デスクトップ用 Power Automate(PowerAutomateDesktop)(以下PAD)を使って、PDFデータを分割しました。
困った電帳法
突然ですが、電帳法、ご存じでしょうか。電子帳簿保存法です。
聞きたくない言葉出てきましたね。最初だけなので最後まで見てください。
よくわからないんですけど、電子で受領した書類をちゃんと保存しろよ、紙で貰っても保存しとけよ、作った書類も保存しとけよ、ってやつです。
それがどうしたかっていうと、一括で貰っている何ページものPDF書類を1つずつのPDFに分ける必要ができてたのです(今まではそのまま印刷していた)。
PDF分割するツールくらいあるだろ、と思うかもしれませんが、会社のパソコンって結構縛りがあるのです。有料ツールを申請したら使えなくもないのですが、そのためだけに使用料払うのももったいない。フリーツールもダウンロードできないです。
会計担当している人に聞くと、印刷とか駆使して、一枚のPDFを作成して、印刷・PDF・印刷・PDFというのを数10ページやってるという非効率極まりないことをしているみたいです。

たとえ月1回の作業とは言え、それに30分くらい時間がかかったり、漏れがあったりなど問題点が多いです。
PADでPDF分割ができる
調べてみたらPADを使えばできるらしいということで、作ってみました。
PADはMicrosoftの無料RPAツールで、Windows10、11の環境で利用できます。
うちの会社では申請したらダウンロードしてくれます。
それではPADでのPDF分割フローについて説明していきます。
フローはこちらからコピーできます。◆のところは編集してください。
__________Display.SelectFileDialog.SelectFile Title: $'''分割したいPDFを選んでね''' IsTopMost: False CheckIfFileExists: False SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed
LOOP LoopIndex FROM 1 TO 1000 STEP 1
Pdf.ExtractPages PDFFile: SelectedFile PageSelection: LoopIndex ExtractedPDFPath: $'''C:\◆Users\じぶんの\Desktop\新しいフォルダー◆\%LoopIndex%ページ.pdf''' IfFileExists: Pdf.IfFileExists.AddSequentialSuffix ExtractedPDFFile=> ExtractedPDF
ON ERROR
GOTO Loopout
END
END
LABEL Loopout
__________

こちらが全体のフロー図です。
5行で終わっているので、結構サラッと作れちゃいます。
それぞれの行でやっていることは、
①分割したいPDFを選ぶ
②1~1000まで繰り返す(10000でも100000でも良いです)
③デスクトップの新しいフォルダ(場所を変えれば好きなところ)に格納
④ループする場所。②に戻る
⑤ラベルの設定(後述)
ポイントとしては、③が肝になってきます。

②~④をループさせて間の③の処理を1ページから終わるまで実行します。
画像にある「nページ」というのは、ループ回数で増えていきます。
「抽出されたPDFのファイルパス」というところについては、
保存したい場所の後ろにファイル名と拡張子(.pdf)を付けてあげると名前がついて保存されます。
ファイル名は変数を使うことができるので、ここではページ数を付けています。
なにもつけなければ、「ファイル名(1)」「ファイル名(2)」・・・となっていくと思います。
最後のページまでループが続いた時、エラーを吐いて終わってしまう(指定されたページが無い)ので、エラー発生時の設定をしておきます。

事前に作っておいた⑤のラベルがここで登場します。
③でエラーが発生したときに、⑤のラベルに移動という行動をとるように設定することで、最後のページまで進んだらループから抜けるフローになりました。
出来上がったフローを動かしてみるとこんな感じ。

これで、PDFを数秒で1ページずつ分割して保存することができました。
フローを実行する前に、ファイル名のところに文書名を付けると、
「文書名nページ.pdf」のようになるので、アレンジできそうです。
フローを弄るのが怖い場合は、最初に「入力ダイアログを表示」で文書名を入れるフローを組み込んて、入力した文字変数を使って、「x nページ」みたいにしてみてもいいかもしれません。
使わせてみた
さて、PDF分割するフローができましたよ、と実際業務をしている会計担当に使ってもらいました。
「おお、さすが!めっちゃ便利ですね!!」
「でもページ数では中身がわかりません」
ですよね、わかってはいました。
今回作り始めたきっかけが、「業務完了確認書」という書類で、ページ毎にそれぞれの業務の内容が異なります。
たとえ「1ページ」が「業務完了報告書1ページ」となったところで、結局名前を付け直さないといけません。
PDFを分割できることが分かったのは良いけれど、これじゃ今一つ。
PDFからテキストを抽出して名前を付ける
なにか良い策がないかと調べてみたら、PDFのテキストを抽出する機能があるらしい。
「PDFからテキストを抽出」 という完全にソレじゃん!というアクションがありました。
早速使ってしてみました。

「PDFからテキストを抽出」というアクションを使うと、そのPDFのテキスト情報が全部でてきました。
実際いろいろなPDFで試してみると、なかなか癖があります。
見たままの文字がそのまま出てくるとは限りません。
欲しいところだけ取るにはワンステップ必要です。
この出てきたテキストから、今回は「業務名称」というところをさらに抽出して、名前に入れたいです。
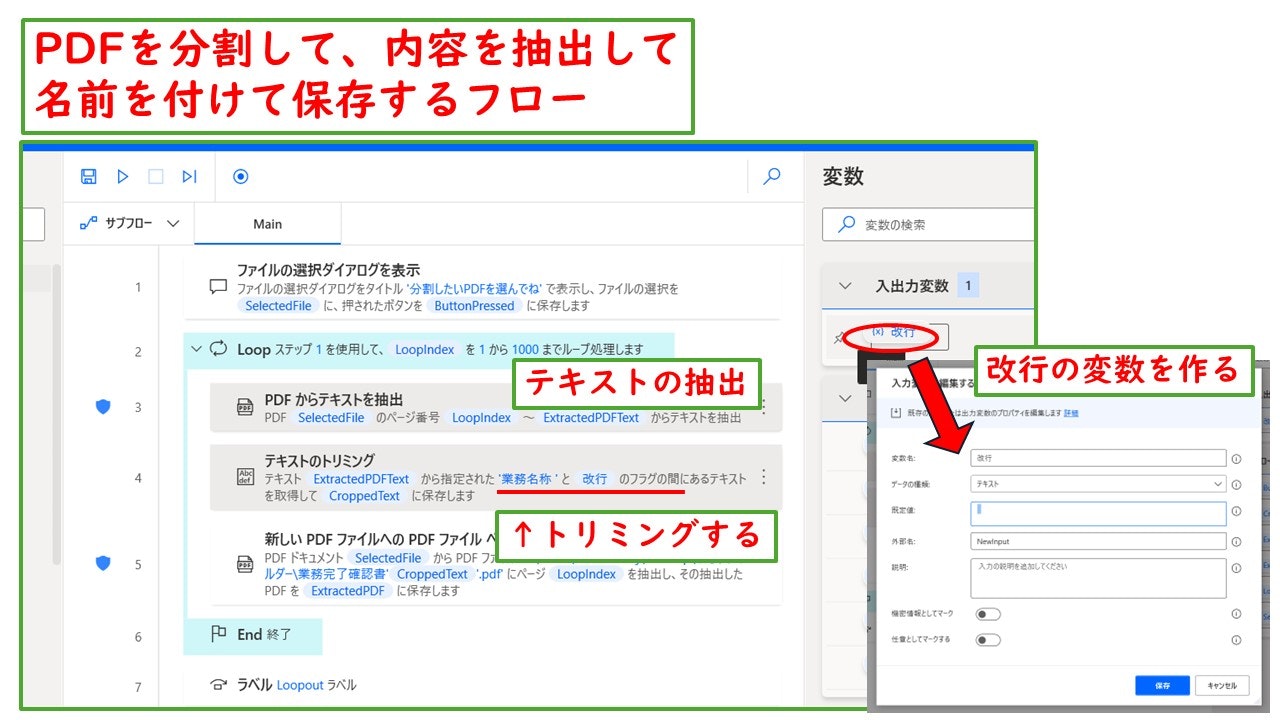
これが完成後のフローになります。
テキストの抽出は「テキストのトリミング」というアクションを使いました。
先ほどの「業務名称」と「改行」の間をトリミングすることで、うまく業務名称を切り抜くことができました。
改行ですが、「テキストのトリミング」アクションのなかで、
「
」
(改行)でトリミングしようとすると、空白ではできませんのようにエラーが出てきます。
そこで、「改行」という変数を作ることによって、認識させることができます。
どうするかというと、右側にある、「入出力変数」 のところで、「改行」を作ることができます。
この「入出力変数」ですが、フローを共有する際には反映されませんので、各自で作成してください。「改行」だけでなく、「半角スペース」「全角スペース」なども作っておくと、テキストのトリミングの際に役立ちます。
※ちなみに、通常のフロー内でも改行やスペースの変数を作ることもできます。が、いろいろ試したところ、入出力変数でやった方が綺麗に切り取れる印象です。
フローはこちらからコピーできます。◆のところは編集してください。
__________Display.SelectFileDialog.SelectFile Title: $'''分割したいPDFを選んでね''' InitialDirectory: $'''C:\Users\matsumuraj\Desktop''' IsTopMost: False CheckIfFileExists: False SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed
LOOP LoopIndex FROM 1 TO 1000 STEP 1
Pdf.ExtractTextFromPDF.ExtractTextFromPage PDFFile: SelectedFile PageNumber: LoopIndex DetectLayout: False ExtractedText=> ExtractedPDFText
ON ERROR
GOTO Loopout
END
Text.CropText.CropTextBetweenFlags Text: ExtractedPDFText FromFlag: $'''業務名称 ''' ToFlag: 改行 IgnoreCase: False CroppedText=> CroppedText
Pdf.ExtractPages PDFFile: SelectedFile PageSelection: LoopIndex ExtractedPDFPath: $'''◆C:\Users\じぶんの\Desktop\新しいフォルダー◆\業務完了確認書%CroppedText%.pdf''' IfFileExists: Pdf.IfFileExists.AddSequentialSuffix ExtractedPDFFile=> ExtractedPDF
ON ERROR
GOTO Loopout
END
END
LABEL Loopout
__________
実行したら、こんな感じです。

これにはさすがの会計担当もニッコリ。
「使います!またなにか作ってくださいね」と言って去っていきました。忙しそうです。
まとめ
そんなこんなで今回はPADでPDFを分割して、おまけに内容を抽出してそれぞれ名前を付けて保存するフローを作成しました。
いろいろ応用が効きそうなので、学びにもなりました。
また、前半のPDF分割だけならすぐ作成できたのと、そこからさらにこうしたい、というのが出てきて、ちょっとしたことから手を出してみるというのも結構効果的だと感じました。
PAD、サクッと作れる部分は作れて、手の込んだものも時間をかければ作れるので、なかなか便利です。おすすめです。
それでは