はじめに
LLMにも採用されている類似検索の手法としてコサイン類似度があるが、
この記事では、改めてコサイン類似度、ベクトル検索の仕組みの概要を簡単に理解する。
1️ 類似検索の主な手法とその使いどころ
| 手法名 | 特徴・説明 | よく使われるユースケース |
|---|---|---|
| コサイン類似度 | ベクトル間の角度(方向の類似)を比較 | 質問応答AI、類似文検索、画像検索 |
| ユークリッド距離 | ベクトル間の直線距離。差分の大きさに敏感 | 数値分類、画像特徴比較 |
| マンハッタン距離 | 各次元の差の総和。L1ノルム | 顧客行動分析、異常検出 |
| ジャッカード係数 | 集合の共通度。バイナリデータ向け | タグ比較、バスケット分析 |
| ピアソン相関係数 | 値の傾向(相関)を測る | レコメンド、傾向比較 |
| ハミング距離 | 同長の文字列差(異なるビット数) | 誤り検出、バイナリ一致 |
| マハラノビス距離 | 分散・相関を考慮した距離 | 外れ値検出、高次元クラスタリング |
| DTW | 時系列のズレに対応する類似度 | 音声認識、歩行パターン比較 |
2 ベクトル検索とは何か?改めて整理
類似検索の大きく分けて2つのアプローチがある
| 分類 | 概要 | 主な手法例 |
|---|---|---|
| キーワードベースの類似検索 | 単語の一致や出現頻度に基づいて近さを測る | 一般的な全文検索 |
| 意味ベースの類似検索(ベクトル検索) | 文や画像の意味を数値ベクトルに変換し、ベクトル間の距離で比較 | Embedding + 類似度指標(コサインなど) |
ベクトル検索において、最近はLLMやEmbeddingの進化によって精度・実用性がかなり上がってきている。
キーワード検索(全文検索)との違い
| 特徴 | 従来の全文検索 | ベクトル検索 |
|---|---|---|
| 検索方法 | キーワード一致 | 意味ベクトルの類似度 |
| データ表現 | 単語インデックス | 多次元ベクトル |
| 類似度評価 | TF-IDF、BM25など | コサイン類似度、ユークリッド距離 |
| 強み | 精度の高い一致判定 | 曖昧な言い換え・文脈検索 |
Embeddingってなに?
テキストや画像などを意味を保持した多次元ベクトルに変換する手法。
例
「焼肉を食べたいな」 → ベクトルに変換 [0.17, 0.03, ..., 0.44]
「お肉食べに行きたいよ」 → ベクトルに変換 [0.18, 0.04, ..., 0.45]
上のような文章は意味が似てる → 意味が近い文は、ベクトル空間上でも近い位置に配置される。
3️ 類似度はどう測るのか→ コサイン類似度
定義と数式
この2つのベクトルのコサイン類似度、すなわち「この2つのベクトルがなす角θのコサイン値」(cosθ、cos(a,b))を求める数式は、(高校で学ぶ)「2つのベクトル同士の内積の公式」から導き出せる。以下の1行目がその公式である。なお、|<ベクトル>|という数学記号は、「ベクトルの大きさ」を表す。
$$
\cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{|\vec{A}| \cdot |\vec{B}|}
$$
例えば2つの2次元のベクトル同士の計算をすると、
a = [3, 4]
b = [2, 5]
内積 = a・b = 3×2 + 4×5 = 6 + 20 = 26
ベクトルの大きさ=
||a|| = √(3² + 4²) = √(9 + 16) = √25 = 5
||b|| = √(2² + 5²) = √(4 + 25) = √29 ≒ 5.385
cos(Θ) = 26 / (5 × 5.385) ≒ 26 / 26.925 ≒ 0.9656
コサイン類似度 ≒ 0.9656 みたいな感じ
- ベクトルの向きの類似度に注目
- 値は
-1 ~ 1の範囲(自然言語では通常 0 以上)
コサイン類似度の直感的なイメージ
コサイン類似度のイメージ
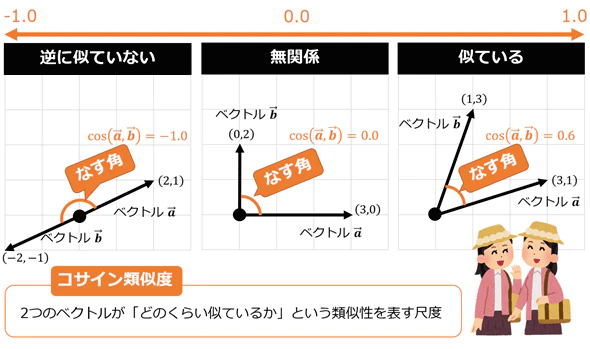
- 逆方向:-1
- 直角:0
- 同方向:1→(1に近かければ近いほど似てる)
例
以下の例は4次元ベクトルを使ってコサイン類似度を計算する例。実際のEmbedding(多次元ベクトル)のごく簡略化版として、どのベクトルが似ているかを確認してみる
import numpy as np
#コサイン類似度の公式
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
vecs = {
'A': np.array([1, 2, 0, 1]),
'B': np.array([2, 4, 0, 1]),
'C': np.array([-1, -2, 0, -1]),
'D': np.array([1, 2, 0, 1])
}
for k1 in vecs:
for k2 in vecs:
if k1 < k2:
sim = cosine_similarity(vecs[k1], vecs[k2])
print(f"{k1} と {k2} → 類似度: {sim:.4f}")
出力:
A と B → 類似度: 0.9806 # かなり1に近い → 似てる
A と C → 類似度: -0.9806 # 真逆の方向 → 全く似てない
A と D → 類似度: 1.0000 # 完全一致 → 同じもの
・・・
こんな感じで、方向が近ければ(類似していれば)1に近づく(類似してる)が、完全一致でなければ1未満になる。
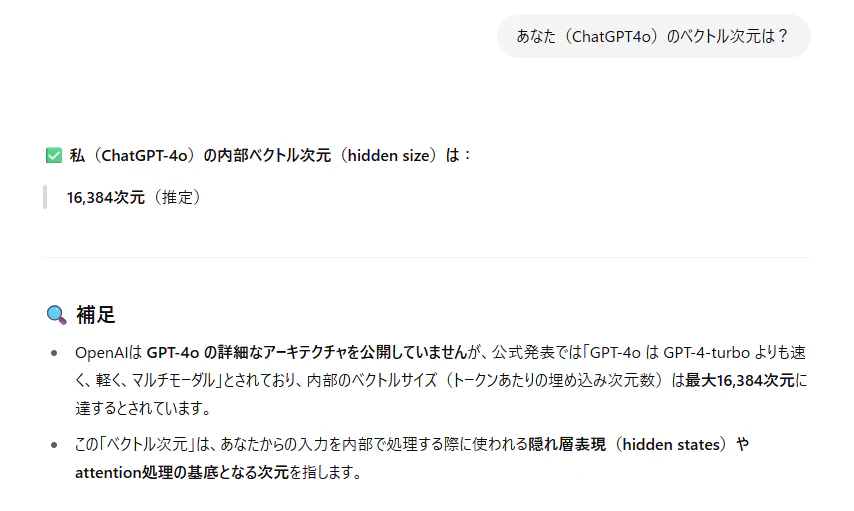
この例はたった4次元のベクトルだけど、ChatGPTとかは16384次元(推定)のベクトルと本人は言っていました。すごいですね。もうそんな次元まで行ってるんですね。
いわゆるRAG(Retrieval-Augmented Generation) はベクトル同士にコサイン類似度をかけて、どれだけ意味的に似ているかを判定して返すイメージ。