1. はじめに
前回に続いて、今回はsql関係を書きたいと思います。やはりコネクション関係よりも数が多く、まだまだ理解しきれていない部分もありますが、色々書いて行きます。事前に以下の知識は必須になるかと思います。
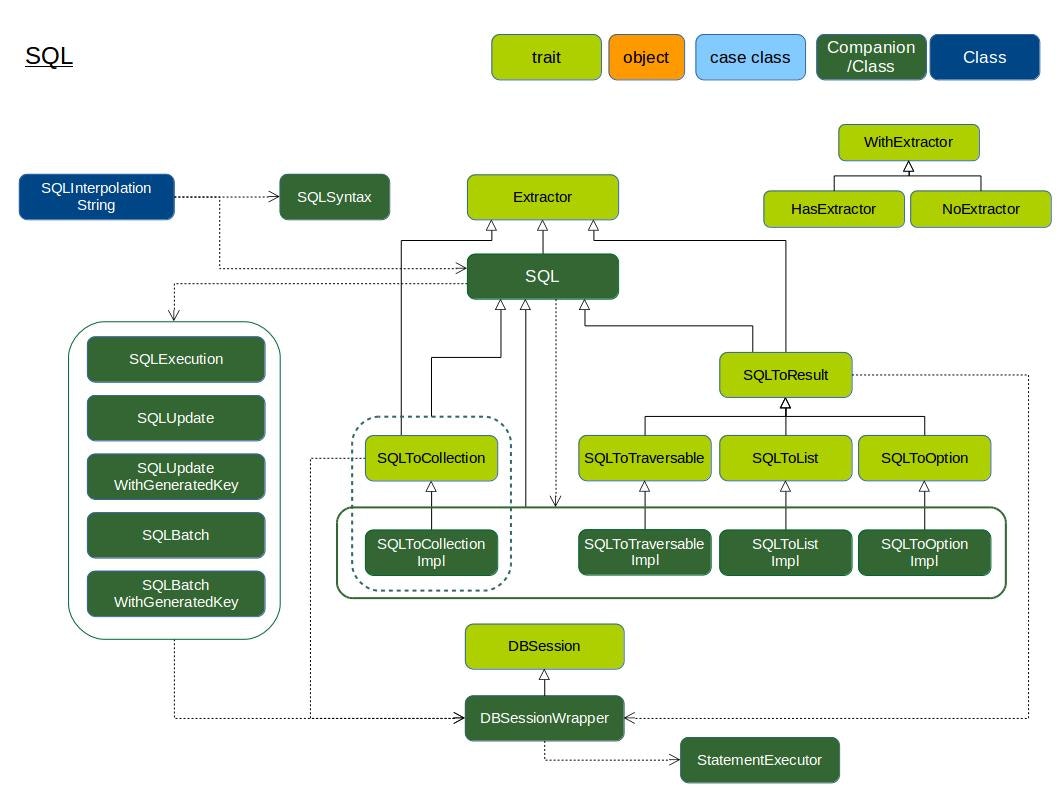
正確にはクラス図ではないかもしれませんが、理解の助けになるようにと思いまして、図もつけておきます。
2. SQL
その名の通り『SQL』が中心となるクラスになります。
SQLInterpolationStringが起点となり、『SQL』を継承したクラスがインスタンス化されます。
SQLを継承しているクラスは主に2系統あります。一つは『データ取得』で、もう一つは『作成・登録・更新・削除』関係です。
2.1 SQLInterpolationString
sqlで始まる宣言でSQLをインスタンス化しています。この時はSQLToTraversableImplがインスタンスとして作成されます。
def sql[A](params: Any*): SQL[A, NoExtractor] = {
val syntax = sqls(params: _*)
SQL[A](syntax.value).bind(syntax.rawParameters: _*)
}
sqlsは、SQLInterpolationStringの中で宣言されている別の関数で、SQLSyntaxを戻り値として返します。sql文の部品的な扱いをするためのクラスですが、内部的には全て一度SQLSyntaxとして宣言されます。
その後、SQLのapply(sql文)が呼ばれて、bind関数が呼ばれています。
def apply[A](sql: String): SQL[A, NoExtractor] = new SQLToTraversableImpl[A, NoExtractor](sql, Seq.empty)(noExtractor[A](
ErrorMessage.THIS_IS_A_BUG
))
このapply関数だけ見ていると、"THIS IS A BUG"とかあるので、本当に呼ばれているのか理解できていなかったのですが、後で呼ばれているbindがポイントになっています。
def bind(parameters: Any*): SQL[A, E] = {
withParameters(parameters).fetchSize(fetchSize).tags(tags: _*).queryTimeout(queryTimeout)
}
この中で呼ばれている『withParameters』は、trait『SQL』では以下の様に宣言されており、更に何が呼ばれているのかよくわからなくなります。
protected def withParameters(params: Seq[Any]): SQL[A, E] = ???
結局は、SQLToTraversableImplがインスタンス化されており、そのwithParametersが呼ばれています(その間に『SQL』のbindが呼ばれているだけです)。ちなみに『???』は、ScalaのPredef.scalaの一つの関数です。
2.2 データ取得関係
『データ取得』関係は、Extractorを継承しています。Extractorは、メソッド『extractor』が宣言されており、これは『WrappedResultSetを受け取り型[A]を返す関数』です。更に、『データ取得』関係は2系統に分かれており、直接コレクション型を指定可能なtrait(SQLToCollection)とSQLToResultを継承するtraitに分かれます。
全てapplyで『結果が返って』きます。Scalaのapplyと若干意味合いが異なります(SQLを適用の意味合い?)。
a) 直接Collectionを指定可能
| trait | 内部で呼ぶDBSessionの関数 | 特徴 |
|---|---|---|
| SQLToCollection | collection | 結果データをコレクション型に格納して返す。 |
b) SQLToResultを継承
| trait | DBSessionの関数 | 特徴 |
|---|---|---|
| SQLToList | list | 結果データをList型に格納して返す。 |
| SQLToOption | single or first | 結果データを1件だけOptionに格納して返す。 |
| SQLToTraversable | traversable | 結果データをTraversable型に格納して返す。 |
呼び方の参考例)
SQLToResultを継承した3つのtraitでは、関数をひとつ宣言しています(result)。
def result[AA](f: WrappedResultSet => AA, session: DBSession): List[AA] = {
session.list[AA](statement, rawParameters: _*)(f)
}
def result[AA](f: WrappedResultSet => AA, session: DBSession): Option[AA] = {
if (isSingle) {
session.single[AA](statement, rawParameters: _*)(f)
} else {
session.first[AA](statement, rawParameters: _*)(f)
}
}
def result[AA](f: WrappedResultSet => AA, session: DBSession): Traversable[AA] = {
session.traversable[AA](statement, rawParameters: _*)(f)
}
各traitは、XXXImpl(実装)が存在します。SQLが呼ばれる際には、それぞれの実装クラスのインスタンスが作られて、祖父のtraitであるSQLToResultのapplyが呼ばれます。
val entities: List[Map[String, Any]] = sql"select * from members".map(_.toMap).list.apply()
applyの内部では、resultが呼ばれています(正確には、『DBSessionを引数として受け取り、resultを呼ぶ』関数)。
def apply()(
implicit
session: DBSession,
context: ConnectionPoolContext = NoConnectionPoolContext,
hasExtractor: ThisSQL =:= SQLWithExtractor
): C[A] = {
val attributesSwitcher = createDBSessionAttributesSwitcher()
val f: DBSession => C[A] = s => result[A](extractor, DBSessionWrapper(s, attributesSwitcher))
// format: OFF
session match {
case AutoSession | ReadOnlyAutoSession => DB.readOnly(f)
case NamedAutoSession(name, _) => NamedDB(name, session.settings).readOnly(f)
case ReadOnlyNamedAutoSession(name, _) => NamedDB(name, session.settings).readOnly(f)
case _ => f(session)
}
// format: ON
}
DBのreadOnly関数に『resultを呼ぶ関数』を渡し、更に内部ではDBConnectionのreadOnlyに『resultを呼ぶ関数』を渡し、その内部で『resultを呼ぶ関数』がようやく呼ばれています。この例では、下記のコードのexecutionがresult関数となっています。
def readOnly[A](execution: DBSession => A): A = {
if (autoCloseEnabled) using(conn)(_ => execution(readOnlySession()))
else execution(readOnlySession())
}
SQLToResultのapplyの中で、DBSessionWrapperのインスタンスが作られて、traversableやlistが呼ばれています。その中で、『collection』が呼ばれ、StatementExecutorのインスタンスが作らています。
def collection[A, C[_]](template: String, params: Any*)(extract: WrappedResultSet => A)(implicit cbf: CanBuildFrom[Nothing, A, C[A]]): C[A] = {
using(createStatementExecutor(conn, template, params)) {
executor =>
val proxy = new DBConnectionAttributesWiredResultSet(executor.executeQuery(), connectionAttributes)
new ResultSetTraversable(proxy).map(extract)(breakOut)
}
}
そしてStatementExecutorの中で、java.sql.PreparedStatementのexecuteQueryが呼ばれています。
def executeQuery(): java.sql.ResultSet = statementExecute(() => underlying.executeQuery())
2.3 作成・登録・更新・削除 関係
これまではデータ取得を説明してきましたが、Create Table文、Inset文、Update文等々を実行するための主要クラスは以下の3つとなります。このクラスのapply関数の中で、sqlが実行されます。
| クラス名称 | 用途 | applyの戻り値 |
|---|---|---|
| SQLExecution | 色々な種類のSQL文の実行 | boolean |
| SQLUpdate | Insert,Update,Delete,CreateTable文の実行 | int |
| SQLBatch | 複数のSQL文の一括実行 | int[] |
例えば、executeであれば以下の様な使い方になります。
sql"""
create table members (
id serial not null primary key,
name varchar(64),
created_at timestamp not null
)
""".execute.apply()
executeが呼ばれるとSQLExecutionのインスタンスが返されます。
def execute(): SQLExecution = {
new SQLExecution(statement, rawParameters, tags)((stmt: PreparedStatement) => {})((stmt: PreparedStatement) => {})
}
SQLExecutionクラスには、apply関数が存在し、その中でDBSessionWrapperのインスタンスが作られて、executeWithFiltersが呼ばれています。
class SQLExecution(val statement: String, val parameters: Seq[Any], val tags: Seq[String] = Nil)(
val before: (PreparedStatement) => Unit
)(
val after: (PreparedStatement) => Unit
) {
def apply()(implicit session: DBSession): Boolean = {
val attributesSwitcher = new DBSessionAttributesSwitcher(SQL("").tags(tags: _*))
val f: DBSession => Boolean = DBSessionWrapper(_, attributesSwitcher).executeWithFilters(before, after, statement, parameters: _*)
// format: OFF
session match {
case AutoSession => DB.autoCommit(f)
case NamedAutoSession(name, _) => NamedDB(name, session.settings).autoCommit(f)
case ReadOnlyAutoSession => DB.readOnly(f)
case ReadOnlyNamedAutoSession(name, _) => NamedDB(name, session.settings).readOnly(f)
case _ => f(session)
}
// format: ON
}
}
更にDBSessionのexecuteWithFiltersが呼ばれており、その中でStatementExecutorのインスタンスが作られています。そして、executeが呼ばれています。
def executeWithFilters(
before: (PreparedStatement) => Unit,
after: (PreparedStatement) => Unit,
template: String,
params: Any*
): Boolean = {
ensureNotReadOnlySession(template)
using(createStatementExecutor(conn, template, params)) {
executor =>
before(executor.underlying)
val result = executor.execute()
after(executor.underlying)
result
}
}
def execute(): Boolean = statementExecute(() => underlying.execute())
このexecuteが、最終的にDBConnectionのautoCommitにて呼ばれる関数となります。
def autoCommit[A](execution: DBSession => A): A = {
if (autoCloseEnabled) using(conn)(_ => execution(autoCommitSession()))
else execution(autoCommitSession())
}
このあたりの動作は、データ取得系と同様の動きになっています。
3.気付いたところ
3.1 抽象化
オブジェクト指向の考え方で、共通の振る舞いを抽出して汎化するとかの考え方で継承がありますが、Scalaの『関数を引数に受け取る関数』(高階関数)がScalikeJDBCでも活用されています。
特に『DBSessionを受け取り、処理を行い、結果を返す』部分で広く活用されていると感じました。result(list,single,first,traversable)、executeWithFilters 等々が、その関数となります。呼ばれる順番を、そのまま処理を追っていっても、途中で関数型(=>)に変わっており、見失う部分がありましたが、今回このSQL関係を色々見ることで追い方を少しつかめた漢字がしました。
他にもtype parameterが効いているところが、色々なEntityを返せるようになっているところです。この言語仕様自体が無いと、型を定義しつつ、汎用的な処理をサポートする事は難しかったと思います。
3.2 同一ファイルに複数クラスの意味
元々ソースを見ていて感じていたのは、同一フォルダ階層に大量のクラスがあると感じていました。もう少しフォルダを分けてくれていれば、機能的なグループが出来て、理解がしやすいのにと。更に、SQL.scalaの中に色々クラスが宣言されていたりして、戸惑いがありました。
しかし、DBアクセスを担当するフレームワーク(ライブラリ?)であれば、様々な方に利用されることを考えると、package階層が複数あると、その階層の多さに壁を感じてしまうかもしれません。そう考えると、同一ファイルに複数クラスも問題無いと感じました。しかも、各クラスの実装内容は、Scalaらしく数行で済んでいますし。
4.おわりに
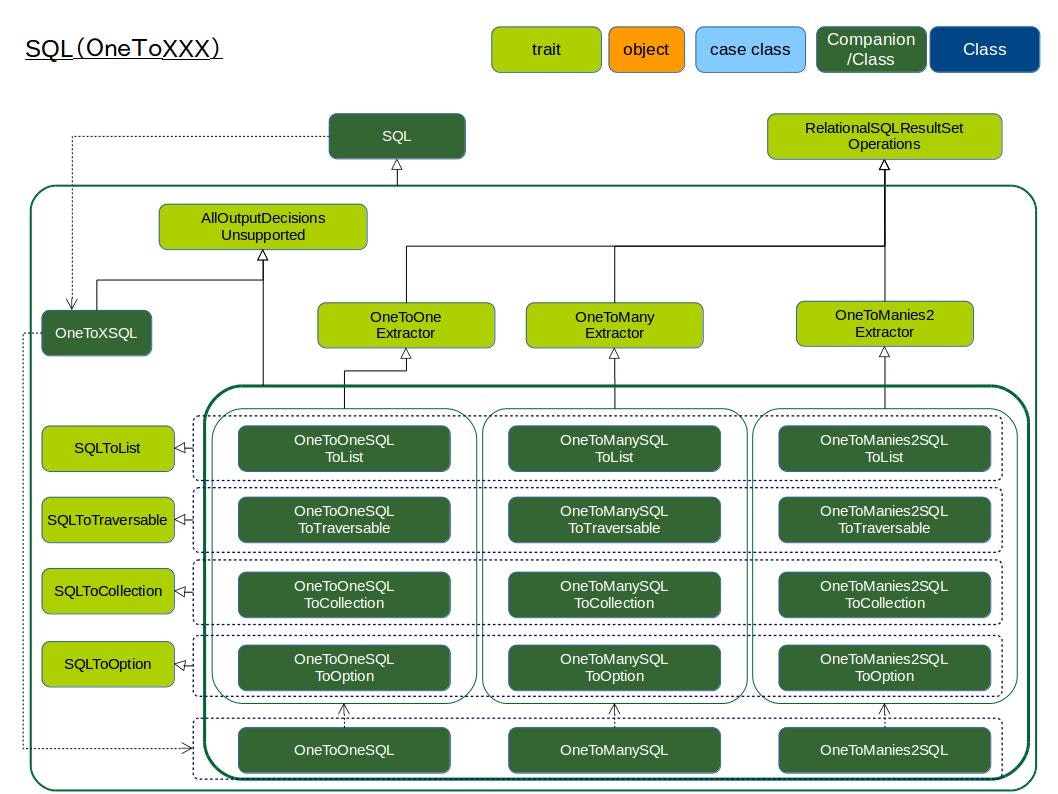
一応、One-to-Xの図も載せておきます。SQLToResultまわりの応用で、クラスの構成が理解できるかと思います。
まだ、WrappedResultSet とかのクラスもあるのですが、また書ければ書きたいと思います。