みんな大好きHadley氏作ったreadrが0.1.0になったようなので、早速試してみました。
今回はやったのは、使い方の確認と簡単な速度比較です。
まずは、readrの紹介から。
readrとは
表形式のデータを高速に、そして簡単に読み込むことを目的としたRのpackage。
一応、ファイル書き込み用の関数もあります。
使い方
読み込み用の関数は幾つかありますが、代表的なread_delimを説明します。
read_csvやread_tsv等は、read_delimのパラメータが設定されているラッパーです。
read_delim(file,
delim,
quote = '\"',
escape_backslash = TRUE,
escape_double = FALSE,
na = "NA",
col_names = TRUE,
col_types = NULL,
skip = 0,
n_max = -1,
progress = interactive())
入力パラメータの説明です。
| パラメータ | デフォルト値 | 解説 |
|---|---|---|
| file | ファイルパス、コネクション、リテラルデータを指定できます。 gz、bz2、xz、zipは自動解凍されます http:// 、https://、ftp://、ftps://はdownloadします d |
|
| delim | 区切り文字 | |
| quote | " | quote string |
| escape_backslash | TRUE | |
| escape_double | FALSE | |
| na | NA | 値がない場合にいれる文字 |
| col_names | TRUE | 以下の3つの値を取れます。 TRUE:ヘッダー行を列名とする。 FALSE:順に番号振ります。 列名に使用するvector |
| col_types | NULL | デフォルトの列クラスを上書きする。後で詳細に解説します。 |
| skip | 0 | スキップする行数を指定 |
| n_max | -1 | 読み込む最大行を指定 |
| progress | interactive() | 推定ロード時間が5秒以上の場合はプログレスバーを表示する。 FALSEを指定すると非表示。 |
標準のread.delimで生成されるデータフレームとの違い
- 文字列をfactorに自動変換しない。(stringsAsFactors = FALSEが常に指定されている感じ)
- 有効な列名かどうかチェックしてない。`で列を囲めば使える。
- classが"tbl_df"、"tbl"、"data.frame"が設定され、dplyrで扱う場合にちょっと便利。
- 行名がセットされない
Column types
col_typesを指定しない場合は、最初の100行を読んで、列の型を推測します。
推測される型は以下の通り。
| 列型 | 省略形 | 説明 |
|---|---|---|
| col_logical() | l | contains only T, F, TRUE or FALSE. |
| col_integer() | i | integers. |
| col_double() | d | doubles. |
| col_euro_double() | e | “Euro” doubles that use , as the decimal separator. |
| col_date() | D | Y-m-d dates. |
| col_datetime() | T | ISO8601 date times |
| col_character() | c | everything else. |
推定では、意図した型にならない場合は、列毎に型を指定することができます。
| 列型 | 省略形 | 説明 |
|---|---|---|
| col_skip() | _ | don’t import this column. |
| col_date(format) and col_datetime(format, tz) | dates or date times parsed with given format string. Dates and times are rather complex, so they’re described in more detail in the next section. | |
| col_numeric() | n | a sloppy numeric parser that ignores everything apart from 0-9, - and . (this is useful for parsing currency data). |
| col_factor(levels, ordered) | parse a fixed set of known values into a (optionally ordered) factor. |
col_types の引数
col_typesは、文字列とvectorの2種類の引数を取ることができます。
一つはコンパクトな文字列で、"dc __d"のように、1列目がdouble型、2列目がcharacter型、3,4列目をskip、5列目がdouble型のように上記表の省略形の文字列を繋いだ形で指定できます。
もう一つは、リストで各列毎にcol_typeを指定する方法。指定を省略した場合は、skipされるのではなく、列の型が推定されます。
problems
データを読み込んだ際に、問題が発生した行と列をレポートしてくれます。
壊れたデータが紛れていた場合等に便利ですね。
速度比較
使い方がだいたいわかったところで、速度比較してみます。
比較するのは、標準のread.delim、readr::read_delim``data.table::freadの3パターンです。
ドキュメントによると、標準のread_delimより10倍以上速いが、data.table::freadよりは1.2~2倍ぐらい遅いらしいですが、実測したいと思います。
計測方法は、以下に記載している方法で、各10回の試行の平均を採用しています。
読み込む対象のファイルは、約554万行、9列でファイルサイズが231MBのTSVファイルです。
それでは、まずは標準のread.delimから。
system.time(
df <- read.delim("C://tmp/all_user_list-2015-04-10.tsv" , sep="\t")
)
23.892秒。それなりに時間がかかる。
続いて、readr::read_delim
system.time(
df2 <- readr::read_delim("C://tmp/all_user_list-2015-04-10.tsv" , delim="\t")
)
9.130秒。は、早い・・!?
最後にdata.table::fread
system.time(
df3 <- data.table::fread("C://tmp/all_user_list-2015-04-10.tsv" , sep="\t" , header=T )
)
2.477秒。爆速。
比較結果
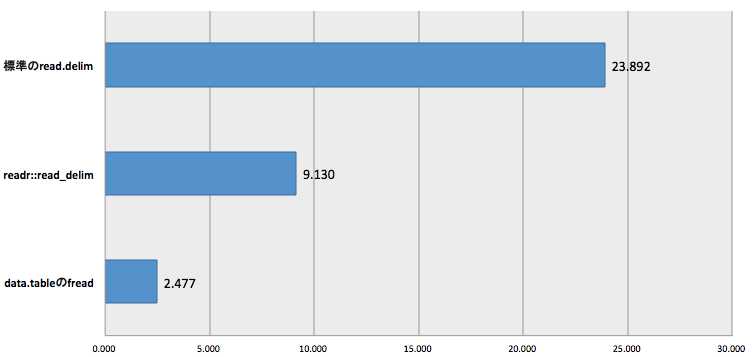
Hadley氏も言っている通り、data.table::freadがその爆速っぷりを見せつける結果となりました。
readrは標準のread_delimより2.5倍早いですが、ちょっと物足りない数値です。data.table::freadともちょっと差が開いています。
折角調べたので、速度に関係ありそうなオプションを変更して計測してみます。
まずは、型を明示的に指定した場合に早くなるか。
system.time(
df4 <- readr::read_tsv("C://tmp/all_user_list-2015-04-10.tsv" , col_types = "iDiDiiDii")
)
結果:9.004秒
結果は、誤差の範囲内でほぼ変わらず。
先頭100行読んで9列の型を推定するぐらいだと、速度にはほぼ影響しないです。
よくあるDate型が遅いんじゃないか説を検証するために、Date型をcharacter型で読み込む。
## col_character
system.time(
df5 <- readr::read_tsv("C://tmp/all_user_list-2015-04-10.tsv" , col_types = "iciciicii")
)
結果:5.27秒
早くなった!4秒弱ぐらい早くなったので、結構前進。
最後は、不要な列の指定ができるので、最低限の列だけに絞って読み込む。
system.time(
df6 <- readr::read_tsv("C://tmp/all_user_list-2015-04-10.tsv" , col_types = "ic_____i_")
)
結果:3.656秒
さらに早くなった!(当たり前だけど。。)
ざっと試せる感じだと、このあたりが限界のような気がします。
最終比較結果
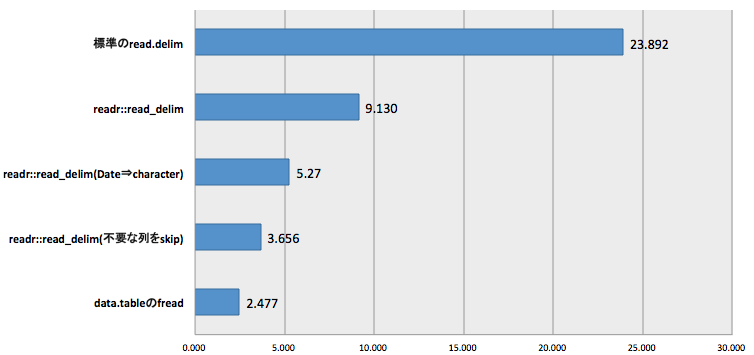
色々オプションを指定することで、data.table::freadよりはちょっと遅いですが、標準のread.delimよりは十分に早い速度を出すことができました。
まとめ
速度的な面は、data.table::freadの方が早い。
速度が命の場面では、data.table::freadを使用し、それ以外の用途ではreadrを使うみたいな使い分けができそうですね。
日付や時間の扱いやすさや、視覚的な読み込み時間のわかりやすさ、そして現時点でも十分早いので、今後使う頻度が増えそうです。
今回は、試せたパターンが少なかったので、安定性はまだ評価できてないですが、今後に期待できそうです!
おまけ
↓こんな感じの書き方もできるので、ちょっとした集計するのに便利。
今回は、計測した実行時間の平均を取るのに利用しました。地味に便利!
readr::read_tsv(
"elapsed_time
3.75
3.56
3.71
3.64
3.61
3.70
3.66
3.66
3.72
3.66
3.67
3.54
"
) %>% summarise(avg=mean(as.numeric(elapsed_time)))
avg
1 3.656667