MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation(Xing, 2025)

3行要約
- 🎥 本論文は、画像から動画を生成する際に、カメラとオブジェクトの動きを正確に制御してシネマティックなショットをデザインする手法を提案しています。
- ⚙️ MotionCanvasは、ユーザーが3Dシーン空間で意図した動き(カメラパス、オブジェクトのバウンディングボックス、点追跡)を、高価な3D学習データなしで2Dスクリーン空間の制御信号に変換し、ビデオ拡散モデルに適用します。
- ✨ 本手法は、ユーザーの動きの意図を忠実に反映した、多様で高品質な動画生成を可能にし、既存の手法と比較して優れた性能を示します。
Q:この論文の概要を教えてください
A:
本論文は、Image-to-Video(I2V)生成の文脈において、ユーザーがシネマティックなショットデザインを行うための手法である「MotionCanvas」を提案しています。映画制作におけるショットデザインは、カメラの動きとオブジェクトの動きの両方を綿密に計画する重要な側面ですが、現代のI2V生成システムでは、ユーザーのモーションデザイン意図を効果的に捉え、それをビデオ拡散モデルが利用可能なモーション情報として表現することに課題がありました。特に、カメラの動きとシーン空間におけるオブジェクトの動きが密接に絡み合っているため、ユーザーの曖昧な入力を正確に解釈することが困難でした。
既存のI2Vモデルはテキスト入力に大きく依存しており、モーションの複雑な詳細を捉えるには不十分でした。また、先行研究にはカメラモーションやオブジェクトモーションの制御を試みたものもありますが、3D空間におけるカメラとオブジェクトの相互作用を完全には扱えず、ユーザー意図の解釈に曖昧さが残るという問題がありました。例えば、キャラクターの腕をドラッグする動作が、カメラのパン、キャラクター全体の移動、あるいは単に腕の動きのいずれを意味するのかが不明確でした。従来の3D関連のトレーニングデータに依存する方法は、ラベル付けが労力を要し、データの多様性と量に限界があるという問題も抱えていました。
MotionCanvasは、古典的なコンピューターグラフィックスの知見と現代のビデオ生成技術を組み合わせることで、高価な3Dトレーニングデータを必要とせずに、3D認識型のモーション制御をI2V合成で実現します。本手法は、ユーザーがシーン空間でのモーション意図を直感的に表現し、それをビデオ拡散モデルのための時空間モーション条件付け信号に変換します。
MotionCanvasは、以下の3つの主要コンポーネントで構成されます。
-
モーションデザインモジュール (Motion Design Module):
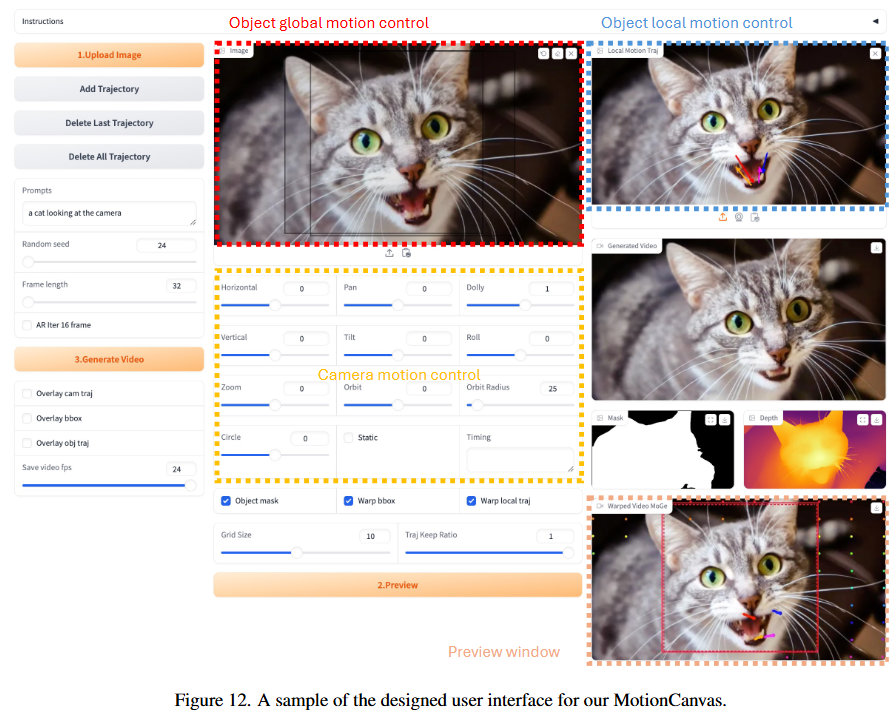
- ユーザーが入力画像キャンバス上でモーションデザインを行うためのインターフェースを提供します。
- カメラモーション制御: 標準的なピンホールカメラパラメータ $E_l \in \mathbb{R}^{3 \times 4}$ と $K_l \in \mathbb{R}^{3 \times 3}$ を用いて3Dカメラパスを定義します。ユーザーは、M個の基本モーションパターン(パン、ドリー、ズームなど)の方向と速度を指定することで、カメラパスを直感的に設計できます。
- オブジェクトグローバルモーション制御: シーンに固定されたバウンディングボックスを用いて定義されます。ユーザーは、開始、終了、およびオプションの中間キーボックスを入力画像上に配置し、位置、スケール、形状を調整することで、3Dシーン内のオブジェクトの位置、スケール、ポーズ、カメラからの相対距離をシーン認識型で制御できます。提供されたキー位置と出力ビデオの期間から、Catmull-Romスプライン補間によりスムーズなバウンディングボックス軌道が生成されます。
- オブジェクトローカルモーション制御: ドラッグベースの編集にインスパイアされ、スパースなポイントトラジェクトリを用いてオブジェクト内の局所的な動き(腕を上げる、頭を回転させるなど)を表現します。
- タイミング制御: オブジェクトとカメラの動きに直接タイムラインを割り当てることで、ナラティブの連携を可能にします。
-
モーション信号変換モジュール (Motion Signal Translation Module):
- ユーザーが3Dシーン中心で設計したモーション意図を、ビデオ生成モデルが効率的に学習できる2Dスクリーン空間のフレーム中心データに変換するモジュールです。
- カメラムーブメントのポイントトラッキングによる表現: カメラの動きは、画像平面に投影されたシーンポイントのスパースなトラッキングセットとして表現されます。これは、人間の視覚認知における自己中心的な動きの回復に着想を得たものです。推論時には、入力画像上の静的背景からランダムにポイントをサンプリングし(YOLOv11で推定された移動オブジェクト領域は除外)、オフザシェルフの単眼深度推定器からカメラの内部パラメータと深度マップを取得します。最後に、これらのポイントを3Dカメラパスと深度に基づいてワープし、対応する2Dスクリーン空間トラッキングを生成します。
-
シーン認識型オブジェクトモーションのバウンディングボックス軌道による表現: ユーザー定義のシーン空間バウンディングボックス軌道は、カメラの動きと遠近法によって歪められるため、これを実際のビデオから抽出されるオブジェクトバウンディングボックスシーケンスに似た方法でスクリーン空間に変換します。まず、初期バウンディングボックスのSAM2で生成されたセマンティックマスク内の平均深度を用いて、シーン空間バウンディングボックスを2.5Dにリフトアップします。その後のバウンディングボックスは、シーン内の参照深度、または透視整合性(拡大するバウンディングボックスはカメラへの接近を示す)に基づいて深度が割り当てられます。割り当てられた深度とカメラポーズ変換を用いて、時刻 $l$ における2.5Dバウンディングボックス $b^l_{\text{scene}}$ は、調整された位置とサイズを持つスクリーン空間 $b^l_{\text{screen}}$ に次のように投影されます。
$$b^l_{\text{screen}} = T^l_{\text{camera}}(b^l_{\text{scene}})$$
ここで $T^l_{\text{camera}}(\cdot)$ はカメラモーション変換を表します。 -
オブジェクトローカルモーションのポイントトラジェクトリ分解による表現: シーンに固定された制御点 $p^l_{\text{scene}}$(対応するオブジェクトバウンディングボックスの深度を用いてシーン空間にリフトアップ)を対応するスクリーン空間 $p^l_{\text{screen}}$ に変換します。この変換は、カメラモーションとグローバルモーションの両方を考慮します。
$$p^l_{\text{screen}} = T^l_{\text{camera}}(T^l_{\text{global}}(p^l_{\text{scene}}))$$
ここで $T^l_{\text{global}}(\cdot)$ はオブジェクトのグローバルモーション変換を表します。局所モーション中の深度変化は、グローバルモーションに比べて無視できるほど小さいという仮定を置きます。
-
モーション条件付きビデオ生成モデル (Motion-conditioned Video Generation Model):
- 事前に学習されたDiffusion Transformer(DiT)ベースのI2Vモデルを基盤とし、スクリーン空間のモーション条件でファインチューニングを行います。
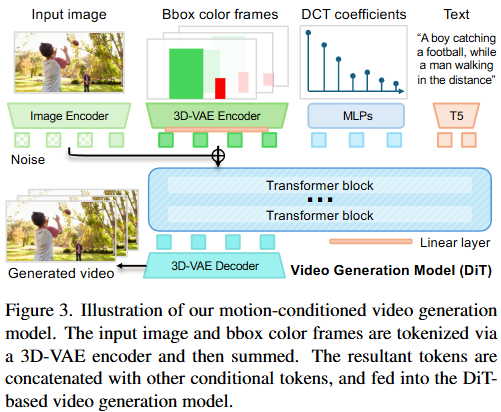
- ポイントトラジェクトリ条件付け: N個のポイントトラジェクトリは、それぞれ離散コサイン変換(DCT)係数のコンパクトなセットに符号化されます。実験では $K=10$ 個の係数を使用し、DC成分は初期位置を符号化します。このコンパクトな表現 $C_{\text{traj}} \in \mathbb{R}^{N \times K \times 2}$ は、モーションデータの処理を簡素化し、効率を向上させます。各トラジェクトリは個別のトークンとして扱われ、その埋め込みはDCT係数から導出されます。
- バウンディングボックスシーケンス条件付け: バウンディングボックスシーケンスは、ユニークな色分けマスクにラスタライズされ、RGBシーケンス $C^{\text{RGB}}_{\text{bbox}} \in \mathbb{R}^{L \times H \times W \times 3}$ を形成します。このシーケンスは、ベースDiTモデルと同じ事前学習済みビデオオートエンコーダ(3D-VAE)を用いて時空間埋め込み $C_{\text{bbox}} \in \mathbb{R}^{L' \times H' \times W' \times C}$ にエンコードされ、パッチ化されてノイズビデオ潜在トークンに追加されます。
-
モデル学習: 潜在拡散モデルとして、フローマッチング損失を用いて最適化されます。グラウンドトゥルースビデオ潜在を $X_1$、ノイズを $X_0 \sim \mathcal{N}(0, 1)$ とすると、時刻 $t$ におけるノイズ入力は線形補間 $X_t = tX_1 + (1 - t)X_0$ で生成されます。モデル $v_{\theta}$ は速度 $V^t = \frac{d}{dt} X_t = X_1 - X_0$ を予測します。訓練目的は以下の通りです。
$$\min_{\theta} \mathbb{E}_{t,X_0,X_1} |V^t - v_{\theta} (X_t, t | C_{\text{img}}, C_{\text{traj}}, C_{\text{bbox}}, C_{\text{txt}}) |_2^2$$
ここで $C_{\text{img}}, C_{\text{traj}}, C_{\text{bbox}}, C_{\text{txt}}$ はそれぞれ入力画像、ポイントトラジェクトリ、バウンディングボックス、テキストプロンプトを表します。 - 可変長ビデオ生成: オートレグレッシブ生成を通じて、シネマティックなストーリーテリングのための可変長ビデオを生成します。16フレームの短いビデオクリップ $C_{\text{vid}}$ を追加条件としてMotionCanvasARを学習することで、先行する時空間コンテキストに基づいて各生成ステップを条件付け、自然な遷移を実現します。推論時には、ユーザーの意図とバックトレースされたモーションを組み合わせてスクリーン空間モーション信号を再計算し、よりスムーズで一貫性のあるモーション生成を保証します。
MotionCanvasは、カメラとオブジェクトの動きをシーン認識型で制御し、シネマティックなショットデザインを可能にするだけでなく、モーション転送やビデオ編集といった応用も実現します。実験では、提案手法が既存のカメラモーション制御やオブジェクトモーション制御の手法を、定量的・定性的に上回ることを示しました。特に、カメラポーズラベルに依存しない広範なビデオデータセットでの学習により、多様なモーション生成において優れた汎化能力を発揮します。ユーザー調査でも、モーションの忠実性、モーション品質、フレーム品質のすべての側面で競合手法を上回る結果が得られました。アブレーションスタディにより、提案されたカメラモーション表現(DCT係数ベースのトラジェクトリエンコーディング)とバウンディングボックス条件付けの有効性が確認されました。
本研究の限界としては、現在のビデオ拡散モデルに起因する比較的遅い推論時間、オブジェクト内深度変化の近似、モーションデザインとテキストプロンプト間の明示的な調和メカニズムの欠如が挙げられます。これらの課題は、今後の研究の方向性を示唆しています。

Q:提案手法の処理の流れを順序だてて説明してください
A:
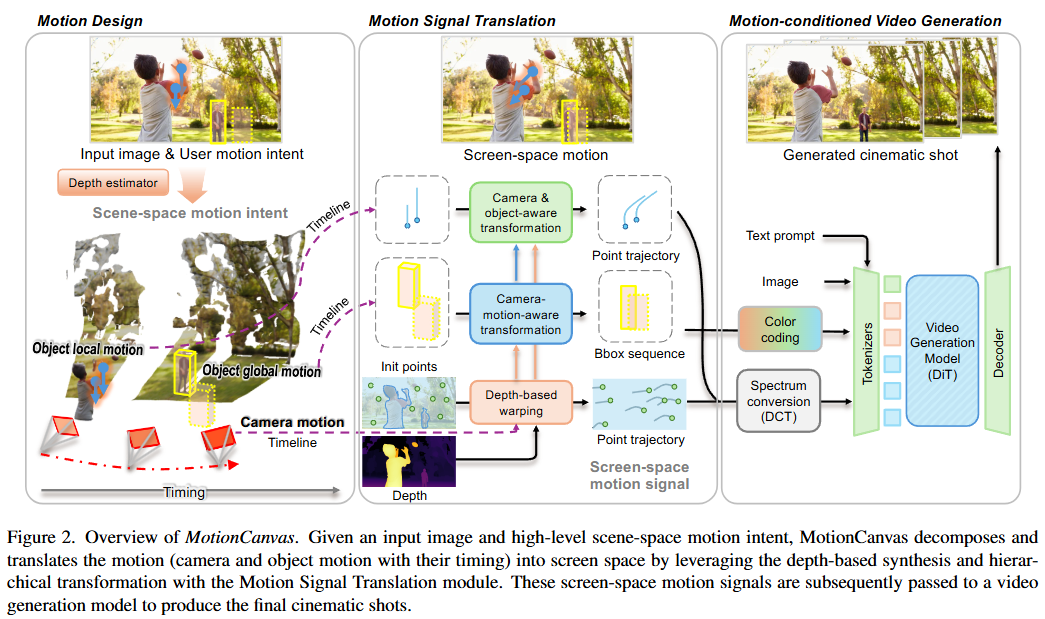
MotionCanvasの処理フローは、静止画像からユーザーの意図したモーションを持つ映画のようなビデオショットを生成するために、以下の3つの主要なモジュールが連携して動作します。
-
モーションデザインモジュール (Motion Design Module) – ユーザーの意図の取得
- 入力: 静止画像を「キャンバス」として使用し、ユーザーはここにモーションデザインの意図を描き込みます。
- カメラモーション制御: ユーザーは、パン、ドリー、ズームなどの事前に定義されたM種類の基本モーションパターンを組み合わせて、3Dカメラパスを指定できます。これにより、カメラの動きの方向や速度を直感的に設定します。
- オブジェクトのグローバルモーション制御: シーンに固定されたバウンディングボックス (bounding box) を開始点、終了点、およびオプションの中間点として入力画像上に配置することで、オブジェクトの全体的な動き(位置、スケール、ポーズ、カメラからの相対距離)を定義します。これらのキーボックスからCatmull-Romスプライン補間により滑らかなバウンディングボックスの軌跡が生成されます。
- オブジェクトのローカルモーション制御: ドラッグベースの編集に触発され、オブジェクトの特定部分の動き(例:腕を上げる、頭を回転させる)を表現するために、スパースな点軌跡 (point trajectory) を使用します。
- タイミング制御: カメラモーションとオブジェクトモーションの両方にタイムラインを割り当て、動きの同期と物語の流れを調整します。
- 出力: ユーザーが3Dシーン空間で意図したモーションデザイン(カメラパス、シーン固定のバウンディングボックス軌跡、シーン固定の点軌跡、およびそれらのタイミング)が生成されます。
-
モーションシグナル変換モジュール (Motion Signal Translation Module)
- 目的: ユーザーが3Dシーン空間で設計したモーション意図を、ビデオ生成モデルが効率的に利用できる2Dスクリーン空間のモーションシグナルに変換します。
- カメラモーションの変換: ユーザーが指定した3Dカメラパスを、2Dの点追跡 (point tracking) に変換します。これは、入力画像上の静的な背景ポイントをランダムにサンプリングし、単眼深度推定器 (monocular depth estimator) で得られた深度マップとカメラパラメータを用いて、3Dカメラパスに基づいて2Dスクリーン空間のトラックにワープ (warp) することで実現されます。
- シーン認識オブジェクトモーションの変換: ユーザーが定義したシーン固定のバウンディングボックス軌跡を、カメラの動きと遠近法による歪みを考慮して2.5Dに持ち上げ、各フレームでスクリーン空間に再投影します。これにより、実際のビデオから抽出されるようなオブジェクトのバウンディングボックスシーケンスを生成します。
- オブジェクトローカルモーションの分解と変換: シーン固定のコントロールポイント(オブジェクトのローカルモーション用)を、カメラモーションとオブジェクトのグローバルモーションの両方を考慮してスクリーン空間に変換します。ローカルモーション中の深度変化は無視できると仮定し、変換を簡素化します。
- 出力: 空間的・時間的に調整されたスクリーン空間モーションシグナル(カメラとローカルモーション用の2D点軌跡、グローバルオブジェクトモーション用の2Dバウンディングボックスシーケンス)が生成されます。
-
モーション条件付きビデオ生成 (Motion-conditioned Video Generation)
- モデル: 事前学習済みのDiTベースの画像-ビデオ生成モデルを、上記のスクリーン空間モーションシグナルでファインチューニング (fine-tuning) して構築されます。
- 点軌跡の条件付け: 各点軌跡(カメラの動きとローカルオブジェクトモーション)を、離散コサイン変換 (Discrete Cosine Transform: DCT) 係数のコンパクトなセットとして符号化します。これにより、各軌跡が個別のトークンとしてDiTフレームワークに統合されます。
- バウンディングボックスシーケンスの条件付け: バウンディングボックスシーケンス(グローバルオブジェクトモーション)を独自のカラーコード化されたマスクにラスタライズし、RGBシーケンスを生成します。このシーケンスは、ベースDiTモデルの3D-VAEエンコーダを使用して空間的・時間的埋め込み (spatiotemporal embeddings) に変換され、ノイズのあるビデオ潜在トークンに追加されます。
- トレーニング: Flow-matching lossを用いてモデルを最適化します。テキスト条件も保持され、ビデオコンテンツの制御に柔軟性を提供します。
- 出力: クリーンなビデオ潜在トークンが生成され、その後RGBフレームにデコードされて、最終的な映画のようなショット(ビデオ)が生成されます。
さらに、MotionCanvasは可変長ビデオの自動回帰生成 (Auto-regressive generation for variable-length videos) もサポートしており、ユーザーの意図とバックトレースされたモーションを組み合わせることで、より滑らかで一貫性のある長尺ビデオを生成することが可能です。
Q:関連手法との比較について詳しく説明してください
A:
MotionCanvasは、Image-to-Video (I2V) 生成におけるモーション制御の課題を解決するため、既存の関連手法と比較して複数の点で優位性を示しています。主な比較ポイントとMotionCanvasの強みについて詳しく説明します。
1. カメラモーション制御に関する比較
関連手法:
- MotionCtrl [46]: ビデオ拡散モデルにカメラとオブジェクトのモーション制御を組み込もうとしましたが、カメラとオブジェクトの動きが絡み合う性質を完全には扱えず、ユーザーの曖昧な意図を解釈するのに苦労していました。
- CameraCtrl [15]: Explicitな3Dカメラパラメータを用いてカメラモーション制御を提供しますが、トレーニングデータセットが主に静的なシーンやキュレーションされたドメインに限定されており、生成できるオブジェクトモーションが少なく、汎用性に欠けるという課題がありました。また、両者とも3Dカメラポーズラベル付きデータセット (RealEstate10Kなど) で訓練されています。
MotionCanvasの優位性:
- 定量的評価: RealEstate10KテストセットにおけるRotErr. (回転誤差), TransErr. (並進誤差), CamMC (カメラモーションコントロール精度), FVD (Fréchet Video Distance), FID (Fréchet Inception Distance) の全指標において、MotionCanvasはMotionCtrlとCameraCtrlを上回る性能を示しました(表1参照)。特筆すべきは、MotionCanvasが「Zero-shot」設定、つまりRealEstate10Kのトレーニングデータで事前に訓練されていないにもかかわらず、これらの既存手法を凌駕している点です。
- 定性評価: Fig. 8に示すように、MotionCanvasはDolly-Zoomのようなより高度な映画的なショットタイプを、既存手法では困難なレベルで正確に生成できます。既存手法の生成品質が低いのは、3Dカメラポーズラベル付きの多様性に欠ける静的シーンのデータセットに依存しているためと指摘されています。MotionCanvasは内因性パラメータの制御も可能で、より高度なショットデザインを可能にします。
MotionCanvasの背景にある強み:
- MotionCanvasは、高価で労働集約的な3Dラベル付きトレーニングデータに依存せず、2Dバウンディングボックスや2D点軌跡といった自動的かつ信頼性の高い推定が可能な2D信号のみで訓練されています。これにより、多様な種類のビデオデータを利用でき、生成の多様性を高めています。
- 「Motion Signal Translationモジュール」が、ユーザーの3Dシーン空間でのモーション意図を、ビデオ生成モデルが効率的に利用できる2Dスクリーン空間の制御信号に効果的に変換します。
2. 3D-Awareオブジェクトモーション制御に関する比較
関連手法:
- Bounding Box Control [20, 22, 28, 43]: オブジェクトの位置から始まる一連のバウンディングボックスを描くことでモーションを制御しますが、カメラモーションの制御がないため、バウンディングボックスの動きがオブジェクトの動きなのか、シーン全体の動きなのか曖昧さがありました。
-
Point Trajectory Control [31, 33, 36, 46, 49]: ドラッグベースのモーション制御を点軌跡で行いますが、3D-awareなオブジェクトモーションを考慮できず、限定された数の軌跡に制限されることが多かったです。特に、
- DragAnything [49]: ドラッグベースの編集に特化。
- MOFA-Video [33]: ドラッグベースの編集に特化。
- TrackDiffusion [22]: ドラッグベースの編集に特化。
MotionCanvasの優位性:
- 定量的評価: VIPSegの検証セットにおけるObjMC (オブジェクトモーションコントロール精度) とFIDの指標において、MotionCanvasはDragAnything、MOFA-Video、TrackDiffusionといった他のベースラインを上回る性能を示しました(表2参照)。これは、制御の正確性とフレーム品質の両方で優れていることを意味します。
- 定性評価: Fig. 9に示すように、DragAnythingやMOFA-Videoは明示的なワーピング (warping) によってオブジェクトの歪みを生じさせる傾向があります。TrackDiffusionはユークリッド座標に依存しているため、収束が困難で不正確さにつながります。これに対し、MotionCanvasはバウンディングボックスに空間的・時間的表現を組み込むことで、位置、サイズ、ポーズといったオブジェクトモーションを精密に制御できます。
- 3D-awareな制御: 既存の多くの手法が3D訓練データを欠いているためにシーン認識型のオブジェクト制御ができないのに対し、MotionCanvasは2D信号のみで訓練されつつ、深度ベースの合成を通じて3D-awareな制御を可能にしています。
3. ジョイントなカメラとオブジェクトのモーション制御に関する比較
これはMotionCanvasの最も重要な独自性と強みです。
関連手法の課題:
- 上述の通り、既存のほとんどの手法は、カメラモーション制御に特化しているか、オブジェクトモーション制御に特化しているかのどちらかであり、これらを統一されたフレームワークで同時に、かつ3D-awareな方法で制御できるものはありませんでした。特に、オブジェクトとカメラの動きが相互に影響し合う複雑なシナリオでの制御は困難でした。
MotionCanvasの優位性:
-
ユーザー調査: 35名の参加者によるユーザー調査(表3参照)では、MotionCanvasはDragAnythingとMOFA-Videoと比較して、モーションの忠実度 (Motion Adherence)、モーション品質 (Motion Quality)、フレーム忠実度 (Frame Fidelity) の全ての側面で一貫して高い評価を受けました。
- Motion Adherence (モーション忠実度): MotionCanvas (75.24%) vs. DragAnything (14.29%) / MOFA-Video (10.48%)
- Motion Quality (モーション品質): MotionCanvas (79.05%) vs. DragAnything (10.10%) / MOFA-Video (10.86%)
- Frame Fidelity (フレーム忠実度): MotionCanvas (77.14%) vs. DragAnything (9.90%) / MOFA-Video (12.95%)
- 定性評価: Fig. 10に示すように、既存のベースラインは、複雑なオブジェクトのグローバルモーション(身体の動き)、ローカルモーション(腕を下ろすなど)、およびカメラモーションを3D-awareな方法で同時に捉えることができませんでした。MotionCanvasは、その統一されたフレームワークとモーション表現のデザインにより、これらすべての種類の制御に従うモーションを生成できます。
- Motion Signal Translationモジュールの重要性: Fig. 13の「カメラ認識型変換 (Camera-aware transformation)」や「カメラ-オブジェクト認識型変換 (Camera-object-aware transformation)」の図は、このモジュールがいかにカメラとオブジェクトの動きの相互作用を正確に反映し、自然な結果を生み出す上で不可欠であるかを示しています。
まとめ
MotionCanvasは、以下の核心的な貢献によって既存手法を凌駕しています。
- 統一されたフレームワーク: カメラとオブジェクトの動きを単一のシステム内で、シーン認識型 (scene-aware) に、かつ3D-awareな方法で統合的に制御できる。
- 革新的なモーション表現と変換: ユーザーの3Dシーン空間での意図を、ビデオ拡散モデルが訓練される2Dスクリーン空間の信号に、Motion Signal Translationモジュールを介して効果的に変換する。これにより、高価な3Dアノテーション付きトレーニングデータなしに、汎用的な2Dビデオデータから学習することを可能にしている。
- 優れた生成品質と制御精度: 定量・定性評価、特にユーザー調査において、主要な競合手法を圧倒的に上回る性能を示している。
これらの特徴により、MotionCanvasは映画的なショットデザインにおけるクリエイティブなワークフローを大幅に強化し、多様なImage-to-Video編集アプリケーションに適応できる可能性を秘めています。
Q:提案手法の限界と今後の課題はなんですか?
A:
MotionCanvasはImage-to-Video生成において画期的な進歩を遂げた一方で、研究論文の「Limitations and Future Work」セクションで言及されているように、いくつかの限界と今後の課題が存在します。これらは、今後の研究の方向性を示す重要なポイントでもあります。
1. 推論速度 (Inference Time)
- 限界: MotionCanvasは、高品質なビデオ生成を可能にするビデオ拡散モデル (Video Diffusion Model: VDM) を利用していますが、その代償として推論速度が比較的遅いという課題があります。具体的には、2秒のビデオ(32フレーム)を生成するのに約35秒かかるとされています。
- 今後の課題: この計算コストは、現在のVDMに共通する特徴であり、リアルタイムアプリケーションへの適用を制限しています。将来的には、より効率的な生成モデルの探求が有望な方向性として挙げられます。例えば、より高速なDiffusionモデルのアーキテクチャ、モデルの蒸留 (distillation)、あるいは全く異なる生成パラダイムなどが考えられます。リアルタイムでのインタラクティブなショットデザインを実現するためには、推論速度の劇的な改善が不可欠です。
2. オブジェクトローカルモーションの3D近似 (3D Approximation for Object Local Motion)
- 限界: 現在のMotionCanvasでは、オブジェクトのローカルモーションを近似するために、「各オブジェクトが正面平行な深度平面上にある」と仮定しています。つまり、ローカルモーション中の深度変化は、オブジェクトがカメラから離れている距離と比較して小さいと見なされています。これは多くの自然なシーンでは有効な仮定ですが、厳密には2.5D的なアプローチです。
- 今後の課題: この疑似3D近似は、オブジェクト内の深度変化が著しい「極端なクローズアップ」や「マクロショット」の場合には適切ではない可能性があります。例えば、カメラに向かって大きく手を差し出すような動きや、複雑な形状のオブジェクトが3D空間で大きく回転するような場合には、不自然な結果が生じるかもしれません。将来的には、このようなシナリオに対応するために、より明示的な3D定式化を統合することが興味深い研究方向として挙げられています。これにより、より複雑なオブジェクトの変形や深度の変化を正確にモデル化できる可能性があります。
3. モーションデザインとテキストプロンプトの調和 (Harmonization between Motion Design and Textual Prompts)
- 限界: 現在のシステムでは、モーションデザインの意図とテキストプロンプト間の調和を明示的に制約していません。これは、ユーザーが両方の制御モダリティを組み合わせて創造的なバリエーションを探求できる柔軟性を提供する一方で、矛盾するモーション信号が発生する可能性を残しています。論文の例では、テキストプロンプトが「猫が待っている」と示唆しているにもかかわらず、モーションデザインで猫を前方に動かすように明示的に制御した場合、モーションコントロールがテキストプロンプトよりも優先され、テキストの意図に反する動きが生成される可能性があると指摘されています。
- 今後の課題: このような矛盾を解決し、より一貫性のあるユーザーエクスペリエンスを提供するために、「モーション認識型プロンプト調和 (motion-aware prompt harmonization)」が有益な研究方向とされています。これは、モデルがテキストとモーションの両方の意図をより賢く解釈し、必要に応じてバランスを取るメカニズムを開発することを意味します。例えば、両方のモダリティからの信号をインテリジェントに統合し、優先順位付けや調整を行うようなアプローチが考えられます。
これらの限界と課題は、MotionCanvasがすでに達成した優れた成果の上に、さらなる改良と拡張の可能性を示しています。特に、リアルタイム性、より正確な3D表現、そして多様な制御モダリティ間のインテリジェントな連携は、将来のビデオ生成技術の主要な研究テーマとなるでしょう。