はじめに
アプリケーションをデプロイした後、パフォーマンスや障害発生などアプリケーションの状態を継続的に監視(モニタリング)する必要がありますが、最近、そのモニタリングの上位互換(?)の概念「オブザーバビリティ(Observability:可観測性)」が登場してきました。
私自身上手く説明ができないのですが、ざっくり申し上げると、観察する能力の向上させることを指していて、各種アプリケーションの情報(トレース、ログ、メトリクスなど)を集約+可視化し、システム全体の稼働状態や障害ポイントの特定を容易に行えるようにしておきましょう!、という感じです。(伝わりますか…?)
AWSからもここ数年でオブザーバビリティ向けのAWSサービスや機能が増えており、非常に注目度の高いトピックなのだと感じております。
そこで今回は、AWSから提供されているオブザーバビリティサービスの一つである、CloudWatch ServiceLensを触って実際にオブザーバビリティを体験してみようと思います。
CloudWatch ServiceLensとは
X-Ray、CloudWatch Logs、CloudWatch Metricsなどの各種サービスに散っていた情報(トレース、ログ、メトリクスなど)を、1か所に統合して表示してくれるサービスです。
なんと、CloudWatch ServiceLensを利用することでの追加料金は発生しません。
もちろん上記に記載したX-Rayなどの各種サービスに対しての課金は従来通り発生しますが、CloudWatch ServiceLens自体は有効化せずとも自動的に情報を集約してくれているので、上記サービス群を利用していた方々は活用しないなんてもったいないです。
なお、CloudWatch ServiceLensを利用するためには、公式に書かれている通り、以下のことを実施する必要があります。
- サービスマップを表示できるように AWS X-Ray をデプロイします。
- CloudWatch エージェントと X-Ray デーモンをデプロイして、CloudWatch メトリクスおよび CloudWatch Logs とのサービスマップの統合を有効にします。
こちらも上記サービス群をすでに利用している方であれば、X-Rayの有効化やCloudWatch Logsへのログ収集は既に行ったことがあるかと思いますので、特別なことは何もありません。
事前準備
準備する内容について
今回はAPI Gateway×Lambda×DynamoDB構成のシンプルなサーバーレスアプリケーションを用意します。
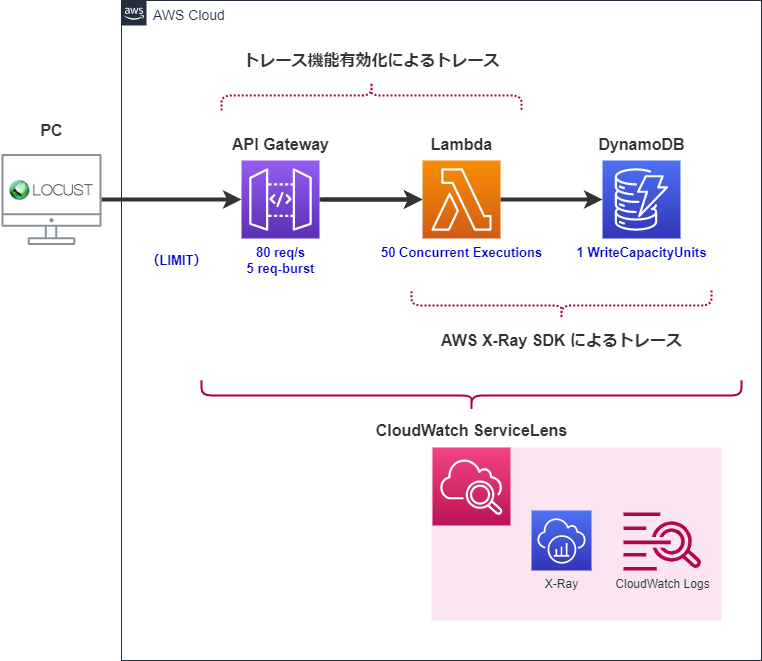
その他に用意する内容は以下の通りです。
- トレースするためには
API GatewayとLambdaのトレース機能(X-Ray)を有効化します。 -
LambdaとDynamoDBの間は標準ではトレースされないため、トAWS X-Ray SDKをLambdaのコード側に仕込み、トレースできるようにします。 - 各種上限値を越えてスロットリングされた場合の挙動を見てみたいので、青文字で書いた上限値を設定した状態で各AWSリソースを構築します。
- スロットリングを発生させるための負荷試験ツールとして
Locustというオープンソースのツールをローカルで起動させて利用します。
サーバーレスアプリケーション構築
CDK(Python)セットアップ
いつものおまじないです。
CDK(Python)でプロジェクトを構築し、Pythonの仮想環境内で作業するように以下のコマンドを実行します。
$ cdk init --language python
$ source .venv/bin/activate
(.venv) $ pip install -r requirements.txt
CDK(Python)サーバーレスアプリケーション準備
「準備する内容について」の章で説明した通りの環境を用意します。
既に説明したこと以外にそこまで特別なことはしていませんので、コードを眺めていただいてお察しいただけると助かります。
from aws_cdk import (
Stack,
Duration,
RemovalPolicy,
aws_lambda as lambda_,
aws_apigateway as apigateway,
aws_dynamodb as dynamodb,
aws_iam as iam,
)
from constructs import Construct
function_timeout = 10
function_memory_size = 128
class TraceServerlessStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# [1] Create DynamoDB Table
dynamodb_table = dynamodb.Table(self, "MyTable",
partition_key=dynamodb.Attribute(
name="username",
type=dynamodb.AttributeType.STRING
),
billing_mode=dynamodb.BillingMode.PROVISIONED,
read_capacity=1,
write_capacity=1,
)
dynamodb_table.apply_removal_policy(RemovalPolicy.DESTROY)
# [2] Create Lambda Layer for X-Ray module
lambda_layer_xray = lambda_.LayerVersion(self, "XrayLayer",
removal_policy=RemovalPolicy.DESTROY,
code=lambda_.Code.from_asset("xray_layer"),
compatible_runtimes=[lambda_.Runtime.PYTHON_3_8]
)
# [3] Create Lambda Function
lambda_function = lambda_.Function(self, "MyFunction",
code=lambda_.Code.from_asset("my_function"),
handler="app.lambda_handler",
runtime=lambda_.Runtime.PYTHON_3_8,
timeout=Duration.minutes(function_timeout),
memory_size=function_memory_size,
tracing=lambda_.Tracing.ACTIVE,
layers=[lambda_layer_xray],
# reserved_concurrent_executions=5,
)
lambda_function.add_environment(
key="TABLE_NAME",
value=dynamodb_table.table_name,
)
lambda_function.add_to_role_policy(
iam.PolicyStatement(
actions=[
"dynamodb:PutItem",
],
resources=[
dynamodb_table.table_arn,
]
)
)
# [4] Create API Gateway
api_gateway = apigateway.RestApi(self, "MyRestApi",
deploy_options=apigateway.StageOptions(
tracing_enabled=True,
data_trace_enabled=True,
logging_level=apigateway.MethodLoggingLevel.INFO,
stage_name="v1",
throttling_rate_limit=80,
throttling_burst_limit=5,
),
)
api_resource_input_data = api_gateway.root.add_resource("input-data")
api_resource_input_data.add_method(
http_method="POST",
integration=apigateway.LambdaIntegration(lambda_function),
)
Lambda Layer(AWS X-Ray SDK for Python)準備
Lambda関数内にはAWS X-Ray SDKが標準で搭載されていないため、自分でLambda関数のソースコードの含める必要があります。
今回はLambda Layerに仕込む方法で準備しました。
Lambda Layerを仕込む際の注意点としては、各 Lambda ランタイムのレイヤーパスが決まっていますので、それに従ってフォルダを構成しなければなりません。
Pythonの場合は、/pythonで始まるフォルダ構成にしますが、その他のランタイムを利用される場合はこちらを確認してご準備ください。
(.venv) $ mkdir -p xray_layer/python
(.venv) $ pip install aws-xray-sdk -t xray_layer/python/
Collecting aws-xray-sdk
Downloading aws_xray_sdk-2.11.0-py2.py3-none-any.whl (102 kB)
|████████████████████████████████| 102 kB 2.9 MB/s
Collecting botocore>=1.11.3
Downloading botocore-1.29.84-py3-none-any.whl (10.5 MB)
|████████████████████████████████| 10.5 MB 11.9 MB/s
Collecting wrapt
Downloading wrapt-1.15.0-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (81 kB)
|████████████████████████████████| 81 kB 32.7 MB/s
Collecting python-dateutil<3.0.0,>=2.1
Using cached python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
Collecting urllib3<1.27,>=1.25.4
Using cached urllib3-1.26.14-py2.py3-none-any.whl (140 kB)
Collecting jmespath<2.0.0,>=0.7.1
Downloading jmespath-1.0.1-py3-none-any.whl (20 kB)
Collecting six>=1.5
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Installing collected packages: six, python-dateutil, urllib3, jmespath, botocore, wrapt, aws-xray-sdk
Successfully installed aws-xray-sdk-2.11.0 botocore-1.29.84 jmespath-1.0.1 python-dateutil-2.8.2 six-1.16.0 urllib3-1.26.14 wrapt-1.15.0
$ ls xray_layer/python/
__pycache__ dateutil urllib3
aws_xray_sdk jmespath urllib3-1.26.14.dist-info
aws_xray_sdk-2.11.0.dist-info jmespath-1.0.1.dist-info wrapt
bin python_dateutil-2.8.2.dist-info wrapt-1.15.0.dist-info
botocore six-1.16.0.dist-info
botocore-1.29.84.dist-info six.py
Lambda関数のコーディング
今回コーディングした内容は以下のとおりです。
import os
import json
import boto3
from aws_xray_sdk.core import patch_all
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
TABLE_NAME = os.environ.get('TABLE_NAME')
dynamodb = boto3.client("dynamodb", region_name="ap-northeast-1")
patch_all()
def lambda_handler(event, context):
logger.info('>> process start')
try:
body = json.loads(event.get("body"))
options = {
"TableName": TABLE_NAME,
"Item": {
"username": {"S": body.get("username")},
"sequence": {"N": str(body.get("sequence"))},
"timestamp": {"S": body.get("timestamp")},
}
}
dynamodb.put_item(**options)
logger.info("Put Item Succsess.")
return {
"statusCode": 200,
"body": "Succsess",
}
except dynamodb.exceptions.ProvisionedThroughputExceededException:
logger.error("Provisioned ThroughputExceeded Exception")
return {
"statusCode": 503,
"body": "Faild(ProvisionedThroughputExceededException)",
}
except Exception:
import traceback
logger.error(traceback.format_exc())
raise Exception("Internal Error")
finally:
logger.info('<< process end')
X-Rayのトレースは基本的にAWS X-Ray SDKをインポートして、patch_all()を唱えるだけです。
上記を唱えると、こちらに書かれているライブラリの追跡が可能なようです。
上記公式ページに書いてある通り、AWS SDK for Python (Boto)クライアントが測定対象になっていますので、LambdaとDynamoDB間のトレースができます。
今回は測定しませんが、mysql-connector-pythonやpsycopg2などのDBのクライアントも対象になっていますので、DBとのトレースも簡単に行えそうです。
その他コーディング内容はざっくり以下の内容になっています。
-
DynamoDBへの書き込みが成功すれば、HTTPステータス200を返却する。 -
DynamoDBのスロットリングエラーが発生した場合、HTTPステータスで503を返却する。 - その他のエラーが発生した場合、Lambda関数自体例外をスローする。(HTTPステータスで
502を返却される想定)
CDKで環境デプロイ
もろもろの準備が整いましたので、AWSにデプロイしていきます。
$ cdk deploy
{中略}
TraceServerlessStack: deploying... [1/1]
[0%] start: Publishing 53522fccd87a3515e1f97df8275f7ca2696be9ffdf658a237e1a59acb44628cb:current_account-current_region
[0%] start: Publishing 2bd6f8763ee11fcf5aeb587f4bc89b8e21d8050d201df30edb6ec431a9f97713:current_account-current_region
[0%] start: Publishing 122cf804c7c71c75c96fc9482482e22aa1e53e4004a41b12bf3c214b9e375c5d:current_account-current_region
[33%] success: Published 53522fccd87a3515e1f97df8275f7ca2696be9ffdf658a237e1a59acb44628cb:current_account-current_region
[66%] success: Published 2bd6f8763ee11fcf5aeb587f4bc89b8e21d8050d201df30edb6ec431a9f97713:current_account-current_region
[100%] success: Published 122cf804c7c71c75c96fc9482482e22aa1e53e4004a41b12bf3c214b9e375c5d:current_account-current_region
TraceServerlessStack: creating CloudFormation changeset...
✅ TraceServerlessStack
✨ Deployment time: 123.11s
Outputs:
TraceServerlessStack.MyRestApiEndpoint4C55E4CB = https://y9kv654qgd.execute-api.ap-northeast-1.amazonaws.com/v1/
Stack ARN:
arn:aws:cloudformation:ap-northeast-1:0123456789AB:stack/TraceServerlessStack/8a125a10-ba72-11ed-85bd-060d317cacb5
✨ Total time: 127.42s
無事デプロイできました。
動作確認
念のため問題なくアプリケーションが動くか確認します。
先ほどのcdk deployの結果で出力されているエンドポイントを利用して、Lambdaのソースコードで定義したパラメータをリクエストに添えて、curlコマンドを実行しています。
$ curl -X POST https://y9kv654qgd.execute-api.ap-northeast-1.amazonaws.com/v1/input-data -d '{"username":"User1","timestamp":"2023/03/04 15:00:00","sequence": 1}'
Success
成功したメッセージ(Success)を受け取れました。
さらにDynamoDBのテーブルを確認すると、先ほどリクエストで送ったデータが入っていました。

きちんと動いていそうです。
負荷試験ツール構築
過去にLocustと呼ばれる負荷試験ツールを利用したことがあったため、そちらをローカルで起動して動かします。
(AWS ECS(Fargate)で構築した過去の記事はこちら)
Locustの詳細は触れませんが、Locustでは以下の内容を実施するように仕込みます。
-
POSTメソッドで画面から指定されたエンドポイント+input-dataパスに対してリクエストを送信する。 - リクエストに含めるパラメータは以下の内容で、1/3の確率で
usernameが飛ばないようにする。(Lambda関数内でアプリケーションエラーを発生させるため)-
username: ユーザー名(WEBUIで指定したユーザ数分生成される) -
sequence: 1ユーザ単位のリクエスト送信回数 -
timestamp: リクエスト送信時刻
-
-
LocustのWebUIから指定したユーザ数が10秒間隔で同時にリクエストを送信する。
以降はLocust環境の準備手順です。
- LocustのDocker環境構築向けフォルダ作成
$ mkdir locust -
docker-composeファイル作成locust/docker-compose.ymlversion: '3' services: master: build: ./ ports: - "8089:8089" command: -f /mnt/locust/locustfile.py --master -P 8089 worker: build: ./ command: -f /mnt/locust/locustfile.py --worker --master-host master -
Dockerfileファイル作成(テストファイルを公式のLocustイメージ内に含めるだけ)locust/DockerfileFROM locustio/locust WORKDIR /mnt/locust COPY *.py /mnt/locust/ -
Locustテストコード作成locust/locustfile.pyfrom locust import HttpUser, task, events, constant from locust.runners import MasterRunner, WorkerRunner import datetime import json usernames = [] def setup_test_users(environment, msg, **kwargs): usernames.extend(map(lambda u: u["name"], msg.data)) @events.init.add_listener def on_locust_init(environment, **_kwargs): if not isinstance(environment.runner, MasterRunner): environment.runner.register_message("test_users", setup_test_users) @events.test_start.add_listener def on_test_start(environment, **_kwargs): if not isinstance(environment.runner, WorkerRunner): users = [] for i in range(environment.runner.target_user_count): users.append({"name": f"User{i+1}"}) worker_count = environment.runner.worker_count chunk_size = int(len(users) / worker_count) for i, worker in enumerate(environment.runner.clients): start_index = i * chunk_size if i + 1 < worker_count: end_index = start_index + chunk_size else: end_index = len(users) data = users[start_index:end_index] environment.runner.send_message("test_users", data, worker) class WebAccessUser(HttpUser): seq = 0 wait_time = constant(10) def __init__(self, parent): self.username = usernames.pop() super().__init__(parent) @task(3) def web_access_success(self): self.seq += 1 request_body={ "username": self.username, "sequence": str(self.seq), "timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") } self.client.post( url="/input-data", headers={"Content-Type": "application/json"}, json=request_body, ) print(json.dumps(request_body)) @task(1) def web_access_faild(self): self.seq += 1 request_body={ "sequence": str(self.seq), "timestamp": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") } self.client.post( url="/input-data", headers={"Content-Type": "application/json"}, json=request_body, ) print(json.dumps(request_body)) - Locust起動
$ cd locust $ docker-compose build $ docker-compose up --scale worker=2 - Locust起動画面
直前のコマンドでLocustのコンテナを起動させたため、ローカルでLocustが動いている状態です。
その状態でブラウザからhttp://localhost:8089/にアクセスしてLocust画面を表示させます。

Let's オブザーバビリティ体験
ここからは実際にサーバーレスアプリケーションに負荷をかけてCloudWatch ServiceLensから確認できる景色を眺めていきましょう。
Locostから負荷をかける
Locust実行前
Locustにて以下の指定を行って負荷をかけます。
-
Number of users(リクエストするユーザ数)は200ユーザとする。 -
Spawn rate(リクエストを増やしていく数)は200とし、初回アクセスから最大ユーザ数でリクエストを送信する。 -
Host(アクセス先のホスト)はAPIGatewayのエンドポイントを指定する。(Stage含む) -
Run time(実行時間)は1分間とする。

Locust実行後
上記指定で実行した結果はこちら。1,100リクエストのうち、Failsが721。なかなかの数です。

Failuresタブを開くとエラーの数とその内容をランキング形式で確認できました。

CloudWatch ServiceLensで結果を確認する
ようやっとCloudWatch ServiceLensの画面です。
以降のCloudWatch ServiceLens画面は、出力時間を負荷試験実施時間に絞り込み表示しています。
サービスマップ
まずはサービスマップを確認します。
サービスマップでは、リクエスト元のクライアントから各種到達地点のAWSサービスがノードとして表現されており、円グラフで成功と失敗の割合が表現されてます。
また、API Gatewayに関してはスロットリングエラーとその他の障害で色分けされて表現されていますね。

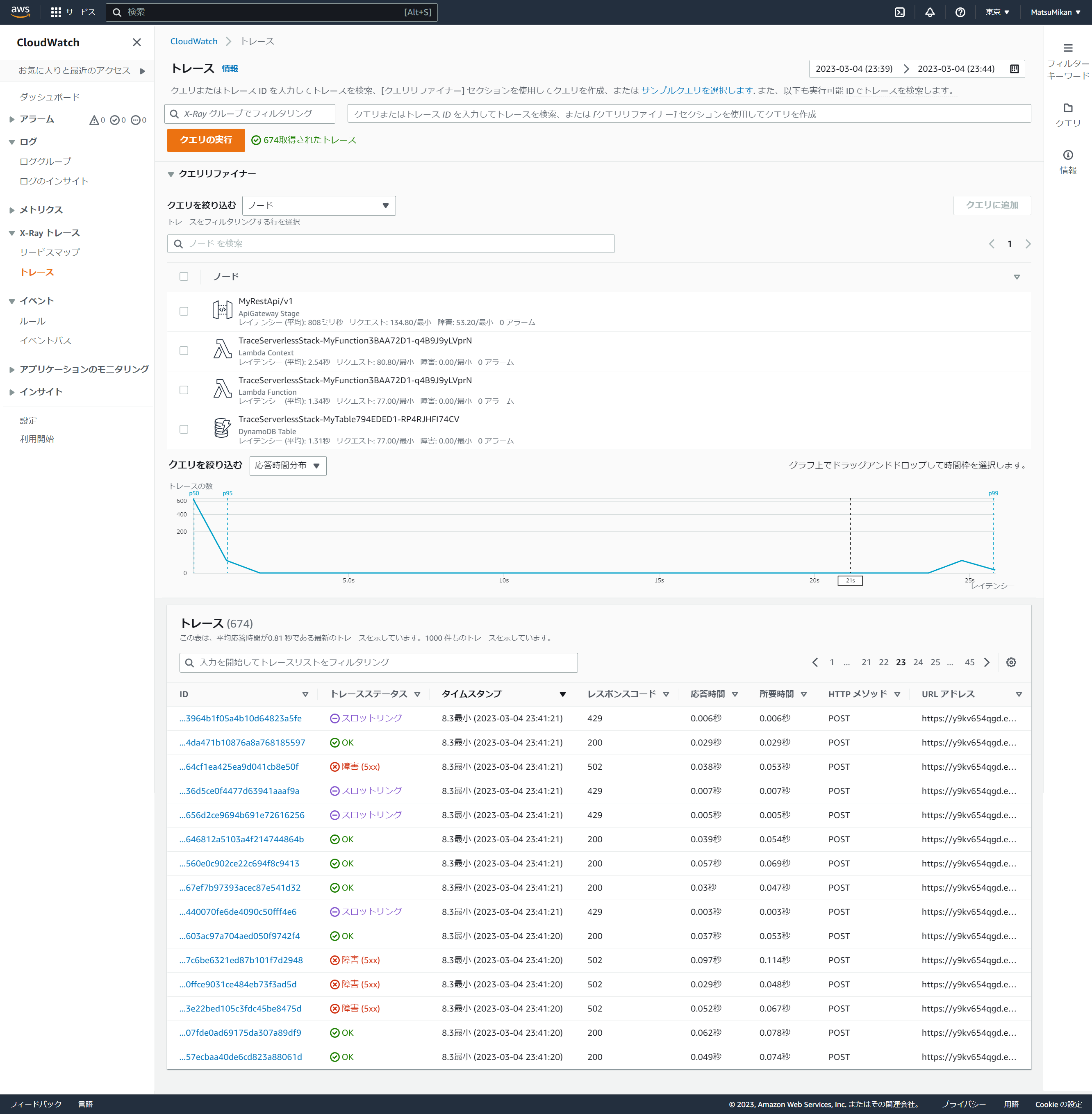
トレース一覧
次はX-Rayにより集約されたトレースの一覧です。
トレース件数が674件と出ています。(実際のリクエスト数と少ない理由は後述でご説明します)
現時点ではすべてのトレース一覧がページで別れて表示されていますが、クエリ機能を利用することで、障害や一定のレイテンシを越えたものトレースのみを抽出することもできそうです。
トレース①成功
ここで成功のトレースを見てみましょう。

マップ情報、タイムライン、ログが確認できます。
タイムラインでは各サービスのポイントでそれぞれどの程度処理時間がかかっているかを確認できますので、パフォーマンスチューニングでは重宝する情報でないでしょうか。
また、注目いただきたいのが一番下のログです。
こちらにはAPI Gatewayの実行ログとLambdaの実行ログが重なって出力されています。(@logのカラムでロググループ名が確認できますが、こちらでどちらのログかを確認することができます)
CloudWatch Logsの画面ではこれらのログが離れて出力されているのですが、CloudWatch ServiceLensから見ると一つの画面で同時に見れるのが利点です。
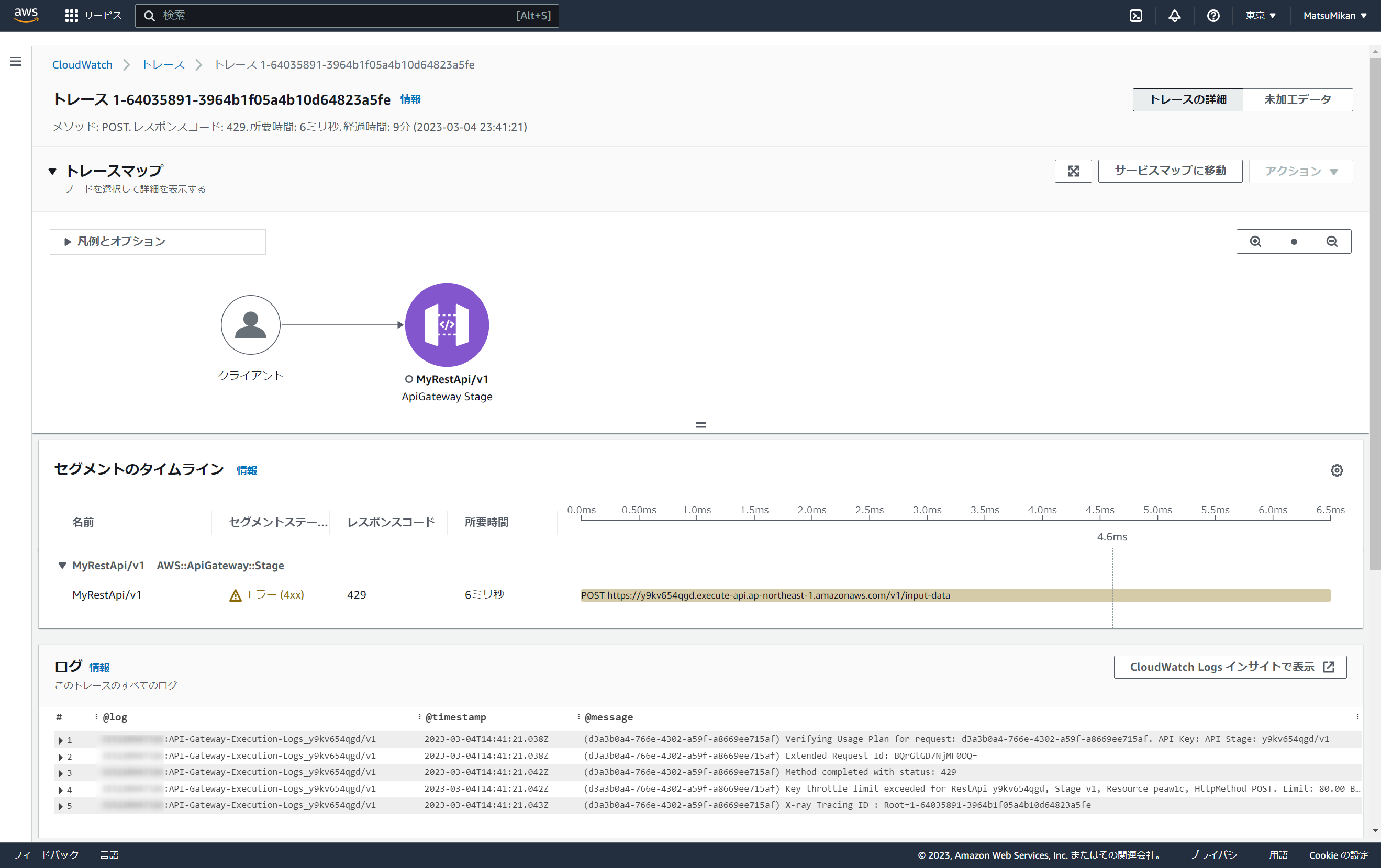
トレース②失敗(API Gatewayのスロットリングエラー)
API Gatewayのスロットリングエラーのトレースはいたってシンプルで、API Gatewayにしかリクエストが到達していないので以下のような表現になっています。
トレース③失敗(Lambdaのスロットリングエラー)
LambdaのスロットリングエラーもAPI Gatewayのスロットリングエラーと同様で、API Gatewayにしかリクエストが到達していないので以下のような表現になっています。
これは、Lambda関数自体を呼び出せていないため、想定通りではあります。

トレース④失敗(Lambdaのアプリケーションエラー)
Lambdaのアプリケーションエラーでは、DynamoDBテーブルのプライマリーキーusernameに対してNoneを送るような処理を行っています。そのため、botocore.exceptions.ParamValidationErrorが発生していたのですが、なぜかDynamoDBがOKになっていますね。
HTTPステータスが502となるのは想定していたのですが、DynamoDBにはリクエストを送信できていないのでそもそもDynamoDBはマップに表現されないと思っていたのですが…少し想定外でした。
(訂正:2023/03/05)
Lambda関数内でbotocore.exceptions.ParamValidationErrorのexceptionを丸めているのが原因だと思われるので、これは私のアプリケーションの設計ミスでした…。なので想定通りの動きになっています。

トレース⑤失敗(DynamoDBのスロットリングエラー)
DynamoDBのスロットリングエラーは、DynamoDBまでリクエストを送信してエラーとなっているところまできちんと表現されていますね。

こんな感じで、CloudWatch ServiceLensを確認するだけで障害発生率や障害発生しているサービスの特定、障害発生内容(ログ)の確認までスムーズに行えることが確認できました。
静止画だけで伝わりづらいと思うのですが、基本的にマウスクリックだけで多くの情報を入手できているので、調査の速さ・手軽さが体験できました。
【補足】X-Rayのサンプリングルールおよび上限値について
X-Rayはデフォルトでサンプリングルールが適用されているので全リクエストの結果は見れない
「Let's オブザーバビリティ体験」の章でも少し触れましたが、今回のリクエスト総数と、トレース数が一致していません。
- リクエスト総数:
1100※Locustの実行後の画面参照 - トレース数:
674※CloudWatch Lensのトレース一覧画面参照
X-RayはAWSによる計らいで、1r/sec に制限し、次に 5 固定レートに制限という上限が設けられています。

公式では以下のような説明がされていました。
デフォルトでは、X-Ray SDK は 1 秒ごとに最初のリクエストを記録し、追加のリクエストの 5% を記録します。
開始時にサービス料がかからないように、デフォルトのサンプリングレートは控えめになっています。 デフォルトのサンプリングルールを変更し、サービスまたはリクエストのプロパティに基づいてサンプリングを適用する追加のルールを設定するように X-Ray を設定できます。
課金を考えてデフォルト値でX-Rayに記録する上限を設定しているとのことです。
もしすべてのリクエストを記録させたい場合は、このサンプリングレートを独自で設定するのがよさそうです。
X-Rayは1秒当たりに記録できる上限がある
「すべてのリクエストを記録させたい場合はこのサンプリングレートを設定せよ」と数行前に申し上げましたが、残念ながら上限値があります。
こちらは公式にあるとおり現時点は1秒当たり2,600までで、上限緩和はできませんのであらかじめご注意ください。
(補足:2023/03/12)
クォータの単位を濁してしまいましたが、「1秒当たり2,600」はX-Ray に送信できる 1 秒ごとのセグメントの最大数となります。
セグメントは、1つのサービスまたはアプリケーションのコンポーネントに関するすべてのデータポイントをカプセル化したもの、だそうです。
ちょっとわかりづらいですが、上記で検証したもので表すと、「1つのトレースの中で、API Gateway、Lambda(Context)、Lambda(Function)、DynamoDBの計4つのセグメントが含まれている」、ということになります。
そのため、セグメントの多いリクエストを情報を収集しようとすると、クォータに引っ掛かりやすいので、あらかじめご認識ください。
【余談】本日のはまりポイントと謎
Lambda関数の同時実行数が上手く指定できない件について
本当はLambda関数の同時実行数を5あたりに設定したかったのですが、CDKで以下のエラーが出ました。
Stack Deployments Failed: Error: The stack named TraceServerlessStack failed to deploy: UPDATE_ROLLBACK_COMPLETE: Resource handler returned message: "Specified ReservedConcurrentExecutions for function decreases account's UnreservedConcurrentExecution below its minimum value of [50]. (Service: Lambda, Status Code: 400, Request ID: 7cff18f2-9fe3-4089-9ee2-2f4d806a1861)" (RequestToken: fb5e3690-a2bd-fdbc-4190-4575aee18226, HandlerErrorCode: InvalidRequest)
マネージメントコンソールから設定しようとしても以下のようなメッセージが。

過去には設定できた記憶があるのですが、仕様が変わったのでしょうか。
確かに公式には以下のような記述があったため、もしかすると100以下に設定できないのかも…?と想定しております。
関数レベルでは、すべての関数全体で、デフォルトで最大 900 ユニットの同時実行を予約できます。同時実行を明示的に予約しない関数のために、100 ユニットの同時実行が常に予約されています。
今回の本題ではないので浅くしか調べていませんが、今後は同じようにはまりそうな予感がするので裏で調べておこうと思います。
※ちなみに私のアカウントでは50を下回ることはできない、と言われていますが、おそらく次に説明する内容が関わっています。
Lambda関数の同時実行数のアカウント上限値が50だった件について
AWSのデフォルトの上限値は1000のはずなのに、私のAWSアカウントは50が適用されていました。

そのため今回は同時実行数を関数レベルで指定せず、アカウントレベルの上限値を利用したテストを実施してなんとかやりたい検証を行った感じです。
AWSサポートに上限値を下げるような申請をした記憶も履歴もなく、本件謎に包まれているのですが、私個人のAWSアカウントが2015年8月に作成されたものなので、もしかしたら当時の上限値だった可能性はあります。
しかし当時の情報が見当たらず確信が持てず…もやもやしております。
もし、Lambda関数の同時実行数の歴史を知っている方がいらっしゃいましたらぜひ教えてください。
【後日談】今回の検証で発生した課金チェック
(課金額がわかり次第追記予定です)
おわりに
X-RayやCloudWatch Logsを個々に確認して障害を調査することはよくやっていたのですが、X-RayからトレースIDを引っ張ってきてCloudWatch Logs Insightsで検索して…とコンソール画面を行き来することがあり、手間と時間がかかっていました。
それがCloudWatch ServiceLensを使えば簡単に見れるようになり、調査時間が短縮されそうです。
これが、観察する能力(オブザーバビリティ)の力、ということでしょうか。(表現が難しい…)
なお、今年(2023年)の1月にO'Reilly社よりオブザーバビリティの本も出ているそうで、以下の記事で概要をわかりやすく紹介されていました。
大変興味があるので、購入してお勉強したい所存です。
こちらからは以上です。
参考URL