本記事の概要
この記事では「IT Text 自然言語処理の基礎」(オーム社)の 第1章「自然言語処理の概要」 に付いている演習問題を詳しく解説します。
書籍にも略解はありますが、解説が省略されていたりします。
略解でわからなくなったときは、この記事を参考にしてもらえればと思います!
問1
Penn Treebankの品詞タグ付けのアノテーションガイドラインを参考にして、以下の例文の斜体の単語の品詞を答えよ。
(1) He was invited by some friends of hers.
(2) He was very surprised by her remarks.
(1) VBN、動詞(過去分詞)
(2) JJ、形容詞
Penn Treebankは 注釈付きコーパス(annotated corpus) のひとつで、英語テキストの基礎的な解析に用いられる代表的なものです。ここでいう「注釈」とは「品詞タグ」のことで、本問ではその品詞タグをガイドラインにそって付けてくださいね、ということを問うています。
アノテーションガイドラインの原文はこちら↓です。
全部に目を通すのは大変ですが、テキストにはその抜粋の日本語訳が表1.1・図1.1に掲載されているので、これを使いましょう。
(1)を日本語に訳すと
彼は彼女の友人たちに誘われた。
となります。
「invited」は受動態で、「invite(招待する/誘う)」の過去分詞形です。
したがって表1.1よりVBN、つまり動詞(過去分詞) です。
(2)を日本語に訳すと
彼は彼女の発言にとても驚いた。
となります。
「surprised」は、動詞「surprise(驚かす)」の過去分詞形とも捉えられますし、形容詞「surprised」とも捉えることができます。
迷ったのでここはガイドライン(図1.1)を見てみましょう。
現在分詞(VBG)との区別に関して,単語が以下の条件のいずれかを満たすならば,形容詞(JJ)のタグを付与する.
...(中略)...
- be動詞の構文で用いられる場合,そのbe動詞をbecomeやfeelなどで置き換えることができる.
- The conversation was depressing /JJ.
- The conversation became depressing /JJ.
- The place feels depressing /JJ.
He was very surprised by her remarks.
は
He became very surprised by her remarks.
と書き換えることができるので、この条件にあてはまります。
したがって、ここでの「surprised」はJJ、つまり形容詞とタグ付けされます。
問2
表1.2のランキングを作成するプログラムを実装せよ。
(a) すべての単語
順位 単語 出現回数 1 の 81,162 2 に 53,057 3 は 49,361 4 が 42,113 5 を 36,614 6 と 32,465 7 年 24,667 8 で 18,988 9 いる 12,846 10 さ 12,448 (b) 名詞のみ
順位 単語 出現回数 1 国 9,571 2 語 6,129 3 人 5,864 4 日本 4,625 5 こと 4,401 6 世界 3,390 7 政府 3,267 8 島 3,211 9 大統領 3,157 10 共和 3,042
テキストによると、表1.2(a)は次のようにして作成されています。
...日本語版ウィキペディアから世界中の国家に言及している記事を抽出し,マークアップ(MediaWiki記法)を除去したテキストを対象として確認してみよう.
表1.2(a)に,コーパス中に含まれる単語のうち,その出現回数,すなわち出現頻度(frequency)が高いトップ10のランキングを示した.
「日本語版ウィキペディアから世界中の国家に言及している記事」については、↓のデータが使われています。
このデータにはマークアップが含まれており、下記リンク先に掲載されているようなものを除去する必要があります。
しかしこれらをすべて正確に除去するのはかなり骨が折れます。
正規表現で除去することになりますが、ここでは面倒なのでやりません。
興味のある方は以下の記事を参考にしてください。
その代わり、Wikipediaから該当記事をスクレイピングします。
そうすればマークアップのない文章を取得することができます。
以下がPythonによる実装です。
# MeCabをインストールしてimport
!pip install mecab-python3 unidic-lite
import MeCab
# Wikipediaをスクレイピングして形態素解析
import requests
from bs4 import BeautifulSoup
import re
tagger = MeCab.Tagger('-Odump')
words = dict()
for title in df['title'].values:
response = requests.get('https://ja.wikipedia.org/wiki/' + title)
soup = BeautifulSoup(response.content, 'html.parser')
soup = soup.find('div', {'id':'mw-content-text'})
reflist_div = soup.find('div', {'class': 'reflist'})
if reflist_div:
next_elements = reflist_div.find_next_siblings()
for element in next_elements:
element.decompose()
text = soup.text
text = re.sub(r'詳細は[^\s]+を参照', '', text)
text = text.replace('[編集]', '')
text = text.replace('この節の加筆が望まれています。','')
text = text.replace('(英語版)', '')
text = text.replace('この節は検証可能な参考文献や出典が全く示されていないか、不十分です。出典を追加して記事の信頼性向上にご協力ください。(このテンプレートの使い方)', '')
parsed_text = tagger.parse(text).split('\n')
words[title] = [t.split(',')[0].split(' ')[1:] for t in parsed_text]
# DataFrameにまとめる
import pandas as pd
words_all = []
for lst in words.values():
words_all += lst
df_words = pd.DataFrame(words_all, columns=['word','tag'])
# 単語の出現頻度
print(df_words['word'].value_counts().head(30))
# 名詞の出現頻度
print(df_words[df_words['tag']=='名詞']['word'].value_counts().head(30))
出力結果は次のようになりました。
※スクレイピングしているため、記事が編集されると出力結果は変わります。
の 106743
、 98650
に 74540
は 61905
。 52116
が 51279
て 45308
を 45244
で 41410
た 40758
と 40635
し 35829
年 34989
( 24970
) 24307
・ 21024
. 19501
いる 17534
れ 16893
月 16077
[ 15785
さ 15460
も 14475
ある 13869
日 13005
人 11771
]。 11054
「 11044
」 11030
する 10871
年 34989
月 16077
1 9580
語 8840
2 7471
3 6068
日本 5531
こと 5440
4 5208
5 4769
世界 4612
6 4047
大統領 4001
共和 3880
8 3811
ため 3715
7 3698
万 3648
政府 3501
9 3457
経済 3295
10 3273
州 3077
アメリカ 3065
独立 2990
フランス 2976
12 2766
軍 2695
地域 2609
国際 2596
というわけで、出力結果にもとづくとランキングは以下のようになります。
(a) すべての単語
| 順位 | 単語 | 出現回数 |
|---|---|---|
| 1 | の | 106,743 |
| 2 | に | 74,540 |
| 3 | は | 61,905 |
| 4 | が | 51,729 |
| 5 | て | 45,308 |
| 6 | を | 45,244 |
| 7 | で | 41,410 |
| 8 | た | 40,758 |
| 9 | と | 40,635 |
| 10 | し | 35,829 |
(b) 名詞のみ
| 順位 | 単語 | 出現回数 |
|---|---|---|
| 1 | 年 | 34,989 |
| 2 | 月 | 16,077 |
| 3 | 語 | 8,840 |
| 4 | 日本 | 5,531 |
| 5 | こと | 5,440 |
| 6 | 世界 | 4,612 |
| 7 | 大統領 | 4,001 |
| 8 | 共和 | 3,880 |
| 9 | ため | 3,715 |
| 10 | 万 | 3,648 |
問3
表1.3のランキングを作成するプログラムを実装せよ。
(a) 単語の頻度
順位 単語 出現回数 1 日本 796 2 国 359 3 日 148 4 世界 143 5 こと 142 6 人 132 7 関係 121 8 経済 113 9 中国 112 10 ため 88 (b) TF-IDF
順位 単語 TF DF TF-IDF 1 天皇 65 16 178.2 2 倭国 30 2 144.6 3 朝鮮 61 26 137.6 4 列島 42 11 130.9 5 書紀 22 1 121.3 6 明示 47 23 111.8 7 琉球 25 3 110.4 8 沖縄 37 14 106.4 9 倭 21 2 101.2 10 新幹線 21 4 86.7
本問では、日本のWikipediaを対象に
- (a) 名詞の出現頻度のランキング
- (b) 名詞のTF-IDFのランキング
を作成することが問われています。
(a)については、前問の結果を流用できます。
df_ja = pd.DataFrame(words['日本'], columns=['word','tag'])
df_ja[df_ja['tag']=='名詞']['word'].value_counts().head(30)
出力結果から、名詞の出現頻度のランキングは次のようになります。
| 順位 | 単語 | 出現回数 |
|---|---|---|
| 1 | 日本 | 1,270 |
| 2 | 年 | 1,124 |
| 3 | 市 | 366 |
| 4 | 県 | 357 |
| 5 | 月 | 298 |
| 6 | 世界 | 239 |
| 7 | 区 | 224 |
| 8 | こと | 201 |
| 9 | 関係 | 199 |
| 10 | 経済 | 164 |
続いて、(b)のTF-IDFのランキングを作成しましょう。
TF-IDFの定義は次式で定義されます。
$$
\text{TF-IDF}(x,d) = \text{TF}(x,d) \times \log\left(\frac{N}{\text{DF}(x)}\right)
$$
ここで、$\text{TF}(x,d)$は単語$x$の文書$d$における出現頻度、$\text{DF}(x)$は単語$x$が出現する文書の個数を表します。
本問では「$d=$日本のWikipedia記事」として考えています。
実装は以下のようになります。
# TFの計算
TF = df_ja[df_ja['tag']=='名詞']['word'].value_counts()
TF = TF[~TF.index.str.isdigit()] # 数字は除去
# DFの計算(20分くらい時間かかる)
DF = []
for w in TF.index:
cnt = 0
for lst in words.values():
if [w, '名詞'] in lst:
cnt += 1
DF.append(cnt)
df_tfidf = pd.DataFrame()
df_tfidf['TF'] = TF
df_tfidf['DF'] = DF
# TF-IDFの計算
import numpy as np
N = len(words)
df_tfidf['TF-IDF'] = df_tfidf['TF'] * np.log(N / df_tfidf['DF'])
# TF-IDFの大きい10単語を表示
df_tfidf.sort_values('TF-IDF', ascending=False).head(10)
DFの計算が非効率だと思うので、もっと早く計算する方法があると思います…。
結果は次のようになりました。

日本独自の単語が並んでいることが確認できましたね。
問4
図1.2のグラフを描画するプログラムを実装せよ。
ジップの法則を確認するグラフを描画する問題です。
ジップの法則は、単語$x$の出現頻度を$f_x$、出現順位を$r_x$、$x$に依らない定数を$C$とすると
$$f_x \times r_x = C$$
が成り立つことを主張しています。
この式の両辺の対数をとると
$$
\begin{align*}
\log_{10}f_x + \log_{10}r_x &= \log_{10}C \\
\therefore \log_{10}f_x &= -\log_{10}r_x + \log_{10}C
\end{align*}
$$
なので、両対数グラフを描き、直線になっているかを確かめればよいです。
import matplotlib.pyplot as plt
word_rank = df_words['word'].value_counts().reset_index(drop=True)
plt.scatter(word_rank.index, word_rank.values)
plt.xscale('log')
plt.yscale('log')
plt.ylabel('frequency')
plt.xlabel('rank')
plt.show()
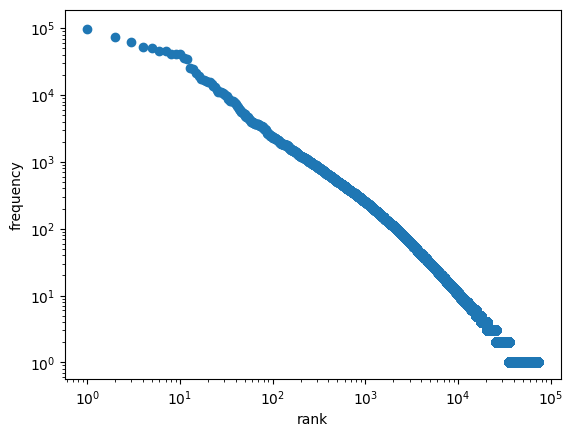
だいたい直線形になっているので、ジップの法則に従っていることがわかる。
問5
ジップの法則にはさまざまな適用例および関連概念・法則がある。それらを調べて説明せよ。
略解で紹介されている例について、実際のデータを調べてみました。
- ウェブサイトのアクセスランキング
- 収入のランキング
【ウェブサイトのアクセスランキング】
私の個人運営ブログのアクセスデータ(Google Search Console)を使って検証してみました。
各検索クエリに対する、クリック回数と順位の関係を下図に示します。

ちょっとまがっているような気もしますが、大目に見れば直線です。
【収入のランキング】
日本の上場企業の平均年収データ(2022)を使って検証しました。
各企業の平均年収と順位の関係が下図です。

下位がイレギュラーな形となっていますが、それを除けばジップの法則に従っていると言えそうですね。
関連概念としては、
- ロングテール
- パレートの法則(80-20の法則)
が挙げられています。
ロングテール戦略はWeb販売においてよく用いられる戦略です。
Amazonなどのネットショップでは、よく売れる人気商品だけではなく、売れないニッチな商品も取り揃えていますよね。ロングテール戦略では、少数の人気商品ではなく、その他大勢の商品の販売量を積み重ねて全体の売上をかさ上げしていきます。
リアル店舗ではその逆で、少数の人気商品が売り上げの大部分を占めることが多いです。
パレートの法則(80-20の法則) は「全体の成果の80%は、全体を構成する要素の20%が出している」ことを主張する法則です。
問6
"I made her duck."という英語の文の意味を考えよ。
彼女が食べるダックを私が料理した。
彼女が飼っているダックを私が育てた。
私は彼女に身をかがめさせた。
私は彼女をダックに変えた。
同じ文章であっても、文脈によって係り受け・品詞・意味が変わってくるという自然言語処理の難しさを実感してもらうための問題ですね。
問7
「乗用車が中央分離帯を乗り越えて走ってきたトラックと正面衝突した」という文の係り受け木を図示せよ。
文章をどこで区切るかによって意味が変わってくる例です。
小学校の頃に国語の授業で勉強しましたね。
(a)「乗用車が中央分離帯を乗り越えて、走ってきたトラックと正面衝突した」
(b)「乗用車が、中央分離帯を乗り越えて走ってきたトラックと正面衝突した」