今回とあるプロジェクトでChaliceのフレームワークを使うことになり、その導入資料を作成したので、記事として残そうと思います。
Chaliceとは
Chaliceは、Amazon製であるため、AWS専用のフレームワークとなっています。
- デプロイ周りを簡単にかつ自動で構築できるため、コードを書くことに集中できる
- Flask、bottle、FastAPIなどのフレームワークで使用されているおなじみのデコレーターベースの構文を使用しているため、学習コストが低い
- さまざまなデプロイツールに対応しているため、自分が慣れ親しんだデプロイツールを利用できる(TerraformやAWS SDKなど)
公式ドキュメントではデプロイまでの時間が早いことを示すため、ターミナルでの実行時間を見れるようにしています。
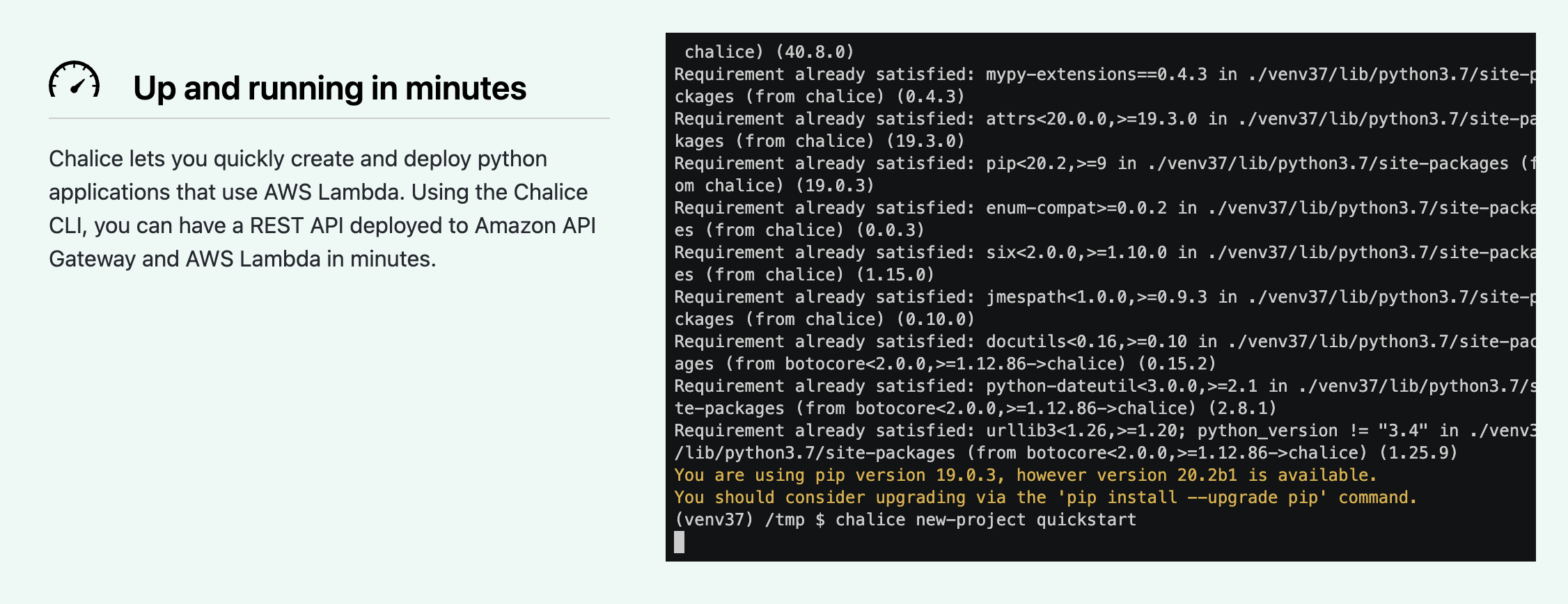
とても自信がおありのようで...
何が便利なのか?
デプロイするだけで、AWSへのデプロイまでの流れとして必要なAWSCodePipelineや AWSCodeBuildやIAMを自動で構築してくれます。
継続的インテグレーションを自動でやってくれるのはとてもありがたいです。
また、ローカル環境ではテストサーバーを用意してくれているので問題なくローカルで確認も可能です(以前まではローカルサーバーの起動が出来ず、都度デプロイでの確認だったようです...)
一方、その他AWSリソースへのアクセスは一部制限されており、API Gatewayに特化しているフレームワークと言えます。
用意してあるコマンドも少なく、扱いやすいです。
Commands:
deploy
gen-policy
generate-sdk
local
logs
new-project
url
その他 Python ライブラリとの比較
基本、PythonのフレームワークはFlask or Djangoといった感じです。
その中でもChaliceは、Flaskをベースとして作られているようです。
言い換えると、Flaskの知識さえあれば、パスルーティングの設定や、リクエスト、レスポンスの取り扱いはほぼそのままの知識でできます。
実装方法
実際にChaliceを触っていこうと思います。
Chalice インストール方法
使っているPythonのバージョンは3.9.6です。
まず仮想環境を作りましょう。
Docker等を使うのも良いですが、Pythonでは仮想環境をサクッと構築できるので今回は仮想環境を利用した方法で進めます。
# 仮想環境の作成
$ python3 -m venv .venv
# 仮想環境の起動とログイン
$ source .venv/bin/activate
# 仮想環境から抜ける時
$ deactivate
crendential の作成
aws-cliを利用するので、まだの方はインストール等で準備をしておいてください。
$ mkdir ~/.aws
$ cat >> ~/.aws/config
[default]
aws_access_key_id=YOUR_ACCESS_KEY_HERE
aws_secret_access_key=YOUR_SECRET_ACCESS_KEY
region=YOUR_REGION (such as us-west-2, us-west-1, etc)
プロジェクト作成
ここまでやるとPythonの開発環境が整ったので、Chaliceをインストールして、プロジェクトを作成しましょう。
$ python3 -m pip install chalice
$ chalice new-project [プロジェクト名]
$ cd [プロジェクト名]
Chaliceがインストールされたことがわかります。
$ chalice --version
chalice 1.27.3, python 3.9.6, darwin 21.5.0
$ chalice --help
Usage: chalice [OPTIONS] COMMAND [ARGS]...
Options:
--version Show the version and exit.
--project-dir TEXT The project directory path (absolute or
relative).Defaults to CWD
--debug / --no-debug Print debug logs to stderr.
--help Show this message and exit.
Commands:
delete
deploy
dev Development and debugging commands for chalice.
gen-policy
generate-models Generate a model from Chalice routes.
generate-pipeline Generate a cloudformation template for a starter CD...
generate-sdk
invoke Invoke the deployed lambda function NAME.
local
logs
new-project
package
url
リリース初期のChaliceだとローカルサーバーの起動コマンドがなく、都度deployをして確認という方法だったみたいですが、localサーバーの起動ができるようになっています。
$ chalice local
Serving on http://127.0.0.1:8000
GET メソッドの作成
app.pyを覗くとこのようになっています。
from chalice import Chalice
app = Chalice(app_name='sample-app')
@app.route('/')
def index():
return {'hello': 'world'}
この状態でlocalhost:8000にアクセスすると {'hello':'world'}と表示されるはずです。
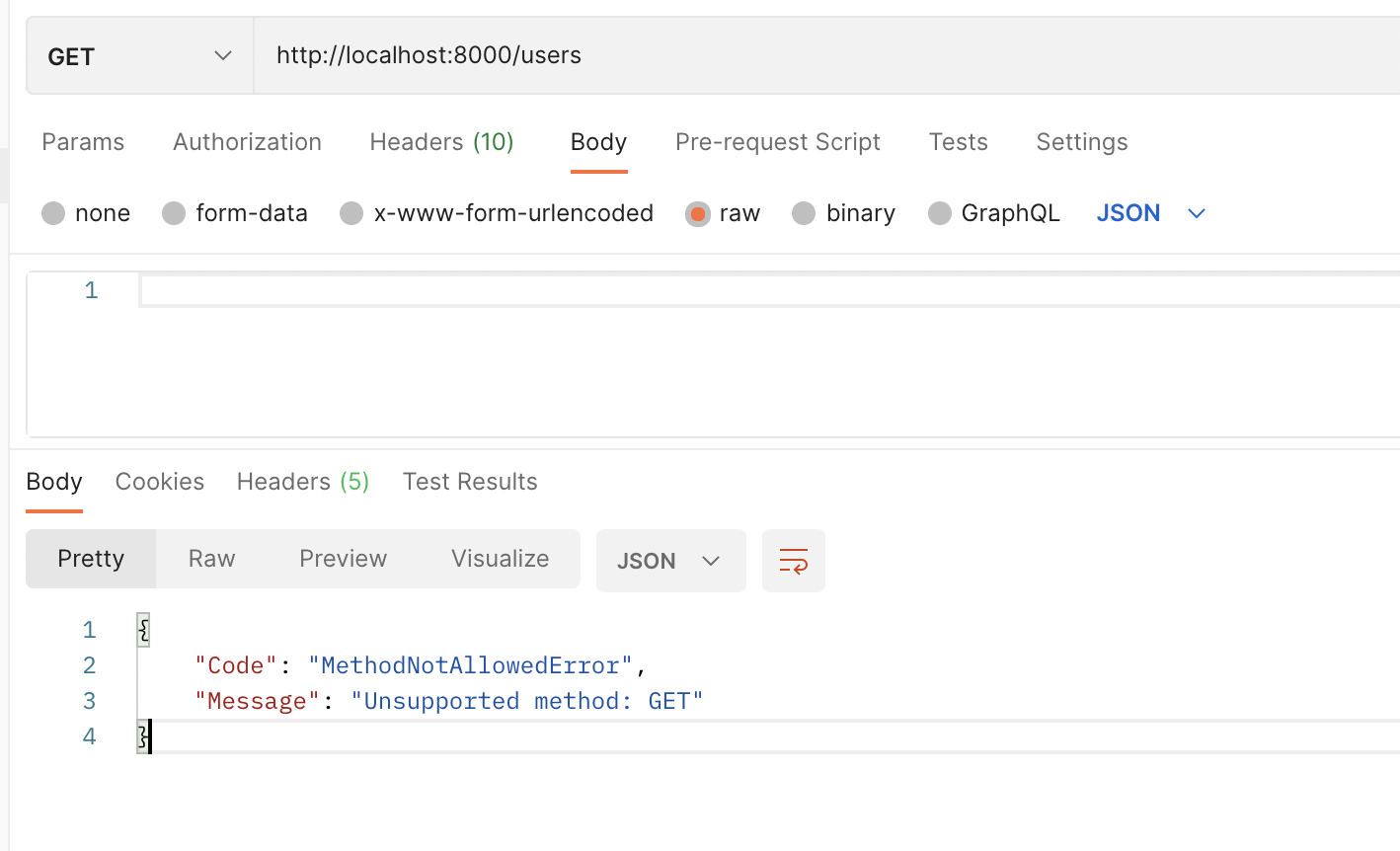
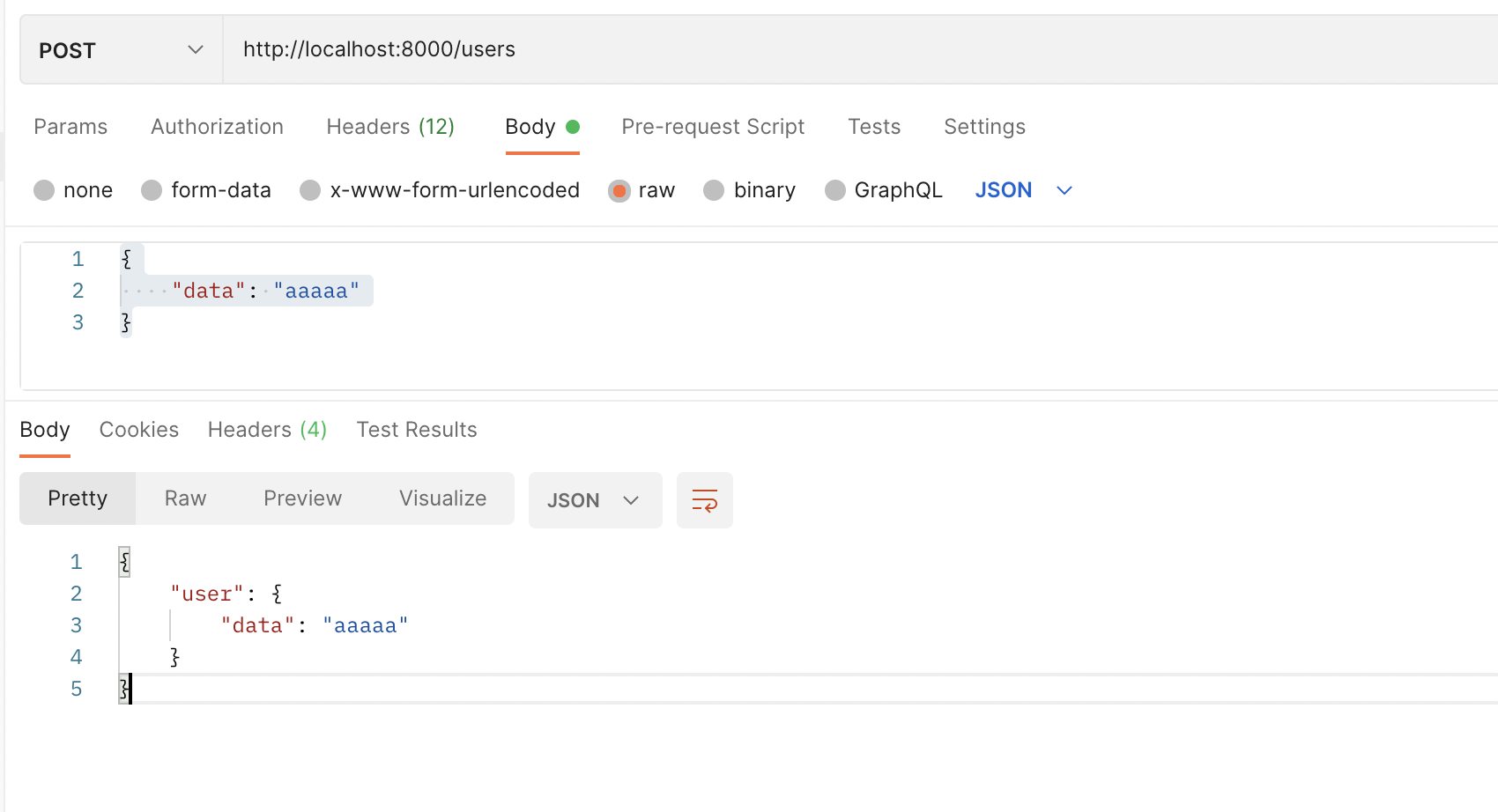
POST メソッドの作成
POSTの時はrouteの引数でmethodを指定してあげます。
@app.route("/users", methods=["POST"])
def create_user():
if app.current_request is None:
raise BadRequestError("paramater not found")
user_as_json = app.current_request.json_body
return {"user": user_as_json}
GETメソッドではエラーとなりますが、POSTだとうまくいくことが確認できます。
さらなる実装の方法について
エラーハンドリング
chaliceにもデバッグモードが存在しており、debugをTrueにするとリクエスト時のエラーの詳細をスタックトレースで表示できます。
chaliceにはあらかじめ準備された例外を持っており、それを返すことで適切なステータスコードも返すことができる。
例外と返すステータスコードは以下の通りです。利用するときはchaliceパッケージからimportしてあげます。
* BadRequestError - return a status code of 400
* UnauthorizedError - return a status code of 401
* ForbiddenError - return a status code of 403
* NotFoundError - return a status code of 404
* ConflictError - return a status code of 409
* UnprocessableEntityError - return a status code of 422
* TooManyRequestsError - return a status code of 429
* ChaliceViewError - return a status code of 500
# How to use
from chalice import UnauthorizedError
レスポンス自体、カスタマイズすることも可能です。
Responseクラスを使用します。
from chalice import Chalice, Response
app = Chalice(app_name='custom-response')
@app.route('/')
def index():
return Response(body='hello world!',
status_code=200,
headers={'Content-Type': 'text/plain'})
Requestクラスについて
app.current_requestのオブジェクトはRequestクラスになっています。
type(app.current_request)
⇨<class 'chalice.app.Request'>
よって、下記のような情報を取得できます。
current_request.query_params - A dict of the query params.
current_request.headers - A dict of the request headers.
current_request.uri_params - A dict of the captured URI params.
current_request.method - The HTTP method (as a string).
current_request.json_body - The parsed JSON body.
current_request.raw_body - The raw HTTP body as bytes.
current_request.context - A dict of additional context information
current_request.stage_vars - Configuration for the API Gateway stage
current_request.methodを使うことでmethod名を取得できるので、POSTかPUT課によって処理を分けることができます。
def create_user():
# This is the JSON body the user sent in their POST request.
user_as_json = app.current_request.json_body
if current_request.method == 'POST':
# Create User Code
else:
# Update User Code
return {'user': user_as_json}
CORS対応
@app.route()に対し、cors=Trueを追加することで簡単にCORS対策ができます。
もし細かくCORSの設定をするなら、CORSConfigを利用し、そのconfigを先ほどのcorsに設定することでカスタマイズした設定ができるようになります。
from chalice import CORSConfig
cors_config = CORSConfig(
allow_origin='https://foo.example.com',
allow_headers=['X-Special-Header'],
max_age=600,
expose_headers=['X-Special-Header'],
allow_credentials=True
)
@app.route('/custom-cors', methods=['GET'], cors=cors_config)
def supports_custom_cors():
return {'cors': True}
イベントキックによる実行
chaliceはAWSと密接に関わっていることから、AWSのSNS等の通知によって処理を実行させることができます。
下記は、snsにメッセージの通知があった場合、ログを出力する関数となっています。
from chalice import Chalice
app = Chalice(app_name='chalice-sns-demo', debug=True)
@app.on_sns_message(topic='MyDemoTopic')
def handle_sns_message(event):
app.log.debug("Received message with subject: %s, message: %s",
event.subject, event.message)
他にもs3のイベントやdynamodbへの記録によって実行できるイベントがあるようです。
_EVENT_CLASSES = {
'on_s3_event': S3Event,
'on_sns_message': SNSEvent,
'on_sqs_message': SQSEvent,
'on_cw_event': CloudWatchEvent,
'on_kinesis_record': KinesisEvent,
'on_dynamodb_record': DynamoDBEvent,
'schedule': CloudWatchEvent,
'lambda_function': LambdaFunctionEvent,
}
1時間ごとに実行といったcronのような使い方もできます。
app = chalice.Chalice(app_name='foo')
@app.schedule(Rate(1, unit=Rate.HOURS))
def every_hour(event):
print(event.to_dict())
イベントは色々な使い方ができそうです。
その他
pipでインストールしたパッケージを書き出し、他の人が同じように環境構築できるようにリストとして書き出してあげるのが良いでしょう。
いわゆるJSでいうpackage.json、PHPでいうcomposer.jsonと同じですね。
pip freeze > requirements.txt
すでにrequirements.txtが存在しているとエラーになるので、一度消すか、空の状態なら上書きするのが良いです。
AWS へのデプロイ方法
デプロイ実行
デプロイコマンドで Lambda に関数が生成される
$ chalice deploy
Creating deployment package.
Creating IAM role: sample-app-dev
Creating lambda function: sample-app-dev
Creating lambda function: sample-app-dev-demo_auth
Creating Rest API
Resources deployed:
- Lambda ARN: arn:aws:lambda:ap-northeast-1:881585394409:function:sample-app-dev
- Lambda ARN: arn:aws:lambda:ap-northeast-1:881585394409:function:sample-app-dev-demo_auth
- Rest API URL: https://1zarx7vdn0.execute-api.ap-northeast-1.amazonaws.com/api/
コンソール確認
Lambda と API Gateway と IAM を確認
API GateWay
Lambda
削除方法
chaliceのデプロイによって色々なものがAWSに構築されるようになっていますが、さらに便利なのがdeleteコマンドによってリソース削除もできるところです。
Terraformでいうapplyコマンドの役割を持っています。
$ chalice delete
Deleting Rest API: 1zarx7vdn0
Deleting function: arn:aws:lambda:ap-northeast-1:881585394409:function:sample-app-dev-demo_auth
Deleting function: arn:aws:lambda:ap-northeast-1:881585394409:function:sample-app-dev
Deleting IAM role: sample-app-dev
ユニットテスト
pythonですので、pytestを利用することでテスト可能です。
$ pip install pytest
テストファイルはプロジェクトディレクトリにtestディレクトリを作成し、その中にtest_app.pyでファイルを作成します。
下記テストは先ほど作成したルートのエンドポイントで返すJSONファイルの検証をしております。
import json
from chalice.test import Client
from app import app
def test_index():
with Client(app) as client:
response = client.http.get("/")
assert response.json_body == {"hello": "world"}
app.pyの分割
ルーティングでの処理はこのapp.pyに記載していくのですが、エンドポイントが増えてくるとこのファイルが肥大化していく可能性があります。
ページパスによってファイルを分けたい等ができないかを確認したところBlueprintという機能を使えばapp.pyのファイルを分割できるようです。
シチュエーションとして、記事を管理するページが/articlesというパスを持つとします。
まずはプロジェクトディレクトリの中で
sample-app
├── app.py →本来はここにまとめる
└── chalicelib
├── articles
└── app.py →/articlesのパスの時はここにまとめる
from chalice.app import Chalice
from chalice.app import Blueprint
articles_app = Blueprint(__name__)
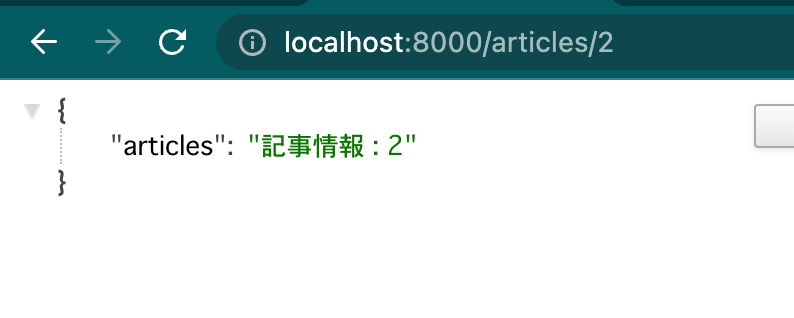
@articles_app.route('/articles/{id}', methods=['GET'])
def getArticles(id):
return {'articles': f'記事情報 : {id}' }
articlesでのルーティングができたので、本来あったapp.pyに登録します。
from chalice.app import Chalice
from chalice.app import BadRequestError
from chalicelib.articles.app import articles_app
app = Chalice(app_name="sample-app")
app.register_blueprint(articles_app) →追記
articles/2でリクエストすると下記JSONデータが返ってきているので、問題なく分割できています。
dynamodbへの接続
Chaliceでデータを扱う場合、APIGatewayからの接続となります。
RDSでの接続はRDSProxyというサービスが最近出たみたいですので、こちらを使えば接続可能ですが、調べていると結構面倒な印象を受けました。
そこで今回は手軽に接続できるNoSqlのdynamodbに接続し、データを操作することとしました。
テーブルの作成
テーブル作成にはschemaが必要となります。
schema.jsonとして下記のようなファイルを準備しておきます。
{
"KeySchema": [
{
"KeyType": "HASH",
"AttributeName": "id"
}
],
"AttributeDefinitions": [
{
"AttributeName": "id",
"AttributeType": "S"
}
],
"ProvisionedThroughput": {
"WriteCapacityUnits": 1,
"ReadCapacityUnits": 1
}
}
jsonファイルを使わなくても、コマンド内で指定できれば可能ですが、schemaを管理したいのでjsonで追い出します。
aws-cilとcredentialの設定が終わっている前提で、下記コマンドを実行することでテーブルを作成可能です。
aws dynamodb create-table --table-name 'TestTable' --cli-input-json file://schema.json
もしうまくいかない場合は、AWSのコンソール画面からテーブル作成でも問題ないかと思います。
テーブルへデータ追加
テーブルへのデータ追加は下記の通りコマンドで登録可能です。
inital-data.jsonデータを準備しましょう。
{
"Records": [
{
"PutRequest": {
"Item": {
"id": {
"S": "id1"
},
"sub": {
"S": "LOCAL_USER"
},
"race": {
"S": "3"
},
"team": {
"S": "TeamA"
},
"section": {
"S": "1"
},
"runner_name": {
"S": "あべべ"
},
"result_time": {
"S": "00:23:01"
},
"description": {
"S": "Memo1"
}
}
}
},
...略
]
}
aws dynamodb batch-write-item --request-items file://initial-data.json
ここまでやるとデータの準備が完了しました。
ポリシーの変更
ここからは、.chalice/config.jsonを編集します。
本来、Chaliceは、ソースコードを解析して必要なポリシーを自動的に付与する機能があります。
どうもdynamodbを操作する際に、boto3のライブラリを使うのですが、Clientクラスを使わず、Resourceクラスを使うと自動的に作成してくれないようです...
dynamodbに対するポリシー作成が自動で作成できないため、手動で作成していきます。
そもそも、このClientとResourceのクラスの違いは下記のように説明されます。
-
Client: 低レイヤーのサービスのアクセスが可能
-
Resource: 高レイヤーのオブジェクト指向なサービスアクセスが可能
ここでの説明は割愛いたしますが、Clientクラスを使うと低レイヤーからのアクセスとなるため、たくさんのコードを書くことが必要となります。
特に理由がない限りはResourceクラスを使うのが良いでしょう。
話を戻すと・・・
今回はResourceクラスを使って実装するため、ポリシーの手動作成が必要となります。
config.jsonファイルを下記のようにします。
{
"version": "2.0",
"app_name": "sample-app",
"stages": {
"dev": {
"api_gateway_stage": "api",
"environment_variables": {
"DB_TABLE_NAME": "Records"
},
"autogen_policy": false
}
}
}
"autogen_policy": false でポリシーの自動生成をオフにします。
"iam_policy_file": "custom-policy.json" と言ったような記載で、手動で作成したポリシーの JSON ファイルを指定することができます。
しかし、今回のように "stages": {"dev": {・・・}}とすることで命名規則からpolicy-dev.jsonでファイルを作成することで勝手に認識してくれるようです。
policy-dev.jsonは下記のようにします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:UpdateItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query"
],
"Resource": "*"
}
]
}
dynamodbに対するcrudの権限を付与します。
あとは実装をしていきます。
db接続周りを下記のように記載しました。(一部抜粋)
import os
import boto3
from boto3.resources.base import ServiceResource
class DBDataCheckException(Exception):
pass
def _get_database() -> ServiceResource:
"""
DB接続関数
Returns:
ServiceResource: dynamoDBリソース
"""
endpoint = os.environ.get("DB_ENDPOINT")
if endpoint:
print("DB接続")
print(endpoint)
return boto3.resource("dynamodb", endpoint_url=endpoint)
else:
print("DB接続エンドポイント指定なし")
return boto3.resource("dynamodb")
def get_record(record_id):
table = _get_database().Table(os.environ["DB_TABLE_NAME"])
response = table.get_item(Key={"id": record_id})
return response["Item"]
def post_record(item):
table = _get_database().Table(os.environ["DB_TABLE_NAME"])
table_data = table.get_item(Key={"id": item["id"]})
if "Item" in table_data:
raise DBDataCheckException("既にデータがあります")
put_data = table.put_item(Item=item)
if put_data:
put_data["ResponseMetadata"]["message"] = "success create!"
return put_data["ResponseMetadata"]
_get_database()でデータベースに接続する関数を用意し、各種crudの関数で利用できるようにします。
get_record関数では、record_idを引数に受け取り、そのkeyに一致するデータを返すような関数です。
post_record関数は、itemをdict型で引数に受け取り、その値を使ってdbに登録するような関数です。
ここでテスト的にcrudを実装して気づいたのですが、RDSのように既存レコードがあった時、存在したidで登録しようとしたらエラーとなるものがdynamodbだと上書きされてしまうようです。
そこでデータが既にあるかどうかの判定をして、あれば例外を返すような処理にしました。
dynamodbでは例外ではないのでこちら側で自作Excepiton(DBDataCheckException)として定義しています。
DBDataCheckExceptionは、Exceptionを継承するようにしています。
これを例にapp.py側の記載を確認していきましょう。
dbのcrud周りもBlueprintで分割しました。
import traceback
from chalice.app import NotFoundError, BadRequestError
from chalice.app import Blueprint
from chalicelib import database
db_record = Blueprint(__name__)
@db_record.route("/records/{record_id}", methods=["GET"], cors=True)
def get_records(record_id):
record = database.get_record(record_id)
if record:
return record
else:
raise NotFoundError("record not found")
@db_record.route("/records", methods=["POST"], cors=True)
def post_record():
try:
return database.post_record(db_record.current_request.json_body)
except database.DBDataCheckException as e:
print(traceback.format_exc())
print(f"DB登録エラー!詳細 : {e}")
raise BadRequestError("This is a bad request")
except Exception as e:
print(traceback.format_exc())
print(f"DB登録エラー!詳細 : {e}")
raise BadRequestError("This is a bad request")
@db_record.route("/records/{record_id}", methods=["DELETE"], cors=True)
def delete_record(record_id):
try:
return database.delete_record(record_id)
except database.DBDataCheckException as e:
print(traceback.format_exc())
print(f"DB登録エラー!詳細 : {e}")
raise BadRequestError("This is a bad request")
except Exception as e:
print(traceback.format_exc())
print(f"DB登録エラー!詳細 : {e}")
raise BadRequestError("This is a bad request")
post結果
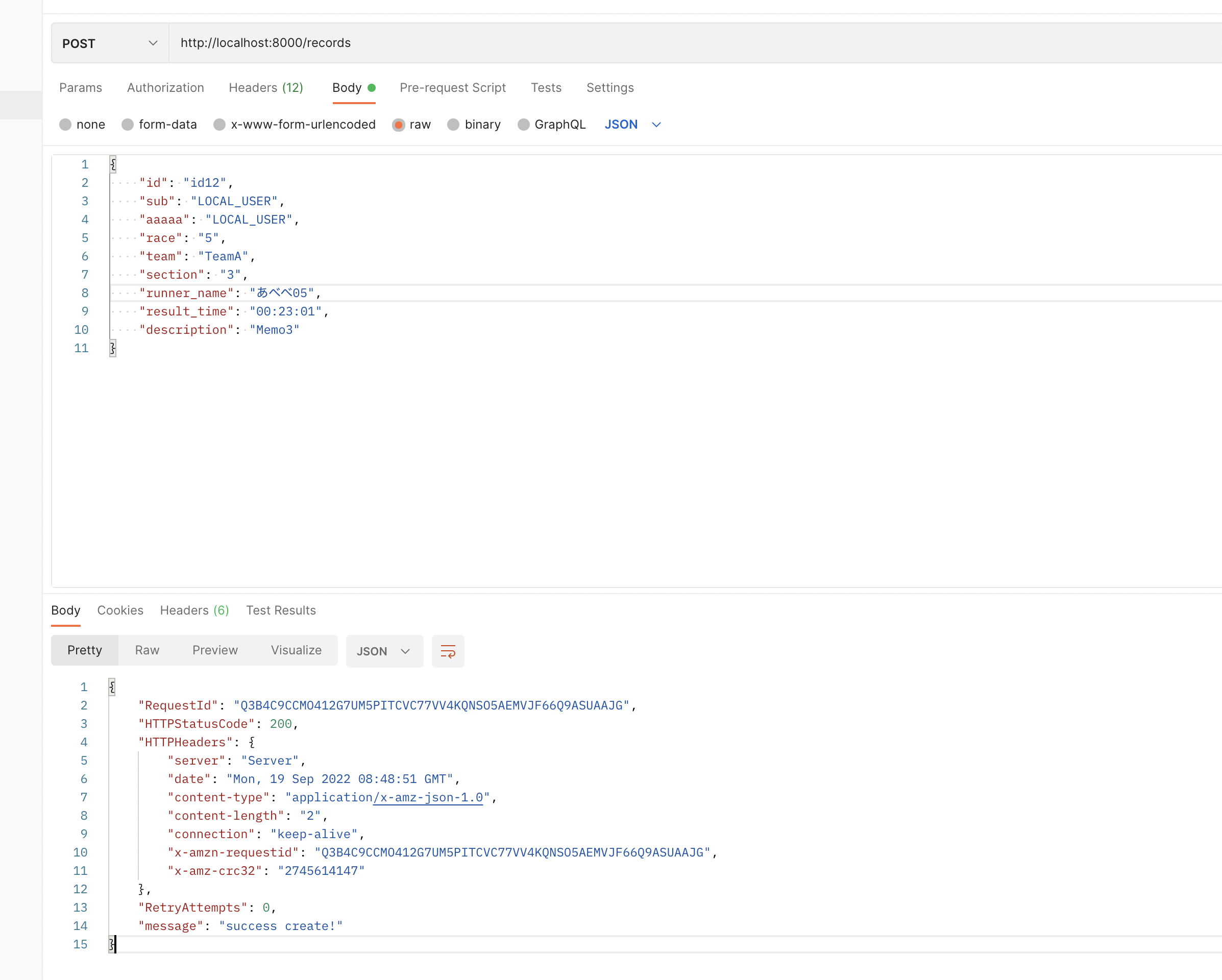
get結果
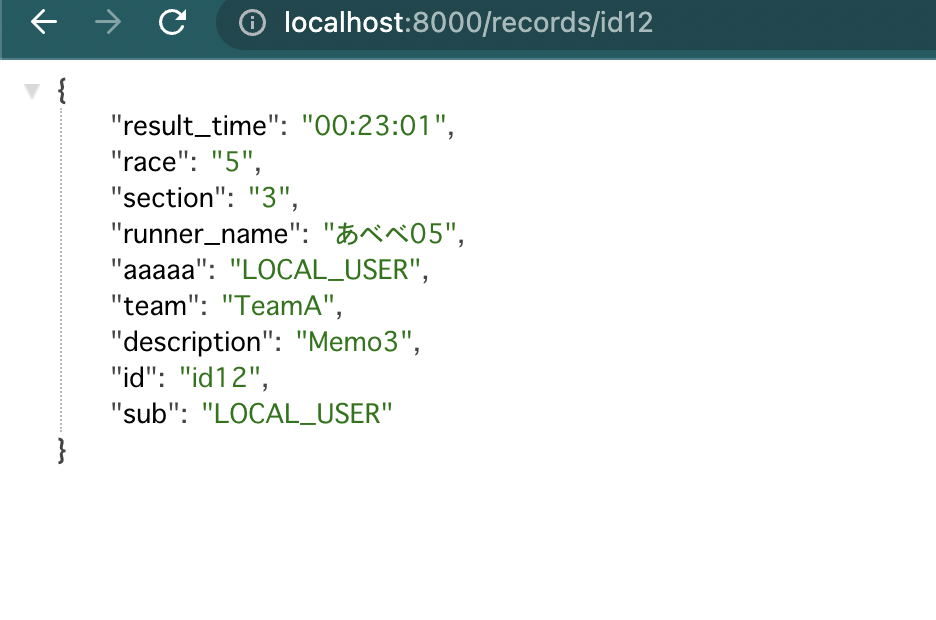
このようにしてdynamodbを利用したcrudが実装できました。
まとめ
いかがだったでしょうか?
想像以上に簡単にAPIが作成できちゃいました。
そもそも、Python自体簡単に書ける言語なのですが、デプロイ周りも比較的簡単にできるため、冒頭に述べたようにコーディングに集中して開発ができるものになっています。
個人開発~中規模のシステム開発で導入検討はありだと思います。
みなさんもよかったら触ってみてください。