アドベントカレンダー17日目です。
先月Lightbend社よりリリースされたCloudflowを触ってみました。チュートリアルをやりながらポイントだと思ったところを記事にしています。日本語でサクっと概要を知りたい方向けです!
また、本記事の元になった内容は公式ガイドに全て載っています。
Cloudflowとは
CloudflowはLightbend社によって開発されているOSSで、Kubernetes上に分散ストリーム処理を使ったアプリを高速に開発・運用することを目的としているようです。
ストリームの各処理を小さなコンポーネントに分割し、スキーマべースでコンポーネント同士を結合して、複雑なシステムを組み上げていきます。
現状、Akka Streams、Apache Spark、Apache Flinkのストリーム処理エンジンに統合可能で、Kubernetes環境にデプロイするまでに必要な開発や作業を簡単にできるようです。(ボイラープレートが不要だったり、Docker imageを生成するようなコマンド等を提供してくれている)
要するに、楽にストリーム処理を実現するためのフレームワークになります。
基本的な概念
まず、Cloudflowで登場する用語や概念をご紹介します。
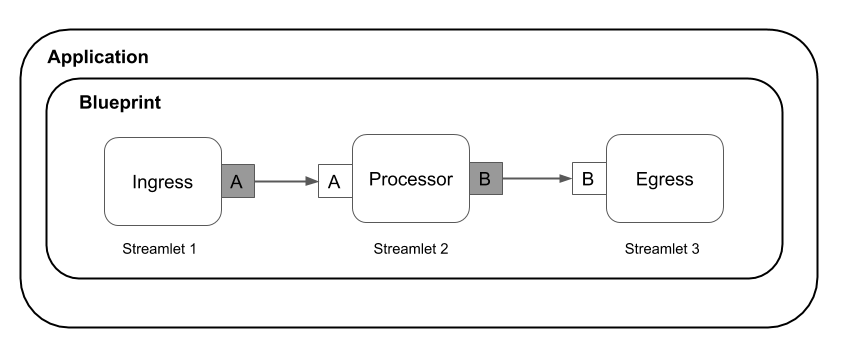
(引用: https://github.com/lightbend/cloudflow/blob/master/docs/images/apps.png)
図のIngress, Processor, EgressとなっているのがStreamletと呼ばれるコンポーネントで、コンポーネント同士は疎結合になります。Streamletはinlet、outletと呼ばれる入出力を持っていて、それを使って各コンポーネントと接続します。
StreamletはIngress, Processor, Egress, FanOutというshapeに分けられ、次のような違いがあります。
- Ingress: outletだけ持つ。入力はHTTPリクエスト等
- Processor: inlet/outletを1つずつ持つ。メインの処理はここに書く
- FanOut: Splitterとも呼ばれる。1つのinlet、複数のoutletを持つ。条件分岐するために使う。
- Egress: inletだけ持つ。Slackに通知、HDFSに書き込むといった何かしら副作用のある処理を書く。
また、Streamletを囲むBlueprintはまさに設計図のことで、スキーマベースで各Streamletの繋がりを表現するために使います。
Cloudflowで登場する用語はこのくらいです。概念自体はシンプルですね。Akka Streamsの開発元と同じなので、概念はどことなく似ています。
Getting Startedをやってみる
それでは、Cloudflowを触っていきます。
題材はhttps://cloudflow.io/docs/current/get-started/index.html です。
Hello World的なアプリケーションとして、*「風力発電所の各タービンから送信されるイベントを処理するパイプライン処理を作る」*をテーマにチュートリアルがありましたので、ローカルで起動するところまでやってみました。
チュートリアルはKubernetes環境にデプロイするところまで載っていますので、興味のある方は公式ガイドを参考にしてもらえればと思います。
準備
下記をインストール
- Java 8 (JDK)
- sbt(バージョン1.2.8以上)
※Kubernetes環境にデプロイする場合は、Dockerとkubectlも必要です。
全体像
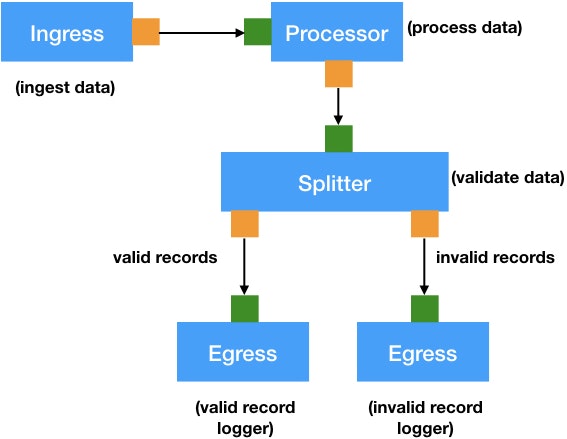
(引用: https://cloudflow.io/docs/current/get-started/wind-turbine-example.html)
全体像は上図の通りになります。見たままだと思いますが、流れを説明しますと下記のようになります。
- Ingressで入力データを受け付ける
- Processorで入力をドメインオブジェクトに変換する
- Splitterで入力値のバリデーションをして分岐する
- Egressでそれぞれの分岐に応じたログを記録する
それでは、次節から実際にコーディングしていきます。
プロジェクトの準備
プロジェクトの構成は下記のようになります。
|-project
|--cloudflow-plugins.sbt
|-src
|---main
|-----avro
|-----blueprint
|-----resources
|-----scala
|-------sensordata
|-build.sbt
ほぼsbtで同じみの構成かと思いますが、いくつか気になる部分がありますので下記に取り上げます。
-
project/cloudflow-plugins.sbt: Cloudflowをsbtで有効化するためのプラグインを記述するファイル -
avro: Xxx.avscといったavro形式でドメインオブジェクトを定義する。コンパイル時に動的にScalaファイルが生成される -
blueprint: Streamletを接続するためのスキーマを定義するblueprint.confを配置する
このように、avro形式でドメインオブジェクトを定義、blueprint.confでパイプラインを定義するところがポイントですね。
build.sbt
build.sbtは以下のように定義します。
import sbt._
import sbt.Keys._
lazy val sensorData = (project in file("."))
.enablePlugins(CloudflowAkkaStreamsApplicationPlugin)
.settings(
libraryDependencies ++= Seq(
"com.lightbend.akka" %% "akka-stream-alpakka-file" % "1.1.2",
"com.typesafe.akka" %% "akka-http-spray-json" % "10.1.10",
"ch.qos.logback" % "logback-classic" % "1.2.3",
"com.typesafe.akka" %% "akka-http-testkit" % "10.1.10" % "test"
),
name := "sensor-data",
organization := "com.lightbend",
scalaVersion := "2.12.10",
crossScalaVersions := Vector(scalaVersion.value)
)
ポイントは
.enablePlugins(CloudflowAkkaStreamsApplicationPlugin)
の部分で、CloudflowでAkka Streamsを使ったアプリケーションを作成する場合に、このプラグインを有効にします。Sparkを使いたいなら、下記を有効します。このように使うストリーム処理エンジンに応じて使い分けます。
.enablePlugins(CloudflowSparkApplicationPlugin)
また、cloudflow-plugins.sbtは下記の通りにします。
addSbtPlugin("com.lightbend.cloudflow" % "sbt-cloudflow" % "1.3.0-M5")
Avroでドメインオブジェクトを定義
ここでのドメインオブジェクトとは、Streamlet間で受け渡すオブジェクトのことです。
Avro形式で定義しておくと、コンパイル時にScalaファイルに変換してくれます。
このチュートリアルだといくつか用意しているのですが、全部載せると記事が長くなるので1つだけ掲載します。
{
"namespace": "sensordata",
"type": "record",
"name": "SensorData",
"fields":[
{
"name": "deviceId",
"type": {
"type": "string",
"logicalType": "uuid"
}
},
{
"name": "timestamp",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
},
{
"name": "measurements", "type": "sensordata.Measurements"
}
]
}
SensorDataは最初の入力となるオブジェクトです。Avroの説明は省略するとして、deviceId、timestamp、measurementsの3つのフィールドを持つスキーマだと何となく分かるかと思います。
そして、自動生成されるScalaファイルは以下のようになります。
/** MACHINE-GENERATED FROM AVRO SCHEMA. DO NOT EDIT DIRECTLY */
package sensordata
import scala.annotation.switch
case class SensorData(var deviceId: java.util.UUID, var timestamp: java.time.Instant, var measurements: Measurements) extends org.apache.avro.specific.SpecificRecordBase {
... //省略
}
一部省略して掲載していますが、avroファイルに定義したとおりのフィールドを確かに持っていることが分かると思います。
Streamletの実装
src/main/scala/sensordata以下にStreamletを実装していきます。
今回はAkka Streamsベースで実装するので、書き方もAkka Streamsっぽくなります。
ここでも全部のStreamletを掲載すると記事が長くなるため、入力部分に相当するIngressのStreamletとAkka StreamsのAPIを実際に使っているコードを掲載します。
Ingressの実装
package sensordata
import akka.http.scaladsl.marshallers.sprayjson.SprayJsonSupport._
import cloudflow.akkastream._
import cloudflow.akkastream.util.scaladsl._
import cloudflow.streamlets._
import cloudflow.streamlets.avro._
import SensorDataJsonSupport._
class SensorDataHttpIngress extends AkkaServerStreamlet {
// create an outlet that will use the default Kafka partitioning
val out =
// define the streamlet shapte
AvroOutlet[SensorData]("out").withPartitioner(RoundRobinPartitioner)
def shape = StreamletShape.withOutlets(out)
// override createLogic to provide the streamlet behavior
override def createLogic = HttpServerLogic.default(this, out)
}
AkkaServerStreamletを継承すると、HTTPで入力を受け付けるようなIngressを定義できます。また、Ingressはoutletさえ定義すれば良いです。ここでは入力をそのままoutletに流しています。
shape、createLogicの定義は無視するとして、ポイントは以下です。
AvroOutlet[SensorData]("out").withPartitioner(RoundRobinPartitioner)
outにSensorDataを流すことを定義しています。また、Streamlet同士はKafkaを経由して接続するため、Kafkaへの記録方法をRoundRobinPartitionerとして設定しています。Kafkaを経由することで、下記引用の通りですが、Streamlet間のライフサイクルを独立させる目的があるとのことです。
The data sent between Streamlets is safely persisted in the underlying pub-sub system, allowing for independent lifecycle management of the different components.
(引用: https://github.com/lightbend/cloudflow)
Processorの実装
続いて、Processorの実装を見てみましょう。
package sensordata
import cloudflow.akkastream._
import cloudflow.akkastream.scaladsl._
import cloudflow.streamlets.{ RoundRobinPartitioner, StreamletShape }
import cloudflow.streamlets.avro._
class SensorDataToMetrics extends AkkaStreamlet {
// define inlets and outlets
val in = AvroInlet[SensorData]("in")
val out = AvroOutlet[Metric]("out").withPartitioner(RoundRobinPartitioner)
// define the streamlet shape
val shape = StreamletShape(in, out)
// define a flow that makes it possible for cloudflow to commit reads
def flow = {
FlowWithOffsetContext[SensorData]
.mapConcat { data ⇒
List(
Metric(data.deviceId, data.timestamp, "power", data.measurements.power),
Metric(data.deviceId, data.timestamp, "rotorSpeed", data.measurements.rotorSpeed),
Metric(data.deviceId, data.timestamp, "windSpeed", data.measurements.windSpeed)
)
}
}
// override createLogic to provide streamlet behavior
override def createLogic = new RunnableGraphStreamletLogic() {
def runnableGraph = sourceWithOffsetContext(in).via(flow).to(sinkWithOffsetContext(out))
}
}
SensorDataをMetricに変換する処理をしているだけですが、Akka StreamsのAPIを呼び出している部分に注目したいです。
def runnableGraph = sourceWithOffsetContext(in).via(flow).to(sinkWithOffsetContext(out))
sourceWithOffsetContextはKafkaからレコードをコンシュームするためのAkka StreamsのAPIで、他にも、via, to等もAkka Streamsでお馴染のAPIです。
このように、Akka Streamsを使いながら、Cloudflowのフレームワークに載せることができるのです。
Blueprintを作る
Streamletを一通り実装し終えたら、いよいよStreamlet同士を繋ぎ込みます。
次のblueprint.confを定義します。
blueprint {
streamlets {
http-ingress = sensordata.SensorDataHttpIngress
metrics = sensordata.SensorDataToMetrics
validation = sensordata.MetricsValidation
valid-logger = sensordata.ValidMetricLogger
invalid-logger = sensordata.InvalidMetricLogger
}
connections {
http-ingress.out = [metrics.in]
metrics.out = [validation.in]
validation.invalid = [invalid-logger.in]
validation.valid = [valid-logger.in]
}
}
実装したStreamletを指定し、inlet/outletをどこに繋ぐか定義しています。コンフィグの中身は見た感じの雰囲気で何となく分かるかと思います。
重要な点はコンフィグファイルで定義していることですね。疎結合なStreamletはScalaファイルに記述し、どのように接続するかはコンフィグファイルに記述しています。
これによってランタイムにパイプラインを組めるようになります。
以上でコーディングは完了です。
実際に起動してみる
プロジェクト直下で下記コマンドを実行して、ストリーム処理を開始します。
$ sbt verifyBlueprint
$ sbt runLocal
[info] Streamlet 'sensordata.SensorDataToMetrics' found
[info] Streamlet 'sensordata.MetricsValidation' found
[info] Streamlet 'sensordata.SensorDataHttpIngress' found
[info] Streamlet 'sensordata.ValidMetricLogger' found
[info] Streamlet 'sensordata.InvalidMetricLogger' found
[success] /Users/mattsu/ideaProjects/cloudflow-test/src/main/blueprint/blueprint.conf verified.
[info] No local.conf file location configured.
[info] Set 'runLocalConfigFile' in your build to point to your local.conf location
---------------------------------- Streamlets ----------------------------------
http-ingress [sensordata.SensorDataHttpIngress]
- HTTP port [3000]
invalid-logger [sensordata.InvalidMetricLogger]
metrics [sensordata.SensorDataToMetrics]
valid-logger [sensordata.ValidMetricLogger]iptors 1s
validation [sensordata.MetricsValidation]
--------------------------------------------------------------------------------
--------------------------------- Connections ---------------------------------
validation.valid -> valid-logger.in
http-ingress.out -> metrics.in
validation.invalid -> invalid-logger.in
metrics.out -> validation.in
--------------------------------------------------------------------------------
------------------------------------ Output ------------------------------------
Pipeline log output available in file: /var/folders/zc/zzk9s6251d108k6nnc542nv00000gn/T/local-cloudflow765191599949274043/local-cloudflow2906863708067165705.log
--------------------------------------------------------------------------------
Running sensor-data
To terminate, press [ENTER]
起動時のログから公開されているポートが分かるので、そこへHTTPリクエストを送れば実際に動作を確認できます。
以下のように、httpリクエストを送ってみましょう。
※httpieコマンドをインストールしていなければ、curlコマンドでも大丈夫です。
$ http POST http://localhost:3000 Content-Type:application/json < <(echo '{"deviceId":"c75cb448-df0e-4692-8e06-0321b7703992","timestamp":1495545346279,"measurements":{"power":1.7,"rotorSpeed":23.4,"windSpeed":100.1}}')
すると、ログファイルに以下のようなログが記録されることが確認できます。
[INFO] [12/16/2019 19:34:27.403] [akka_streamlet-akka.actor.default-dispatcher-2] [akka.actor.ActorSystemImpl(akka_streamlet)] {"deviceId": "c75cb448-df0e-4692-8e06-0321b7703992", "timestamp": 1495545346279, "name": "power", "value": 1.7}
これで、ローカルで起動するところまではできました。チュートリアルではさらにGKE環境にデプロイするところまで書かれています。
おわりに
Cloudflowを少し触ってみました。これを使うと、主要なストリーム処理エンジンであればCloudflowのフレームワークに載せることができます。開発コストや運用コストがどの程度削減できるのかは、さらに触ってみないと分かりませんが、割と簡単にストリーム処理が書けるようになるのはその通りかと思います。
ただ、パッと思いつくだけでも懸念点はいくつかありそうです。例えば、Cloudflowの対応状況に引っ張られて、ストリーム処理エンジンの最新版が使えない状況はあるかも知れません。
そのため、プロダクション環境で使うにはまだまだ検証が必要そうです。