Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models(Fei, 2022)
この論文は、視覚的注目予測の発展過程について、神経生物学的基盤から深層モデルまでを探求したレビュー論文です。視覚的注目とは、人間が視覚的に注目する対象のことであり、コンピュータビジョンにおいても重要な役割を果たしています。本論文では、視覚的注目予測の歴史的な背景や、従来の手法から深層学習モデルによる予測手法の改善、そして実世界での応用についても議論されています。
概要
人間は毎日80%の情報を視覚から得ています。人間の視覚システムは、毎秒数百メガバイトの視覚情報を受け取りますが、情報処理速度は40ビット/秒に限られています。このため、人間は視覚情報の中から注目すべき情報を選択する必要があります。このような注目の過程をコンピュータに再現することで、コンピュータビジョンの分野においても重要な役割を果たす「視覚的注目予測」が生まれました。
この論文では視覚的注目予測に関して主に以下の3つを説明しています。
・この研究では、顕著性予測という課題に焦点を当て、顕著性予測に関連する心理学的、生理学的メカニズムを分析し、顕著性予測に関連する古典的なメカニズムを紹介した。顕著性予測に関連する心理的・生理的メカニズムを分析し、顕著性予測に影響を与える古典的モデルを紹介した。を紹介し、これらの理論がディープラーニングモデルに与える影響を明らかにした。これらの理論がディープラーニングモデルに与える影響を明らかにした。
・ディープラーニングに基づく視覚的顕著性モデルを詳細に分析し、代表的な実験データセットと静的・動的条件下でのモデルの性能評価指標を議論した。モデルの静的条件下と動的条件下での性能評価指標を議論しまとめた。
・本研究では、ディープラーニングに基づく視覚的顕著性モデルを分析し、現在のディープラーニングモデルの限界を分析し、改善の方向性を提案した。ディープラーニングの最新の進展に基づく新たな応用領域が議論された。今後の開発動向に関する顕著性予測の貢献と意義が示された。
視覚的顕著性の心理学的・神経生物学的基盤
「2. Psychological and Neurobiological Basis of Visual Saliency」では、視覚的注目予測の基盤となる神経生物学的および心理学的メカニズムについて説明されています。人間の視覚システムは、視覚情報を処理するために限られたリソースしか持っていないため、情報処理の効率を高めるために注目の過程が必要です。この注目の過程は、視覚的注目予測の基盤となる神経生物学的および心理学的メカニズムによって制御されています。
神経生物学的メカニズムには、視覚情報処理の初期段階で発生する中心周囲抑制や、視覚情報の特徴を抽出する機能が含まれます。また、心理学的メカニズムには、課題や目標に応じた注目の制御や、視覚情報の特徴に基づく注目の制御が含まれます。
これらの神経生物学的および心理学的メカニズムは、従来の視覚的注目予測の手法に大きな影響を与えています。例えば、FIT(Feature Integration Theory)モデルは、視覚情報処理の前注目段階と注目段階に分け、注目段階で特徴の統合を行うことで、注目の制御を実現しています。また、Wolfeのガイド付き検索モデルは、視覚情報の特徴に基づく注目の制御を実現するために開発されました。
これらの神経生物学的および心理学的メカニズムに基づいて、視覚的注目予測の手法が開発されてきました。これらの手法は、視覚情報の特徴に基づく注目の制御を実現することで、視覚的注目予測の精度を向上させることができます。
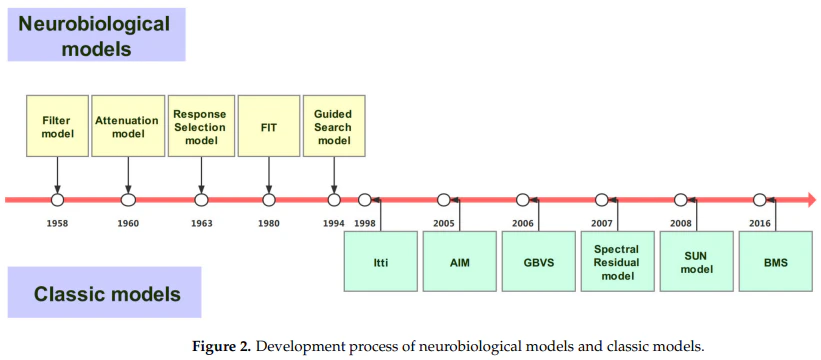
古典的な視覚的顕著性モデル
「3. Classic Visual Saliency Models」では、古典的な視覚的注目予測モデルについて説明されています。これらのモデルは、心理学的および神経生物学的な基盤に基づいて開発され、視覚情報の特徴に基づく注目の制御を実現することを目的としています。
古典的な視覚的注目予測モデルは、通常、手作業で設計された特徴モデルです。これらのモデルは、情報処理のレベルに応じて、ボトムアップの注目モデル(データ駆動型、タスクに依存しないモデル)とトップダウンの注目モデル(タスク駆動型、タスク固有のモデル)に分類されます。
ボトムアップの視覚的注目予測モデルは、通常、コントラスト、色、テクスチャなどの低レベルの特徴を抽出します。これらの特徴の違いが背景と強く引き立てるため、注目のリソースを引き付けます。この注目予測メカニズムは無意識的であり、迅速な処理を必要とします。
これらの古典的なモデルは、視覚情報の特徴に基づく注目の制御を実現することで、視覚的注目予測の精度を向上させることができます。これらのモデルは、視覚情報処理の神経生物学的および心理学的な基盤に基づいて開発されており、視覚的注目予測の重要な基盤となっています。
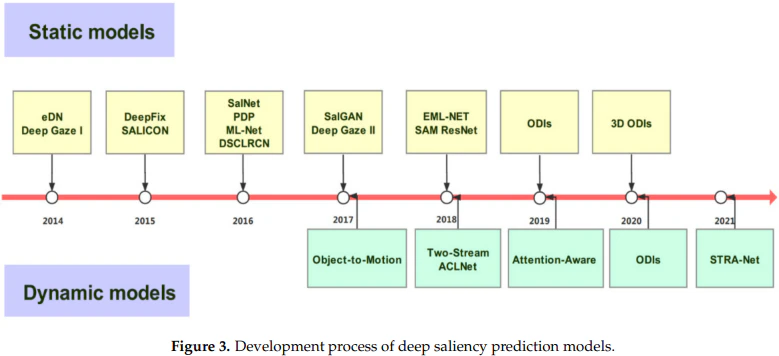
深層視覚顕著性モデル
「4. Deep Visual Saliency Models」では、深層学習を用いた視覚的注目予測モデルについて説明されています。深層学習は、手作業で設計された特徴を使用する従来のモデルとは異なり、自動的に特徴を学習することができます。
深層学習を用いた視覚的注目予測モデルは、通常、畳み込みニューラルネットワーク(CNN)を使用して構築されます。これらのモデルは、画像の特徴を自動的に抽出し、注目の予測を行うことができます。深層学習を用いたモデルは、従来の手作業で設計されたモデルよりも高い精度を実現することができます。
深層学習を用いた視覚的注目予測モデルは、画像認識、物体検出、セグメンテーション、映像圧縮、映像検索などの多くのアプリケーションに使用されています。これらのモデルは、人間の視覚システムと同様に、画像の特徴に基づく注目の制御を実現することができます。
しかし、深層学習を用いた視覚的注目予測モデルには、いくつかの制限があります。例えば、複雑なシーンにおいては、深層学習によって抽出された特徴が、画像内の重要なオブジェクトや領域を完全に表現できない場合があります。また、深層学習を用いたモデルは、多様な情報や高次の意味理解に対応することができない場合があります。
静止画像に対する深層視覚的注目予測モデル
静止画像に対する深層学習を用いた視覚的注目予測モデルは、通常、CNNを使用して構築されます。これらのモデルは、画像の特徴を自動的に抽出し、注目の予測を行うことができます。静止画像に対する深層学習を用いた視覚的注目予測モデルは、従来の手作業で設計されたモデルよりも高い精度を実現することができます。
静止画像に対する深層学習を用いた視覚的注目予測モデルは、多くのアプリケーションに使用されています。例えば、画像認識、物体検出、セグメンテーション、映像圧縮、映像検索などが挙げられます。
静止画像に対する深層学習を用いた視覚的注目予測モデルは、多くのデータセットで評価されています。これらのデータセットには、CAT2000、MIT1003、PASCAL-S、MSRA-B、DUT-OMRON、SALICONなどが含まれます。これらのデータセットに対するモデルの評価は、AUC-Judd、AUC-Borji、sAUC、SIM、EMD、CC、NSS、KLなどの指標を使用して行われます。
動画に対する深層視覚的注目予測モデル
動画に対する深層学習を用いた視覚的注目予測モデルは、通常、畳み込みニューラルネットワーク(CNN)や長短期記憶(LSTM)を使用して構築されます。これらのモデルは、動画内のフレームごとに画像の特徴を自動的に抽出し、時間的な情報を考慮して注目の予測を行うことができます。
動画に対する深層学習を用いた視覚的注目予測モデルは、動画内の動きや変化を考慮することができます。これにより、動画内の注目領域や視覚的な興味の変化をより正確に予測することが可能となります。
動画に対する深層学習を用いた視覚的注目予測モデルは、動画認識、映像圧縮、映像検索、動画編集などの多くのアプリケーションに使用されています。これらのモデルは、動画内の注目領域や視覚的な興味の変化を分析し、それに基づいて様々な処理を行うことができます。
しかし、動画に対する深層学習を用いた視覚的注目予測モデルには、静止画像に比べてより多くの計算リソースやデータが必要となるという課題があります。また、動画内の複雑な動きや変化を正確に捉えるためには、より高度なモデルやアルゴリズムが必要となります。