Predicting Human Attention using Computational Attention(2023)
2023年の最新の研究事例。Transformerをベースにしている。
概要
HAT(Human Attention Transformer)は視覚的な注目を予測する新しいトランスフォーマーベースのモデルで、上向きと下向きの注意制御の両方を予測し、従来の手法を上回る性能を発揮します。HATの革新的なデザインと単純化された焦点網膜により、人間の動的な視覚作業メモリに似た空間的時間的な認識が可能です。HATは異なる注意制御タスクでSOTAの予測を達成し、注目の空間的および時間的割り当てを示す。データセットCOOC-Search18およびCOCO-FreeViewにおいて、HATはcNSSで83%、58%、72%の向上を達成した。これは、さまざまな注目を必要とするシナリオで人間の行動をより良く予測できる新しい注目モデルの開発を促す可能性があります。

主な貢献
1.人間の注意の空間的・時間的配分(固視スキャンパス)を予測するために、2つの異なる偏心位置の視覚情報を統合する新しい変換器アーキテクチャであるHATを提案する。
-
TP、TA、FV設定におけるSOTAスキャンパス予測によって実証されたように、我々のHATアーキテクチャが様々な注意制御タスクに幅広く適用できることを示す。また、HATによる人間の注意 人間の注意の予測は非常に解釈可能であることを示す。
-
固定離散化の必要性を排除し スキャンパス予測を逐次的な高密度予測タスクとして定式化する。HATを高解像度入力に適用できるようにする。
モデルアーキテクチャ
HAT(Hierarchical Attentive Transformer)モデルによるスキャンパス予測の手法が紹介されています。エンコーダー,デコーダー,CNNを使用し、視覚的なタスクにおいて作業メモリを構築し、タスクごとに学習することで、精密なフィクセーションヒートマップ(注視点マップ)を生成します。HATは、従来の低い解像度のグリッド空間での離散的なフィクセーションを排除し、ピクセル座標の連続的な予測としてスキャンパス予測を行います。
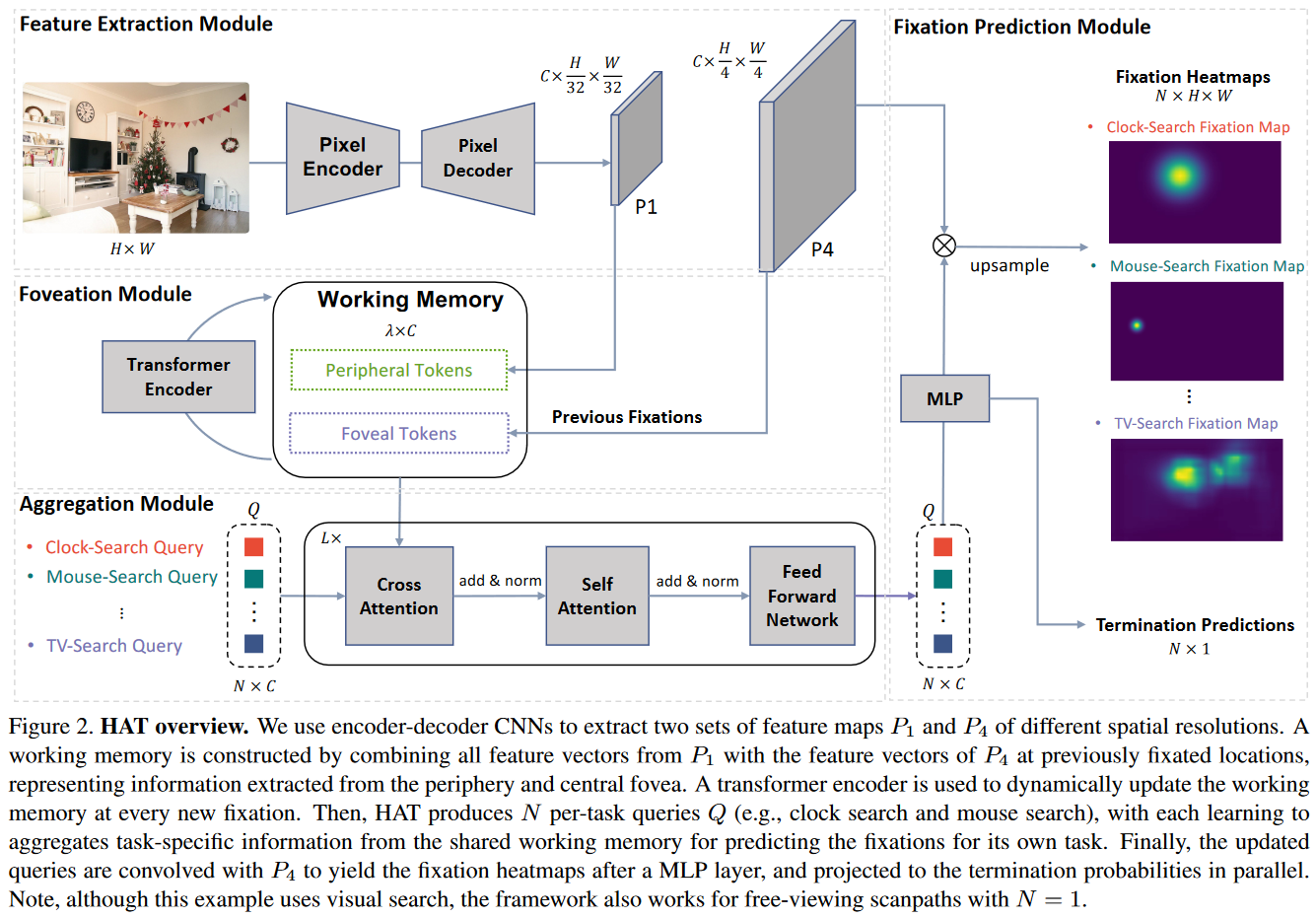
実験結果
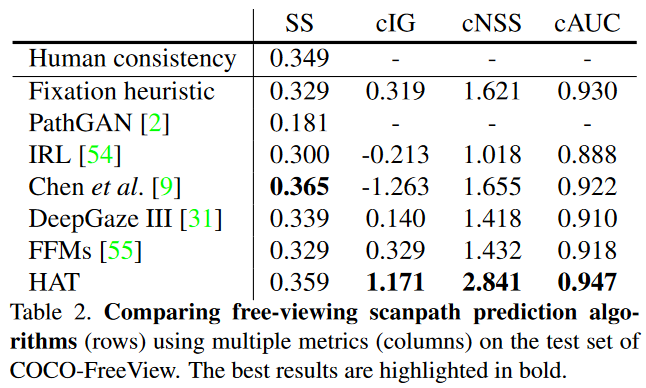
COCOのデータセットにしてHATとその他のモデルを適応し比較.SOTA
HATは視線予測において他の手法を上回り、特に視覚探索と自由閲覧のタスクで高い性能を示しました。視線の定量的な予測結果や定性的な比較を通じて、HATは人間の注視に対して優れた予測能力を持ち、未知のデータセットにおいても安定した性能を示すことが確認されました。注視予測のための新しいアプローチとして、HATは広範なタスクでの有望なフレームワークとなりうることが示唆されています。

議論
提案されたHATモデルの実装詳細(セクションB)、削減研究の追加結果(セクションC)、OSIEおよびMIT1003での実験(セクションD)、追加の質的分析(セクションE)、および提案されたHATモデルの応用に関する議論(セクションF)が提供されています。画像のトレーニングの詳細については、固定解像度(320×512)に画像をリサイズし、トレーニング中にデータ拡張を使用せずに、30エポックでHATをトレーニングします。また、畳み込み層とMLPを含むいくつかのパラメータは、損失を使用してエンドツーエンドでトレーニングされます。HATはOSIEおよびMIT1003で優れた性能を発揮し、推論速度は1秒で、メモリ使用量は18GBです。実験では、異なるピクセルエンコーダーとデコーダー構成でHATが優れた性能を発揮し、モデルの柔軟性が示されています。
HAT(Human Attention Transformer)モデルによる視線予測の性能評価とその応用について述べられています。実験結果によれば、HATは異なるエンコーダやデコーダ、Transformerデコーダレイヤーの選択においても高い性能を示し、特に自由視点データセットでの予測が優れています。また、HATは視線の予測において人間の行動に近い結果を示し、将来的にはVR/ARゲームや自動運転システムなど様々な分野での応用が期待されます。
所感
最新の研究ではSVMやCNNではなくtransformerを用いるようになっている.
やはりtransformerは偉大.
また人が注視する箇所の予測だけでなく、視線がどのように推移するかまで予測出来ているようだ(注視マップの数値が大きい順に線を結んでいるだけ?)