Google Cloud Next Tokyo ’23というGoogle Cloudのイベントに参加してきました!
2日間のイベントということで両日とも参加してきましたが、今回は2日目の基調講演を中心に発表します。
リンク:Google Cloud Next Tokyo ’23

1日目は生成AIのお話が中心で、2日目は生成AIを含む新しいクラウドの使い方が開発従事者のデベロッパーエクスペリエンスをどのように変えていくかといった観点でのお話で、大きく以下にまとまっていました。
- Googleソフトウェアのイノベーションについて
- Googleクラウドのテクノロジーについて
- Google Cloudを採用している企業のご紹介
Googleソフトウェアのイノベーションについて

1998年
検索エンジンの仕組みはどこにでもあるようなPCで構築
デメリット→特定のデータがどこにあるかを追跡するのが難しい、PCディスクもよく壊れる、データセンター間のデータ転送はハードドライブを満載した車で物理的に移動など

2003年
分散ファイルシステムの構築開始
2010年
Colossusの誕生
→回復力に優れたスケーラブルなバージョンへ進化
仮想マシンのディスク、オブジェクトストレージ、データベース、Googleドライブ内のファイル、YouTubeファイルが保存されている(現在も使用されている)
リンク:Colossus の仕組み: Google のスケーラブルなストレージ システムの舞台裏
運用負荷という面でも右肩あがり
数千台のPCを管理し効率的に運用する必要が出てきた
2003年
Borgの誕生
→Googleクラウドの全てのアプリケーションをオーケストレーションするシステム
データセンター運用に欠かせない技術
2013年
Kubernetesの誕生
→Borgと同じコンセプトのオープンソースバージョン
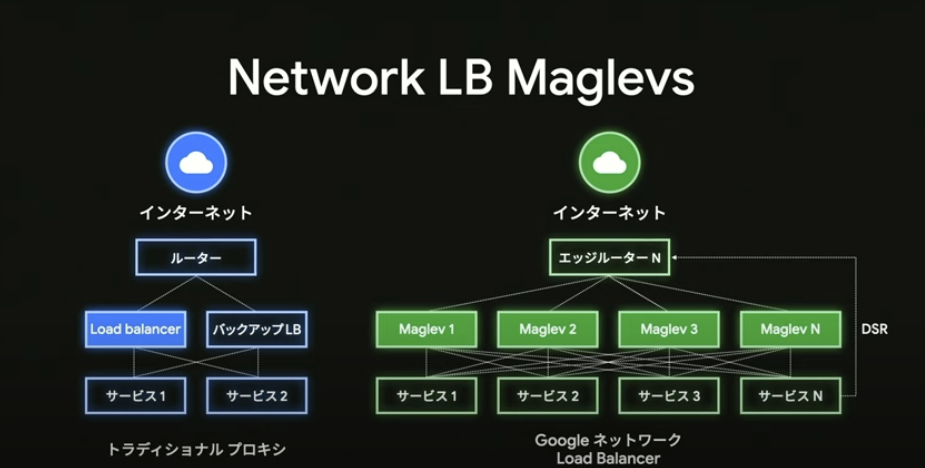
ロードバランサーの話
2008年
サードパーティ製のハードウェアデバイス使用
→レイヤーカプセル化ができなく(ネットワーク層)、ネットワークがARPストームと呼ばれる一種のトラフィックに遭遇すると壊滅的な障害モードに陥る
→ベンダーからはこの修正は不可能と言われたが、サービス運用のSREチームは汎用linuxサーバ上のソフトウェアで独自の負荷分散の仕組みを作り上げた
2009年以降
上記がクラウドロードバランシングを含む全てのデータセンタートラフィックの分散を行なっている高速で信頼性の高いNetwork LB Maglevsを開発したきっかけとなった
25年の中で特に重要なソフトウェアイノベーション
現在でもGoogleの各サービスを支えるデータセンター運用の根幹をなしている
→これらのアイデアは突然生まれたのではなく非常に泥臭いタスクをこなし、それをいかに合理的に効率化するかと悩み抜いたところからイノベーションが生まれていった
→Googleの強み!これらのテクノロジーを土台としてGoogle Cloudの各サービスは提供されていき、この強固な土台があるからこそ各サービスを素早く進化させ新しいクラウドの使い方を提供できる!
これらの話を聞いて、Kubernetesについて改めて復習してみました。
業務において開発環境構築では使いますが、本番環境などで使用したことがなく
概念をさらっと見たことしかなかったためです。
改めてDockerとは
普段開発業務で環境構築をする歳にdocker buildなどしていますが
そもそもDockerとは「データやプログラムを隔離できる仕組み」です。
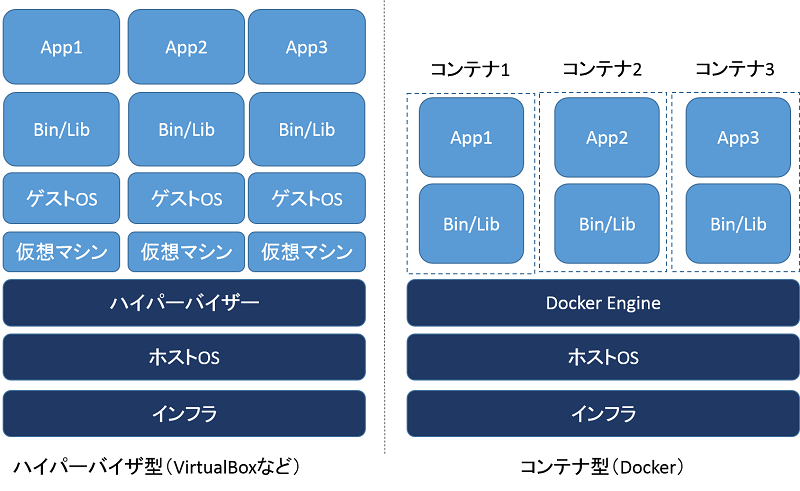
コンテナ
- データやプログラムが入っている独立した物置のこと
→コンテナを作成するにはDocker Engine(サーバー側のアプリケーション)で操作し、イメージと呼ばれるコンテナの素になるものから生成する。併せて何らかの形でLinuxが必要
コンテナに入れるプログラムもLinux用のプログラムとなっており、プロセスはイメージの作成、コンテナの実行、オーケストレーションなどがある
イメージ
- 金型のようなもの。イメージからコンテナを作成して利用する(PHPやMySQLなど)
Kubernetes(k8s)とは?
Kubernetes
- コンテナのオーケストレーションツール
→オーケストレーションツールとはシステム全体の統括をし、複数のコンテナを管理できるようにするもの
一般的なプログラマーが管理することは少ないよう(インフラ側の人が触る?)
リンク:Kubernetesの基礎から実際に使ってわかったメリット・デメリットまで解説 - NCDC株式会社
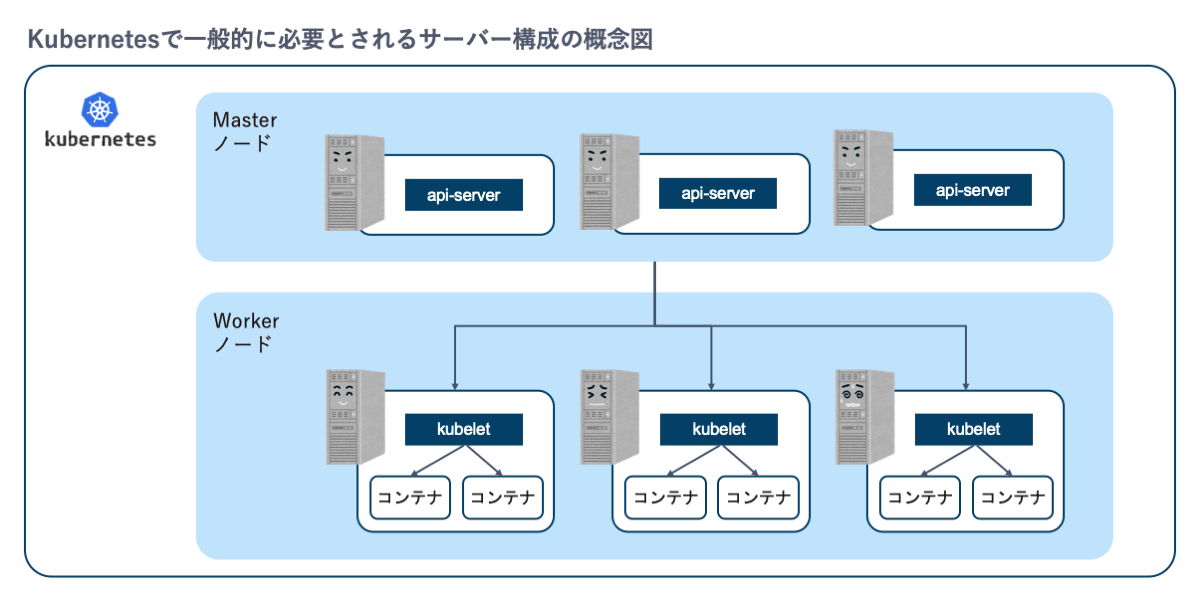
Kubernetesは複数の物理的マシンに複数のコンテナがあることが前提
→Dockerは1台の物理的マシンで実行するイメージだったが、Kubernetesは複数の物理的マシンがあることが前提でその1台1台の物理的マシンの中に複数のコンテナがある
→その複数コンテナを1台ずつ作ったり管理したりするのが大変なので、Kubernetesがある
(20個コンテナを作ろうと思ったら20回docker runコマンドを実行するため)
こうしたコンテナの作成や管理の煩雑さを上手くやってくれるツール。小規模な場合だとオーケストレーションはDocker ComposeやDocker Swarmなどを使うことが多いよう
マスターノード
- コントロールを司るノード。マスターノード上でコンテナは動いておらず、ワーカーノード上のコンテナを管理するだけ
ワーカーノード
- 実際に動かすノード
クラスター
- マスターとワーカーで構成されたKubernetesシステムの一群のこと
使用にはKubernetesとCNIをインストールしないといけなく、マスターノードにはetcd(DB)を入れワーカーノードのはContainer Engineを入れる
望ましい状態に保つため、基本的に手動で管理はしない(20個のうち1つを停止させると設定によっては勝手に立ち上がったりするため)
Googleクラウドのテクノロジーについて
モダンインフラストラクチャークラウドに関する最新アップデートについてです。
AI-optimized infrastructure
- 機械学習のトレーニングやサービス化のための推論を行うためのインフラストラクチャ
Cloud TPU v5e(効率的、多彩、拡張性)
リンク:Cloud TPU v5e 推論の概要
G2VMからA3VMsへ
2024年6月に東京リージョンで利用可能
Modern and Enterprize Workloads
- 複雑で高度な要件や運用が求められるワークロードに対して高度な機能を提供
2027年までにグローバル組織の90%以上は、コンテナ化されたアプリケーションを
本番環境で実行するようになると予想されている(2021年は40%未満)
コンテナ活用の最初の一歩として
- Cloud Run(サイドカー対応)
- Google Kubernetes Engine
Reliable and scalable infrastructure
- Googleのサービスを支える信頼性の高いスケーラブルなインフラストラクチャ
GKE Enterprise editionはよりパワフルなKubernetesエコシステムを利用できる
(実際にデモを見てみたがGUIで全てできる。クラスターポリシーではGoogle Cloudの業界標準ベストプラクティスの遵守データ利用できる)
Google Cloudを活用しているお客様の声
カプコン
ストリートファイター6のオンライン対戦などにGoogle Cloudが使われている
北國銀行
コンテナ化によるアプリケーションの見直し、Windows・COBOLからの脱却
コールセンターで使えるDuet AI・Vertex AIなどのAI ecosystem
非構造化データの価値をLLM(大規模言語モデル)で引き出す
BigQueryを用いて録音データをテキスト変換し、内容から顧客がどう感じているかの理由分析などができる
リンク:データドリブンのイノベーションを推進するクラウド データ ウェアハウス
TBS
元々大規模ファイル共有を目的としてとして導入していたが、現在ではG SuiteやWorkspaceも活用している。社内学習やハッカソンの実施も
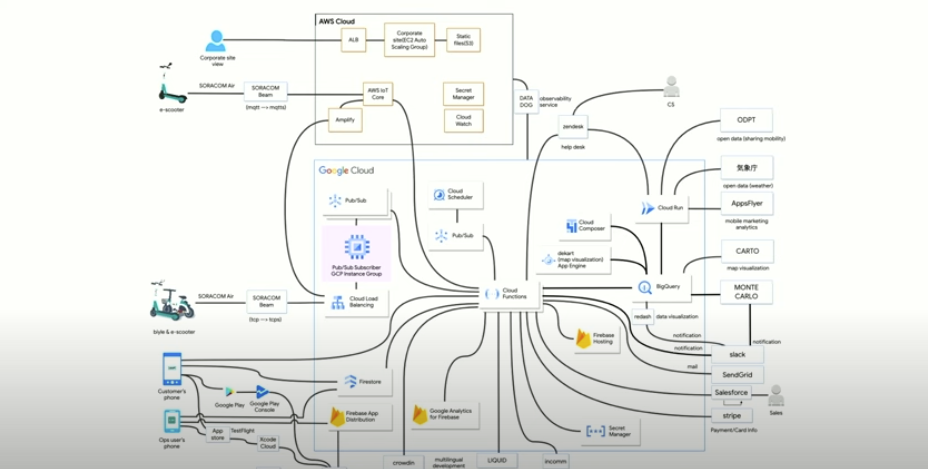
Luup
Googleのサービス(AnalyticsやBigQueryなど)を多数使用してシステム構築している
まとめ
- 様々な課題を泥臭く解決していった結果、今のGoogleがある
- GoogleはAIを絡ませこれからも進化を続けていく
- Kubernetesが採用されている現場にいつか参画してみたい!
来年は8月1日、2日にパシフィコ横浜で開催予定なので、当社のスキルアップ休暇を使ってご参加いただければと!![]()