Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control (Gu, 2025)

3行要約
- Diffusion as Shader (DaS)は、従来の単一制御に限定されたビデオ生成の課題を解決するため、多様な制御タスクを可能にする3Dアウェアなビデオ拡散モデルを提案します。
- ✨本手法は、動的な3D点の軌跡から生成され、初期3D座標に基づいて色付けされた「3Dトラッキングビデオ」を制御入力として活用し、ビデオ生成プロセスに内在的な3D認識と高い時間的整合性をもたらします。
- 🎯DaSは、メッシュからビデオへのアニメーション、モーション転送、カメラ制御、オブジェクト操作といった幅広いタスクを統一アーキテクチャで実現し、既存手法と比較してこれらのタスクにおける性能と整合性を大幅に向上させます。
Q:何が問題で、それをどのように解決したのか、わかりやすく説明してください
A:
1. 抱えていた問題点:
従来のビデオ生成AIは、テキストや画像から高品質なビデオを生成できるようになりましたが、以下のような課題がありました。
-
制御の限定性(多様な制御ができない):
- これまでの手法は、カメラの動きや特定のオブジェクトの見た目を維持するなど、特定の種類の制御に特化していました。一つのモデルで様々な種類の制御(カメラ、オブジェクト、モーションなど)を同時に、または柔軟に行うことが困難でした。
- 例えば、「アバターの左手を正確に上げる」といったきめ細かい操作は、従来の2Dベースの制御では非常に難しかったのです。
-
3D情報の欠如(3Dアウェアネスがない):
- ビデオは、現実世界では動的な3Dコンテンツの2D投影に過ぎません。しかし、多くのビデオ生成AIは、レンダリングされた2Dピクセルに対して2Dの制御信号を適用するに留まっていました。
- このため、モデルはビデオの背後にある本当の3D構造や動きを理解せずに、表面的な2Dパターンを学習していました。これが、正確で汎用的な制御を妨げる原因となっていました。
-
時間的一貫性の課題:
- 特に複雑な動きや、オブジェクトが一時的に画面から消えて再出現するような場合、生成されるビデオのフレーム間でオブジェクトの見た目や位置がバラバラになってしまい、時間的な一貫性(Temporal Consistency)が損なわれやすいという問題がありました。
2. DaSによる解決策:
DaSは、これらの問題を**「3Dトラッキングビデオ」という新しい3D制御信号**を導入することで、根本的に解決しました。
-
「ビデオは3Dコンテンツの2Dレンダリングである」という洞察:
- DaSは、従来のCG制作パイプラインのように、まず裏側の3D表現を操作すれば、ビデオのあらゆる側面を詳細に制御できるという重要な洞察に基づいています。
-
3Dトラッキングビデオの導入(新しい制御信号):
- DaSは、動画内の**「動く3Dポイントの軌跡」を記録した3Dトラッキングビデオ**を、主要な制御入力として採用しました。
- これらの3Dポイントには、最初のフレームのカメラ座標系に基づいて固有の色が付けられます。この色はビデオ全体で変化しません。これにより、各3Dポイントが**「時間を通じて変わらない固有のID」**を持つことになります。
-
拡散モデルを「シェーダー」として活用(3Dアウェアネスの実現):
- DaSは、通常のビデオ拡散モデルを「シェーダー」のように機能させます。シェーダーが3Dデータに「見た目」を計算するように、DaSの拡散モデルは、この**3Dトラッキングビデオ(3D幾何学的情報と動き)と入力画像(初期の見た目やスタイル)**を受け取り、各フレームの動的な3Dポイント上にリアルなテクスチャやシェーディングを計算してビデオを生成します。
- このメカニズムにより、拡散モデルはビデオ生成プロセスにおいて本質的に3Dを認識(3D-aware)するようになります。2Dの見た目だけでなく、その背後にある3Dの動きや構造を理解して生成するため、非常に正確な制御が可能になります。
-
強力な時間的一貫性の確保:
- 3Dトラッキングビデオの各3Dポイントは固有の色を持つため、これが「カラーアンカー」として機能し、フレーム間で同じ3Dポイントが同じ見た目を維持するようにモデルを誘導します。
- これにより、オブジェクトが動いたり、一時的に隠れたりしても、その見た目の一貫性が大幅に向上し、より自然で安定したビデオが生成されるようになりました。
解決による主なメリット:
- 多様な制御の実現: メッシュからビデオ生成、カメラ制御、モーション転送、オブジェクト操作といった様々なタスクを、一つの統一されたアーキテクチャで柔軟に制御できるようになりました。
- 高精度な制御: 3D情報を直接扱うため、従来の2Dベースの手法では難しかった、きめ細かい3D空間内の操作が可能になりました。
- 優れた時間的一貫性: 3Dトラッキングポイントがフレーム間の明確な関連付けを担うことで、生成されるビデオの連続性とリアリズムが大きく向上しました。
要するに、DaSは、「ビデオが3Dの世界の投影である」という本質に着目し、**3Dの動きを明示的に伝える「3Dトラッキングビデオ」**という新しい情報源を拡散モデルに与えることで、従来のビデオ生成AIが抱えていた「制御の限界」と「時間的一貫性の課題」を画期的に解決した、と言えるでしょう。
Q:なぜDiffusion as Shaderというタイトルなのですか?
A:
「Diffusion as Shader」というタイトルは、提案手法の核心的なアイデアと、それがコンピュータグラフィックス(CG)における「シェーダー」の機能にどのように似ているかを示す**比喩(アナロジー)**に基づいています。
このタイトルが選ばれた理由は、主に以下の点にあります。
-
「シェーダー」の役割の比喩:
- 伝統的なCGにおけるシェーダー: コンピュータグラフィックスにおいて、シェーダーは3Dモデルの幾何学的情報(頂点、法線、UV座標など)や光源、カメラの位置といったデータを受け取り、それに基づいて各ピクセルの最終的な色や光沢、質感を計算し、2D画像としてレンダリングするプログラムです。つまり、生の3Dデータに「見た目」を与える役割を担います。
-
DaSにおける拡散モデルの役割: DaSでは、「ビデオ拡散モデルがシェーダーのように機能し、動的な3Dポイントにシェーディングされた見た目を計算してビデオを生成する」と説明されています(論文2ページ目)。
- DaSの「3Dトラッキングビデオ」は、動的な3Dポイントの軌跡と、最初のフレームのカメラ座標に基づく固定された色(つまり、「生」の3D幾何学的情報と、その時間的な動き)を提供します。
- DaSの「入力画像」は、生成されるビデオの最初のフレームの見た目やスタイルを定義し、これはシェーダーが適用するテクスチャやマテリアルに相当します。
- そして、DaSの「拡散モデル」は、これらの3D幾何学的情報(3Dトラッキングビデオ)と見た目の情報(入力画像)を統合し、各フレームにおいて、その動的な3Dポイントがどのようなリアルなテクスチャやシェーディング、アピアランスを持つべきかを「計算」し、最終的な2Dビデオフレーム群として「レンダリング」します。
-
3Dアウェアネス(3D-awareness)の強調:
- 「シェーダー」という言葉は、本質的に3D空間内のオブジェクトの見た目を操作する概念と強く結びついています。このタイトルを用いることで、DaSが従来の2Dベースのビデオ生成制御とは異なり、**根本的に3D空間を意識した(3D-awareな)**アプローチであることを明確に示しています。
- 3Dトラッキングビデオがフレーム間で一貫した3Dポイントのアイデンティティを提供するため、拡散モデルは単なる2Dピクセルの変化を追うのではなく、裏にある3Dオブジェクトがどのように動き、どのように見えるべきかを理解している、というメッセージが込められています。
したがって、「Diffusion as Shader」というタイトルは、DaSが拡散モデルを、動的な3Dデータにリアルな「見た目」を付与するシェーダープログラムのように活用する、という画期的なアプローチを端的に表現しているのです。
Q:この論文の概要を教えてください
A:
Diffusion as Shader (DaS) は、汎用的なビデオ生成制御を可能にする新しい3D-awareなビデオ拡散モデルです。従来のビデオ生成モデルは、カメラ操作やコンテンツ編集といった正確な制御が困難であり、通常は単一の制御タイプに限定されていました。本研究では、ビデオが本質的に動的な3Dコンテンツの2Dレンダリングであるという洞察に基づき、多様なビデオ制御を可能にするために3D制御信号を活用するDaSを提案します。DaSは、従来の2D制御信号とは異なり、3Dトラッキングビデオを制御入力として利用することで、ビデオ拡散プロセスを本質的に3D-awareにします。これにより、3Dトラッキングビデオを操作するだけで、幅広いビデオ制御を実現できます。さらに、3Dトラッキングビデオはフレーム間を効果的にリンクし、生成されるビデオの時間的整合性を大幅に向上させます。DaSは、わずか10,000未満のビデオと8基のH800 GPUでの3日間のファインチューニングで、メッシュからビデオへの生成、カメラ制御、モーション転送、オブジェクト操作といった多様なタスクにおいて強力な制御能力を発揮します。
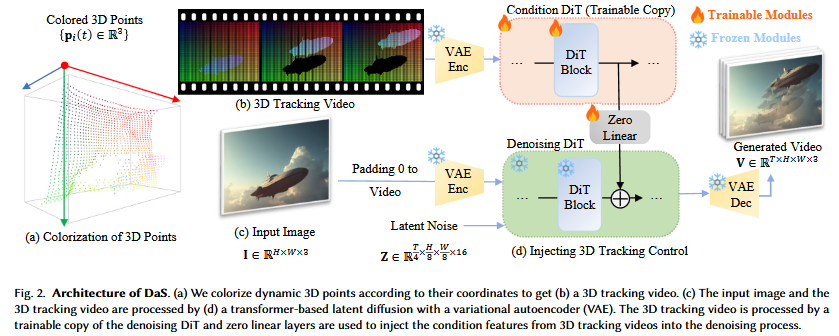
DaSは、Image-to-Video (I2V) 拡散生成モデルであり、入力画像 $\mathbf{I} \in \mathbb{R}^{H \times W \times 3}$ と3Dトラッキングビデオを条件として受け取ります。バックエンドのビデオ拡散モデルとしてCogVideoX [Yang et al. 2024b] をベースにしています。入力画像 $\mathbf{I}$ はゼロパディングされてターゲットビデオと同じサイズ $T \times H \times W \times 3$ の条件ビデオとなり、VAEエンコーダによって潜在ベクトル $T \times \frac{H}{8} \times \frac{W}{8} \times 16$ に変換されます。この潜在ベクトルは、ノイズと連結され、Diffusion Transformer (DiT) [Peebles and Xie 2023b] によって繰り返しノイズ除去され、VAEデコーダで最終的なビデオ $\mathbf{V} \in \mathbb{R}^{T \times H \times W \times 3}$ が生成されます。
DaSにおける主要な技術革新は、3Dトラッキングビデオを補助的な条件として組み込む方法にあります。
-
3Dトラッキングビデオの生成: 3Dトラッキングビデオは、移動する3D点集合 ${ \mathbf{p}_i(t) \in \mathbb{R}^3 }$ からレンダリングされます。ここで、$t=1, \dots, T$ はフレームインデックスです。これらの点の色は、最初のフレームでのカメラ座標系における座標に基づいて決定され、 $[0, 1]^3$ に正規化されてRGB色 ${ \mathbf{c}_i }$ となります(Z座標の逆数を使用)。これらの色は全フレームで一定に保たれ、各フレームはこれらの3D点を対応する時刻 $t$ のカメラに投影してレンダリングされます。合成ビデオの場合、ground-truthの3Dメッシュとカメラ姿勢を利用して密な3D点トラッキングを構築します。実世界ビデオの場合、SpatialTracker [Xiao et al. 2024b] を用いて4,900個の3D点を検出し、その軌跡を追跡します。
-
3Dトラッキング制御の組み込み: ControlNet [Zhang et al. 2023] と同様の設計を採用しています。まず、プリトレーニングされたVAEエンコーダを用いて3Dトラッキングビデオを潜在ベクトルにエンコードします。次に、プリトレーニングされたdenoising DiTの学習可能なコピーである
condition DiTを作成します。denoising DiTは42ブロックで構成されており、最初の18ブロックをcondition DiTとしてコピーします。condition DiTの各DiTブロックの出力特徴は、ゼロ初期化された線形層で処理され、denoising DiTの対応する特徴マップに追加されます。ファインチューニングでは、プリトレーニングされたdenoising DiTは凍結され、condition DiTのみが拡散損失を用いて学習されます。これにより、3Dトラッキングビデオがビデオ生成プロセスに効果的にガイドとして注入されます。
DaSは、この3Dトラッキングビデオの活用により、以下の多様なビデオ生成制御を可能にします。
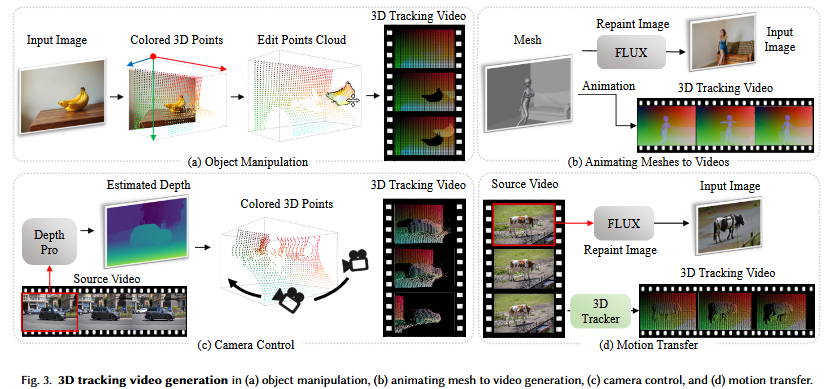
- オブジェクト操作: 入力画像からDepth Pro [Bochkovskii et al. 2024] やMoGE [Wang et al. 2024b] で深度マップを推定し、SAM [Kirillov et al. 2023] でオブジェクトをセグメンテーションします。これにより、オブジェクトの点群を操作して3Dトラッキングビデオを構築し、オブジェクトの移動や回転を制御できます。
- メッシュからビデオへの生成: Blenderなどの3Dツールで作成されたアニメーションメッシュから3Dトラッキングビデオを生成します。これを深度から画像へのFLUXモデル [Labs 2024] で生成された初期フレームと組み合わせることで、シンプルなメッシュから高品質で詳細なビデオを生成します。
- カメラ制御: Depth Pro [Bochkovskii et al. 2024] で初期フレームの深度マップを推定し、それをカラー化された3D点に変換します。これらの点を指定されたカメラ軌跡に投影して3Dトラッキングビデオを作成することで、高精度なカメラ移動を伴うビデオを生成します。
- モーション転送: 既存のソースビデオからモーションを転送します。ソースビデオの最初のフレームの深度マップを推定し、FLUXモデルでテキストプロンプトに基づいてターゲットの見た目に再描画します。次に、SpatialTracker [Xiao et al. 2024b] でソースビデオから3Dトラッキングビデオを生成し、これを編集された最初のフレームと組み合わせてターゲットビデオを生成します。
実験では、カメラ制御とモーション転送において、DaSは既存のベースライン手法(MotionCtrl [Wang et al. 2024c]、CameraCtrl [He et al. 2024b]、TokenFlow [Geyer et al. 2023b]、CCEdit [Feng et al. 2024b])を上回る性能を示し、より正確なカメラ軌跡の制御とテキストアライメントおよび時間的整合性を実現しました。DaSの3D-awareな特性が、ビデオ生成プロセスにおける空間推論の精度を高めていることが示されました。
Q:提案手法の処理の流れを順序だてて説明してください
A:
ご提案いただいたDiffusion as Shader (DaS)の処理の流れについて、順序だててご説明いたします。この手法は、3D制御信号を活用することで、多様なビデオ生成制御を可能にする点が画期的ですね。
DaSの処理は、主に以下のステップで構成されます。
-
3Dトラッキングビデオの準備:
-
3Dポイントの特定と色付け: まず、ビデオ内で動く3Dポイントの集合 ${p_i(t) \in \mathbb{R}^3}$ を準備します。ここで、$t$ はフレームインデックスです。
- これらの3Dポイントは、制御タスクに応じて様々な方法で取得されます。例えば、アニメーションメッシュから直接、既存のビデオからの3Dトラッキング、入力画像の深度推定とセグメンテーションによる特定オブジェクトの3Dポイント抽出などです。
- これらのポイントの色 ${c_i}$ は、最初のフレームにおけるカメラ座標系での座標値に基づいて決定されます。座標は $[0, 1]^3$ の範囲に正規化され、RGBカラーに変換されます。この色は、時間経過(フレーム間)で変化しないため、同じ3Dポイントがフレーム間で一貫した色を保ちます。
- 3Dトラッキングビデオのレンダリング: 特定された3Dポイントを、各フレームのカメラポーズに投影することで、3Dトラッキングビデオがレンダリングされます。このビデオは、ビデオ内の基礎となる3Dモーションを視覚的に表現します。
-
3Dポイントの特定と色付け: まず、ビデオ内で動く3Dポイントの集合 ${p_i(t) \in \mathbb{R}^3}$ を準備します。ここで、$t$ はフレームインデックスです。
-
入力画像の前処理:
- ビデオを生成するための開始フレームとなる入力画像 $I \in \mathbb{R}^{H \times W \times 3}$ が与えられます。
- この入力画像は、目的のターゲットビデオと同じサイズ $T \times H \times W \times 3$ になるように、ゼロパディング(不足部分をゼロで埋める処理)されて、条件付けビデオとして準備されます。
- 次に、このパディングされた条件付けビデオは、事前に学習されたVAE (Variational Autoencoder) エンコーダによって、潜在ベクトル(潜在空間における表現)にエンコードされます。そのサイズは $T/4 \times H/8 \times W/8 \times 16$ となります。
-
ビデオ拡散モデルの条件付け:
- 3Dトラッキングビデオのエンコード: ステップ1で準備された3Dトラッキングビデオも、入力画像と同じVAEエンコーダで潜在ベクトルにエンコードされます。
- 潜在空間でのノイズ付与: 入力画像から得られた潜在ベクトルに、ノイズが加えられます。このノイズを、拡散モデルが段階的に除去していくことで、最終的なビデオを生成します。
-
条件の注入 (ControlNetに類似したメカニズム):
- DaSは、事前学習済みのビデオ拡散モデル(CogVideoX [Yang et al. 2024b])をバックエンドとして利用します。具体的には、そのDenoising DiT (Diffusion Transformer) モジュールのコピー(Condition DiT)を訓練します。
- 3Dトラッキングビデオの潜在ベクトルは、このCondition DiT(オリジナルDenoising DiTの最初の18ブロックのコピー)に入力されます。
- Condition DiTの各ブロックから出力される特徴は、ゼロで初期化された線形層を介して処理された後、オリジナルDenoising DiTの対応する特徴マップに加算されます。この際、オリジナルDenoising DiTは凍結(パラメータを更新しない)されており、Condition DiTのみがファインチューニングされます。
-
ビデオの生成:
- ノイズ除去の反復: 拡散モデル(Denoising DiT)は、与えられたステップ数だけ繰り返しノイズ除去プロセスを実行し、ノイズが除去された潜在ベクトルを生成します。
- 最終ビデオのデコード: ノイズが除去された潜在ベクトルは、VAEデコーダを介して処理され、最終的な生成ビデオ $V \in \mathbb{R}^{T \times H \times W \times 3}$ が出力されます。
この一連のプロセスにより、DaSは入力画像と3Dトラッキングビデオを効果的に組み合わせて、高画質かつ時間的に一貫性のあるビデオを、ユーザーの意図した3D制御下で生成することを可能にしています。
Q:「3Dトラッキングビデオの準備」において、3Dポイントの色が最初のフレームのカメラ座標系に基づいて決定され、時間経過で変化しないと説明がありましたが、この「色付け」が生成されるビデオの内容や3D制御に具体的にどのような影響を与えるのでしょうか?
A:
ご質問ありがとうございます。「3Dトラッキングビデオの準備」における3Dポイントの「色付け」が、生成されるビデオの内容や3D制御にどのような影響を与えるか、非常に重要な点ですね。この色付けは、DaSが実現する多才な制御と時間的な一貫性の鍵となります。
具体的には、以下の点で影響を与えます。
-
3Dポイントの「識別子」としての機能(明確な3Dアイデンティティの付与):
- 各3Dポイントに、最初のフレームのカメラ座標系に基づく固有の色を割り当てることで、その3Dポイントに**一貫した「アイデンティティ」**が付与されます。この色は、ビデオの全フレームにわたって変化しません。
- これは、従来のCGパイプラインで各3Dモデルの頂点やオブジェクトに割り振られるIDのような役割を果たします。拡散モデルは、この色を通じて、特定の3D空間上の点(あるいは、その点が属する表面上の位置)をビデオ全体で認識し続けることができます。
-
時間的な一貫性(Temporal Consistency)の大幅な向上:
- 通常のビデオ拡散モデルでは、フレーム間の関連性を学習するのが難しい場合があります。特に、オブジェクトが動いたり、一時的に隠れて再出現したりする際に、その見た目(アピアランス)を安定して保つことが課題となります。
- DaSでは、固定された色の3Dポイントが「カラーアンカー (color anchors)」として機能します。例えば、ある特定の3Dポイントが青色で表現されている場合、その青色がビデオのどのフレームに現れても、拡散モデルはそれが同じ3Dポイントであることを認識します。
- これにより、その3Dポイントに割り当てられるべき見た目(テクスチャ、シェーディングなど)が、フレーム間で一貫して生成されるようになります。論文で述べられているように、「3D領域が一時的に消滅し、その後再出現した場合でも、DaSはその領域の見た目の一貫性を効果的に維持します」というのは、このメカニズムの直接的な恩恵です。
-
より高精度な3Dアウェアネス(3D-awareness)の実現:
- 単なる深度マップ(depth maps)は、各フレームにおける2Dピクセルごとの奥行き情報を提供しますが、異なるフレームの深度マップ上の点同士が、3D空間で同じオブジェクトの同じ部分に対応しているかを明示的に教えてはくれません。
- DaSの3Dトラッキングビデオでは、色付けされた3Dポイントの時系列データが、各フレームの2D画像上のピクセルがどの3D点に由来するかという情報を明示的に提供します。これにより、拡散モデルはビデオが2Dレンダリングされた動的な3Dコンテンツであるという「3D認識」を非常に強く持ち、シーンの構造と動きをより正確に理解し、再現できるようになります。
-
多様な制御タスクへの柔軟な対応:
- モーション転送 (Motion transfer): ソースビデオの動きを新しいビデオに転送する際、ソースビデオから抽出された3Dポイントとその固定された色が、新しいスタイルのビデオでも正確な動きと見た目の連続性を保証します。
- オブジェクト操作 (Object manipulation): 特定のオブジェクトの3Dポイントを抽出し、それらを操作(移動、回転など)する場合、固定された色情報によって、モデルはそのオブジェクトがどこへ動いても、その一貫した見た目を維持しながら操作された状態を生成できます。
- メッシュからビデオ生成 (Mesh-to-video generation): アニメーションメッシュの各頂点や表面上の点に色を割り当て、それを追跡することで、シンプルだったメッシュが、その3D構造と動きを保ちつつ、リアルなテクスチャで「シェーディング」されたビデオに変換されます。
簡単に言えば、この「色付け」は、各3Dポイントが「私はビデオ全体を通じてこの位置に存在し、このような見た目を持つべきだ」と拡散モデルに語りかけるための、ユニークなIDと空間的ヒントを組み合わせた信号として機能します。これにより、生成されるビデオは、動きの正確性、オブジェクトの見た目の一貫性、そして全体的なリアリズムにおいて、飛躍的に向上するのです。
Q:関連手法との比較について詳しく説明してください
A:
DaS(Diffusion as Shader)は、その多才なビデオ制御能力において、既存の関連手法とどのように比較されるか、詳しくご説明します。論文では、特に「3Dアウェアネス」と「3Dトラッキングビデオ」の活用が、DaSの大きな強みとして強調されています。
1. 汎用的なビデオ生成制御の観点
- 既存手法の課題: 多くの先行研究 [Guo et al. 2024; He et al. 2024b,a; Huang et al. 2023; Ma et al. 2024b,a; Namekata et al. 2024; Polyak et al. 2024; Wang et al. 2024f,c; Yuan et al. 2024] は、特定の制御タイプ(例: 識別子の保持、カメラ制御、モーション転送)に特化しており、専用のアーキテクチャに依存していました。これらは、多様な制御要求への適応性に欠け、カメラの動きやアイデンティティ保持といった高レベルな調整に限られ、アバターの左手を正確に上げるようなきめ細かい操作には対応できませんでした。
- DaSの優位性: DaSは、ビデオが根本的に動的な3Dコンテンツの2Dレンダリングであるという洞察に基づき、3D制御信号の活用を提唱しています。3Dトラッキングビデオを制御入力として用いることで、本質的に3Dアウェアなビデオ拡散プロセスを実現し、単一のアーキテクチャ内でメッシュからビデオ生成、カメラ制御、モーション転送、オブジェクト操作といった幅広いビデオ制御タスクを可能にします。これにより、より汎用的で高精度な制御が実現されます。
2. 特定の制御タスクにおける比較
(1) メッシュからビデオ生成 (Animating meshes to videos)
-
既存手法:
- TexFusion [Cao et al. 2023] や TEXTure [Richardson et al. 2023] は、2Dレンダリングやトリマップ表現を用いて3D形状のテクスチャを生成します。
- G-Rendering [Cai et al. 2024] は、動的メッシュを入力とし、UVガイド付きノイズ初期化と対応認識ブレンドにより一貫性を保ちます。
-
DaSの優位性:
- G-Renderingと同様に動的メッシュをターゲットとしますが、DaSは3Dトラッキングビデオを補助情報として活用し、これを拡散モデルに統合することで、ノイズやアテンションレベルでの一貫性保持に加え、時間的・空間的一貫性をより強固に保証します。
- 実験結果: 著名な人間アニメーション手法であるCHAMP [Zhu et al. 2024] との比較では、DaSは異なるモーションシーケンスやスタイルにおいて、アバターの3D構造とテクスチャのディテールにおいてより優れた一貫性を示しています(図8)。
(2) カメラ制御 (Camera control)
-
既存手法:
- MotionCtrl [Wang et al. 2024c] や CameraCtrl [He et al. 2024b] は、カメラやレイ埋め込みを条件として使用します。
- ViewCrafter [Yu et al. 2024] は、ポイントベースの表現を用いてフリービューレンダリングを可能にします。
- これらの手法は、暗黙的にカメラパラメータやレイ情報から3D構造を推論する必要があり、真の3Dアウェアネスに欠ける場合があります。
-
DaSの優位性:
- DaSは、入力フレームから推定された深度マップを3Dポイントに変換し、これらのポイントを目的のカメラパスに沿って投影することで3Dトラッキングビデオを構築します。これにより、カメラ制御プロセスに明示的な3Dアウェアネスを導入します。拡散モデルはシーンの3D構造を推論するのではなく、既に構造化された3Dモーション情報を受け取ることができます。
-
実験結果: MotionCtrlとCameraCtrlをベースラインとして、カメラポーズの回転誤差(RotErr)と並進誤差(TransErr)を評価しています。DaSは、どちらのベースラインよりも大幅に低い誤差を達成し、生成ビデオのカメラポーズにおいて安定かつ正確な制御能力を示しています(表1)。これは、3Dトラッキングビデオの活用により、ビデオ生成プロセスにおける正確な空間推論が可能になったためだと結論付けています。

(3) モーション転送 (Motion transfer)
-
既存手法:
- Gen-1 [Esser et al. 2023] は深度推定結果をモーションガイドに利用します。
- TokenFlow [Geyer et al. 2023a] は、拡散特徴空間の一貫性を強制することで、一貫したモーション転送を実現します。
- MotionCtrl [Wang et al. 2024c] や Motion Prompting [Geng et al. 2024] などもモーション制御を行います。
- これらのアプローチは、主に2Dモーション(オプティカルフローや2Dトラック)や、拡散モデルの内部特徴の一貫性に依存することが多いです。
-
DaSの優位性:
- DaSは、3Dトラッキングビデオをモーション転送のガイドとして採用することで、各オブジェクトの動きとその関係性をより包括的に捉えます。これにより、ビデオ全体で幾何学的および時間的に一貫した正確なモーション転送を保証します。
-
実験結果: CCEdit [Feng et al. 2024b] とTokenFlow [Geyer et al. 2023b] をベースラインとして比較しています。
- CCEdit: 低品質なフレームを生成し、時間的な一貫性を維持するのが困難。
- TokenFlow: 意味的に一貫したフレームを生成するものの、ビデオ全体としてのコヒーレンスに課題。
-
DaS: テキストとのアライメント(Text-Ali)とフレーム間の一貫性(Tem-Con)の両方で最高のCLIPスコアを達成し、ソースビデオのモーションを高い時間的コヒーレンスで正確に転送できることを示しています(表2、図5、図6)。

(4) オブジェクト操作 (Object manipulation)
-
既存手法:
- 既存の主流手法 [Chen et al. 2023a; Geng et al. 2024; Jain et al. 2024; Li et al. 2024; Ma et al. 2024b; Mou et al. 2024; Qiu et al. 2024; Teng et al. 2023; Wang et al. 2024f,c; Yang et al. 2024a; Yin et al. 2023] は、主に2Dガイダンス(軌跡やバウンディングボックス間の関係性)に依存しており、ユーザーの意図を正確に捉えきれず、歪んだ出力になることが頻繁にありました。
- ObjCtrl-2.5D [Wang et al. 2024a] は、2D軌跡に深度情報を付加して単一の3D軌跡を作成し、この制限に対処しようとします。
-
DaSの優位性:
- DaSは、単一の3D軌跡よりも詳細な3Dトラッキングビデオを活用します。オブジェクトの3Dポイントを抽出し、それらを操作して3Dトラッキングビデオを構築することで、前景と背景のモーション関係をより効果的に表現し、より正確でリアルなオブジェクト操作を実現します。
- 実験結果: 定性的な結果(図9)では、DaSがオブジェクトの移動や回転といった操作において、正確なオブジェクト操作と、強力なマルチビュー一貫性を持つフォトリアルなビデオ生成を達成できることを示しています。
結論として
DaSは、3Dトラッキングビデオを明示的な3D制御信号として利用することで、従来の2Dベースの制御や暗黙的な3D推論に頼る手法と比較して、ビデオ生成プロセスにより深い3Dアウェアネスと時間的一貫性をもたらします。これにより、単一の統一されたアーキテクチャで、きめ細かい制御から大規模なモーション転送まで、幅広い制御タスクにおいて優れた性能を発揮できる点が、その最大の強みと言えるでしょう。
Q:提案手法の限界と今後の課題はなんですか?
A:
DaS(Diffusion as Shader)は、多才なビデオ生成制御において目覚ましい成果を上げていますが、他の革新的な研究と同様に、いくつかの限界と今後の課題を抱えています。論文では、主に以下の2つの主要な限界が指摘されており、それに対する1つの将来的な研究方向が示されています。
提案手法の限界 (Limitations)
-
3Dトラッキングビデオと入力画像の非互換性:
- 問題点: DaSは、入力画像と提供される3Dトラッキングビデオの間に強い互換性があることを前提としています。もし、3Dトラッキングビデオが入力画像の構造や内容と大きく食い違っている場合、生成されるビデオは不自然なものになってしまいます。論文の図11(上)では、追跡ビデオが入力画像の構造に対応していない場合、DaSは互換性のある新しいシーンへ「シーン遷移」を起こして、非現実的なビデオを生成する可能性があると示されています。
- 背景: これは、DaSが3Dトラッキングビデオを「現実世界の3Dコンテンツの動き」として解釈し、それに沿って入力画像を「シェーディング」しようとするためです。もし、動きの指示が視覚的な内容と根本的に矛盾すれば、モデルはその矛盾を解決できず、破綻した結果を生み出してしまいます。
-
トラッキング範囲外の領域における制御の欠如:
- 問題点: 3Dトラッキングビデオがカバーしない、つまり3Dトラッキングポイントが存在しない領域では、DaSは生成コンテンツに対する制御を失う可能性があります。このような制御されていない領域では、不自然な結果が生じる可能性があります(論文の図11、下)。
- 背景: DaSの制御メカニズムは、あくまで3Dトラッキングポイントによって定義される3Dモーション情報に基づいています。トラッキングポイントが疎であったり、特定の領域が完全に欠落している場合、その領域はモデルのガイダンスが及ばなくなり、結果として意図しないビジュアルアーティファクトや、場面にそぐわない要素が生成されるリスクが高まります。これは特に、複雑なシーンや、トラッカーが安定して追跡できない領域で顕在化しやすい問題です。
今後の課題と研究方向 (Future Works)
-
高品質な3Dトラッキングビデオの自動生成:
- 現状: 現在のDaSは、高品質な3Dトラッキングビデオを得るために、提供されたアニメーションメッシュや既存のビデオ(そしてそれらを解析するSpatialTracker [Xiao et al. 2024b] などの外部ツール)に依存しています。これは、ユーザーがDaSを利用する上での前処理の負担となり、手軽さの点で課題となります。
- 将来の方向性: 将来の有望な研究方向として、新しい拡散モデルを用いてこれらの3Dトラッキングビデオ自体を学習し、自動生成することが挙げられています。
- 意義: これが実現すれば、ユーザーはより抽象的な指示(テキストプロンプトや大まかなスケッチなど)から直接、DaSのための3Dトラッキングビデオを生成できるようになり、システム全体の使いやすさと汎用性が飛躍的に向上するでしょう。これは、ビデオ生成のコントロールにおける、さらなるブレークスルーに繋がる可能性を秘めています。
