はじめに
アドベントカレンダー22日目です.
Akka Streamsでコレクションを分割して並列に処理する方法をカスタムGraphStageを実装して説明したいと思います.
通常,Akka Streamsで並列処理する場合はBroadcastやBalanceといったGraphStageを利用します.
BroadCastは同じ要素を異なるフローに渡して並列に処理したい場合に使います.例えば,あるログデータを一方はerrorだけ,もう一方はwarnだけ集計するような独立している後続処理がある場合に利用します.
Balanceは同じ要素を同じフローに渡して負荷分散したい場合に使います.例えば,あるログデータを集計する処理がボトルネックになるため負荷分散したい場合に利用します.
しかし,今回はコレクションを分割して並列に処理したいので,既存で用意されているGraphStageでは実現できません.
そこで,Distributeという入力を複数のコレクションに分割するファンアウトのGraphStageとSerialという複数の入力をまとめるファンインのGraphStageを作っていきます.
※本記事では説明のため必要なエラーハンドリングを省いていますので,完全なコードを見たい場合は後述するGithubのリンクよりご参照ください.
Distributeの実装
それではDistributeを実装していきます.
class Distribute[T <: Distributable[T]](size: Int) extends GraphStage[UniformFanOutShape[T, T]] {
...
まず,上記のようにGraphStageを独自に定義するためにはGraphStage[S <: Shape]を継承します.Shapeは入力と出力の数や型を表現します.ここではUniformFanOutShapeを使います.これは複数の同じの型の出力を持つShapeです. Distributableはdistributeというコレクションを分割するメソッドを持つtraitです.(本記事では紹介しませんので参考資料をご覧ください)
...
val in: Inlet[T] = Inlet[T]("Distribute.in")
val outs: Seq[Outlet[T]] = Seq.tabulate(size)(i => Outlet[T](s"Distribute.out$i"))
override val shape: UniformFanOutShape[T, T] = UniformFanOutShape(in, outs: _*)
...
続いてshapeを定義します.これを定義することで外部からGraphの持つ入力と出力等が分かるようになります.(GraphDSLで定義する場合に必要)
そしてcreateLogicを実装します.Akka Streamsはイベント駆動なので最低限以下のハンドラを実装する必要があります.
-
onPush: 新しい要素が入力に来たときに実行されるコールバック -
onPull: 次の要素を出力可能になったときに実行されるコールバック
下図がすごくわかりやすいです.onPush時にはpushで要素を次のフローに流し,onPull時にはpullで新しい要素を要求するというサイクルになっています.
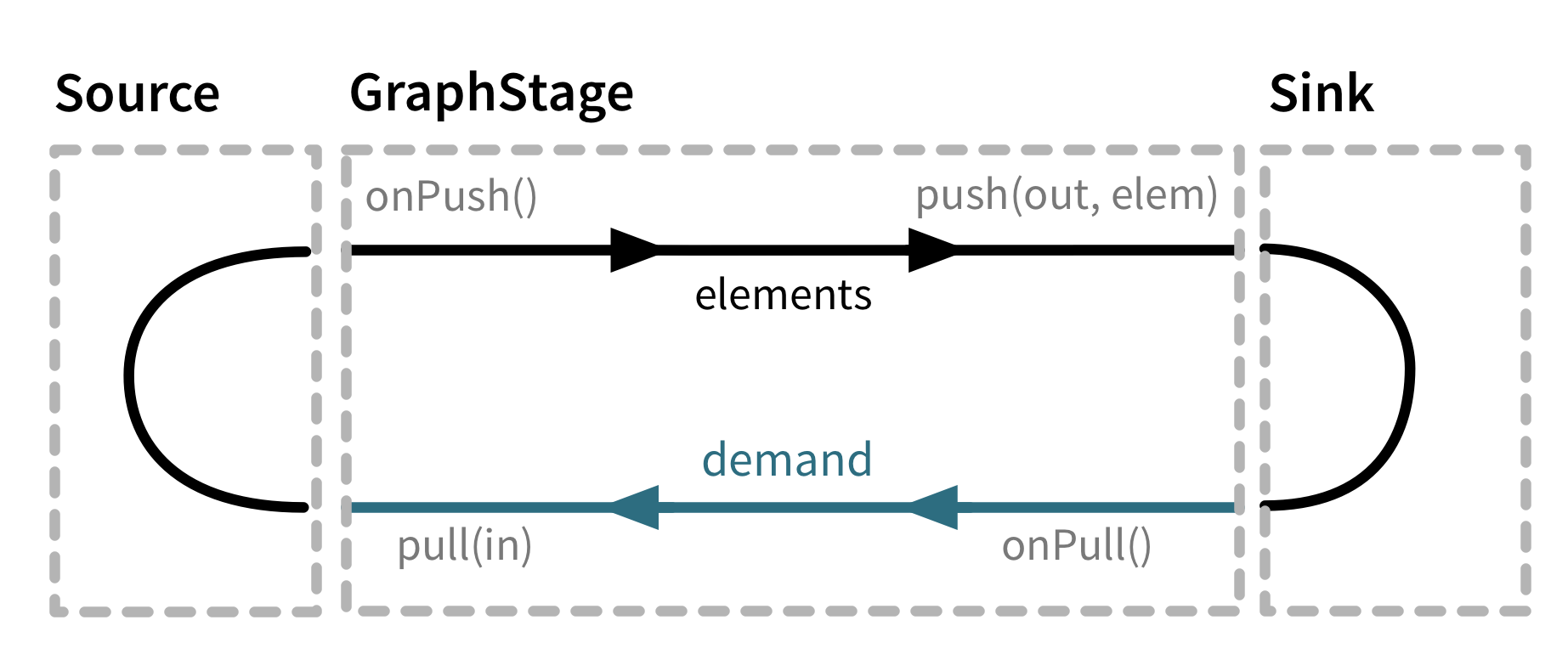
ということで,下記がcreateLogicの実装になっています.適宜コメントを書きましたのである程度分かるかなと思いますが,ポイントとなるのは
-
onPush時に入力のコレクションを分割 -
pendingCountによる出力ポートからのpull要求の管理
の2つです.
まず,入力を受け取った際に入力を分割する必要があるため,受け取る要素は必ずDistributableである必要があります.Distributableのdistributeによってコレクションを指定した数に分割し,分割した要素をそれぞれの出力ポートに流していきます.
また,全てのフローからpull要求があった場合に初めて上流にpullするように制御するため,pendingCountによって管理します.
...
override def createLogic(inheritedAttributes: Attributes): GraphStageLogic = new GraphStageLogic(shape) {
private var pendingCount = size
setHandler(
in,
new InHandler {
// 上流から新しい要素を受け取った時に実行されるコールバック
override def onPush(): Unit = {
pendingCount = size
// 新しい要素を取得して分割する
val elements = grab(in).distribute(size)
// Outletと出力する要素をzipしpushしていきます.
outs.zip(elements).foreach { e =>
if (!isClosed(e._1)) {
push(e._1, e._2)
}
}
}
}
)
outs.zipWithIndex.foreach { e =>
setHandler(e._1, new OutHandler {
// 下流から新しい要素を要求されたときのコールバック
override def onPull(): Unit = {
// 全てのポートからpullを受け取ったときに上流に対してpullする
pendingCount -= 1
tryPull()
}
})
}
private def tryPull(): Unit =
if (pendingCount == 0 && !hasBeenPulled(in)) pull(in)
}
...
これでDistributeは実装完了です.
Serialの実装
続いてDistributeによって分散したコレクションを1つにまとめるGraphStageを実装していきます.
要領としてはDistributeと同様ですのでコメントにて補足いたします.
// Distributeと異なり複数の入力を持つのでUniformFanInShapeを使う
// また要素を結合する関数を引数に渡す.これを使って分割したコレクションを1つにまとめる
class Serial[T](inputPorts: Int)(f: (T, T) => T) extends GraphStage[UniformFanInShape[T, T]] {
// 外部に公開するShapeを定義
val ins: Seq[Inlet[T]] = for (i <- 0 until inputPorts) yield Inlet[T](s"Serial.in$i")
val out: Outlet[T] = Outlet[T]("Serial.out")
override def shape: UniformFanInShape[T, T] = UniformFanInShape(out, ins: _*)
override def createLogic(inheritedAttributes: Attributes): GraphStageLogic = new GraphStageLogic(shape) {
var pending = 0
override def preStart(): Unit = ins.foreach(pull)
ins.foreach { in =>
setHandler(
in,
new InHandler {
// 全ての入力を受け取った後に下流にpushする
override def onPush(): Unit = {
pending -= 1
if (pending == 0) pushAll()
}
}
)
}
setHandler(out, new OutHandler {
// pullを受け取った際はpendingを更新する
override def onPull(): Unit = {
pending += ins.size
}
})
// 要素をpushかつ,全ての入力に新しい要素を要求する
private def pushAll(): Unit = {
push(out, ins.map(grab).reduce(f))
ins.foreach(pull)
}
}
}
object Serial {
def apply[T](inputPorts: Int)(f: (T, T) => T): Serial[T] = new Serial(inputPorts)(f)
}
DistributeとSerialを使ってみる
それでは以上の実装を実際に使ってみます.下記のようにSeq(1, 2, 3, 4)を用意し,これを3並列で動かしてみます.この時,並列化するフローに.asyncをつけるのを忘れないようにします.
Akka Streamsは基本的にシングルスレッドで動作するので,マルチスレッドで並列化したい場合はasyncメソッドを使う必要があります.
object Main extends App {
implicit val system = ActorSystem()
implicit val ec = system.dispatcher
implicit val materializer = ActorMaterializer()
val distributedFlow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val distribute = b.add(Distribute[Elements](3))
val serial = b.add(Serial[Elements](3)((a, b) => a + b))
val flow = Flow[Elements].map { elems =>
println(s"Thread id: ${Thread.currentThread().getId} for ${elems.value}"); Elements(elems.value.map(_ * 10))
}
distribute ~> flow.async ~> serial
distribute ~> flow.async ~> serial
distribute ~> flow.async ~> serial
FlowShape(distribute.in, serial.out)
})
Source.single(Elements(Seq(1, 2, 3, 4))).via(distributedFlow).runWith(Sink.seq).foreach(println)
}
実行結果
Thread id: 13 for List(1)
Thread id: 12 for List(3, 4)
Thread id: 17 for List(2)
Vector(Elements(List(10, 20, 30, 40)))
マルチスレッドかつ,コレクションを分割して並列に実行することができました.
これを利用することで,サイズの大きなコレクションも並列化して高速に処理できるようになりますので,是非ご活用ください.
参考資料
- Akka Documentation, https://doc.akka.io/docs/akka/2.5/stream/stream-parallelism.html