はじめに
この記事はMicroAd Advent Calendar 2017の12日目の記事です.
Spark Streamingではブロードキャスト変数を利用することで各ワーカノードに変数を配布することができます.通常,ブロードキャスト変数はアプリケーションの開始時に1回だけ実行し,静的データとして利用します.
しかし定期的にブロードキャスト変数を更新したいと思うことってありませんか?例えば,データベースから定期的にデータを取ってきてメモリに載せて扱いたい等.
ということで,本記事ではブロードキャスト変数を定期的に更新する方法をご紹介します.
前提
本記事では出来る限り丁寧な説明を心がけたいと考えておりますが,Spark Streamingを多少触った経験があるとスムーズに理解できるかと思います.
何か不明点や不正確な内容等あれば遠慮なくご指摘頂けると幸いです.
ブロードキャスト変数とは
ブロードキャスト変数とはワーカノード内で参照できる共有変数のことです.ドライバプログラムからワーカノード全体に送信します.ワーカノード内でデータが取得できると,外部とのやり取りにかかるコストを削減できるのでパフォーマンスの向上が見込めるようになります.
下記にブロードキャスト変数の利用例を示します.
// ブロードキャスト変数を使わない例
// 変数streamはStreamingContextを示す.
val foods = Map(1->"ラーメン", 2->"牛丼", 3->"カレー")
stream.map { record =>
foods.get(record.foodId)
}
// ブロードキャスト変数を使った例
// 変数scはSparkContextを示す.
val foods = sc.broadcast(Map(1->"ラーメン", 2->"牛丼", 3->"カレー"))
stream.map { record =>
foods.get(record.foodId)
}
コード上ではsc.broadcastでラップしたかどうかの違いだけです.しかし内部的には前者はfoodsを参照するために毎回,ドライバノードからワーカノードへと変数foodsが送信されます.一方で後者は変数foodsを1度だけワーカノードへ送信し,2回目以降はワーカノード内の変数foodsを参照するようになります.
つまり後者の方がfoodsを毎回ノードに送信しなくて済むので,パフォーマンス的に有利です.デメリットとしては,ワーカノード内のメモリを消費するため,前者と比較してリソースを消費します.
ストリーミング処理中にブロードキャスト変数を更新する
さて,先に紹介したようにブロードキャスト変数は,頻繁に参照するような変数をドライバプログラムからワーカノードへ送信しておきパフォーマンス向上のために利用します.そして,ブロードキャストするタイミングは通常,アプリケーションを起動し,ストリーミング処理を開始する前段階で実行します.
ここで,ブロードキャスト変数を更新する方法を考えましょう.
1つ目はストリーミング処理にブロードキャスト変数を更新するロジックを組み込むことです.下記コード例では経過秒数が60秒を超えたら変数foodsを更新します.その際,unpersistでメモリを解放するようにします.そして,再度ブロードキャストします.
// foodsの初期値.
var foods = sc.broadcast(Map(1->"ラーメン", 2->"牛丼", 3->"カレー"))
stream.transform { rdd =>
// 60秒経ってたらfoodsの値を更新
if (経過秒数 > 60) {
foods.unpersist()
foods = rdd.context.broadcast(Map(1->"ラーメン", 2->"牛丼", 3->"カレー", 4->"寿司"))
}
// foodsを使った処理
rdd.filter { record =>
foods.contains(record.food)
}
}
しかしこの方法にはデメリットがあります.foodsを更新する際に,データベースから値を参照する場合やfoodsがあまりにも大きなコレクションの場合は更新自体に時間がかかってしまい,その間ストリーミング処理が止まってしまうことです.これでは本末転倒・・出来ることならストリーミング処理とは非同期にブロードキャスト変数を更新したいです.
そこでブロードキャスト変数を非同期かつ定期的に更新するためにスケジューラを使うことを考えます.ドライバプログラム上でスケジューラを起動しておき,定期的にブロードキャストしてもらいます.
今回はakka-quartz-schedulerを使います.
下記のような設計にします.
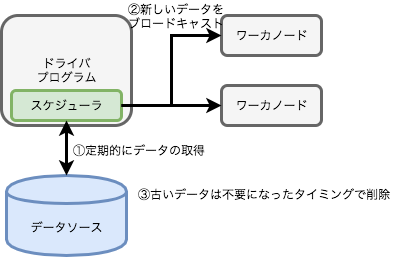
- スケジューラを設定して定期的に新しいデータを取得します
- 新しいデータをブロードキャストします
- 古いデータは不要になったら削除します
といった流れです.ポイントはスケジューラによる処理なので,ブロードキャスト変数の更新はストリーミング処理には一切干渉しません.
実装
まずエントリポイントとなるドライバプログラムを実装します.今回ブロードキャストする変数はただの文字列です.
object Driver {
def main(args: Array[String]): Unit = {
// Sparkの設定関連
val sparkConf = new SparkConf().setMaster("local").setAppName("test-spark")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Milliseconds(10000))
// ブロードキャスト変数を保持するLookupの生成
val sampleLookup = new SampleLookup(sc.broadcast("saisyo"))
// スケジューラの生成. ポイントはSparkContextをスケジューラに渡すことです.
val system = ActorSystem("test-scheduler", ConfigFactory.load("schedule.conf"))
val scheduler = QuartzSchedulerExtension(system)
scheduler.schedule("test-scheduler", system.actorOf(Props(classOf[TaskRunner], sampleLookup, sc)), "")
// メインの処理.map内の処理はワーカノードで実行されます
val stream = ssc.socketTextStream("localhost", 7777)
stream.map { record =>
sampleLookup.data.value
}
}.print()
ssc.start()
ssc.awaitTermination()
}
}
続いてスケジューラを実装します.この後に実装するSampleLookupクラスのreloadメソッドを実行するだけです.
class TaskRunner(lookup: SampleLookup, sc: SparkContext) extends Actor {
override def receive: Receive = {
case _ =>
lookup.reload(sc)
}
}
スケジューラの設定ファイルは以下のような感じになります.
akka {
quartz {
defaultTimezone = "Asia/Tokyo"
threadPool {
threadCount = 1 // スレッド数
threadPriority = 5 // 1(最低優先度)~10(最高優先度)
daemonThreads = true // デーモンとして実行するかどうか
}
schedules {
lookup-reload {
expression = "0 */5 * ? * *"
description = "5分おきに実行"
}
}
}
}
最後にブロードキャスト変数を保持するクラスを実装します.Serializableで定義する必要があります.
ポイントはreloadメソッドとメンバ変数です.ブロードキャストしたい変数はBroadcast型で定義しましょう.
そしてreload()実行時に次の処理を行います.
- 新しいデータの生成: DBから値を取るなり自由に処理を書いてもらって大丈夫です.今回はランダム文字列を生成しています.
- 新規データのブロードキャスト: スケジューラに渡したSparkContextを使って再度ブロードキャストを行います.これによって全く新しい変数を再度各ワーカノードに配布できます
case class SampleLookup(var data: Broadcast[String]) extends Serializable {
def reload(sc: SparkContext): Unit = {
// 1. 新しいデータの生成を行います
val newData = Random.alphanumeric.take(5).mkString
// 2. 新しくブロードキャストします
data = sc.broadcast(newData)
}
}
以上で定期的にブロードキャスト変数を更新することができます.
続いて,古くなったブロードキャスト変数を削除する必要があります.なぜなら永遠にブロードキャストし続けると無駄なデータがどんどん溜まっていきOutOfMemoryErrorになってしまうためです.ブロードキャスト変数は明示的に削除する必要があるのです.
そこで,先程のSampleLookupにさらにスケジューラを設定します.スケジューラを設定せずに新しい値の更新と同時に削除してしまうと,現在走っているストリーム処理で使っている変数が突然削除されたことによってエラーが発生します.なので,古い値はしばらく時間が経って使われなくなったら削除しましょう.この辺りはマイクロバッチの実行時間などによって削除の仕方が変わってくるかと思います.
ここでは更新後,1分経ったら古い値を削除するようにしました.以下が削除ロジックを実装したSampleLookupです.
case class SampleLookup(var data: Broadcast[String]) extends Serializable {
def reload(sc: SparkContext, oldValue: Broadcast[String]): Unit = {
val newData = Random.alphanumeric.take(5).mkString
// 1回だけ実行するタスクを1分後にセットする.
// (説明のためここでschedulerを生成しているが変数schedulerはここで生成せずobjectなどに持たせるほうが良い)
val system = ActorSystem("test-scheduler2", ConfigFactory.load("schedule.conf"))
val scheduler = QuartzSchedulerExtension(system)
scheduler.scheduleOnce(1.minutes, Props(classOf[DestroyBroadcastTask[V]], oldValue), "")
data = sc.broadcast(newData)
}
}
/** ブロードキャスト変数を削除するタスク */
class DestroyBroadcastTask[V](value: Broadcast[V]) extends Actor with StrictLogging {
override def receive: Receive = {
case _ =>
value.destroy()
}
以上で,非同期かつ定期的にブロードキャスト変数を更新することができます.
まだ参照してるのにブロードキャスト変数を削除したらどうなるのか
ブロードキャスト変数を更新していく分には何もエラーは発生しませんが(OutOfMemoryErrorを除く)削除した際には参照できなくなるためエラーになることがあります.その場合の仕組みについて少し補足します.
先程のDriverのコードを抜粋して説明しますと,sampleLookup.dataを参照した時点で既にデータがunpersist()されていた場合,ワーカノードはドライバに問い合わせてデータを取得します.つまりunpersist()はワーカノードからだけデータを削除するので,なくなったらもう1回ドライバから取ってくるようになります.
次にdestroy()した場合です.この場合はブロードキャスト変数が完全に消滅するので,SparkExceptionが発生してストリーミング処理が中断されると思います.ですので,ブロードキャスト変数は古くなった不要な値だけを削除するようにしましょう.
また,補足ですがsc.broadcast(newData)でブロードキャストを実行しているように見えますが,実際にデータが送信されるのはブロードキャスト変数がワーカノードで参照された時になりますので,非同期とは言ったものの,ブロードキャスト変数を更新した後の最初の1回目の参照ではどうしても値を取得するための通信コストは発生します.
補足
今回のサンプルコードでは下記コマンドでデータを送出できます.
nc -lk 7777
参考
- Scala and Spark for Big Data Analytics: unpersist()の挙動に関して
- 初めてのSpark: ブロードキャスト変数の説明に関して
- SparkInternalsで知る、Sparkの内部構造概要(broadcast): ブロードキャスト変数の送信タイミングについて