マイクロサービスアーキテクチャーを実現するKubernetesについて参考にさせていただいた「Kubernetes完全ガイド」という本と公式ドキュメントをざっと追いながらまとめてみました。みなさんの参考になればぜひ。
Kubernetesの基本
Kuberentesは、コンテナ化アプリケーションの展開、スケーリング、および管理を自動化するオーケストレーションツールです。端的に理解するならコンテナに割り当てるリソース管理(ボリューム, IP, アクセスポリシーなど)を行うものということになります。大別すると以下のような役割があり、Kubernetesで定義される各種リソースがその役割を担います。
- 複数サーバーでのコンテナ管理(Workloadsリソース)
- コンテナ間のネットワーク管理、負荷分散(Services,LB&Networkリソース)
- コンテナに割り当てるストレージの管理(Storageリソース)
- コンテナリソースへのアクセス設定(Configurationリソース)
- コンテナ、ノードの監視(Securityリソース)
Kubernetesにおけるアプリケーション展開の流れ
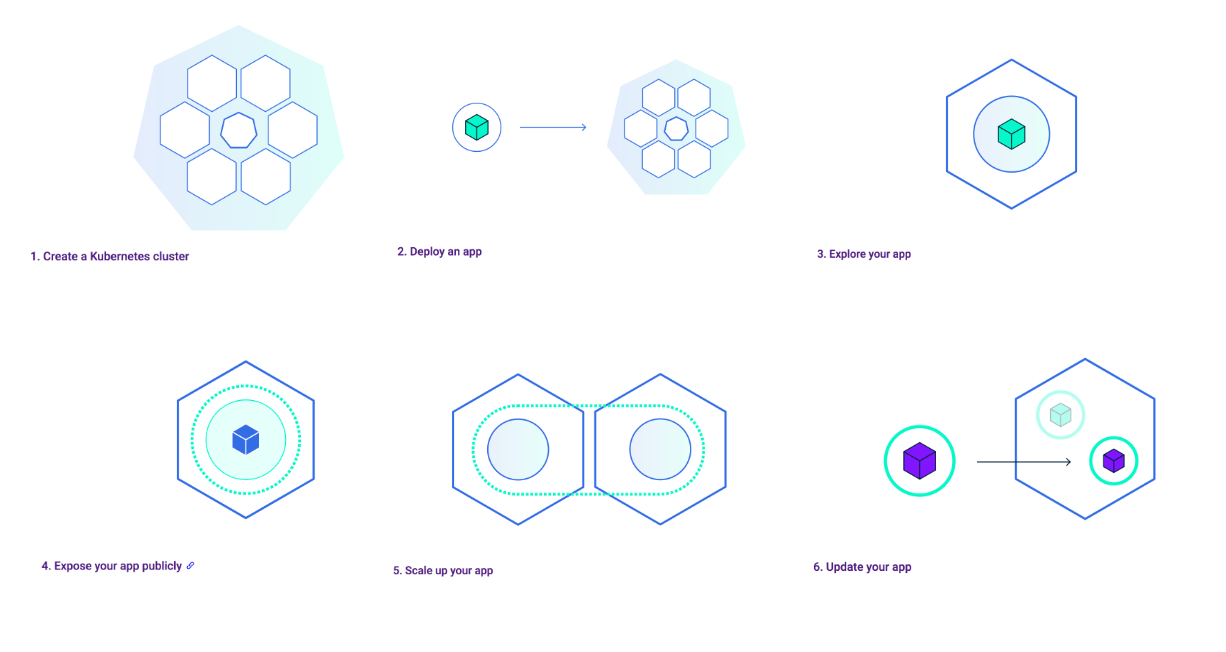
絵だといまいちピンとこないので、以下流れの説明です。
1、Kubernetesクラスタの作成
コンテナといえど、実際に動いているのはVMインスタンスまたは物理マシン上です。クラスタ作成とは、インスタンス1台(冗長も加味するなら2台以上)をKubernetesを管理するマスターノードに割り当て、それ以外の複数台インスタンスをワーカーノードとしてコンテナデプロイし放題のプールを作成するイメージです。
2、アプリのデプロイ
ここではコンテナを利用して設計したアプリケーションにあたります。
3、Podの生成
Kubernetesにおいての最小単位(=原始単位)はPodです。これは「コンテナ+コンテナに割り当てる共有ストレージ(ボリューム)やIPアドレスを定義したもの」になります。Kubernetesにおいてノードリソース状況を判断して自動でPodを配置を行います。そして、Podは配置されたノードに紐付き、ノードで障害が起きた場合は、使用可能なノードに配置されます。(セルフヒーリング機能=?コンテナのVMotion)
コンテナはPodでリソースを身にまとい、Kubernetes環境に身を置くことで耐障害性・拡張性が増します。
4、アプリを公開する
基本的にKubeMasterではマニュフェストファイル(yaml)と言われるものをコマンドで適用します。
$ kubectl apply -f sample.yml
リソースのアップデートや削除はマニュフェストファイルを変更して適用することが推奨されています。
「現在のリソース状態」- 「適用するマニフェスト」の差分を計算してリソース変更を行います。
$ kubectl get pods
$ kubectl delete -f sample.yml
yamlファイルの定義など詳しくは、後半のリソースまとめを参照にしてください。例として、たとえばコンテナに何らかの障害が発生して停止した場合、Replica Setというリソースを定義しておけば、自動的にPodを複製して起動することが可能です。また、PodごとにラベルをつけてPodをグループ化して管理するなども可能です。
5、アプリのスケーリング
Podを空きリソースのあるノードに展開することができます。(縮小することも可能である)これにより、アプリの負荷分散が実現可能です。
6、アプリのアップデート
アプリのアップデートではスケーリング(複数のノードを動かしていること)は最低条件になります。
そうすることでPodsを段階的にアップデートして、ダウンタイムをゼロにすることも可能です。( = ローリングアップデート)
Kubernetesを支える要素とその定義
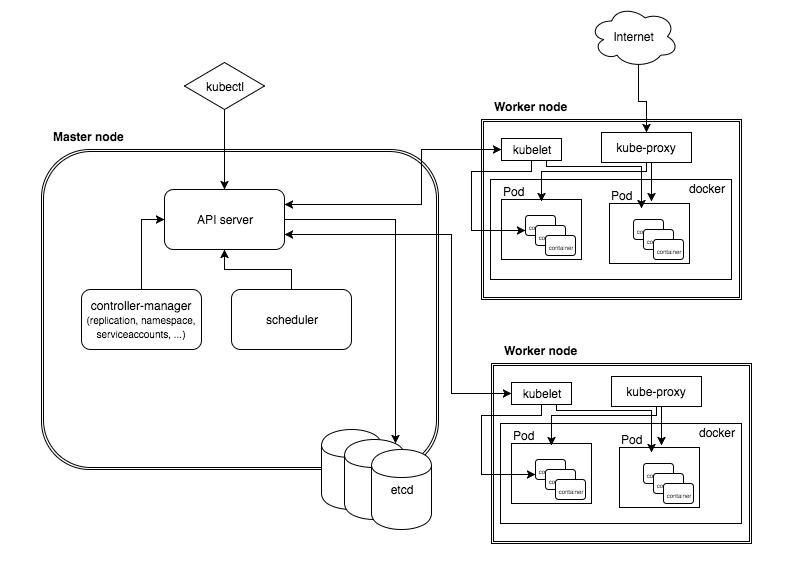
内部的には絵をじっくり見てみると概要がつかめるかと思います。それぞれの構成要素については以下解説です。
kubectl
開発者がkubernetes MasterのAPIを直接叩かずに、操作するためのコマンドラインツール。
scheduler
どのノードで起動するか決まっていないPodを検知して、Podが起動するノードを割り当てる。
controller-manager
各種コントローラー。たとえば、DeploymentやReplicasetの状態を監視しながら、必要に応じてReplicaSetやPodを作成する。
etcd
Kubernetesクラスタ情報を永続化して格納するためのKVS。
kubelet
WokerNode上で動作し、コンテナ(Docker)の起動、停止の管理を行う。
kube-proxy
WorkerNode上で動作し、Pod宛のトラフィックを正しく転送することでPod間の疎通を確保する。
参考:ノード間におけるコンテナ通信について
Kubernetesを使ってコンテナをデプロイする際、基本的にホストを指定してデプロイすることができません。(コンテナがその時のリソース状況に応じてホストを決定するため) つまり、デプロイされるまでコンテナのIPアドレスがわかりません。Kubernetesではどのホストにコンテナがデプロイされてもコンテナへ自由にアクセスできる仕組みとしてServiceがあります。
環境構築ツール
Kubernetesを実際に運用する際のポイントについては、引用させていただいた本の著者のブログにもあるように、アプリケーション視点が重要で基本的に自前でオンプレ構築というよりはマネージドサービスを使って構築・管理するほうが効率的かと思います。
minikube(←ローカル環境向け)
Kubernetesをローカルで容易に実行してくれるツールです。
単純なクラスタをデプロイする軽量のKubernetesが実装されています。動作について確認されたい場合は勉強になります。
パブリッククラウドサービス
大規模環境構築をしたわけでもありませんが、インフラ周りはダッシュボードありきでリソース状況が可視化できるものがおすすめです。Kubernetesを使ったコンテナ運用サービスでリードしているのはGCPかと思いますが、AWS, Azureも対応は進めるでしょう。
補足:クラウドコントローラーマネージャ(CCM)により、クラウドプロバイダがKubernetesと統合できるようにしています。
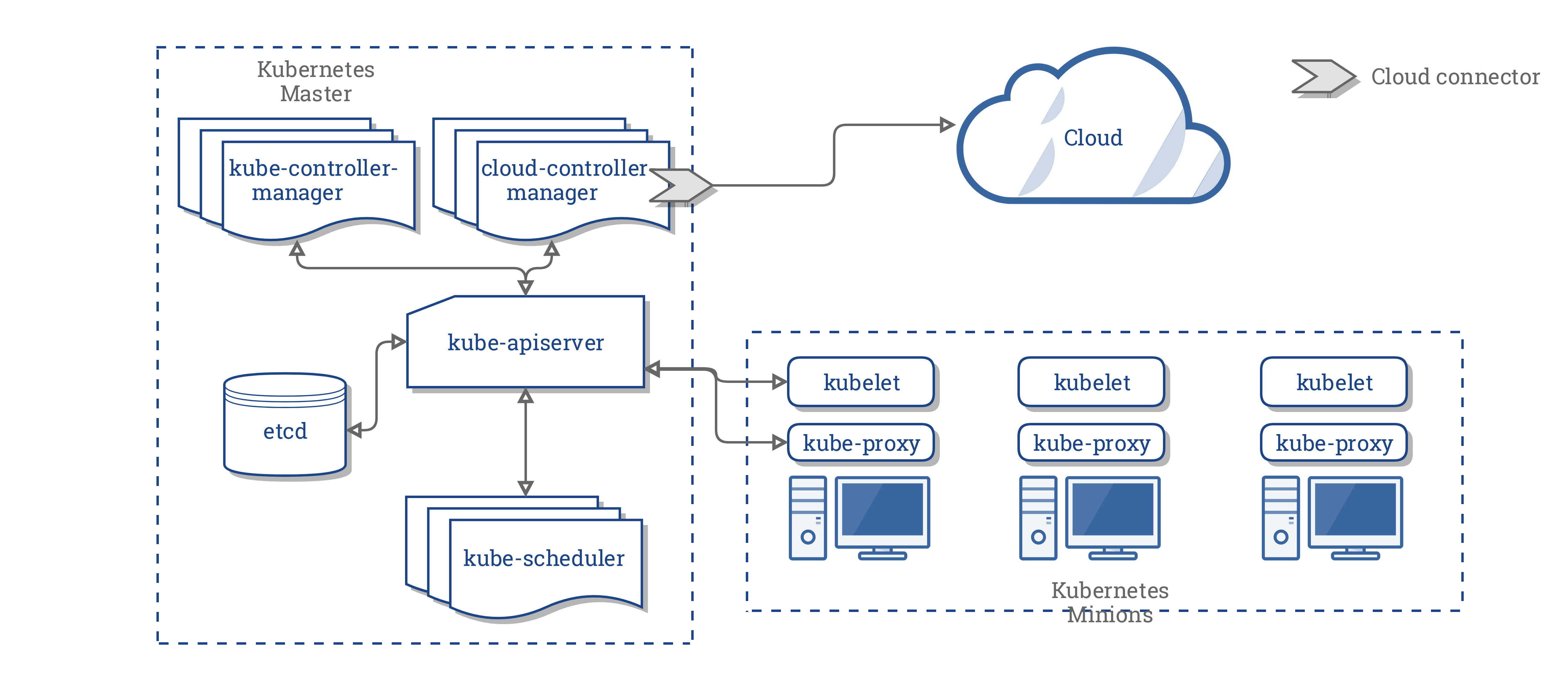
Rancher
Rancher Serverが中央集権的にKubernetesクラスターを管理できます。メリットとしてダッシュボードによって管理できたり、異なるクラウドプロバイダーのプラットフォームを管理できたりすることが挙げられます。
Kubernetesリソースまとめ
リソースについては公式を見るのが早いでしょう。開発スピードもあるので、大幅に変わってるかもしれませんが、一応自分用のメモなので、雰囲気をつかみたい方はざっと目を通してみてください。
リソースの種類
- 👉Workloadsリソース
- 👉Services, LB&Networkリソース
- 👉Storageリソース
- 👉Configuration, Securityリソース
👉Work Loadsリソース
以下で説明しているリソース上位関係は以下の通り。
- Pod << ReplicaSet << Deployment
- Pod << DaemonSet
- Pod << StatefulSet
- Pod << Job << CronJob
Pod
1Pod内に1コンテナが基本だが、異なるPortを指定することで2コンテナ以上含めることも可能。1Podに1つのIPアドレスが割り当てられる。
ReplicaSet
複数のPodを並行して作成する。 指定した数のPod数を常に維持する。また、Pod数が指定数を超過した場合、Podを削除する。そのときにPodのラベリングをもとにPod数を調整する。
セルフヒーリング機能...ノードやPodに障害が発生した場合も別ノードでPodを自動的に起動してくれる。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: sample
spec:
replicas: 3
selector:
matchLabels:
tier: web-proxy
template:
metadata:
labels:
tier: web-proxy
spec:
containers:
-name: nginx-container
image: nginx:1.79
ports:
- containerPort: 80
Deployment
複数のReplicaSetを管理し、ローリングアップデート(Podの稼動状態を維持しながら、順番にPodをアップデートする仕組み)やロールバックを実行するためのリソース。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
DaemonSet
ReplicaSetはPod配置を自動調整するのに対して、DaemonSetは各ノードに1Podを原則として配置(ただし、配置したくないノードを設定することも可能)
StatefulSet
ReplicaSetと異なり、sample-statefulset-1, sample-statefulset-2... sample-statefulset-Nというようにインデックスが付与され、データを永続化させる ( PersistentVolumeClaimで永続化領域を確保する。)
データベースなどに対応するためのリソース。
Job
1つ以上のPodを利用して一度限りの処理(バッチ処理)を実行させるリソース。
specで以下のパラメーターを設定可能
- Completions...目標成功回数(回数分成功したらジョブを終了)
- Parallelism...並列度
- backoffLimit...許容失敗数
CroneJob
Jobのスケジュールを管理するリソース 。
CroneJobのポリシーについては以下を参照
- Allow...Jobの同時実行に対して制限を行わない
- Forbid...前のJobが終了してない場合は次のJobは実行しない
- Replace...前のJobが終了してない場合はキャンセルして次のJobを実行する
👉Services,LB&Networkリソース
Kubernetes環境では内部ネットワークが設定されるため、Pod間通信は基本的にクラスタ構築時点で可能。
=> ただServiceを利用すれば、Podのトラフィックのロードバランシングや公開するPod群(サービス)に名前を定義して、IPアドレスやPortの情報を提供することができる。
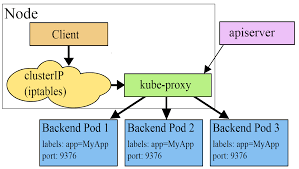
Cluster IP Service
内部ネットワークに仮想IPを割り当て、Podへの通信をロードバランシングしながら転送する役割を持つ。
apiVersion: v1
kind: Service
metadata:
name: sample-clusterip
spec:
type: ClusterIP
ports:
-name: "http-port"
protocol: "TCP"
port: 8080
targetPort: 80
selector:
app: sample-app
External IP Service
指定したノードのIPアドレスとPortで受信→ClusterIPに転送→各Podに転送するように設定する。
(マニュフェストファイルのタイプはClusterIPと同じ)
NodePort Service
全てのKubernetesノードのIPアドレスとPortで受信(利用できるポート範囲はデフォルトだと30000~32767)→ClusterIPに転送→各Podに転送するように設定する。
LoadBalancer Service
Cluster IP ServiceがPodへの通信をロードバランシングするのに対してLoadBalancer Serviceはノードへの通信をロードバランシングする。(ノード障害に強い)
apiVersion: v1
kind: Service
metadata:
name: sample-lb
spec:
type: LoadBalancer
ports:
-name: "http-port"
protocol: "TCP"
#LBが払い出す仮想IPとClusterIPで受信するport
port: 8080
#転送先のコンテナのport
targetPort: 80
#kubernetes上の全ノードのIPアドレスで受信するport
nodePort: 30082
selector:
app: sample-app
Headless Service
通常クラスタ内DNSでPod名の名前解決は行われない。
DNS Round Robinを使ってService名からPodのIPアドレスを割り当てるリソース。(Cluster単位のIPアドレスではなく、Pod単位のIPアドレスで考える)
・DNS Round Robin…1つのドメイン名に複数のIPアドレスを割り当てる負荷分散技術
【前提条件】
- Serviceのspec.typeがClusterIPであること
- Serviceのspec.clusterIPがNoneであること
- Serviceのmetada.nameがStatefulSetのspec.serviceNameと同じであること
ExternalName Service
Service名の名前解決に対してCNAME(外部のドメイン宛)を返すリソース。
None-Selector Service
Service名で名前解決すると自分で指定したホストに対してロードバランシングを行うリソース。
Ingress
ServiceがL4ロードバランシングを提供するのに対して、L7ロードバランシング(HTTPS終端)を提供する特殊なリソース。
HTTPS負荷分散を実現できるため、トラフィックの多い通信処理を捌くのに向いている予感。
-
クラスタ外のロードバランサーを利用したIngress
クライアント => L7ロードバランサー(NodePort経由) => 転送先のPod -
クラスタ内にIngress用のPodをデプロイするIngress
クライアント => L4ロードバランサー => Nginx Pod => 転送先のPod
👉Storageリソース
まずVolume, PersistentVolume, PersistentVolumeClaimの違いについては以下の通り。
- Volume...ホスト領域に用意されている利用可能なボリューム(基本的にはファイルシステムと考えてよい)
- PersistentVolume...外部の永続ボリュームを提供するシステムと連携して、新規のボリューム作成や既存のボリューム削除を行うことができる。
- PersistentVolumeClaim...PersistentVolumeはクラスタにボリュームを登録するためのリソース。このリソースによって、PersistentVolumeを操作することが可能。
Volume
ディレクトリAWS EBS, Azure Disk, emptyDir, hostPathなど様々なボリュームタイプをサポート。サポートされているボリュームによってその特性も変化する。詳しくは公式を参考。ちなみにemptyDirとhostPathの違いは以下の通り。
- emptyDirはホストノード上のコンテナ用の一時領域をコンテナ上の領域にマッピングする(すぐ消える)
- hostPathはホストノード上の領域にマッピングできるが、セキュリティ上注意は必要
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
PersistentVolume(PV)
基本的にネットワーク経由でアタッチされるディスク領域と考えてよい。(もちろんKubernetesクラスタ内のリソース領域)
PersistentVolumeClaim(PVC)によって要求され、プロビジョニングされる。流れとしては、PVCにバインドされたPVが最終的にPodにマウントされます。PVCのyamlファイルのselectorに一致するPVだけがバインドされます。
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
VolumeSnapshotContent
クラスタ内のボリュームからスナップショットを作成するリソース。VolumeSnapshotというユーザー要求から作成される。
👉Configuration, Securityリソース
Secret
ユーザー名やパスワードなどの機密情報を保持するリソース。環境変数として参照させることが可能。Dockerイメージやマニュフェストファイルで記述せず、一括管理可能。(※Configmapとは異なり、機密情報を扱うためにメモリ上の一時的なファイルシステムにデータが保持される仕組みになっている。)以下Secretの種類。
GenericタイプのSecret
kubectlコマンドやマニュフェストファイルからの作成が可能。
apiVersion: v1
kind: Secret
metadata:
name: sample-db-auth
type: Opaque
data:
username: cm 9 vdA == # root
password: cm 9 vdHBhc 3 N 3 b 3 Jk # rootpassword
TLSタイプのSecret
秘密鍵と証明書のファイルから作成する。
$ kubectl create secret tls --save-config tls-sample --key ~/tls.key --cert ~/tls.crt
DockerレジストリタイプのSecret
プライベートレポジトリ用のDockerイメージの取得時に必要な認証用。
$ kubectl create secret --save-config docker-registry sample-registry-auth
\ --docker-server = REGISTRY_ SERVER
\ --docker-username = REGISTRY_ USER
\ --docker-password = REGISTRY_ USER_ PASSWORD
\ --docker-email = REGISTRY_ USER_ EMAIL
Secretの利用方法
1. 環境変数を渡す
spec.containers[].envのvalueFrom.secretKeyRef使って指定する
2. Volumeとしてkeyのみ、Secret全体をマウントする
keyのみの場合は、Spec.volumes[]のsecret.items[]を指定。
Secret全体の場合は、Spec.volumes[]のsecret.secretName[]を指定。
→Volumeにマウントしておくと、定期的にkube-apiserverに変更を確認し、更新してくれる
kubesec について
Secretリソースを暗号化して安全に管理するためのオープンソースソフトウェア 。Google Cloud KMS, AWS KMSの暗号鍵と並行して利用することが可能。
Configmap
単純なKey-Value値や設定ファイルを管理するリソース。
リソース作成方法や利用法はGenericタイプのSecretとほぼ同じ。よって省略。
リソース内容についてあまり綺麗にまとまってなくてすいません。もっと他に綺麗にまとまっている記事があるはず...
マイクロサービス指向の流れでKubernetesにも注目が集まっているのに乗っかって基本的な部分やリソースを含めまとめてみました。最近知ったこととして、コンテナを利用してマイクロサービス化を進めても、最終的には実装するアプリケーションはそのコンテナサービスを組み合わせ、統合することで処理を実装するので、そういったサービス分割後の統合する技術も重要なのだということです。特にコンテナ間通信の高速化・安定性・スリム化については、悩みのタネで様々な解決手法が提示されているようです。gRPCなどもその一翼を担う技術かと思います。開発でもdocker-compose upに慣れてきたので、コンテナ本番運用に関する知見を増やしていこうと思います。