概要
本記事では2022年12月に公開された論文「GraphCast: Learning skillful medium-range global weather forecasting」の概要を解説します。
GraphCastは気象予報を行う機械学習ベースのモデルであり、2023年11月にGoogle Deepmindから以下のような記事が出され各所で話題を集めました。
簡単に言うと
この論文の内容を、落合陽一先生のフォーマットで簡単にまとめます。
どんなもの?
GNN(グラフニューラルネットワーク)を使った全球中期気象予報モデル。10日間の全球気象予報を高解像度で迅速に行うことができる。1380の評価対象変数のうち90%の変数で、ECMWFの数値予報モデル(HRES)の精度を上回った。
先行研究と比べてどこがすごい?
- 数値予報モデルと比べて...
- 数値予報モデルベースの予報では、計算量を増加させたり、モデルの改善によって精度を上げてきた。
- GraphCastは、過去の膨大なデータを使って精度を上げることができる。
- 過去の機械学習モデルと比べて…
- 従来の機械学習モデルでは、10日間の中期予報となると数値予報モデルに劣る精度だった。
- GraphCastは、10日間の予報でも数値予報モデルの精度を上回った。
技術や手法のキモはどこ?
モデルとしてGNNを採用。正二十面体(M0)の各面を4分割して、さらに4分割…を6回繰り返した"multi-mesh"構造を使っている。

どうやって有効だと検証した?
ECMWFの数値予報モデルHRES(High Resolution Ensemble Forecast)と、機械学習ベースモデルPangu-Weather(たぶんVision Transformer使ってる)と、GraphCastを比較。
- HRES vs GraphCast
- 1380ターゲットのうち90.3%でGraphCastの精度がHRESを上回った。
- Pangu-Weather vs GraphCast
- 252ターゲットのうち99.2%でGraphCastの精度がPangu-Weatherを上回った。
評価指標は、RMSE(Root Mean Squared Error)とACC(Anormaly Correlation Coefficient)を用いている。
議論はある?
- 下図のように、上層ではGraphCastよりも数値予報モデルの方が依然精度が高い。

- 不確実性の処理
- HRESでは物理方程式をベースとしているので、予測は決定論的。初期値をわずかにずらしたときの予測を出すことで不確実性を表現。
- しかし、GraphCastは出力を空間的に平滑化する(=ぼかす)ことで不確実性を表現してしまう
- →不確実性をより明示的にモデル化するシステムの構築が重要。
概要はここまで。
ここからは、もう少し詳しく見ていくことにします。
数値予報モデルと機械学習モデルの比較(Introduction)
数値予報
現在の天気予報は、数値天気予測(NWP; Numerical Weather Prediction)が主流です。
その特徴として、論文によると
- 計算量を増やすと精度が向上する
- 熟練のエキスパートたちが、モデル・アルゴリズム・近似のうまい方法を見つけることで精度が改善
- しかし、過去のデータ量が増えても精度はあまり上がらない
- 気象データは膨大にあるものの、近年までデータを使って直接予報モデルの性能を向上させる実用的な方法が存在せず
という点があるそうです。
機械学習ベース
そこで代替手段として登場したのが機械学習ベースの気象予測モデル(MLWP; Machine Learning-based Weather Prediction)です。
機械学習ベースのモデルでは過去のデータを直接学習し、予報を行います。
データを直接学習することのメリットとして、方程式では表現できないようなパターン・スケールを捉えることができる点が挙げられています。
また、スパコンとかではなくDeepLearning用の計算ハードウェア(GPUやTPU)を使うことで、高速かつ効率的な計算が可能です。
実際、先行研究では、数値予報モデルが苦手な領域(sub-seasonal waveの検出、レーダー画像からの降水ナウキャストなど)において機械学習を用いることで精度が改善されたことが報告されているようです。
一方、中期予報ではまだまだ数値予報モデルは負けていません。
例えば、CNNやTransformerを用いたモデルがありましたが、1°よりも粗い分解能で”有望な結果”が得られた程度だったようです。
最近では、GNNやFNO(Fourier Neural Operator)、Transformerといったモデルを使用して、7日予報において数値予報モデルに迫る(中には上回った指標もあった)精度が報告された例はあったようですが。
GraphCast
概要
提案手法GraphCastは、「機械学習ベースの予報モデル(MLWP)」に分類される手法です。
計算速度も優れており、GraphCast「Google Cloud TPU v4」1台で、1分以内に10日間予報を出せるようです(HRESはスパコンを数時間ぶん回すそう)。
論文によると、パラメータ数は36.7M(3670万)です。
モデルの入出力
-
入力
- 現在時刻・6時間前の気象状態
-
出力
- 現在から6時間後の気象状態
-
分解能
- 0.25°×0.25°
- 赤道上で28km四方相当
ざっくりとしたモデル構造
- グラフの構造
- ノードは空間的に均質である
- 正二十面体の各面を4分割することを$i$回繰り返した構造を$\text{M}^i$とし、ノードは$\text{M}^6$の頂点の個数(40962)だけあり、エッジは$\text{M}^0$~$\text{M}^6$の分だけある
- この構造を論文ではmulti-meshと呼んでいる
-
Encoder
- グリッド上の変数をGNNに通してグラフノードへmapする
-
Processor
- 16層のGNNレイヤーによりmulti-mesh上で情報伝達を行う
-
Decoder
- ノード上の変数をGNNに通してグリッドへmapする
- 出力値は入力との差分としている
損失関数は、高度による重み付きの二乗和誤差を使っています(下図)。

学習データ
ERA5という大気再解析データを使用しています。
1979年~2017年を学習用データとして用います。
そのうち、1979年~2015年の37年間ぶんはメインの学習用データ(training)として用い、2016~2017年のデータは評価用(開発用)データ(validation, development)として用いられています。
精度評価では、下図のようにTimeSeriesSplitでデータを分割しています(基本的にはGraphCast<2018で評価し、残りは「Effect of training data recency」の章で使う)。

学習にかかった時間など
気になるのは学習コストですが、Google Cloud TPU v4 (32GBメモリ) × 32個を4週間ぶん回したそうです。
学習時には、メモリ削減のために
- バッチ並列
- 通常よりも精度を落としたbfloat16で計算(評価段階ではfloat32で計算)
-
Gradient Checkpointing
- 勾配を計算する際forwardパスの実行結果を保存するが、全部覚えておくのではなく、そのノード以外は捨ててしまう
という工夫を行っていました。
評価方法(Verification methods)
GraphCast、HRES(数値予報モデル)、Pangu-Weather(従来の機械学習モデル)の3つを、
- RMSE(Root Mean Squared Error)
- ACC(Anomaly Correlation Coefficient)
で評価しています。
GraphCastは下表に示す変数227個を出力します。

227個の内訳は、
- 地上変数×5個
- 気温
- 風速の東西成分
- 風速の南北成分
- 平均海面気圧
- 降水量
- 上空の変数6個×高度37個=222個
- 各高度の気温
- 各高度の風速の東西成分
- 各高度の風速の南北成分
- 各高度のジオポテンシャル高度
- 各高度の比湿
- 各高度の鉛直風速
です。高度の取り方はTable1の最右列のとおりです。
しかしこれら全て使って評価はせず、WeatherBenchの高度の取り方に則り、高度は
50, 100, 150, 200, 250, 300, 400, 500, 600, 700, 850, 925, 1000 (hPa)
の13種類を使い、変数はECMWF Scores cardsに則り、総降水量と鉛直風速を除いた変数を使っています(なお、降水量を外したのは学習データであるERA5には降水量についてバイアスが乗っているからだ、と書かれていました)。
さらに、公平な比較のためにいろいろ考慮しているみたいですが、説明は割愛します。
評価結果(Forecast verification results)
結果は下図(論文のFigure 2)のようになりました。
上半分は、500hPa面ジオポテンシャル高度の予測精度を表しています1。
下半分は、各変数(東西風速u、南北風速v、ジオポテンシャル高度z、気温t、比湿q)の各高度、各予報時間における精度(RMSE)を表しています。

(a) Skill (RMSE): z500
RMSEなので、小さいほど精度が良いと言えます。
プロットを見ると、すべての予報時間でGraphCastが上回っています。
(b) Skill score (RMSE): z500
同じRMSEですが、縦軸を見ると「Norm. RMSE diff.」となっています。これは、HRES(数値予報モデル)での誤差を$\text{RMSE}_B$、GraphCastでの誤差を$\text{RMSE}_A$として
\frac{\text{RMSE}_A- \text{RMSE}_B}{\text{RMSE}_B}\tag{1}
で定義した指標です。なので、値が小さいほどGraphCastが勝っていることになります。
(c) Skill score (ACC): z500
ACCはAnomaly Correlation Coefficientの略で、日本語ではアノマリー相関係数と呼ばれます。これは、予報値の平均からの偏差と実況値の平均からの偏差との相関係数です。
0~1の値をとり、1に近いほど精度は良いといえます。
(d) Scorecard (RMSE skill score)
縦軸は高度、横軸が予報時間となっています。
色は、(b)で説明したRMSE skill scoreの値に対応しています。青いほどGraphCast優位、赤いほどHRES優位という意味です。
100~150hPaより下層ではGraphCastの精度がほとんど勝っていますが、それより上層だと赤色が目立ち、HRESの精度が勝っています。
極端現象の予測(Severe event forecasting results)
さらに論文では、GraphCastの出力を使って
- ①熱帯低気圧の進路予測
- ②大気の川の発生予測
- ③異常気温の予測
を行う、という下流タスクにも取り組み、これらの精度がHRESを上回ったことを報告しています。
①熱帯低気圧の進路予測(Tropical cyclone tracks)
数値予報モデルとGraphCastが出力する、
- ジオポテンシャル高度
- 水平風速
- 平均海面気圧
の情報から、ECMWFの公開プロトコルに基づくアルゴリズムを使って熱帯低気圧の進路予測を行っています。
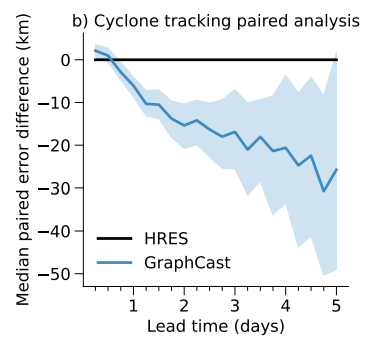
TIGGEという再解析データを真値として、そこからのズレの中央値を集計したところ、下図のような結果になりました。

また、ペア誤差の差(同時点での両モデルの予測誤差の差)をプロットすると下図となっており、予報時間18h~4.75日においてGraphCastがHRESよりも有意に優れていることがわかります。
②大気の川の発生予測(Atmospheric rivers)
大気の川は、豪雨をもたらしうるような水蒸気の大規模な流れです。
大気の川の強さはIVTという指標で特徴づけられ、
- 水平風速
- 比湿
からIVTを計算することができます。
研究では、北米沿岸・東太平洋で頻繁に発生する時期である10月~4月を対象に評価を行いました。その結果が下図です。

(IVTに関して特別に訓練を行ったわけでもないのに)GraphCastがHRESの精度を上回ったことがわかります。
③異常気温の予測(Extreme heat and cold)
ここでは、「50年に1度」級の異常な暑さや寒さの予測精度を比較しています。
異常気温になるかどうかがターゲットであり、精度は下図のようなPR曲線(横軸が再現率、縦軸が適合率)で比較します。
PR曲線は、右上に向かって大きく膨らんでいる(曲線の下の面積が大きい)ほど精度が良い、という見方をします。

予報時間12h、5日、10日の3種類で比較されています。予報時間5日、10日ではGraphCastの方が優れていますが、予報時間12hではHRESの方が優れています。
学習データの新しさは精度に影響するか?(Effect of training data recency)
GraphCastは機械学習ベースなので、定期的に再学習させることが可能です。
新しいデータを取り込むことで、気候変動など時間とともに変化する気象パターンを捉えることができるでしょう。
研究では、学習データとして
- 1979年~2017年
- 1979年~2018年
- 1979年~2019年
- 1979年~2020年
を用いた場合の精度を比較しています(テストデータは2021年のデータ)。
その結果が下図です。「1979年~2017年」で学習したモデルの誤差をベースとして、その他のモデルの誤差がベースとどれくらい差があるのかを示しています(式は先述の$(1)$を参照)。

「~2017年」の学習データの場合でもHRESと比べて遜色ない性能でしたが、データを追加することでさらなる精度向上が見られました。
(当たり前っちゃ当たり前のような気がしますが…。)
終わりに
以上が、GraphCast論文の概要部分の解説でした!
2023年11月版の論文は全102ページにもわたり、もっと細かいことがたくさん書かれています。
次回は、GNNのモデル構造についてもっと踏み込んで解説していきたいと思います!
※もし記事に間違い等ありましたらコメントでご指摘ください!
-
arXiv掲載の論文の補足パートには、他変数の精度プロットが掲載されています。 ↩