです。例えば、肘の周りのメッシュは、上腕の骨と前腕の骨の両方に少しずつ影響される、といった具合です。これにより、関節を曲げたときに肉が自然に変形するようになります。
-
「操作装置(コントローラー)」の追加:
- 実際の骨は体の内側にあって直接触れませんよね?それと同じで、3Dの骨も直接マウスで動かすのは大変です。そこで、キャラクターの周りに「コントローラー」と呼ばれる目に見えるアイコンやハンドルを設置します。
- アニメーター(キャラクターを動かす人)は、このコントローラーを動かすだけで、裏側で繋がっている骨が動き、その結果キャラクター全体が動くようになります。例えば、キャラクターの「手首」のコントローラーを動かせば、腕全体の骨が連動して動くように設定できます。
なぜリグが重要なのでしょうか?
- アニメーションの効率化: リグがなければ、キャラクターを動かすたびに、何千、何万という頂点(メッシュを構成する点)を一つ一つ手で動かさなければなりません。これはとてつもない手間です。リグがあれば、数個のコントローラーを操作するだけで、複雑な動きを簡単に作れるようになります。
- 自然な動きの再現: スキニングウェイトのおかげで、キャラクターの関節が曲がったときに、皮膚や筋肉が自然に伸び縮みしたり、たるんだりするような、リアルな変形を再現できます。
- 再利用性: 一度リグを作ってしまえば、同じキャラクターに異なるアニメーションを何度でも適用したり、他のアニメーションソフトに持ち込んだりすることができます。
まとめると、「リグ」とは、3Dキャラクターに命を吹き込み、アニメーションを可能にするための「隠れた構造」と「操作インターフェース」の総称なんです。
UniRigは、この「骨組みの設置」と「肉と骨の結びつけ」という、手作業だと非常に時間と技術が必要なプロセスを、コンピューターが自動で行ってくれる画期的な技術だということですね。