この記事は Vim Advent Calendar 2018 の最終日 25 日目の記事です。昨日は rhysd さんの「Vim の構文ハイライトでクリスマスツリー🎄を飾ってメリクリする」でした。今年も Vim Advent Calendar は完走しました。皆さんお疲れさまでした。
はじめに
昨今 Vim script は目覚ましい進化を遂げ、Vim script からタイマーも実行でき、プロセスを起動して非同期に通信できる様にもなりました。以前の様にコマンドを実行して Vim でのテキスト入力を妨げる事も少なくなってきました。
Vim script が扱える数値も既に64bit化されています。現在 pull-request されている blob 型 も入れば、ほぼ他の言語と同等の機能を得たと言えるでしょう。1
しかしながら世の中のプログラミング言語は機械学習へと足を延ばし、大量のデータを計算する仕組みを実装し始めています。Vim script も遅れを取ってはなりません。
そう思いませんか?

機械学習やるぞ
そこで今回、Vim script で機械学習を扱う為の仕組みを用意しました。外部コマンドは使っていません。また if_python 等の言語拡張も使っていません。Vim script のみで実装しました。
https://github.com/mattn/vim-brain
Vim script で実装したニューラルネットワークになります。中身は Go言語で実装されている goml/gobrain の完全移植版となります。ただし以前ブログで紹介した、goml/gobrain のモデル保存機能も実装してあります。
えっ?Vim script だけで機械学習が出来るんですか?それ超便利だと思いませんか?

まずは簡単な学習から
使い方は goml/gobrain と変わりません。まずは XOR を学習させてみます。
function! s:test() abort
call brain#srand(0)
let l:patterns = [
\ [[0.0, 0.0], [0.0]],
\ [[0.0, 1.0], [1.0]],
\ [[1.0, 0.0], [1.0]],
\ [[1.0, 1.0], [0.0]],
\]
let l:ff = brain#new_feed()
let l:ff.Init(2, 2, 1)
call l:ff.Train(l:patterns, 1000, 0.6, 0.4, v:false)
call l:ff.Test(l:patterns)
endfunction
call s:test()
pattern は2項の配列で構成され、左が入力、右が期待値になります。brain#new_feed() でフィードフォワードを生成し、Init で初期化します。引数はそれぞれ
- 1入力の値の個数
- 隠れ層の数
- 1期待値の値の個数
となります。XOR は2つの入力から1つの期待値を出すので 2 と 1 ですね。
Train の第一引数に作ったパターンを渡し、イテレーション数 1000、学習レート 0.6、モーメンタムファクタ(活性化係数) 0.4、デバッグ false で実行しています。
このコードですと、Vim script でも2秒程で学習と検証が完了します。余裕ですね。
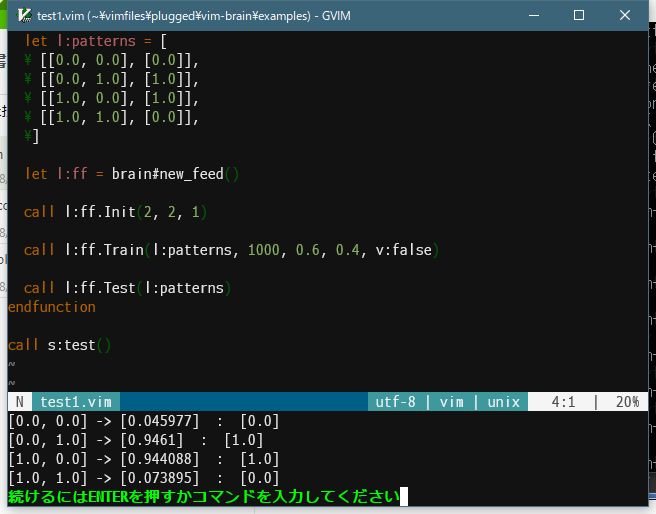
結果もちゃんと出ていますね。
Jupyter Notebook でオシャレに機械学習
Vim Advent Calendar その2 の nohararc さんの記事「Jupyter notebookでもVim scriptが書きたい!」で Jupyter Notebook 上で Vim script を実行されておられたのに感銘し、僕もやってみたくなりました。nohararc さんの実装はセルを実行する毎に Vim を起動しているので処理を継続出来ませんでしたので、python 側で Vim を常駐させておき、入力ファイルを監視させつつ出力ファイルを python 側から読み取る実装にしてみました。
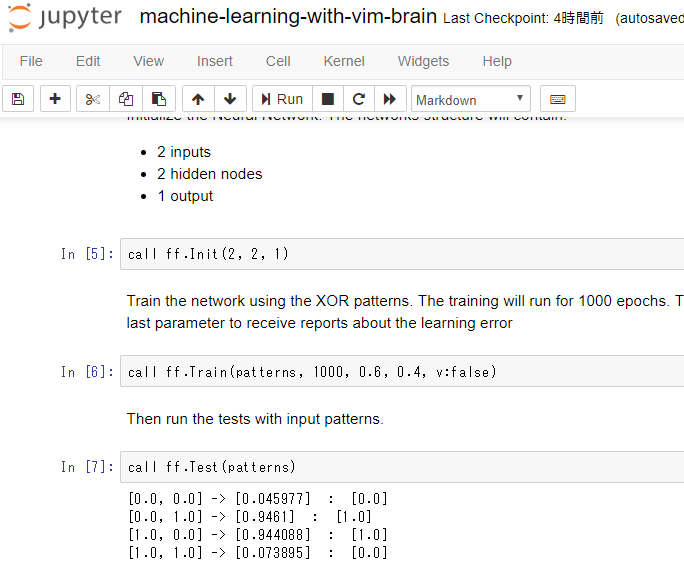
Jupyter Notebook で XOR を学習させた際の記録を以下に置いてあります。
Markdown で説明を書きつつ手順を残せるのでとても人に伝えやすくなりました。今後「Vim script で機械学習やってみたいな」と思われる方が増えると嬉しいですね。
この Vim kernel をインストール出来る様に GitHub に置いておきました。
詳しくは README.md を参照下さい。
ちょっと難しい学習
さて話を戻し今度は少し難しい学習をさせてみます。FizzBuzz を食わせて学習し、どう動くかを確かめます。まずは学習に必要な実装を作ります。
let s:bits = has('num64') ? 64 : 32
let s:mask = s:bits - 1
let s:mask32 = 32 - 1
let s:pow2 = [1]
for s:_ in range(s:mask)
call add(s:pow2, s:pow2[-1] * 2)
endfor
unlet s:_
function! s:lshift(a, n) abort
return a:a * s:pow2[and(a:n, s:mask)]
endfunction
function! s:rshift(a, n) abort
let n = and(a:n, s:mask)
return n == 0 ? a:a :
\ a:a < 0 ? (a:a - s:min) / s:pow2[n] + s:pow2[-2] / s:pow2[n - 1]
\ : a:a / s:pow2[n]
endfunction
function! s:bin(n) abort
let l:f = repeat([0.0], 8)
for l:i in range(8)
let l:f[i] = 0.0 + and(s:rshift(a:n, l:i), 1)
endfor
return l:f
endfunction
function! s:dec(v) abort
let [l:maxi, l:maxv] = [0, 0.0]
for l:i in range(len(a:v))
if a:v[l:i] > l:maxv
let l:maxv = a:v[l:i]
let l:maxi = l:i
endif
endfor
return l:maxi
endfunction
function! s:teacher(n) abort
if a:n%15 == 0
return [1, 0, 0, 0]
elseif a:n%3 == 0
return [0, 1, 0, 0]
elseif a:n%5 == 0
return [0, 0, 1, 0]
else
return [0, 0, 0, 1]
endif
endfunction
function! s:test() abort
call brain#srand(0)
let l:patterns = []
for l:i in range(1, 100)
call add(l:patterns, [s:bin(i), s:teacher(i)])
endfor
let l:ff = brain#new_feed()
let l:ff.Init(8, 100, 4)
call l:ff.Train(l:patterns, 1000, 0.6, 0.4, v:true)
for l:i in range(1,100)
let l:r = s:dec(l:ff.Update(s:bin(l:i)))
if l:r == 0
echo "FizzBuzz"
elseif l:r == 1
echo "Fizz"
elseif l:r == 2
echo "Buzz"
else
echo l:i
endif
endfor
endfunction
call s:test()
仕組みは XOR とほぼ同じですが、FizzBuzz の場合は以下の4つを期待値とします。
- Fizz
- Buzz
- FizzBuzz
- 数値
検証時にはその値を元に分岐を行います。
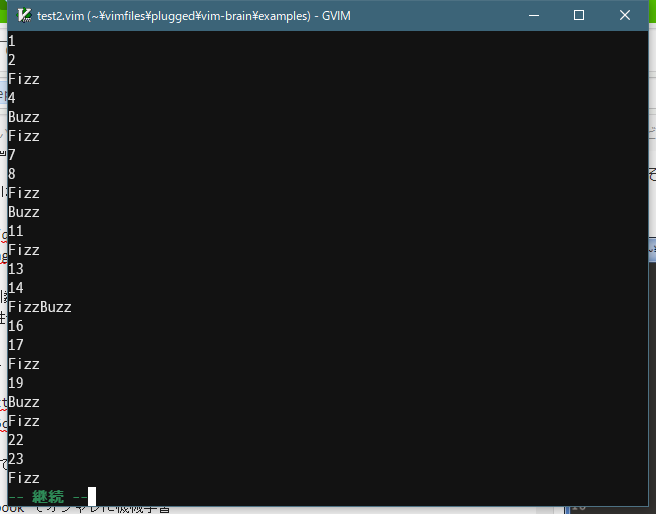
結果は問題ありませんでした。ただ学習に時間が結構掛かります。Intel Core i5、メモリ16GB (ノートPC)の Windows で約1分掛かります。同じコードを golang で書いて実行すると3~4秒なので、単純に Vim script は golang の20倍くらい遅い事になります。2
※もちろん皆さんご存じの通り、学習した範囲ではおおよそ動きますが、そうでないならば15で割り切れるけれど学習した事のない 450 等を食わせても FizzBuzz になる訳ではないのです。学習のさせ方次第ではあります。
モデルを保存できる
FizzBuzz の学習に1分掛かったとしても、学習結果が保存できるなら実用では推論だけで勝負出来ます。golang で同じコードを書いて保存した FizzBuzz 用のモデルファイル(JSON)を用意しました。大きすぎるので以下の Gist に貼り付けてあります。
https://gist.github.com/mattn/e4d8a2009627bda289928e8f370b33f2
※分かりやすい様にフォーマットしました。
※3000行デカすぎる?聞こえませんね
モデルファイルの読み込みには brain#load_model という関数を用意してあります。これにファイル名を指定して JSON ファイルを読み込みます。コードも学習の必要が無くなるのでこんなにスッキリしました。
function! s:test() abort
let l:ff = brain#load_model('fizzbuzz.json')
for l:i in range(1,100)
let l:r = s:dec(l:ff.Update(s:bin(l:i)))
if l:r == 0
echo "FizzBuzz"
elseif l:r == 1
echo "Fizz"
elseif l:r == 2
echo "Buzz"
else
echo l:i
endif
endfor
endfunction
実行結果も一瞬で表示されます。Vim script サイコー!そう思いませんか?

まぁまぁ難しい学習
こうなってくると Vim から実用したくなります。例えば以下のソースコードを見て下さい。
require 'open-uri'
open(url) do |file|
puts file.read
end
プログラマの皆さんならば、これが Ruby のコードだと分かるはずですが Vim は分かりません。ある程度 Vim のファイルタイプ判別もやってくれるのですが、もしファイル名が特徴的でなかったりするとシンタックスハイライトされないのです。一大事ですね。
そこでこの vim-brain を使ってプログラミング言語を判別し、&filetype オプションに設定すべき言語名を推論する仕組みを考えてみました。
プログラミング言語の判別
プログラミング言語の判別には何種類か方法があるのですが、ソースコードからキーワードを抜き出し、キーワードの入力および言語名の期待値から作られるパターンを作り学習させるのが一番簡単な方法と思います。この仕組みは guesslang という Python モジュールでも使用されている実績のある方法です。
※guesslang では TensorFlow を使っているので高速に処理されます。
モデルファイルの生成
モデルは、著名な OSS のソースコードを読みこんでキーワードに分割、全体母数を得た後で再度解析して入力と期待値を構成します。解析は以下の OSS を利用させて頂きました。
| 言語 | 解析に使用したOSS |
|---|---|
| C | h2o |
| C++ | OpenCV |
| Ruby | Sinatra |
| Perl | Plack |
| PHP | Laravel |
| Go | Go |
ディレクトリを探索し、Ruby, PHP, Perl, C, C++, Go のソースを解析します。学習に与えるパターンは固定個で無ければなりませんので、一旦全てのキーワードを抜き出して母数(全キーワード数、全言語数)を得ます。続けて再度キーワードを含む入力と言語インデックスをエンコードした値を期待値としたパターンを作ります。言語インデックスとは languages.json に含まれる配列の添え字に当たります。
実はこのディレクトリ探索やキーワード抽出と言った前準備から全て Vim script でやろうと試みたのですが、いかんせん膨大なデータを処理する必要があり、なおかつ学習に数日かかる(4時間まで我慢しましたが20イテレーションすら到達できませんでした)見込みである事が分かっています。そこで泣く泣く golang の力を借りました。
package main
import (
"encoding/json"
"flag"
"fmt"
"io/ioutil"
"log"
"math/rand"
"os"
"path/filepath"
"regexp"
"sort"
"strings"
"github.com/goml/gobrain"
)
var extMap = map[string]string{
".rb": "ruby",
".php": "php",
".pm": "perl",
".pl": "perl",
".c": "c",
".cc": "cpp",
".cxx": "cpp",
".go": "go",
}
func removeComment(lang, code string) string {
if lang == "c" || lang == "cpp" || lang == "go" {
re := regexp.MustCompile("(?s)//.*?\n|/\\*.*?\\*/")
code = re.ReplaceAllString(code, "")
}
if lang == "perl" || lang == "ruby" {
lines := strings.Split(code, "\n")
for i := 0; i < len(lines); i++ {
if strings.HasPrefix(strings.TrimSpace(lines[i]), "#") {
lines[i] = ""
}
}
code = strings.Join(lines, "\n")
}
return code
}
var allKws = map[string]struct{}{}
var pat = regexp.MustCompile(`\b\w+`)
func keywords(lang, code string, kws []string) []float64 {
kwf := make([]float64, len(kws))
words := pat.FindAllString(removeComment(lang, code), -1)
kc := 0
for _, v := range words {
n := find(kws, v)
if n != -1 {
kwf[n]++
kc++
}
}
fmt.Println(words)
for i := 0; i < len(kwf); i++ {
if kwf[i] > 0 {
kwf[i] /= float64(kc)
}
}
return kwf
}
func analyze(name string) bool {
if strings.Contains(name, "/.") {
return false
}
lang, ok := extMap[strings.ToLower(filepath.Ext(name))]
if !ok {
return false
}
b, err := ioutil.ReadFile(name)
if err != nil {
return false
}
for _, v := range pat.FindAllString(removeComment(lang, string(b)), -1) {
allKws[v] = struct{}{}
}
return true
}
func allLanguages() []string {
l := []string{}
langs := map[string]struct{}{}
for _, v := range extMap {
langs[v] = struct{}{}
}
for k := range langs {
l = append(l, k)
}
sort.Strings(l)
return l
}
func allKeywords() []string {
ks := []string{}
for k := range allKws {
ks = append(ks, k)
}
sort.Strings(ks)
return ks
}
type BasicEncoderDecoder struct {
labels []string
}
func (c BasicEncoderDecoder) EncodeLabel(label string) []float64 {
hasil := []float64{}
for _, l := range c.labels {
if l == label {
hasil = append(hasil, 1.0)
} else {
hasil = append(hasil, 0.0)
}
}
return hasil
}
func (c BasicEncoderDecoder) DecodeLabel(label []float64) string {
maxIndex := 0
maxValue := 0.0
for i, l := range label {
if l > maxValue {
maxIndex = i
maxValue = l
}
}
return c.labels[maxIndex]
}
func find(a []string, x string) int {
for i, n := range a {
if x == n {
return i
}
}
return -1
}
func saveModel(ff *gobrain.FeedForward) error {
f, err := os.Create("guesslang.json")
if err != nil {
return err
}
defer f.Close()
return json.NewEncoder(f).Encode(ff)
}
func loadModel() (*gobrain.FeedForward, error) {
f, err := os.Open("guesslang.json")
if err != nil {
return nil, err
}
defer f.Close()
ff := &gobrain.FeedForward{}
err = json.NewDecoder(f).Decode(ff)
if err != nil {
return nil, err
}
return ff, nil
}
func saveKeywords() error {
f, err := os.Create("keywords.json")
if err != nil {
return err
}
defer f.Close()
return json.NewEncoder(f).Encode(allKeywords())
}
func saveLanguages() error {
f, err := os.Create("languages.json")
if err != nil {
return err
}
defer f.Close()
return json.NewEncoder(f).Encode(allLanguages())
}
func loadKeywords() ([]string, error) {
f, err := os.Open("keywords.json")
if err != nil {
return nil, err
}
var keywords []string
err = json.NewDecoder(f).Decode(&keywords)
if err != nil {
return nil, err
}
return keywords, nil
}
func loadLanguages() ([]string, error) {
f, err := os.Open("languages.json")
if err != nil {
return nil, err
}
var languages []string
err = json.NewDecoder(f).Decode(&languages)
if err != nil {
return nil, err
}
return languages, nil
}
func main() {
flag.Parse()
kws, _ := loadKeywords()
langs, _ := loadLanguages()
ff, _ := loadModel()
enc := &BasicEncoderDecoder{langs}
fmt.Println(len(kws), len(langs))
if len(kws) == 0 || len(langs) == 0 || ff == nil {
base, err := filepath.Abs(flag.Arg(0))
if err != nil {
log.Fatal(err)
}
names := []string{}
err = filepath.Walk(base, func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
if !info.IsDir() && info.Name() != ".git" {
path = filepath.ToSlash(path)
if analyze(path) {
names = append(names, path)
}
}
return nil
})
kws = allKeywords()
langs = allLanguages()
enc = &BasicEncoderDecoder{langs}
visit := map[string]int{}
for _, l := range langs {
visit[l] = 0
}
rand.Seed(0)
patterns := [][][]float64{}
for _, name := range names {
if strings.Contains(name, "/.") {
continue
}
lang, ok := extMap[strings.ToLower(filepath.Ext(name))]
if !ok {
continue
}
if visit[lang] > 20 {
continue
}
log.Println(lang, name)
b, err := ioutil.ReadFile(name)
if err != nil {
continue
}
kf := enc.EncodeLabel(lang)
kw := keywords(lang, string(b), kws)
patterns = append(patterns, [][]float64{
kw, kf,
})
visit[lang]++
}
println(len(kws), len(langs), len(patterns))
ff = &gobrain.FeedForward{}
ff.Init(len(kws), len(langs), len(langs))
ff.Train(patterns, 100, 0.6, 0.4, true)
saveModel(ff)
saveKeywords()
saveLanguages()
}
input := keywords("", `
require 'sinatra'
get '/' do
'Hello world!'
end
`, kws)
vv := ff.Update(input)
fmt.Println(enc.DecodeLabel(vv))
}
※golang を使ってもモデルファイルを生成するのに2時間掛かります。
コードの最後で Ruby のコードを判別していますが、問題なく ruby と表示されます。
Vim script でプログラミング言語を判別
生成した JSON ファイルは 38MB もありますが Vim script の JSON の読み込みはC言語の実装です。それほど遅くならない事を期待しながら、別途用意したファイルを読み込み推論してみましょう。
let s:base = fnamemodify(expand('<sfile>') . '/../data', ':p')
function! s:enc(l, n) abort
let l:f = repeat([0.0], len(a:l))
for l:i in range(len(a:l))
if a:l[l:i] == a:n
let l:f[l:i] = 1.0
endif
endfor
return l:f
endfunction
function! s:dec(v) abort
let [l:maxi, l:maxv] = [0, 0.0]
for l:i in range(len(a:v))
if a:v[l:i] > l:maxv
let l:maxv = a:v[l:i]
let l:maxi = l:i
endif
endfor
return l:maxi
endfunction
if !exists('s:kwd')
let s:kws = json_decode(join(readfile(s:base . '/keywords.json'), "\n"))
endif
if !exists('s:lng')
let s:lng = json_decode(join(readfile(s:base . '/languages.json'), "\n"))
endif
if !exists('s:ff')
let s:ff = brain#load_model(s:base . '/guesslang.json')
endif
function! s:keywords(code) abort
let l:kwf = repeat([0.0], len(s:kws))
let l:words = []
call substitute(a:code, '\<\w\+', '\=add(l:words, submatch(0)) == [] ? "" : ""', 'g')
let l:kc = 0.0
for l:v in l:words
let l:n = index(s:kws, l:v)
if l:n != -1
let l:kwf[l:n] += 1.0
let l:kc += 1.0
endif
endfor
for l:i in range(len(l:kwf))
if l:kwf[l:i] > 0.0
let l:kwf[l:i] = l:kwf[l:i] / kc
endif
endfor
return l:kwf
endfunction
function! s:test() abort
let l:input = s:keywords(join(readfile('test.cc'), "\n"))
let l:r = s:dec(s:ff.Update(l:input))
echo s:lng[l:r]
endfunction
call s:test()
s:enc と :dec はラベル名(プログラミング言語名)をインデックス値としてエンコード/デコードする為の実装、s:keywords は golang で実装した方法と同じ方式でソースコードからキーワードを抜き出す為の実装です。
推論に使用したソースファイルは以下の簡単な C++ のソースファイルです。
# include <iostream>
# include <string>
# include <algorithm>
int
main(int argc, char* argv[]) {
std::vector<std::string> v;
return 0;
}
実行すると10秒後に以下の様に表示されます。
cpp
うまく動きました。その他、上記の golang のソース自身や、そのコードの一番下にある ruby のコードも正しく判別できています。やったぜ!ただC言語と PHP を混同する事が結構多いのですが、これはワード単位のランク付けになっているので、今回見付かった PHP のソースコードにC言語のキーワードと似た物が多く含まれていた結果だと思います。これについては今後、定量的な評価の上で調整し、もう少し精度の高いニューラルネットを作ろうと思います。
なお推論に10秒掛かる点に関して「遅すぎて実用に値しない」と思われるかもしれませんが、これを解決する簡単な方法を Vim の作者 Bram Moolennaar 氏が VimConf 2018 で言及されています。
Vim script が遅いと感じたら、速い PC を買って下さい。
尚、この記事を執筆してから気付いたのですが、Vim の記事なのに Vim script を解析に含める事を忘れていました。
まとめ
Vim script からニューラルネットワークを扱う為の仕組みを実装し、XOR と FizzBuzz の学習と推論を、また保存されたモデルファイルを使ってプログラミング言語の判別をやってみました。さらに皆さんでも汎用的に使って頂ける様に vim-brain というプラグインにしました。学習には golang の実装である goml/gobrain を使って頂き、生成したモデルファイル(JSON)を Vim で使って推論する事で、そこそこ実用的な結果1が得られる事が分かりました。今後は vim-brain の高速化、または Vim 本体の高速化に取り組み、いずれは誰でも簡単に Vim script による機械学習を試せる様に精進して参りたいと思います。
尚、前述の blob 型 が Vim 本体に導入された暁には、Vim script のみで画像の特徴抽出や判別も試してみたいと思います。