概要
シリーズ「気象データで時系列解析」では、気象データを例に時系列解析の基礎を学びます。今回は、自己回帰和分移動平均(ARIMA)モデルについて扱います。
ARIMAモデル
ARIMA(AutoRegressive Integrated Moving Average)モデルは、ARMAモデルを差分系列に適用したものです。
まずは、ARモデルとMAモデルの復習です。
$p$次のARモデルは、過去の値$x_{t-1},\cdots,x_{t-p}$からの線形回帰でした。
x_t = c + \sum_{i=1}^{p} \phi_ix_{t-i} + \epsilon_t
詳しくは、以前書いたこちらの記事をご覧ください。
$q$次のMAモデルは、過去のショック$\epsilon_{t−1},\cdots,\epsilon{t−q}$からの線形回帰でした。
x_t = c + \sum_{j=1}^{q} \theta_j\epsilon_{t-j} + \epsilon_t
そして、$p$次ARモデルと$q$次MAモデルを組み合わせのが$(p,q)$次のARMAモデルでした。
x_t = c + \sum_{i=1}^{p} \phi_ix_{t-i} + \sum_{j=1}^{q} \theta_j\epsilon_{t-j} + \epsilon_t
詳しくは、以前書いたこちらの記事をご覧ください。
このARMAモデルを差分系列に対して適用したのがARIMAモデルということになります。
つまり、$(p,d,q)$次のARIMAモデルは
\begin{align}
x_t &= c + \sum_{i=1}^{p} \phi_i y_{t-i} + \sum_{j=1}^{q} \theta_j\epsilon_{t-j} + \epsilon_t\\
y_t &= x_{t} - x_{t-d}
\end{align}
と表せます。
差分系列を考えることで、非定常過程も扱うことができるようになるため、ARIMAは時系列解析手法としてよく使われるようです。
気温をARIMAで予測してみる
このARIMAモデルを使って、将来の気温予測に挑戦してみます。
- データ元
- 気象庁「過去の気象データダウンロード」
- 京都市の時別値気温データを取得
モデルの構築
statsmodelsライブラリを利用します。
from statsmodels.tsa.arima.model import ARIMA
# statsmodels: 0.14.0
model = ARIMA(df['temp'], order=(24, 1, 1)) # AR次数, I次数, MA次数
次数を指定する引数orderには、ARIMAモデルの次数$(p,d,q)$を入れます。
今回は、$(p,d,q)=(24,1,1)$としました。
パラメータ推定は.fit()で簡単にできます。
結果は.summary()で見ることができます。
result = model.fit()
print(result.summary())
result.summary()の結果がこちら。
SARIMAX Results
==============================================================================
Dep. Variable: temp No. Observations: 26304
Model: ARIMA(24, 1, 1) Log Likelihood -25725.486
Date: Sat, 23 Dec 2023 AIC 51502.973
Time: 18:11:36 BIC 51715.586
Sample: 01-01-2020 HQIC 51571.622
- 01-01-2023
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.4702 0.033 14.413 0.000 0.406 0.534
ar.L2 0.0529 0.010 5.520 0.000 0.034 0.072
ar.L3 -0.0419 0.006 -6.543 0.000 -0.054 -0.029
ar.L4 -0.0427 0.006 -7.263 0.000 -0.054 -0.031
ar.L5 -0.0401 0.006 -6.640 0.000 -0.052 -0.028
ar.L6 -0.0612 0.007 -8.979 0.000 -0.075 -0.048
ar.L7 -0.0514 0.007 -6.941 0.000 -0.066 -0.037
ar.L8 -0.0552 0.008 -7.012 0.000 -0.071 -0.040
ar.L9 -0.0475 0.009 -5.575 0.000 -0.064 -0.031
ar.L10 -0.0203 0.009 -2.278 0.023 -0.038 -0.003
ar.L11 -0.0187 0.009 -2.123 0.034 -0.036 -0.001
ar.L12 -0.0294 0.009 -3.300 0.001 -0.047 -0.012
ar.L13 -0.0293 0.009 -3.379 0.001 -0.046 -0.012
ar.L14 -0.0452 0.008 -5.353 0.000 -0.062 -0.029
ar.L15 -0.0549 0.008 -6.663 0.000 -0.071 -0.039
ar.L16 -0.0544 0.008 -6.705 0.000 -0.070 -0.038
ar.L17 -0.0386 0.008 -5.042 0.000 -0.054 -0.024
ar.L18 -0.0218 0.007 -3.114 0.002 -0.036 -0.008
ar.L19 -0.0262 0.006 -4.135 0.000 -0.039 -0.014
ar.L20 -0.0205 0.006 -3.505 0.000 -0.032 -0.009
ar.L21 0.0154 0.006 2.738 0.006 0.004 0.026
ar.L22 0.0382 0.005 7.625 0.000 0.028 0.048
ar.L23 0.0936 0.006 16.692 0.000 0.083 0.105
ar.L24 0.1014 0.006 15.634 0.000 0.089 0.114
ma.L1 -0.2226 0.033 -6.800 0.000 -0.287 -0.158
sigma2 0.4140 0.002 240.571 0.000 0.411 0.417
===================================================================================
Ljung-Box (L1) (Q): 0.02 Jarque-Bera (JB): 78995.45
Prob(Q): 0.88 Prob(JB): 0.00
Heteroskedasticity (H): 1.04 Skew: -0.56
Prob(H) (two-sided): 0.06 Kurtosis: 11.42
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
ARIMAモデルの次数$(p,d,q)$はいろいろ考えられますが、これはAIC(赤池情報量基準) や BIC(ベイズ情報量基準) などの指標をもとに最適な次数を決定します。
AICは、尤度$L$と自由パラメータ数$k$を用いて次で定義されます。
\mathrm{AIC} = -2\ln L+2k
BICは、尤度$L$と自由パラメータ数$k$、データ数$n$を用いて次で定義されます。
\mathrm{BIC} = -2 \ln L + k\ln n
両者とも尤度$L$が大きいほど小さい値となるので、モデルのあてはまりが良いほどAICやBICの値は小さく出ます。
しかし、モデルパラメータ数やデータ数を大きくすればするほどあてはまりが良くなるのは当然なので、その影響を罰則項$2k$や$k\ln n$を使っておさえています。
ちなみに、HQIC(Hannnan-Quinn情報量基準)というAICやBICの改良版もあるそうで、
\mathrm{HQIC} = -2L + 2k\ln(\ln n)
と定義されます(Wikipedia)。
これらの指標AIC、BIC、HQIC、および対数尤度はsummary()で確認することができます。
予測
パラメータ推定では、2020年~2022年のデータを用いました。
.forecast(step)を使うと、データの続きをstepの分だけ予測することができます。
例えば、2023年1月1日01:00~2日00:00の予測値が欲しいときは次のように書きます。
forecast = result.forecast(steps=24)
実際の値も合わせてプロットすると、下記のようになりました。
(青=ARIMAによる1月1日の予測値、緑=1月1日の観測値、橙=12月31日の観測値)
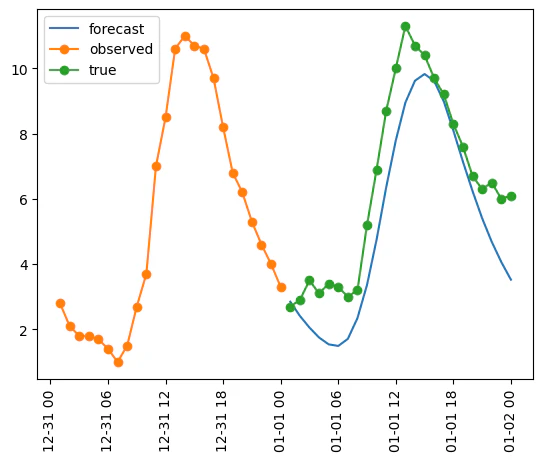
それなりに傾向はつかめているようです。
では、1か月先を予測させるとどうなるでしょうか。

あらら、どんどん減衰していってしまいました。
先ほどの1日先予測を行ったグラフを見ると、ARIMAの予測は前日の最高気温よりも数度低く、最低気温は若干高くなるようになっています。これが1か月分繰り返されるとどんどん振幅が小さくなっていくので、上図のような結果になってしまったようです。
次回の記事では、季節性(周期性)を考慮したSARIMAモデルについて解説し、この問題を解消していきたいと思います。
ソースコード
Qiitaアドベントカレンダーで使ったコードはこちらのレポジトリにまとめています。
本記事のコードは01-JMA_data_analyticsの中に入っています。