この記事の対象者
- DataRobot実行環境がある方(アカウントを作成済みの方)
- pythonについてある程度の知識がある方(中級者以上)
- DataRobotをpythonAPIで実装したい方
はじめに
本記事はDataRobotというAutoMLツールをpythonのAPIを使用して、モデルの学習~デプロイ/予測実行までを行う方法を解説します。
本記事ではGUIの画面は最初のみ触れ、以降はpython APIのみでデプロイまでを実装します。
DataRobotとは
DataRobot社は人工知能(AI)に対するユニークなコラボレーション型のアプローチであるバリュー・ドリブン AIのリーダーです。
DataRobot社はDataRobotというツールを提供しており、以降の「DataRobot」はツールを指すこととします。
DataRobotは自動機械学習(AutoML)プラットフォームであり、機械学習モデルの構築、トレーニング、評価、デプロイメントを自動化することができます。複雑なデータ分析を迅速かつ簡単に実行し、優れた予測モデルの作成をサポートすることが可能です。
基本はWEb上でのGUI操作で完結できますが、python APIを使うことで一連の操作をコード化できるようになり、以下のようなメリットを得られます。
- 数クリック必要な学習・推論プロセスを1つのプログラムの実行だけで実現できる
- pythonで複雑なデータ処理をして、そのまま学習プロセスに移行できる
- 定期的なプログラム実行するようにすれば、自動でDataRobotを運用できるようになる
DataRobotホームページ
DataRobot pythonAPI Documentation
DataRobot PythonAPI実装
前提
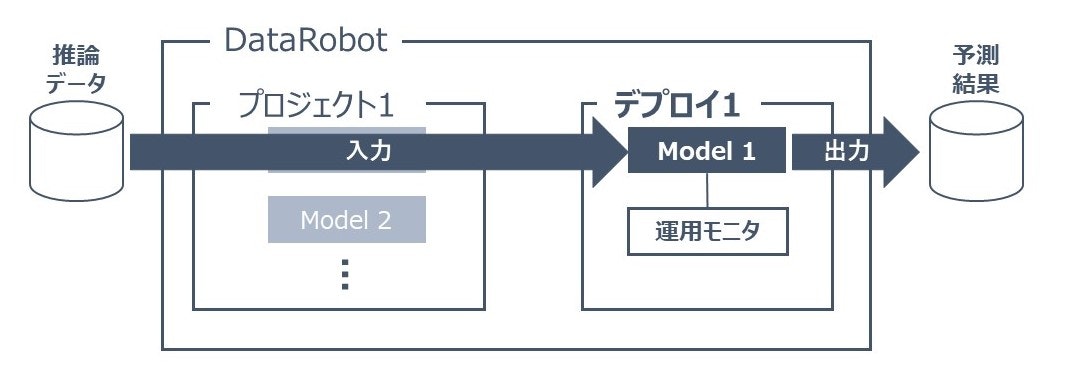
DataRobotイメージ
実装を始める前にDataRobotではどのような構成がなされているかを以下のイメージ図で紹介します。
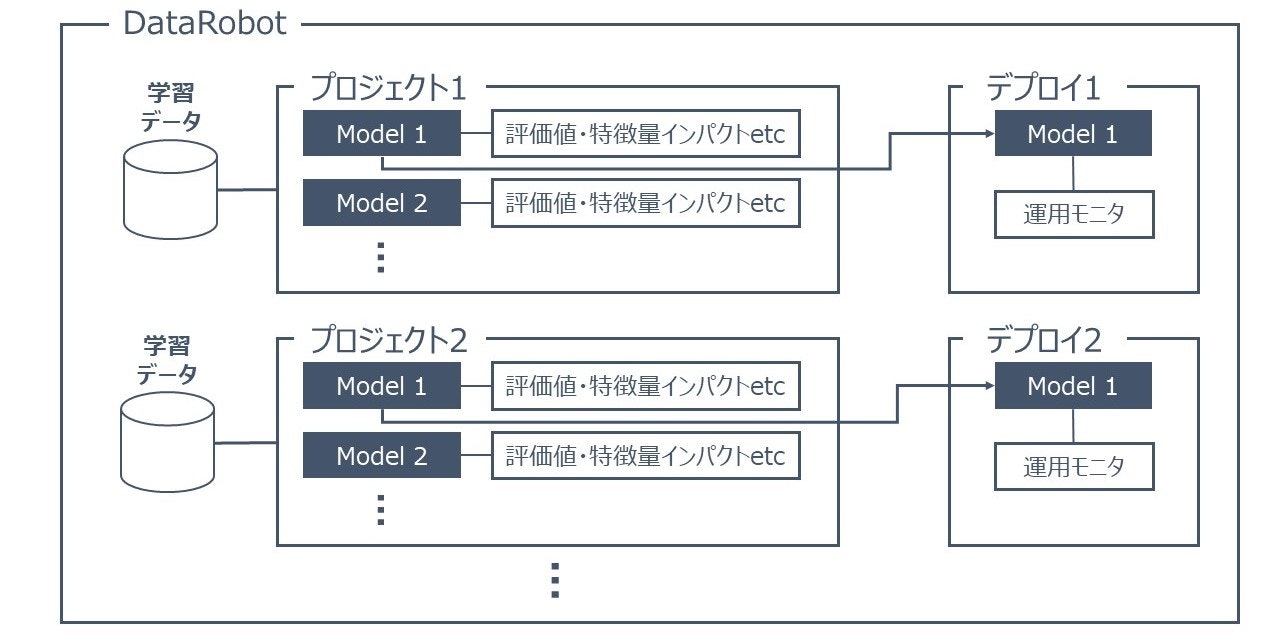
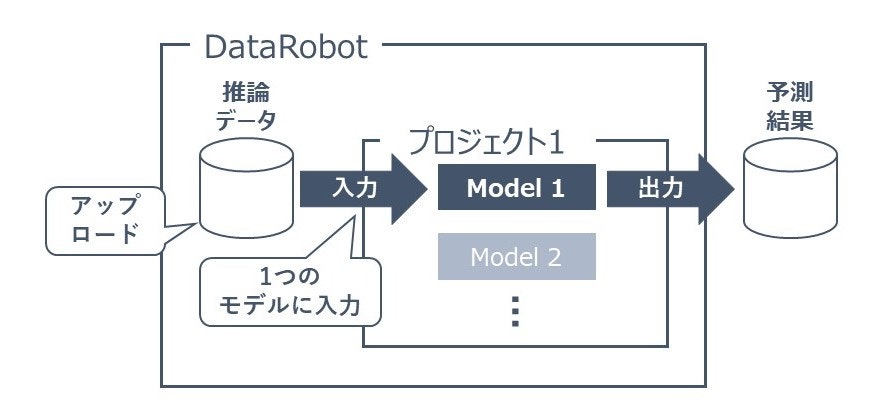
DataRobotでは「プロジェクト」という単位で1つの分析を行います。
そのプロジェクト内で学習を行うことで複数の「モデル」が生成され、モデル毎の評価結果や特徴量のインパクトが作成されます。
この1プロジェクト内の複数のモデルから、1つのモデルを選んで1つのデプロイを作成することができます。
従って、本記事では以下の流れで実装を行っていきます。
- Python API・実装の利用準備
- データ準備
- プロジェクトの作成
- 学習
- 学習結果の取得
- 予測実施(プロジェクトモデル利用)
- デプロイ
- 予測実施(デプロイ利用)
利用データ
本記事ではsickit-learn(sklearn)の乳がんデータセットを使用します。
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html
Python API・実装の利用準備
Python環境
本記事を書くにあたって作成した環境は以下になります。
- python : 3.9.12
- datarobot : 3.2.0 (DataRobot python API)
- matplotlib : 3.5.2 (グラフ描画用)
- pandas : 1.4.3 (データ読み込み用)
- scikit-learn : 1.1.1 (データセット取得/作成用)
上記は絶対のバージョンではないので、動作する環境を調べて構築していただいて構いません。
Version参考
また、プログラム・データの構成は以下のようになっています
project/
┣data/
┃┣train.csv
┃┗test.csv
┣src/
┃┗datarobot_visualization.py
┣データセット取得_作成.py
┣プロジェクト作成.py
┣学習.py
┣学習結果の取得.py
┣予測実施_プロジェクトモデル利用.py
┣デプロイ.py
┗予測実施_デプロイ利用.py
※ここではpyファイルの名前をわかりやすく日本語にしていますが、実際には適切英語にしてください
データ準備
早速、sklearnを使ってデータセットを取得し、保存しておきます。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
dataset = load_breast_cancer()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df['target'] = dataset.target
train_df, test_df = train_test_split(df, test_size=0.2)
train_df.to_csv("data/train.csv")
test_df.to_csv("data/test.csv")
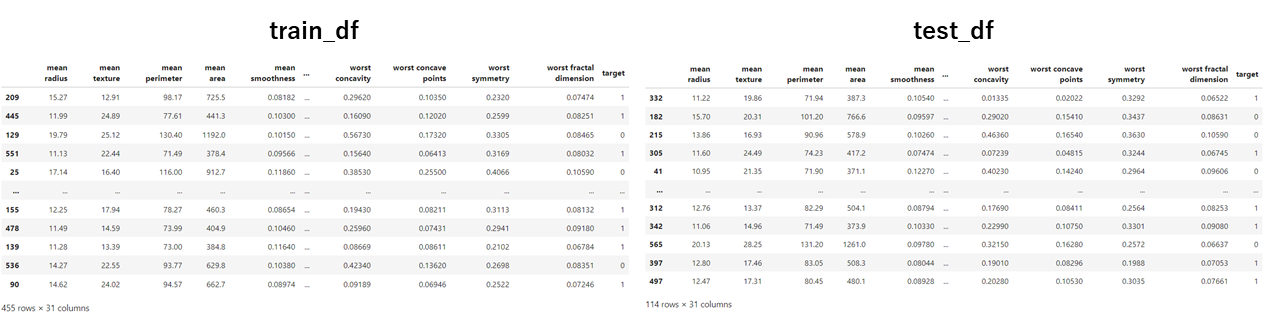
irisデータセットの中身(train_df, test_df)はそれぞれ以下のようになっています。
DataRobot API keyの作成
DataRobotに接続するためのAPI keyを作成します。
これはアカウント毎に作成され、keyが漏洩しないように注意してください。
以下の画像の手順で実施します。
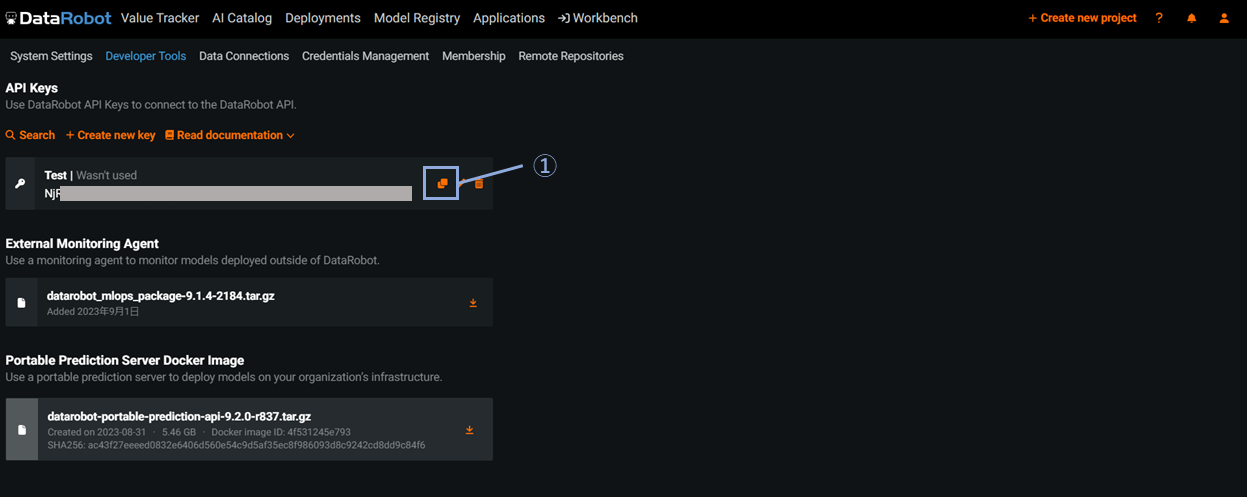
最後の画像でAPI keyをクリップボードにコピーしています。
コピーは後からでも行えるので、keyがわからなくなった場合は再度コピーしてください。
DataRobotの接続先endpoint
Endopointは以下3つのパターンがあります
- US/JPのユーザ:https://app.datarobot.com/api/v2
- EUのユーザ:https://app.eu.datarobot.com/api/v2
- オンプレユーザ:https://{オンプレのドメイン名}/api/v2
今回の環境では「https://app.datarobot.com/api/v2」を使用しました
プロジェクトの作成
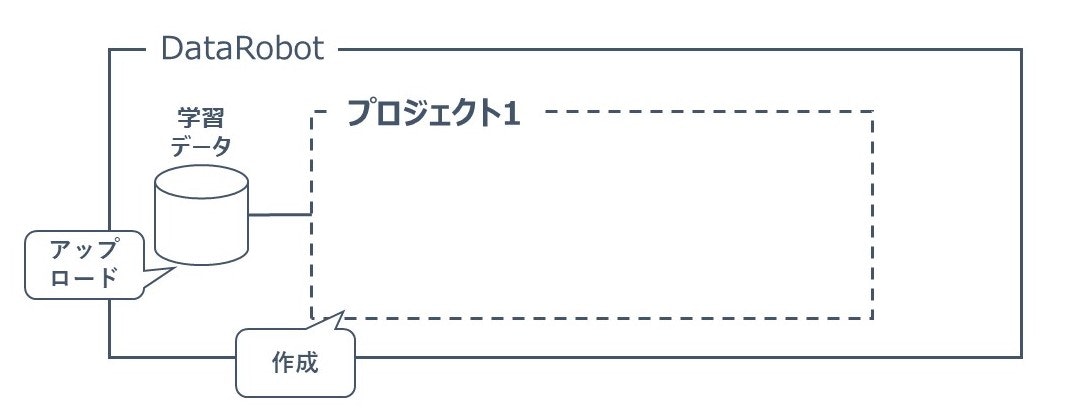
DataRobot上で分析プロジェクトを作成します。
プロジェクトは学習するデータをアップロードすることで作成されます。
以下のようなイメージです。
プログラムの全容は以下です
import datarobot as dr
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
DATA = "data/train.csv" # endpoint
PROJECT_NAME = "Test_Project" # 作りたいプロジェクトの名前
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
)
# データアップロード&project作成
project = dr.Project.create(TRAIN_PATH, project_name=PROJECT_NAME)
エラーなくプログラムが終了すれば、DataRobot側で指定した名前のプロジェクトが出来上がっています。
学習
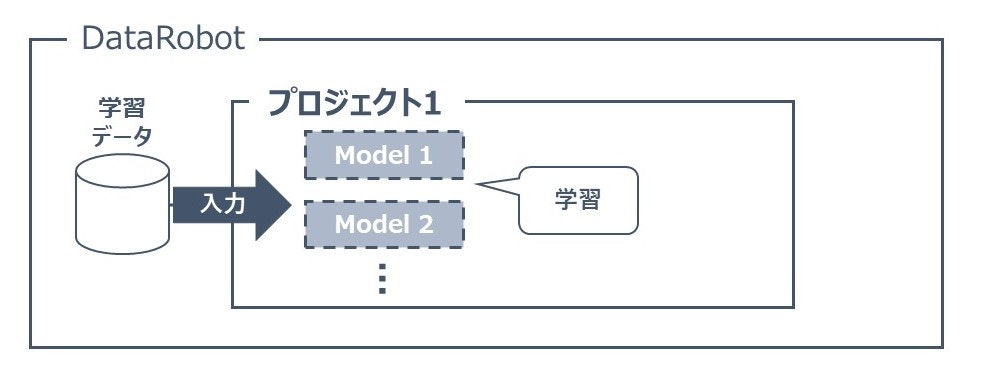
分析プロジェクトの学習をします。
以下のようなイメージです。
import datarobot as dr
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
PROJECT_NAME = "Test_Project" # project名
TARGET = "target" # csv内で目的変数とする列名
TRAIN_MODE = dr.enums.AUTOPILOT_MODE.QUICK #学習モードの設定
TARGET_TYPE = "Binary" # or Regression, Multiclass
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
)
# 作成したprojectの取得
project_list = dr.Project.list()
for project_info in project_list:
if project_info.project_name == PROJECT_NAME:
project = dr.Project.get(project_id=project_info.id)
break
# パーティション設定
partition = dr.RandomTVH(
holdout_pct=20,
validation_pct=20,
)
# その他の学習設定
advanced_options = dr.AdvancedOptions(
consider_blenders_in_recommendation=True, # アンサンブルをする
seed=42,
)
# 学習実行
project.analyze_and_model(
TARGET,
mode=TRAIN_MODE,
partitioning_method=partition,
advanced_options=advanced_options,
max_wait=60*60*10, # sec*min*hour
target_type=TARGET_TYPE,
)
TRAIN_MODE
学習モードはマニュアル、オート、クイックの3種類あり、「TRAIN_MODE = dr.enums.AUTOPILOT_MODE.QUICK」の部分を以下のように書き換えることでその他のモードで実現できます。
TRAIN_MODE = dr.enums.AUTOPILOT_MODE.MANUAL # マニュアル
TRAIN_MODE = dr.enums.AUTOPILOT_MODE.FULL_AUTO # オート
TRAIN_MODE = dr.enums.AUTOPILOT_MODE.QUICK # クイック
作成したprojectの取得
ここでは作成していたプロジェクトを再度このプログラムで取得しています。
ここで注意ですが、プロジェクトの取得は「PROJECT_NAME」という変数と同じプロジェクト名を参照します。
DataRobotではプロジェクト名の重複を許しているので、同じプロジェクト名がある場合は最新のものを取得してしまいます。
私の場合は同じ名前のプロジェクトは作らないようにする工夫をしています。
パーティション
パーティションの設定は様々あり、ここでは深く言及しません。
以下の公式ドキュメントを参考ください。
Partition参考
学習結果の取得
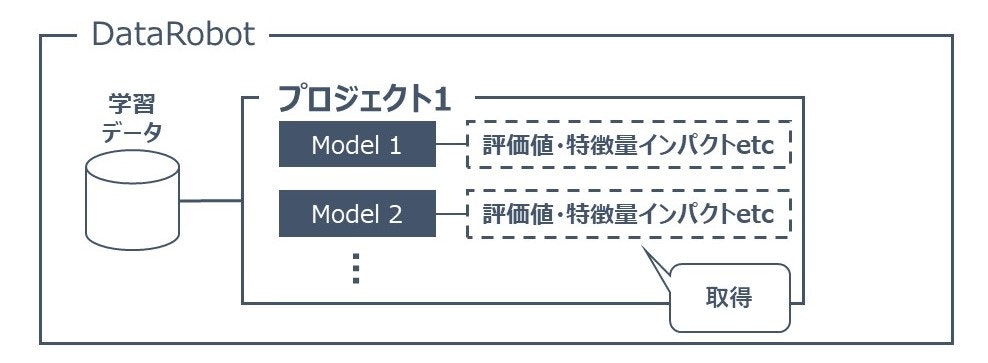
学習結果の取得をします。
以下のようなイメージです。
実際にはAPIでは予測結果のメタデータのみ取得できるため、その先のグラフ描画等は個人で行う必要があります。
この記事の最後でDataRobotぽい形でグラフ描画をする「src/datarobot_visualization.py」も併せて紹介しており、このグラフ描画ではこちらを利用しています。
import datarobot as dr
from src import datarobot_visualization as dr_vis
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
PROJECT_NAME = "Test_Project"
TARGET = "target"
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
)
# 作成したprojectの取得
project_list = dr.Project.list()
for project_info in project_list:
if project_info.project_name == PROJECT_NAME:
project = dr.Project.get(project_id=project_info.id)
break
# Auto pilotが終わるまで待つ
# datarobotの学習はpythonではなくdatarobot側で行われるため
# 結果取得の処理が先に動かないようにする
project.wait_for_autopilot(
check_interval=60*5, # sec
timeout=60*60*10, # sec
verbosity=1, # 0ならno display
)
# model取得
model = project.recommended_model()
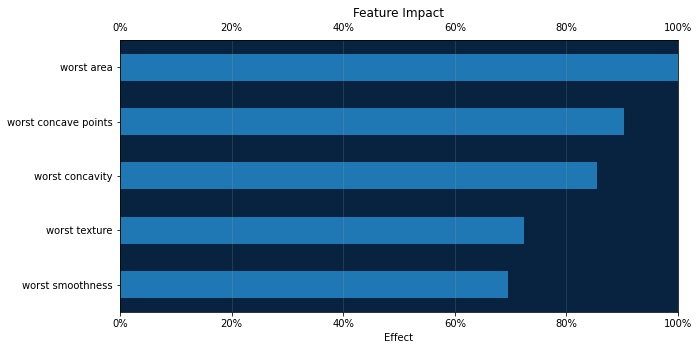
# 特徴量インパクト
dr_vis.show_feature_impact(model, num_features=5)
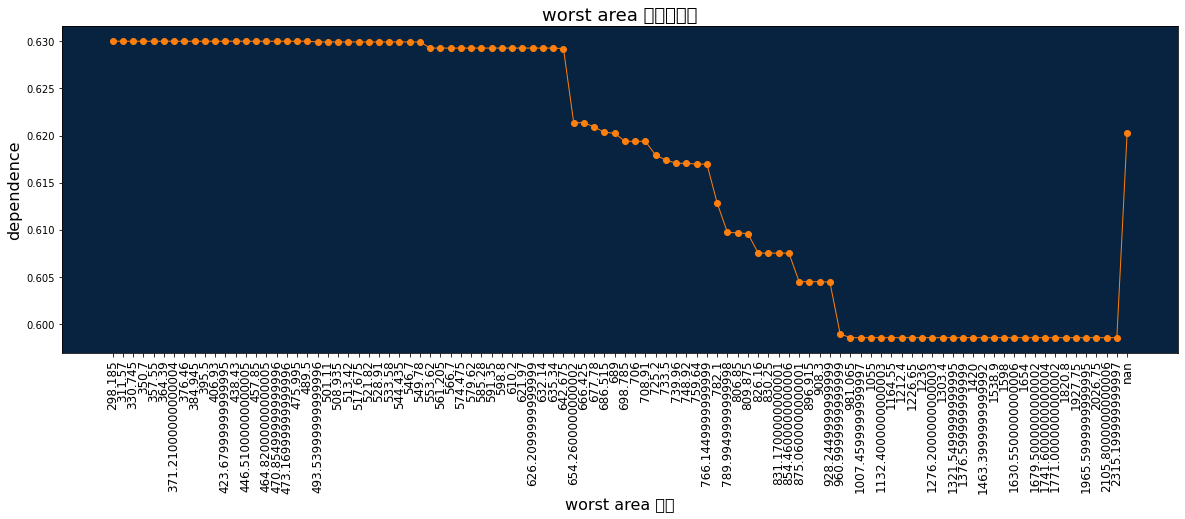
# 部分依存
feature_name = "worst area"
dr_vis.show_partial_dependence(model, feature_name)
取得できたグラフや結果は以下になります
特徴量インパクト
部分依存
予測実施(プロジェクトモデル利用)
予測データをアップロードし、予測を取得します。
以下のようなイメージです。
import datarobot as dr
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
PROJECT_NAME = "Test_Project"
PRED_PATH = "data/test.csv"
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
)
# 作成したprojectの取得
project_list = dr.Project.list()
for project_info in project_list:
if project_info.project_name == PROJECT_NAME:
project = dr.Project.get(project_id=project_info.id)
break
# model取得
model = project.recommended_model()
# DataRobot上に過去の予測用データが残っていることがあるので削除
for pred_data in project.get_datasets():
pred_data.delete()
# 予測用データアップロード
prediction_data = project.upload_dataset(PRED_PATH, max_wait=60*60*5, read_timeout=60*60*5)
# 予測実施
predict_job = model.request_predictions(prediction_data.id)
pred = predict_job.get_result_when_complete(max_wait=60*60*5)
prediction_data.delete()
# 予測結果保存
pred.to_csv("predition.csv", index=False)
dataフォルダ内にprediction.csvというファイルが生成されるはずです。
デプロイ
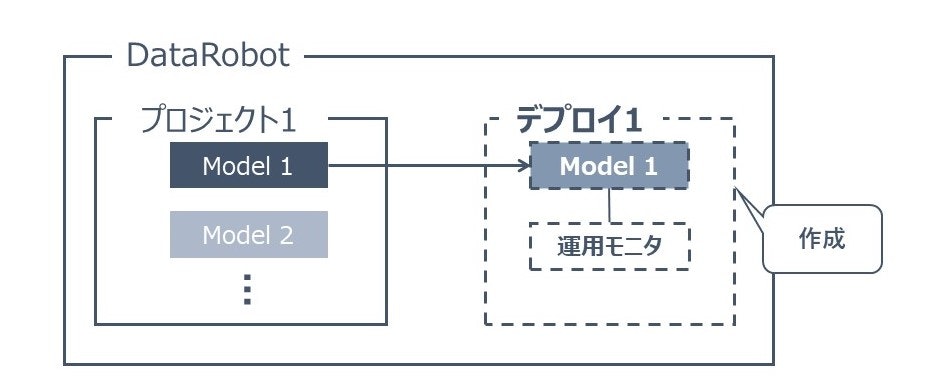
プロジェクト内の1モデルに対してデプロイを行います。
以下のようなイメージです。
import datarobot as dr
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
PROJECT_NAME = "Test_Project"
DEPLOY_NAME = "Test_Deploy"
DEPLOY_DESCRIPTION = "test deploy"
DEPLOY_IMPORTANCE = "MODERATE"
PREDICTION_THRESHOLD = 0.5
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
)
# 予測サーバーのid取得
prediction_server_id = dr.PredictionServer.list()[0].id
# 作成したprojectの取得
project_list = dr.Project.list()
for project_info in project_list:
if project_info.project_name == PROJECT_NAME:
project = dr.Project.get(project_id=project_info.id)
break
# model取得
model = project.recommended_model()
# デプロイ作成
deployment = dr.Deployment.create_from_learning_model(
model.id,
DEPLOY_NAME,
DEPLOY_DESCRIPTION,
prediction_threshold=PREDICTION_THRESHOLD,
importance=DEPLOY_IMPORTANCE,
default_prediction_server_id=prediction_server_id,
)
デプロイ画面に指定した名前のデプロイがされています。
予測実施(デプロイ利用)
デプロイの予測実施を行います。
以下のようなイメージです。
import datarobot as dr
API_KEY = "さっきコピーしたAPI keyをstrで張り付け"
DEPLOY_NAME = "Test_Deploy"
TEST_PATH = "data/test.csv"
PRED_PATH = "data/predition.csv"
# DataRobotへの接続
dr.Client(
token=API_KEY,
endpoint="https://app.datarobot.com/api/v2",
ssl_verify=False,
)
# 作成したデプロイの取得
deployment_list = dr.Deployment.list()
for deployment_info in deployment_list:
if deployment_info.label == DEPLOY_NAME:
deployment_id = deployment_info.id
break
# デプロイ予測
deployment_job = dr.BatchPredictionJob.score_to_file(
deployment_id,
TEST_PATH,
PRED_PATH,
)
# デプロイが終わるまで待つ
deployment_job.wait_for_completion(max_wait=60*60*2) # max_waitはseconds
dataフォルダ内にprediction.csvというファイルが生成されるはずです。
DataRobot図表出力スクリプト
学習後の結果取得スクリプト用いた図表作成関数は本環境では「src/datarobot_visualization.py」に集約していました。
こちらの内容は以下になります。
import pandas as pd
import numpy as np
import datarobot as dr
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
plt.rcParams["font.family"] = "IPAexGothic"
# 色の初期設定
dr_dark_blue = "#08233F"
dr_blue = "#1F77B4"
dr_orange = "#FF7F0E"
dr_red = "#BE3C28"
dr_roc_green = "#03c75f"
white = "#ffffff"
dr_purple = "#65147D"
dr_dense_green = "#018f4f"
def show_feature_impact(
model,
num_features=None,
filename=None,
):
"""
Feature Impactの描画
Args:
model: 選択したmodel
num_features: 描画する特徴量の数. Noneの場合はすべて. Defaults to None
filename: 保存file名. Noneなら保存しない. Defaults to None
"""
feature_impacts = model.get_or_request_feature_impact(5*60) # 5min wait
# Formats the ticks from a float into a percent
percent_tick_fmt = mtick.PercentFormatter(xmax=1.0)
impact_df = pd.DataFrame(feature_impacts)
impact_df.sort_values(
by="impactNormalized",
ascending=True,
inplace=True,
)
# Positive values are blue, negative are red
bar_colors = impact_df.impactNormalized.apply(
lambda x: dr_red if x < 0 else dr_blue,
)
if num_features is None:
num_features = len(impact_df)
ax = impact_df.iloc[-num_features:].plot.barh(
x="featureName",
y="impactNormalized",
legend=False,
color=bar_colors[-num_features:],
figsize=(10, len(impact_df.iloc[-num_features:])),
)
ax.xaxis.set_major_formatter(percent_tick_fmt)
ax.xaxis.set_tick_params(labeltop=True)
ax.xaxis.grid(True, alpha=0.2)
ax.set_facecolor(dr_dark_blue)
plt.ylabel("")
plt.xlabel("Effect")
plt.xlim((None, 1)) # Allow for negative impact
plt.title("Feature Impact")
if filename is not None:
plt.savefig(filename, bbox_inches="tight")
plt.show()
def show_partial_dependence(
model,
feature_name,
source="training",
filename=None,
):
"""
部分依存の描画
Args:
model: 選択したmodel
feature_name: 描画したい部分依存の項目名
source: 部分依存を計算するためのソースデータ. "training" or "validation"を指定. Defaults to "training"
filename:保存file名. Noneなら保存しない. Defaults to None
"""
feature = model.get_or_request_feature_effect(source=source, max_wait=60*60) #1h wait
# 部分依存の取得
feature_dict = [d for d in feature.feature_effects if d["feature_name"] == feature_name][0]
pd_df = pd.DataFrame(feature_dict["partial_dependence"]["data"])
fig = plt.figure(figsize=(min(max(len(pd_df), 12), 20), 6))
ax = fig.add_subplot(1,1,1)
ax.plot(pd_df["label"], pd_df["dependence"], marker="o", lw=1, color=dr_orange)
ax.set_xlabel(f"{feature_name} の値", size=16)
ax.set_ylabel("dependence", size=16)
ax.set_xticklabels(pd_df["label"], size=12)
if len(pd_df) > 10:
ax.tick_params(axis="x", rotation=90)
ax.set_title(f"{feature_name} の部分依存", size=18)
ax.set_facecolor(dr_dark_blue)
if filename is not None:
plt.savefig(filename, bbox_inches="tight")
plt.show()
まとめ
本記事ではDataRobot python APIを使って学習~デプロイ予測までを行いました。
python APIを使うことでpythonで前処理などを行った流れでモデリングをしたり、複数モデルを同じ条件・ロジックで作成することが容易になります。
その他にも、実装をnotebookで行えば、プログラミング知識のないでもワンクリック(notebookのRun all)で動作するので、
お客様先でモデルをシステム化しない運用でも、喜んで活用いただけます。
是非pythonも扱える方は試してみてください!
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。