0. この記事の狙いと対象者
最近では便利な可視化ツールやpythonのパッケージがリリースされ、データ分析作業が日々楽になってきていますが、一方で分析者以外に結果を提出するためのレポーティング作業は属人的な部分が多いように感じています。
例えば分析結果をエクセルファイルで提出する際、視認性を高めるために「ヘッダーの色変更」「数値のカンマ区切り」「罫線の描画」「セル幅の調整」を実施したりします。
視認性が高まることで分析者以外の方からの満足度が向上しますが、pythonなどの分析結果から人手で毎回作成することは大変です。
こういった作業をpythonで自動化することで、レポーティングの負担を減らせるようになることが本記事の狙いです!!
■対象者
- pythonについて基礎知識がある方
- pythonでExcel操作をしたい方
1. openpyxlとは
openpyxlとは、エクセルファイルの作成や細かい編集(色や罫線)を可能にするpythonのパッケージです。
本記事ではopenpyxをどのように使うかを可能な限り最小単位でまとめています。
2. openpyxlのインストール
公式ドキュメントは以下です。
https://openpyxl.readthedocs.io/en/stable/
pythonへの導入は以下でできます。
$ pip install openpyxl
3. openpyxlの基本概念
openpyxlはExcelファイルへのパスを指定して読み込むことで、python内でデータとして扱えるようにします。
読み込んだ際のデータ構成は下図のようなイメージです。

読み込んだデータ自体は「work book」という呼び方をし、work bookの中にExcelファイルの各シートを「work sheet」という単位で保持します。
この「work sheet」の中に各シート内のセル情報がオブジェクトとして保持されています。
読み込んだExcelは同名で保存しない限り上書きされないため、プログラム上で修正などを自由に行って構いません。
4. openpyxlの操作まとめ
4-0. 以降の章で使用するExcelファイルの作成
「3. openpyxlの基本概念」でお見せした画像の「test.xlsx」Excelファイル(test1, test2シート)を作成します。
本記事ではここで作成したExcelファイルを例として利用する場合があるため、事前に下記を実行し、Excelファイルを作成しておくことを推奨します。
このプログラムはあまり汎用的なものではないです。
import openpyxl
from openpyxl.styles.borders import Border, Side
from openpyxl.styles import PatternFill
wb = openpyxl.Workbook() # workbookの作成
# 罫線の設定
side = Side(style='thin', color='000000')
border = Border(top=side, bottom=side, left=side, right=side)
# 背景色設定
color = PatternFill(patternType='solid', fgColor='D9E1F2')
# 1つ目のシート作成
test1_data = [
["ID", "NAME"],
[1,"AAA"],
[2,"BBB"],
[3,"CCC"],
[4,"DDD"],
]
ws = wb["Sheet"] # workbook作成時に「Sheet」シートが作成されているので、それを参照
ws.title = "test1" # sheet名変更
for row_i, row_data in enumerate(test1_data): # 行ごとのデータ取得
for col_i, data in enumerate(row_data): #行内の列ごとのデータ取得
col_letter = chr(ord("A")+col_i) # 列アルファベット名の生成(A,B,...とAにcol_iを足して自動生成)
address = f"{col_letter}{row_i+1}" # セルの位置
ws[address] = data # 値格納
ws[address].border = border # 罫線の設定
if row_i<1:
ws[address].fill = color # 背景色の設定
# 2つ目のシート作成
color = PatternFill(patternType='solid', fgColor='FCE4D6') # 背景色変更
test2_data = [
["ID", "NAME", "", "Address"],
["", "姓", "名", ""],
[1,"A", "AA", "Tokyo"],
[2,"B", "BB", "Tokyo"],
[3,"C", "CC", "Osaka"],
[4,"D", "DD", "Aichi"],
]
ws = wb.create_sheet(title="test2") # Sheetの作成
num_empty_row = 1 # 空の行をいくつ挿入するか
num_empty_col = 1 # 空の列をいくつ挿入するか
for row_i, row_data in enumerate(test2_data): # 行ごとのデータ取得
for col_i, data in enumerate(row_data): #行内の列ごとのデータ取得
col_letter = chr(ord("A")+col_i+num_empty_col) # 列アルファベット名の生成(A,B,...とAにcol_iとnum_empty_colを足して自動生成)
address = f"{col_letter}{row_i+1+num_empty_row}" # セルの位置
ws[address] = data # 値格納
ws[address].border = border # 罫線の設定
if row_i<2:
ws[address].fill = color # 背景色の設定
# セル結合
ws.merge_cells("B2:B3")
ws.merge_cells("C2:D2")
ws.merge_cells("E2:E3")
wb.save("test.xlsx")
4-1. Workbook操作
4-1-1. Excelファイル新規作成
- openpyxl.Workbook()
既存のExcelがない場合に1からworkbookを作成する方法です。
以下使用例です。
import openpyxl
wb = openpyxl.Workbook() # workbookの作成
これで新しいwork bookを作成できます。
ただ、これだけだと何も意味はなく、ここから以下を実施して初めてExcelファイルとなります。
- シート名の変更(デフォルトでは「Sheet」というシートがある)
- セルに対して値やスタイルを挿入
- Excelファイルとしての保存
それぞれの手順については以降の章で説明しています。
4-1-2. 既存Excelファイル読み込み
- openpyxl.load_workbook("Excelファイルのパス")
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
既存のExcelファイルのパスを指定することでworkbookを読み込めます。
4-1-3. 保存
- wb.save("保存するパス")
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx")
wb.save("out.xlsx") # Excelファイルの保存
Excelファイルパスを指定することでworkbookおよびwb内部にあるworksheetを保存します。
ここで保存するExcelのパスを既存のExcelと同じものにすると上書きで保存されます。
保存するExcelファイルパスを指定した時に、そのExcelファイルが開かれていると以下のエラーが出ます
PermissionError: [Errno 13] Permission denied: Excelファイル名
その場合は一度開いているExcelファイルを閉じて、再実行してください。
4-1-4. 値のみの読み込み
- openpyxl.load_workbook("Excelファイルのパス", data_only=True)
以下使用例です。
Excelファイルにはセル内に関数が記載されている場合があり、その関数式ではなく結果の値のみ取り出したい場合があります。
(例:=SUM(~~)とあったとき、そのSUM結果を値として取りたい)
その場合は以下を実行します。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx", data_only=True) # Excelファイルの読み込み
「data_only=True」とすることで実施できます。
関数の結果は一度Excelファイルを手動で開いていないとプログラムで取得することはできません。
理由は一度開いておかないと関数の結果がキャッシュとして残らないためです。
人手で作ったExcelファイルを読み込むなら作成時点で開いているので問題ないですが、プログラムで0から作成したExcelファイルの場合はそのExcelファイルを人手で1度開く必要があります。
4-2. Worksheet操作
4-2-1. シート新規作成/追加
- wb.create_sheet(title="追加するシート名")
- wb.create_sheet(title="追加するシート名", index=追加位置)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb.create_sheet(title="追加シート") # シートの追加
追加するシート名の空シートが作成されます。
追加位置を以下のように指定することもできます。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb.create_sheet(title="追加シート", index=0) # シートの追加
「index」で指定した位置にシートを追加します。
0が先頭で+1するとシート内で右に移動していきます。
indexの値はマイナスも許容しますが-1はシートの一番右から1つ左に位置します。
さらに-1するとシートの位置は左に移動します。
一番右にシートを追加したい場合はindexを指定しなければ実現できます。
4-2-2. シート名一覧取得
- wb.sheetnames
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
sheet_names = wb.sheetnames # シート名一覧取得
print(sheet_names)
出力結果はシート名が文字列として入ったlistになります。
['test1', 'test2']
4-2-3. 既存シート読み込み
- wb["既存のシート名"]
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
既存のシートをworksheetとして「ws」という変数に代入しています。
こちらについては、以下のように変数を再代入しても元のworksheetが壊れることはありません。
また、変数wsに対して何か修正したとしても、大本の変数wb配下にあるwork sheetに自動で修正が反映されます。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シート1の取得
"""~~sheet1の処理~~"""
ws = wb["test2"] # シート2の取得⇒変数wsに再代入しているが「test1」シートには無影響
4-2-4. シート名変更
- ws.title = "新しいシート名"
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
ws.title = "テスト名変更" # 新しいシート名
4-2-5. シートの順番入れ替え
- wb.move_sheet("移動したいシート名", offset=移動幅)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
wb.move_sheet("test1", offset=1) # シートの移動
指定したシート名を今の位置からoffsetの数だけ移動します。
- 正の場合はシートを右に移動
- 負の場合はシートを左に移動
このままだと少し使いづらい場合もあるので「5. おまけスニペット」に先頭へ移動/最後尾へ移動/2シートのスイッチをするコードを用意しています。
4-2-6. 同ファイル内のシートのコピー
- wb.copy_worksheet(wb["コピーしたいシート名"])
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb.copy_worksheet(wb["test2"])
コピー後のシート名はコピー元のシート名の末尾に「Copy」がつきます。
以下その例です。
ws = wb.copy_worksheet(wb["test2"])
print(wb.sheetnames)
['test1', 'test2', 'test2 Copy']
4-2-7. シート内の値記載範囲取得
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
min_row = ws.min_row # 行の最小
max_row = ws.max_row # 行の最大
min_col = ws.min_column # 列の最小
max_col = ws.max_column # 列の最大
print(F"行の最小{min_row}・行の最大{max_row}")
print(F"列の最小{min_col}・列の最大{max_col}")
行の最小1・行の最大5
列の最小1・列の最大2
シート範囲の最小/最大の値は0からではなく1からの基準となっています。
4-2-8. シートの色変更
- ws.sheet_properties.tabColor = "色コード"
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
ws.sheet_properties.tabColor = "FF8C00" # シートの色設定
指定結果は以下のようになります。

色の指定は16進数で行っており、Excelの画面からだと以下のように参照可能です。(この限りではないです)

4-3. セル操作
4-3-1. セルのアドレスでアクセス(列アルファベット・番号)
- ws["アルファベットと数字の組み合わせ"]
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
cell = ws["A1"] # A1セルの取得
上記でExcelファイル・test1シート上の「A1」セルの情報をcell変数に代入します。
指定するアルファベットは実際のデータが格納されていない箇所のセルでも指定できます(例:「AA123」など)
4-3-2. セルのアドレスでアクセス(列番号・番号)
- ws.cell(row=行番号, column=列番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
cell = ws.cell(row=1, column=1) # A1セルの取得
上記でExcelファイル・test1シート上の「A1」セルの情報をcell変数に代入します。
(最初の行を1、最初の列(A)を1として数字を入れます。※マイナスは不可と考えてよいです)
指定するアルファベットは実際のデータが格納されていない箇所のセルでも指定できます(例:row=10, column=10など)
4-3-3. 列のアルファベット名と数値の変換
- 列アルファベットへの変換:openpyxl.utils.get_column_letter(列番号)
- 列番号への変換:openpyxl.utils.column_index_from_string("列アルファベット")
以下使用例です。
column_letter = openpyxl.utils.get_column_letter(10)
column = openpyxl.utils.column_index_from_string("D")
print(f"列アルファベット:{column_letter}")
print(f"列番号:{column}")
列アルファベット:J
列番号:4
上記を用いれば、数値からアルファベットを求めてセルアクセスといったやりかも可能になります。
4-3-4. 行単位でセルアクセス
- row = ws[行番号]
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
row = ws[1] # 1行取得
print(row)
(<Cell 'test1'.A1>, <Cell 'test1'.B1>)
上記ではrowという変数にExcelファイル・test1シート上のデータが1行だけ格納されています。
取得するデータはExcelファイル内に記載されているデータ範囲内となり、A~B列までのタプルを取得できています。
しかし、上記のままでは個別のセルにアクセスできないため、以下のようにすることで個別のセルにアクセスします。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
row = ws[1] # 1行取得
for cell in row:
cellごとの処理
変数rowの中身は行内のセルのタプルでしたので、for文で各セルにアクセスしています。
全セルを各行ごとに処理をする場合は以下のようにします。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
for row in ws: # 各行でループ
for cell in row:
cellごとの処理
ws[行番号]で指定する行番号は1以上の値である必要があります。
4-3-5. 列単位でセルアクセス
- col = ws["列アルファベット"]:
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
col = ws["A"] # 1列取得
print(col)
(<Cell 'test1'.A1>, <Cell 'test1'.A2>, <Cell 'test1'.A3>, <Cell 'test1'.A4>, <Cell 'test1'.A5>)
上記ではcolという変数にExcelファイル・test1シート上のデータがA列だけ格納されています。
取得するデータはExcelファイル内に記載されているデータ範囲内となり、1~5行までのセルのタプルを取得できています。
しかし、上記のままでは個別のセルにアクセスできないため、以下のようにすることで個別のセルにアクセスします。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
col = ws["A"] # 1列取得
for cell in col:
cellごとの処理
変数colの中身は列内のタプルでしたので、for文で各セルにアクセスしています。
全セルを各列ごとに処理をする場合は「ws.columns」で実現でき、以下のようにします。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
for col in ws.columns # 各列でループ
for cell in col:
cellごとの処理
4-3-6. 指定範囲でセルアクセス
- subset_ws = ws.iter_rows(min_row, max_row, min_col, max_col)
- subset_ws = ws["アルファベットと数字の組み合わせ:アルファベットと数字の組み合わせ"]
- subset_ws = ws["アルファベットと数字の組み合わせ":"アルファベットと数字の組み合わせ"]
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
subset_ws = ws.iter_rows(min_row=2, max_row=4, min_col=3, max_col=5)
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
subset_ws = ws["B2:E5"]
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
subset_ws = ws["B2":"E5"]
上記は指定した部分の範囲のセルを変数subset_wsに代入します。
subset_wsから各セルを取得するには、「4-3-4. 行でセルアクセス」と同じやり方を行います。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
subset_ws = ws.iter_rows(min_row=2, max_row=4, min_col=3, max_col=5)
for row in subset_ws: # subset_ws内の各行ごとにループ
for cell in row:
cellごとの処理
4-3-7. セルに値代入/更新
- cell.value
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
cell = ws["A1"] # A1セルの取得
value = cell.value
print(value)
ID
A1のセルに記載されている「ID」が取得できていることが分かります。
上書きする場合は下記のようにします
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
cell = ws["A1"] # A1セルの取得
cell.value = "識別番号"
print(cell.value)
識別番号
まだ値がないセルに対しても同様に値を代入できます。
4-3-8. セルの座標取得
セルから座標を取得することもできます。
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test1"] # シートの取得
cell = ws["A1"] # A1セルの取得
print(f"セルアドレス : {cell.coordinate}")
print(f"セル列番号 : {cell.column}")
print(f"セル列アルファベット : {cell.column_letter}")
print(f"セル行番号 : {cell.row}")
セルアドレス : A1
セル列番号 : 1
セル列アルファベット : A
セル行番号 : 1
- cell.coordinate : アルファベットと数字のアドレスを取得します
- cell.column : 列番号を取得します
- cell.column_letter : 列アルファベットを取得します
- cell.row : 行番号を取得します
4-4. 結合セル(Merged Cell)の操作
結合セルはセル内にマージされているかどうかの情報を持つのではなく、
merged_cellsとして、worksheet内で別途管理されていることに注意して以降を読んでみてください。
4-4-1. 結合セルの一覧確認
- ws.merged_cells.ranges
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
merged_cells = ws.merged_cells.ranges
print(merged_cells)
{<MergedCellRange E2:E3>, <MergedCellRange B2:B3>, <MergedCellRange C2:D2>}
上記のように、結合されているセルの一覧はworksheetが管理しています。
4-4-2. 結合セルのセルアクセス
結合セルへのアクセスは「4-3. セル操作」と変わらずアクセスできます。
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
cell1 = ws["B2"] # 結合セルの先頭
cell2 = ws["B3"] # 結合セルの最後
cell3 = ws["B4"] # 通常セル
print(f"結合セルの先頭:{cell1}")
print(f"結合セルの最後:{cell2}")
print(f"通常セル:{cell3}")
結合セルの先頭:<Cell 'test2'.B2>
結合セルの最後:<MergedCell 'test2'.B3>
通常セル:<Cell 'test2'.B4>
出力結果を見ると、結合セルの先頭は「Cell」オブジェクトで結合セルの最後が「MergedCell」オブジェクト、通常セルは「Cell」オブジェクトになっていることが分かります。
つまり、セル結合は先頭(最左上)のセルは「Cell」オブジェクトで、それ以外は「MergedCell」オブジェクトになっています。
そのため、例えば「B2」のセルだけを見てしまうと、B2が結合セルかどうかは判断できず、それを確認するには「ws.merged_cells.ranges」を使う必要があります。
中の値も以下のように見てみます。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
cell1 = ws["B2"] # 結合セルの先頭
cell2 = ws["B3"] # 結合セルの最後
cell3 = ws["B4"] # 通常セル
print(f"結合セルの先頭の値:{cell1.value}")
print(f"結合セルの最後の値:{cell2.value}")
print(f"通常セルの値:{cell3.value}")
結合セルの先頭の値:ID
結合セルの最後の値:None
通常セルの値:1
上記でもわかるように、結合セルの値は「Cell」オブジェクトである先頭セルが持っており、他の「MergedCell」は値を持たず、結合されているという情報のみ持つことが分かります。
ただし、どのセルと結合されているかはセル自体は持っておらず、それを確認するには「ws.merged_cells.ranges」を使う必要があります。
後にセルの罫線などの扱い方にも触れますが、罫線や背景色も先頭の「Cell」のみ情報として持てば、結合セル全体に適用されます。
4-4-3. 結合セル一覧のデータからセルアクセス
結合セル一覧からセルアクセスしたい場合は以下のようにできます。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
merged_cells = list(ws.merged_cells.ranges) # もともとsetなのでlistに変換
print(f"結合セルリスト:{merged_cells}")
merged_range = str(merged_cells[0]) # もともとMergedCellRangeなのでstrに変換
print(f"1つの結合セル範囲:{merged_range}")
cell = ws[merged_range] # セルへアクセス
結合セルリスト:[<MergedCellRange E2:E3>, <MergedCellRange B2:B3>, <MergedCellRange C2:D2>]
1つの結合セル範囲:E2:E3
「MergedCellRange」オブジェクトをそのまま使うことはできないため、文字列に変換することでアクセス可能にしています。
4-4-4. 結合セルの作成
- ws.merge_cells(start_row=開始の行番号, start_column=開始の列番号, end_row=終了の行番号, end_column=終了の列番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.merge_cells(start_row=4, start_column=2, end_row=5, end_column=4)
merged_cells = ws.merged_cells.ranges
print(merged_cells)
{<MergedCellRange B4:D5>, <MergedCellRange E2:E3>, <MergedCellRange B2:B3>, <MergedCellRange C2:D2>}
上記のように結合したいセルの開始~終了の行番号/列番号を記入することでセル結合されます。
出力結果には新たに結合した<MergedCellRange B4:D5>が含まれていることが分かります。
結果のExcelを保存して比較してみると以下のようになります。
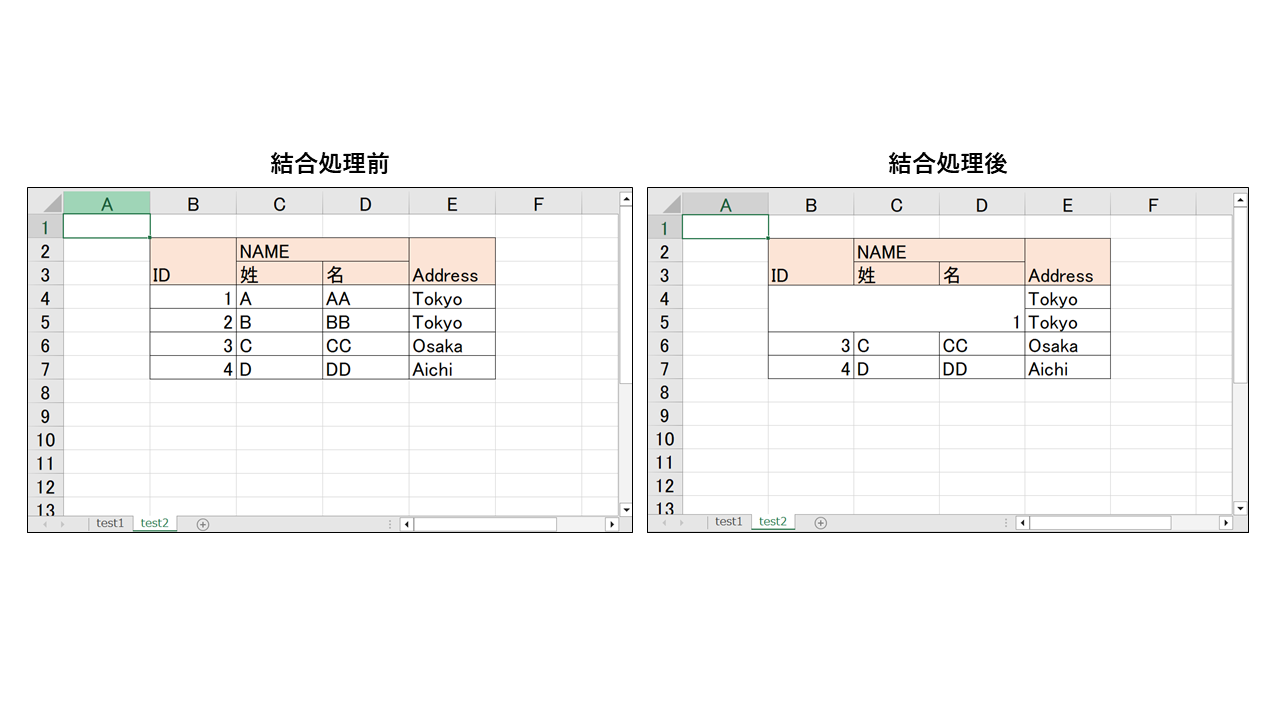
結合セルの作成は既存のセルの値を削除するので注意してください。
4-4-5. 結合セルの解除
- ws.unmerge_cells("結合セル範囲")
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.unmerge_cells("B2:B3")
上記のように解除したい結合セルの範囲を記載することで実現できます。
結果のExcelを保存して比較してみると以下のようになります。

結果より、解除後のセルは値も罫線や背景色などのスタイルもない状態であることが分かります。
4-5. セルのスタイル変更
本記事ではstyleの内、簡単なものをまとめますが、詳細は公式を見るのが早いです。
参照:https://openpyxl.readthedocs.io/en/latest/api/openpyxl.styles.html
4-5-1. スタイル情報へのアクセス
スタイルはセルオブジェクトが情報として持っているため、適用したいセルを取り出し、各スタイル情報にアクセスします。
以下がアクセス方法の例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
cell = ws["B2"]
border = cell.border # 罫線
fill = cell.fill # 背景色
font = cell.font # 文字
4-5-2. 罫線の変更
- openpyxl.styles.Side(style="線のスタイル", color="色コード")
openpyxl.styles.Border(top=上の線, bottom=下の線, left=左の線, right=右の線)
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
line = openpyxl.styles.Side(style="thick", color="000000") # 太線・黒色
border = openpyxl.styles.Border(top=line, bottom=line, left=line, right=line) # lineを上下左右すべてに適用
cell = ws["F4"]
cell.border = border
wb.save("output.xlsx")
罫線はまず「openpyxl.styles.Side()」で線自体を設定し、その線をもって「openpyxl.styles.Border()」の上下左右に線を設定します。
そのため、線の設定を複数用意すれば罫線の上下左右をそれぞれ別の線にすることも可能です。
上記の結果は以下のようになります。

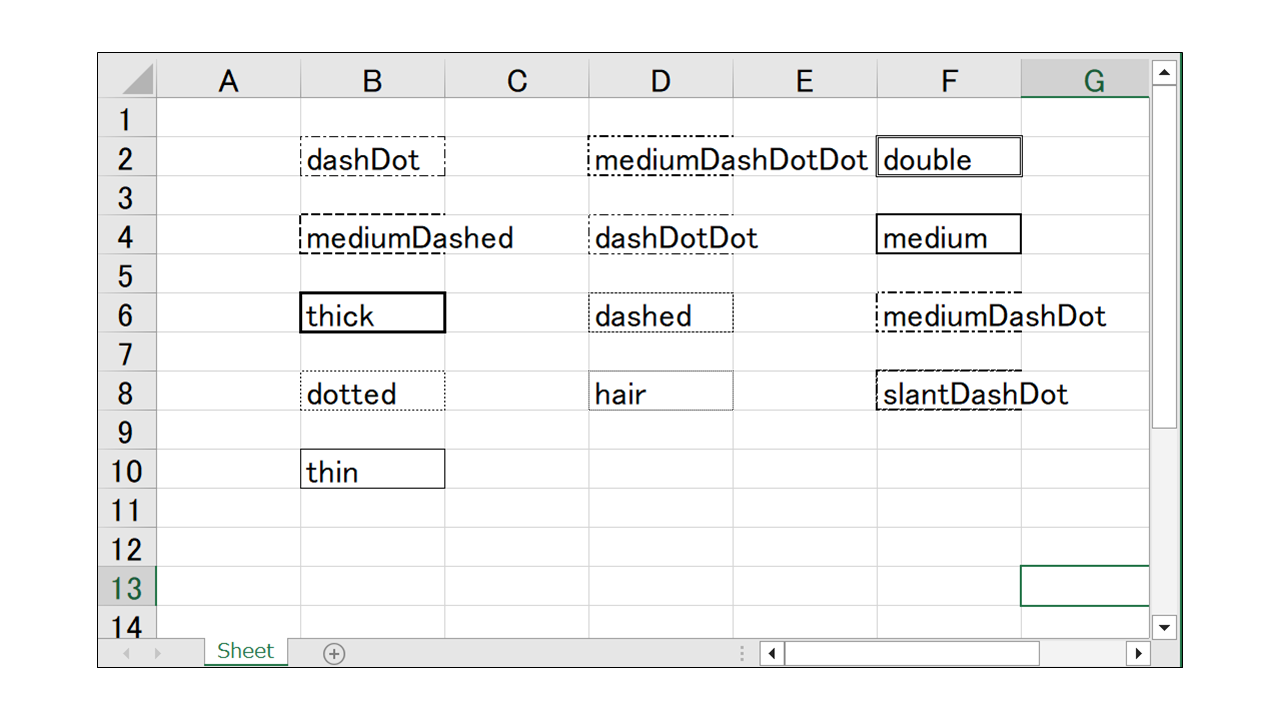
線の設定にある「style」引数は以下を設定できます。
hair, thin, medium, thick, double, dashDot, mediumDashed, dashDotDot, dashed, mediumDashDot, dotted, slantDashDot
それぞれの描画結果は以下のようになります。
4-5-3. 背景色の変更
- openpyxl.styles.PatternFill(fgColor="前面の色", bgColor="背面の色", fill_type="塗り方")
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
fill_color = openpyxl.styles.PatternFill(fgColor="B8CCE4", bgColor="B8CCE4", fill_type="solid") # 青色単色
cell = ws["F4"]
cell.fill = fill_color
wb.save("output.xlsx")
背景色は「openpyxl.styles.PatternFill()」で前面色、背面色、塗り方を指定します。
上記の結果は以下のようになります。

「fill_type」引数は以下を設定できます。
lightGray, darkTrellis, lightGrid, darkDown, darkGrid, darkUp, gray0625, lightTrellis, lightUp, lightDown, lightHorizontal, darkHorizontal, darkGray, gray125, mediumGray, darkVertical, solid, lightVertical
前面色「fgColor="B8CCE4"(青)」と背面色「bgColor="FCE4D6"(オレンジ)」としたときの、それぞれの「fill_type」の描画結果は以下のようになります。

4-5-4. 文字色の変更
- openpyxl.styles.fonts.Font(color="色コード")
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
font = openpyxl.styles.fonts.Font(color="FF0000") # 赤色
cell = ws["B2"]
cell.font = font
wb.save("output.xlsx")
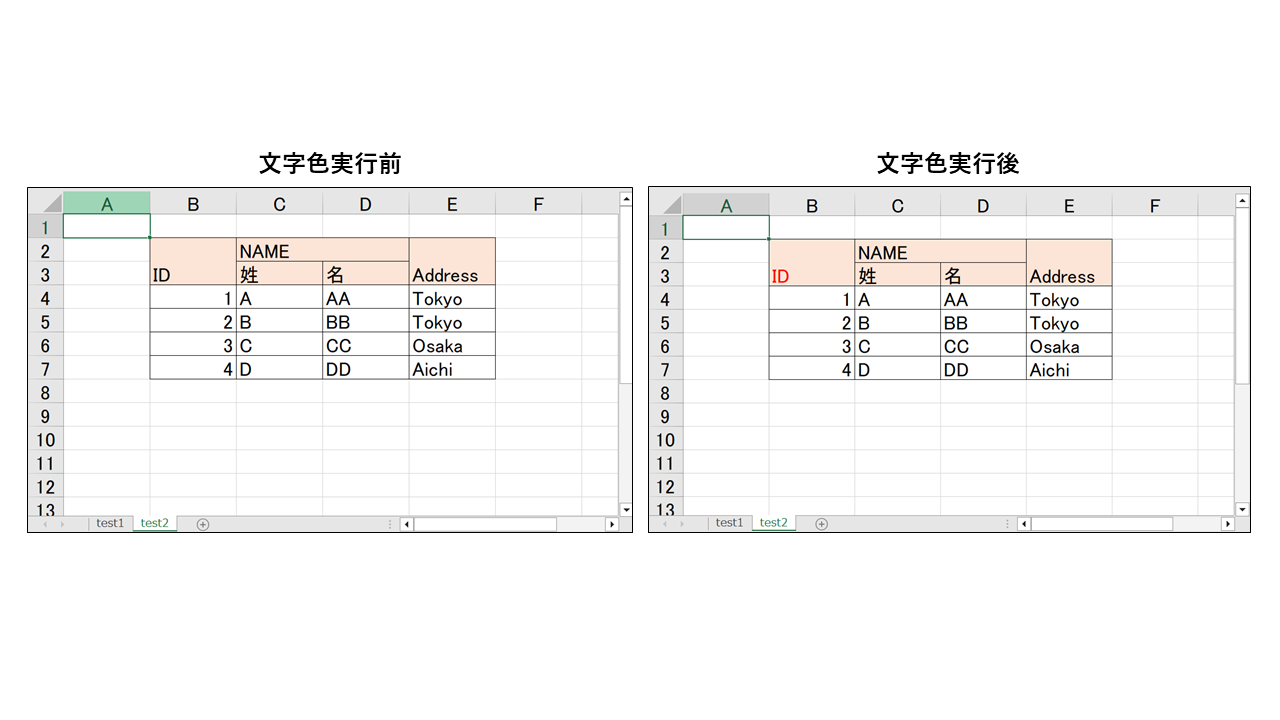
文字回りは「openpyxl.styles.fonts.Font()」に適切な引数を記載することで設定できます。
文字色は「color」引数を使います。
上記の結果は以下のようになります。
4-5-5. 文字の大きさ変更
- openpyxl.styles.fonts.Font(size=文字サイズ)
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
font = openpyxl.styles.fonts.Font(size=20) # サイズ20
cell = ws["B2"]
cell.font = font
wb.save("output.xlsx")
文字回りは「openpyxl.styles.fonts.Font()」に適切な引数を記載することで設定できます。
文字サイズは「size」引数を使います。
上記の結果は以下のようになります。

4-5-6. フォントの変更
- openpyxl.styles.fonts.Font(name="フォント名")
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
font = openpyxl.styles.fonts.Font(name="HGP創英角ポップ体") # fontの変更
cell = ws["B2"]
cell.font = font
wb.save("output.xlsx")
文字回りは「openpyxl.styles.fonts.Font()」に適切な引数を記載することで設定できます。
フォントは「name」引数を使います。
上記の結果は以下のようになります。

4-5-7. 文字の太字/斜字変更
- openpyxl.styles.fonts.Font(bold=True, italic=True)
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
font = openpyxl.styles.fonts.Font(bold=True, italic=True) # 太字, 斜字
cell = ws["B2"]
cell.font = font
wb.save("output.xlsx")
文字回りは「openpyxl.styles.fonts.Font()」に適切な引数を記載することで設定できます。
太字斜字は「bold」と「italic」引数を使います。
上記の結果は以下のようになります。

4-5-8. 文字のフォーマット(書式)変更
- cell.number_format = "表記フォーマット"
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
cell = ws["B5"]
cell.number_format = "0.000" # 0.000表記
wb.save("output.xlsx")
「cell.number_format」に表記を指定することでフォーマットを指定できます。
上記の結果は以下のようになります。

数値の簡単なフォーマットの種類は以下です。
| フォーマット | 結果 |
|---|---|
| オリジナル | 1234.5678 |
| 0 | 1235 |
| 00000 | 01235 |
| 0.000 | 1234.568 |
| #,## | 1,235 |
| #,##0.00 | 1,234.57 |
| 0.00% | 123456.78% |
| #,##0.00 | 123,456.78% |
その他にも年月日や曜日の指定も可能です
参考:https://pythonmaniac.com/openpyxl-cell-formatting/
4-5-9. セル幅の変更
- ws.column_dimensions["列アルファベット"].width = セル幅
以下使用例です。
import openpyxl
import openpyxl.styles # style用に追加import
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.column_dimensions["B"].width = 10
wb.save("output.xlsx")
上記の結果は以下のようになります。

自動で全体のセル幅を調整するコードを「5. おまけスニペット」に用意しているのでご活用ください。
4-5-10. 結合セル(Merged Cell)の場合
結合セルは、そのセル自体にではなく、結合セルの先頭(最左上)のセルに適用したスタイルが結合セル全体に適用されます。
4-6. グラフ描画
以降では各節ごとに異なる入力Excelファイルを使います。
コードが長くなることを防ぐため、Excelデータを作成するコードは記載せず、試したい方はファイル名/シート名をプログラムに合わせて手動で作って実施いただければと思います。(非常に簡素なデータなので)
また、グラフ描画に関する公式のドキュメントは以下になります。
参照:https://openpyxl.readthedocs.io/en/stable/charts/introduction.html
4-6-1. グラフ描画の概要
グラフ描画は以下の図のような考え方を使います。

Excelのデータから「データ」の範囲を参照し、その参照範囲からChartとなるオブジェクトを生成し、それを指定したセル(=アンカー)にグラフの左上を合わせて描画します。
4-6-2. 線グラフ
- openpyxl.chart.Reference(ws, min_row, max_row, min_col, max_col)
- openpyxl.chart.LineChart()
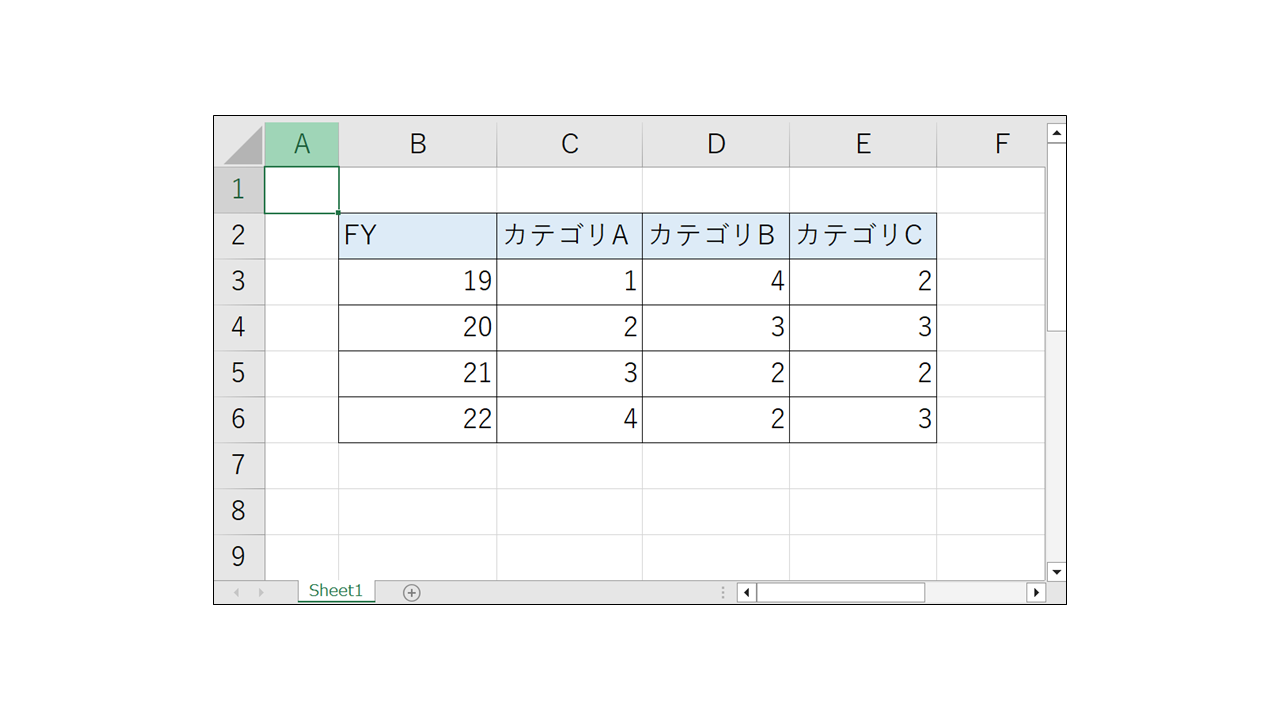
データは以下のExcelを作成し、本記事では「linechart.xlsx」という名前で使うので、同名で保存しておきます。(保存場所は実行するnotebookと同じフォルダ内を想定しています。)
さっそくプログラムで線グラフを描画します。
import openpyxl
import openpyxl.chart
wb = openpyxl.load_workbook("linechart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# 参照
category = openpyxl.chart.Reference(ws, min_row=3, max_row=6, min_col=2, max_col=2) # カテゴリ(x軸)範囲の参照
data = openpyxl.chart.Reference(ws, min_row=2, max_row=6, min_col=3, max_col=5) # データ範囲の参照
# line chartの作成
chart = openpyxl.chart.LineChart()
chart.add_data(data, titles_from_data=True)
chart.set_categories(category)
chart.anchor = "B7" # アンカー
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。
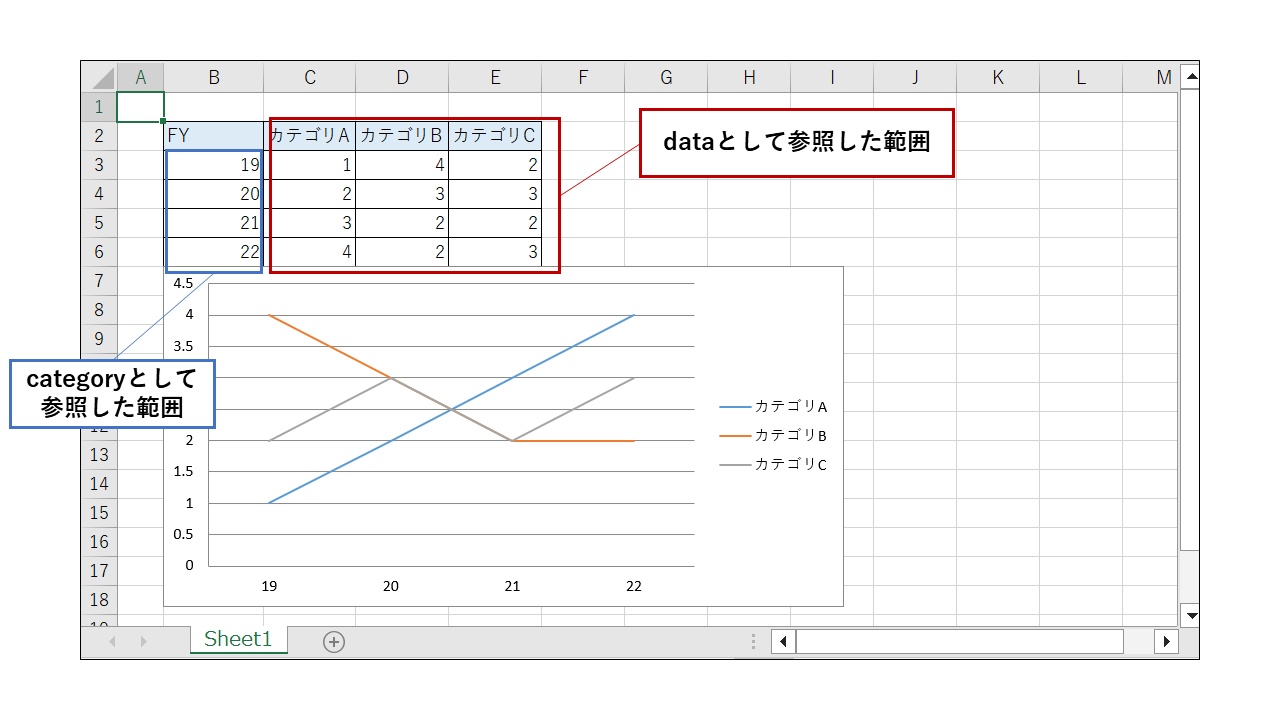
線グラフの設定はまだまだできることがあり、以下いくつか追加した例を記載します。
import openpyxl
import openpyxl.chart
wb = openpyxl.load_workbook("linechart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# 参照
category = openpyxl.chart.Reference(ws, min_row=3, max_row=6, min_col=2, max_col=2) # カテゴリ(x軸)範囲の参照
data = openpyxl.chart.Reference(ws, min_row=2, max_row=6, min_col=3, max_col=5) # データ範囲の参照
# line chartの作成
chart = openpyxl.chart.LineChart()
chart.add_data(data, titles_from_data=True)
chart.set_categories(category)
chart.title = "FYチャート" # title設定
chart.x_axis.title = "FY" # x軸のラベル
chart.y_axis.title = "数値" # y軸のラベル
chart.height = 8 # グラフの高さ
chart.width = 20 # グラフの横幅
chart.anchor = "B7" # アンカー
# 個別の線の設定
chart.ser[0].graphicalProperties.line.solidFill = "FF0000" # 最初の線の色変え
chart.ser[0].graphicalProperties.line.dashStyle = "sysDashDot" # 最初の線を破線に
chart.ser[2].smooth = True # 3番目の線を折れ線ではなくスムーズな線にする
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。

何をやっているかはコードのコメントを見れば理解できるかと思います。
各個別の線の設定のみ複雑なので説明します。
各線の情報は「chart.ser[X]」でX番目の線にアクセスすることができます。
そのうえで、色や線のスタイルなどを個別に設定可能となっています。
こちらで詳しくまとまっています:https://atmarkit.itmedia.co.jp/ait/articles/2203/08/news028.html
4-6-3. 線グラフ(横向きデータ)
線グラフを横向きのデータから同様に作る場合を考えます。
基本の思考は「4-6-2. 線グラフ」と同じです。
データは以下のExcelを作成し、本記事では「linechart_横向き.xlsx」という名前で使うので、同名で保存しておきます。(保存場所は実行するnotebookと同じフォルダ内を想定しています。)
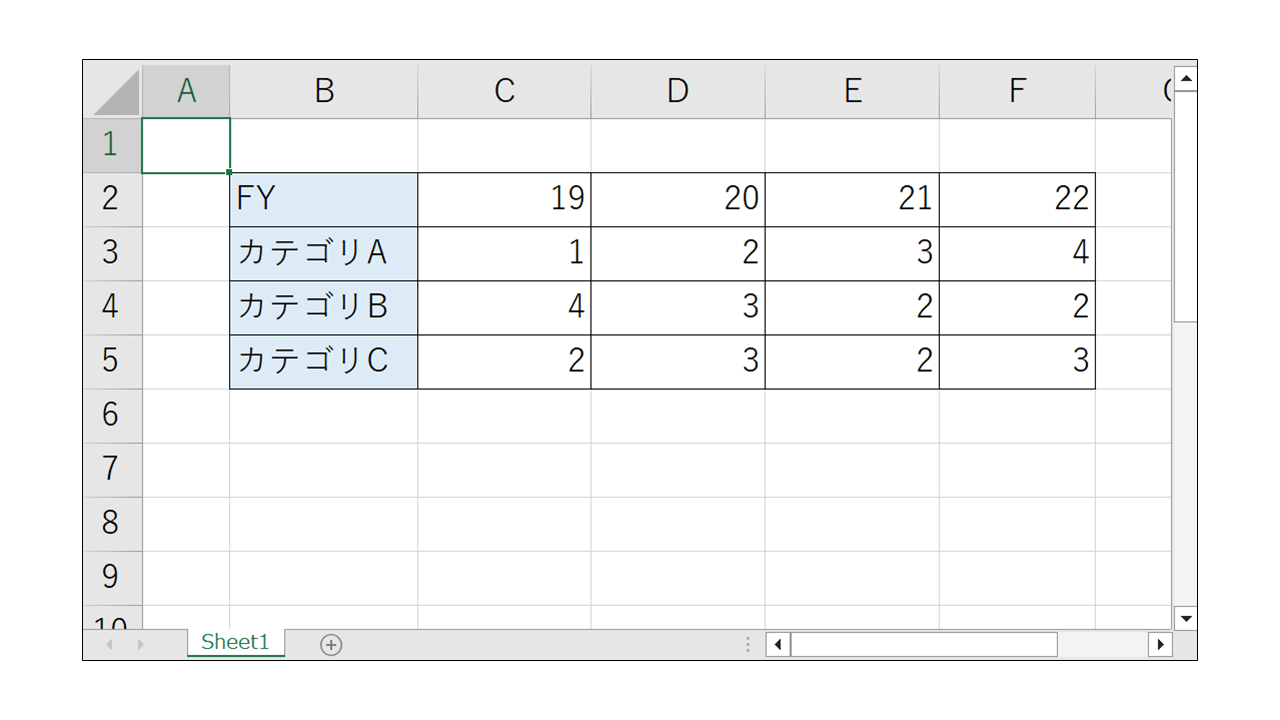
さっそくプログラムでグラフを描画します。
import openpyxl
import openpyxl.chart
wb = openpyxl.load_workbook("linechart_横向き.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# 参照
category = openpyxl.chart.Reference(ws, min_row=2, max_row=2, min_col=3, max_col=6) # カテゴリ(x軸)範囲の参照
data = openpyxl.chart.Reference(ws, min_row=3, max_row=5, min_col=2, max_col=6) # データ範囲の参照
# line chartの作成
chart = openpyxl.chart.LineChart()
chart.add_data(data, titles_from_data=True, from_rows=True) # from_rowsで横向きデータに対応
chart.set_categories(category)
chart.anchor = "B7" # アンカー
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。

「from_rows=True」とすることで横向きのデータを使って線グラフを描画できます。
4-6-4. 散布図
- openpyxl.chart.Reference(ws, min_row, max_row, min_col, max_col)
- openpyxl.chart.ScatterChart()
データは以下のExcelを作成し、本記事では「scatterchart.xlsx」という名前で使うので、同名で保存しておきます。(保存場所は実行するnotebookと同じフォルダ内を想定しています。)

さっそくプログラムでグラフを描画します。
import openpyxl
import openpyxl.chart
import openpyxl.chart.series
wb = openpyxl.load_workbook("scatterchart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# x軸の参照
x_ax = openpyxl.chart.Reference(ws, min_row=3, max_row=11, min_col=2, max_col=2) # x軸範囲の参照
# scatter chartの作成
chart = openpyxl.chart.ScatterChart()
# 1列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=2, max_row=11, min_col=3, max_col=3) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
chart.series.append(data) # chartへの追加
# 2列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=2, max_row=11, min_col=4, max_col=4) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
chart.series.append(data) # chartへの追加
chart.anchor = "E2" # アンカー
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。
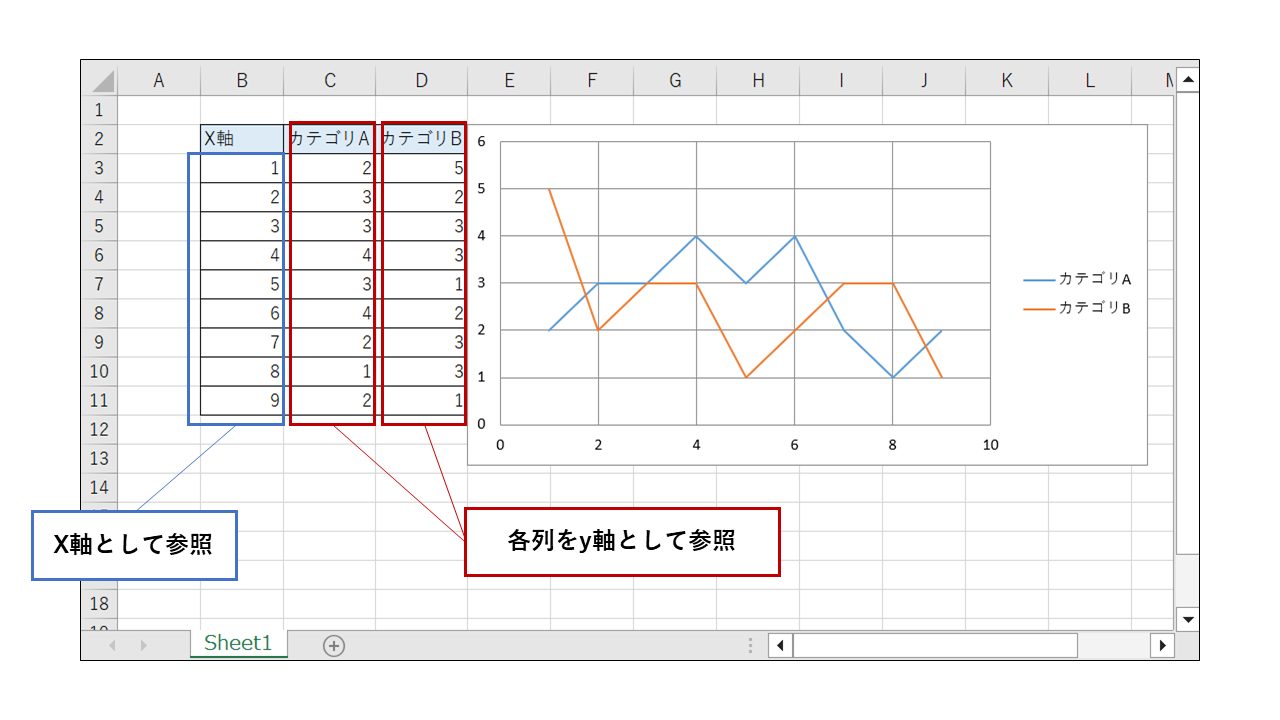
散布図なので、点として描画したい場合は以下のようにします。
import openpyxl
import openpyxl.chart
import openpyxl.chart.series
wb = openpyxl.load_workbook("scatterchart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# x軸の参照
x_ax = openpyxl.chart.Reference(ws, min_row=3, max_row=11, min_col=2, max_col=2) # x軸範囲の参照
# scatter chartの作成
chart = openpyxl.chart.ScatterChart()
# 1列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=2, max_row=11, min_col=3, max_col=3) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
data.graphicalProperties.line.noFill = True # 線を消す
data.marker = openpyxl.chart.marker.Marker('circle') # 点の設定
chart.series.append(data) # chartへの追加
# 2列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=2, max_row=11, min_col=4, max_col=4) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
data.graphicalProperties.line.noFill = True # 線を消す
data.marker = openpyxl.chart.marker.Marker('circle') # 点の設定
chart.series.append(data) # chartへの追加
chart.anchor = "E2" # アンカー
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。

散布図の場合は横向きデータもデータ参照が適切であれば、「from_rows」のような特別な引数を追加する必要はありません。
4-6-5. 棒グラフ
- openpyxl.chart.Reference(ws, min_row, max_row, min_col, max_col)
- openpyxl.chart.BarChart()
データは以下のExcelを作成し、本記事では「barchart.xlsx」という名前で使うので、同名で保存しておきます。(保存場所は実行するnotebookと同じフォルダ内を想定しています。)

さっそくプログラムでグラフを描画します。
import openpyxl
import openpyxl.chart
wb = openpyxl.load_workbook("barchart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# 参照
category = openpyxl.chart.Reference(ws, min_row=3, max_row=6, min_col=2, max_col=2) # カテゴリ(x軸)範囲の参照
data = openpyxl.chart.Reference(ws, min_row=2, max_row=6, min_col=3, max_col=5) # データ範囲の参照
# bar chartの作成
chart = openpyxl.chart.BarChart()
chart.add_data(data, titles_from_data=True)
chart.set_categories(category)
chart.anchor = "B7" # アンカー
ws.add_chart(chart)
wb.save("output.xlsx")
上記の結果は以下です。

棒グラフで横向きのデータを扱う際は線グラフ同様「from_rows=True」を引数とする必要があります。
4-6-6. 複合グラフ
折れ線グラフと散布図など、複数のグラフを重ねる方法です。
データは以下のExcelを作成し、本記事では「multichart.xlsx」という名前で使うので、同名で保存しておきます。(保存場所は実行するnotebookと同じフォルダ内を想定しています。)
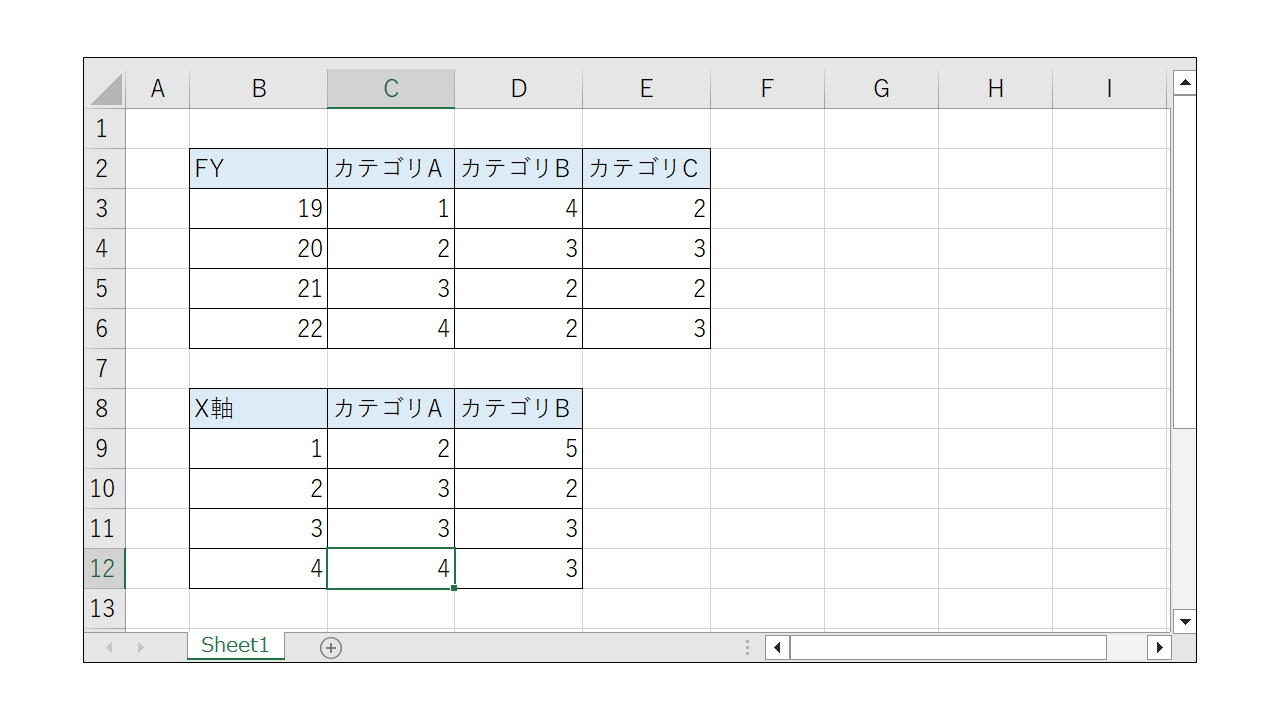
さっそくプログラムでグラフを描画します。
import openpyxl
import openpyxl.chart
import openpyxl.chart.series
wb = openpyxl.load_workbook("multichart.xlsx") # Excelファイルの読み込み
ws = wb["Sheet1"] # シートの取得
# line chartの作成
line_chart = openpyxl.chart.LineChart()
category = openpyxl.chart.Reference(ws, min_row=3, max_row=6, min_col=2, max_col=2) # カテゴリ(x軸)範囲の参照
data = openpyxl.chart.Reference(ws, min_row=2, max_row=6, min_col=3, max_col=5) # データ範囲の参照
line_chart.add_data(data, titles_from_data=True)
line_chart.set_categories(category)
# scatter chartの作成
sc_chart = openpyxl.chart.ScatterChart()
x_ax = openpyxl.chart.Reference(ws, min_row=9, max_row=12, min_col=2, max_col=2) # x軸範囲の参照
# 1列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=8, max_row=12, min_col=3, max_col=3) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
data.graphicalProperties.line.noFill = True # 線を消す
data.marker = openpyxl.chart.marker.Marker('circle') # 点の設定
sc_chart.series.append(data) # chartへの追加
# 2列目のデータ
y_ax = openpyxl.chart.Reference(ws, min_row=8, max_row=12, min_col=4, max_col=4) # y軸範囲の参照
data = openpyxl.chart.Series(y_ax, x_ax, title_from_data=True) # x, y軸を対応付けるためまとめる
data.graphicalProperties.line.noFill = True # 線を消す
data.marker = openpyxl.chart.marker.Marker('circle') # 点の設定
sc_chart.series.append(data) # chartへの追加
# グラフの複合
sc_chart.x_axis = line_chart.x_axis # x軸を線グラフと共有
sc_chart.y_axis = line_chart.y_axis # y軸を線グラフと共有
line_chart += sc_chart # chartを足し算すると重ねられる
line_chart.anchor = "F2" # アンカー
ws.add_chart(line_chart)
wb.save("output.xlsx")
上記の結果は以下です。

グラフの結合は「結合先チャート += 結合チャート」とすることでできます。
その前に、結合するチャートの軸を結合先チャートと共有させておくと見栄えもよくなります。(不要なら実施しなくてよいです)
「結合先チャート += 結合チャート」である必要があります。
「結合先チャート = 結合先チャート + 結合チャート」だとエラーとなります。
4-7. 行/列の操作
行/列の挿入、削除をした場合、「結合セル」と「関数式の参照先」は自動で修正されません。
特に、結合セルに関しては以降の例であるように、値が消滅してしまうため、こちらの操作には注意が必要です。
本記事では「5. おまけスニペット」で「結合セル」と「関数式の参照先」を自動で修正するコードを用意していますので、ご活用ください。
4-7-1. 行の挿入
- ws.insert_rows(行番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.insert_rows(1)
結果は以下のようになります。

上記は最上部に1行挿入しており、その結果レイアウトが崩れています。
レイアウトが崩れている原因は以下になります。
- 行挿入されたとしても、結合セルの範囲情報は更新されず、B2:B3、C2:D2、E2:E3のまま
- 「4-4. 結合セル(Merged Cell)の操作」でも触れたが、結合セルは先頭のセルのデータに準拠する
- その状態で1行追加されると、先頭セル(B2、E2)が空のデータ(スタイルもなし)となったため、IDやAddressという文字が消滅した
4-7-2. 行の削除
- ws.delete_rows(行番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.delete_rows(1)
結果は以下のようになります。

上記は最上部の1行を削除しており、その結果レイアウトが崩れています。
レイアウトが崩れている原因は以下になります。
- 行削除されたとしても、結合セルの範囲情報は更新されず、B2:B3、C2:D2、E2:E3のまま
- 「4-4. 結合セル(Merged Cell)の操作」でも触れたが、結合セルは先頭のセルのデータに準拠する
- その状態で1行削除されると、先頭セルのデータが変わったため、B2、E2は先頭セルのデータ空になり1やTokyoという文字が消滅し、C2は先頭セルのデータが「姓」になったので名が消滅した
4-7-3. 列の挿入
- ws.insert_cols(列番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.insert_cols(1)
結果は以下のようになります。

上記は最左部に1列挿入しており、その結果レイアウトが崩れています。
レイアウトが崩れている原因は以下になります。
- 列挿入されたとしても、結合セルの範囲情報は更新されず、B2:B3、C2:D2、E2:E3のまま
- 「4-4. 結合セル(Merged Cell)の操作」でも触れたが、結合セルは先頭のセルのデータに準拠する
- その状態で1列追加されるため、先頭セルのデータが変わり、NAMEや名という文字が消滅した
4-7-4. 列の削除
- ws.delete_cols(列番号)
以下使用例です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
ws.delete_cols(1)
結果は以下のようになります。

上記は最左部の1列を削除しており、その結果レイアウトが崩れています。
レイアウトが崩れている原因は以下になります。
- 列削除されたとしても、結合セルの範囲情報は更新されず、B2:B3、C2:D2、E2:E3のまま
- 「4-4. 結合セル(Merged Cell)の操作」でも触れたが、結合セルは先頭のセルのデータに準拠する
- その状態で1列削除されるため、先頭セルのデータが変わり、姓やAddressという文字が消滅した
4-8. 条件付書式設定
条件付き書式設定についてしっかりまとまっている記事が別途ありますので、
そちらを参照いただくのが早いです。
- セルの強調表示ルール、上位/下位ルール
- データバー、アイコンセット、カラースケール
5. おまけスニペット
5-1. セル幅自動調整
worksheetを渡すだけで、セル内の文字数に合わせて自動的に幅を調整します。
def adjust_width(ws, min_width=1, max_width=15):
"""
work sheet内のセル幅自動修正
Args:
ws (openpyxl.worksheet.worksheet.Worksheet): 処理したいwork sheet
min_width (int): 最小セル幅
max_width (int): 最大セル幅
"""
for col in ws.columns:
max_length = 0
for cell in col:
if isinstance(cell, openpyxl.cell.cell.MergedCell): # Merged cellは値がないためskip
continue
column_letter = cell.column_letter
value = cell.value
if value is not None:
num_zenkaku = sum([(unicodedata.east_asian_width(s)=="F")|(unicodedata.east_asian_width(s)=="W") for s in str(value)]) # 全角の数
if isinstance(value, float): # floatの場合表示される範囲でセル幅が決まるようにする
value = cell.number_format
if (len(str(value))+num_zenkaku > max_length): # 全角は半角の倍サイズなので、全角の個数分長さを足す
max_length = len(str(value))+num_zenkaku
adjusted_width = max(min_width, min(max_width, (max_length+1)*1.1))
ws.column_dimensions[column_letter].width = adjusted_width
以下は使い方です。
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
ws = wb["test2"]
adjust_width(ws)
5-2. シートの移動
先頭への移動
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
move_sheet = "移動したいシート名"
offset = -wb.sheetnames.index(move_sheet) # 先頭までの個数を取得
wb.move_sheet(move_sheet, offset=offset) # 先頭へのシートの移動
「wb.sheetnames.index(move_sheet)」は先頭からmove_sheetのシート名が何番目にあるかを取得し、それにマイナスをつけることで先頭に移動します。
最後尾への移動
import openpyxl
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
move_sheet = "移動したいシート名"
offset = len(wb.sheetnames)-wb.sheetnames.index(move_sheet)-1 # 最後尾までの個数を取得
wb.move_sheet(move_sheet, offset=offset) # 最後尾へのシートの移動
2シートのスイッチ
import openpyxl
def switch_sheets(wb, sheet1, sheet2):
index_sheet1 = wb.sheetnames.index(sheet1)
index_sheet2 = wb.sheetnames.index(sheet2)
move_1_to_2 = index_sheet2 - index_sheet1 # 1⇒2への移動幅
move_2_to_1 = index_sheet1 - index_sheet2 # 2⇒1への移動幅
# 最初の移動幅は移動方向が正か負かで±1する
if move_1_to_2 > 0:
move_1_to_2 -= 1
elif move_1_to_2 < 0:
move_1_to_2 += 1
wb.move_sheet(move_sheet1, offset=move_1_to_2) # 1⇒2への移動
wb.move_sheet(move_sheet2, offset=move_2_to_1) # 2⇒1への移動
return wb
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
move_sheet1 = "移動したいシート名1"
move_sheet2 = "移動したいシート名2"
wb = switch_sheets(wb, move_sheet1, move_sheet2)
5-3. 別ファイルのシートのコピー
別のファイルのシートをコピーする機能はopenpyxl内では実装されていません。
そのため、以下のように実装します。
参考:https://stackoverflow.com/questions/42344041/how-to-copy-worksheet-from-one-workbook-to-another-one-using-openpyxl
import openpyxl
from copy import copy
def copy_sheet(source_sheet, target_sheet):
copy_cells(source_sheet, target_sheet) # copy all the cel values and styles
copy_sheet_attributes(source_sheet, target_sheet)
def copy_sheet_attributes(source_sheet, target_sheet):
target_sheet.sheet_format = copy(source_sheet.sheet_format)
target_sheet.sheet_properties = copy(source_sheet.sheet_properties)
target_sheet.merged_cells = copy(source_sheet.merged_cells)
target_sheet.page_margins = copy(source_sheet.page_margins)
target_sheet.freeze_panes = copy(source_sheet.freeze_panes)
# set row dimensions
# So you cannot copy the row_dimensions attribute. Does not work (because of meta data in the attribute I think). So we copy every row's row_dimensions. That seems to work.
for rn in range(len(source_sheet.row_dimensions)):
target_sheet.row_dimensions[rn] = copy(source_sheet.row_dimensions[rn])
if source_sheet.sheet_format.defaultColWidth is None:
print('Unable to copy default column wide')
else:
target_sheet.sheet_format.defaultColWidth = copy(source_sheet.sheet_format.defaultColWidth)
# set specific column width and hidden property
# we cannot copy the entire column_dimensions attribute so we copy selected attributes
for key, value in source_sheet.column_dimensions.items():
target_sheet.column_dimensions[key].min = copy(source_sheet.column_dimensions[key].min) # Excel actually groups multiple columns under 1 key. Use the min max attribute to also group the columns in the targetSheet
target_sheet.column_dimensions[key].max = copy(source_sheet.column_dimensions[key].max) # https://stackoverflow.com/questions/36417278/openpyxl-can-not-read-consecutive-hidden-columns discussed the issue. Note that this is also the case for the width, not onl;y the hidden property
target_sheet.column_dimensions[key].width = copy(source_sheet.column_dimensions[key].width) # set width for every column
target_sheet.column_dimensions[key].hidden = copy(source_sheet.column_dimensions[key].hidden)
def copy_cells(source_sheet, target_sheet):
for (row, col), source_cell in source_sheet._cells.items():
target_cell = target_sheet.cell(column=col, row=row)
target_cell._value = source_cell._value
target_cell.data_type = source_cell.data_type
if source_cell.has_style:
target_cell.font = copy(source_cell.font)
target_cell.border = copy(source_cell.border)
target_cell.fill = copy(source_cell.fill)
target_cell.number_format = copy(source_cell.number_format)
target_cell.protection = copy(source_cell.protection)
target_cell.alignment = copy(source_cell.alignment)
if source_cell.hyperlink:
target_cell._hyperlink = copy(source_cell.hyperlink)
if source_cell.comment:
target_cell.comment = copy(source_cell.comment)
wb = openpyxl.load_workbook("test.xlsx") # Excelファイルの読み込み
wb_for_copy = openpyxl.load_workbook("test2.xlsx", data_only=True) # Excelファイルの読み込み
ws_for_copy = wb_for_copy["test2"]
ws = wb.create_sheet(title="test3", index=0) # シートの追加
copy_sheet(ws_for_copy, ws)
print(wb.sheetnames)
wb.save("out.xlsx")
5-4. 行/列の挿入/削除時の結合セル・関数式自動修正
通常の行/列の挿入/削除を実施すると「結合セル」「関数式自動修正」が修正されず、崩れてしまいます。(「4-7. 行/列の操作」で言及)
ここでは自動で修正されるコードを紹介します。
利用データは下記を使います。
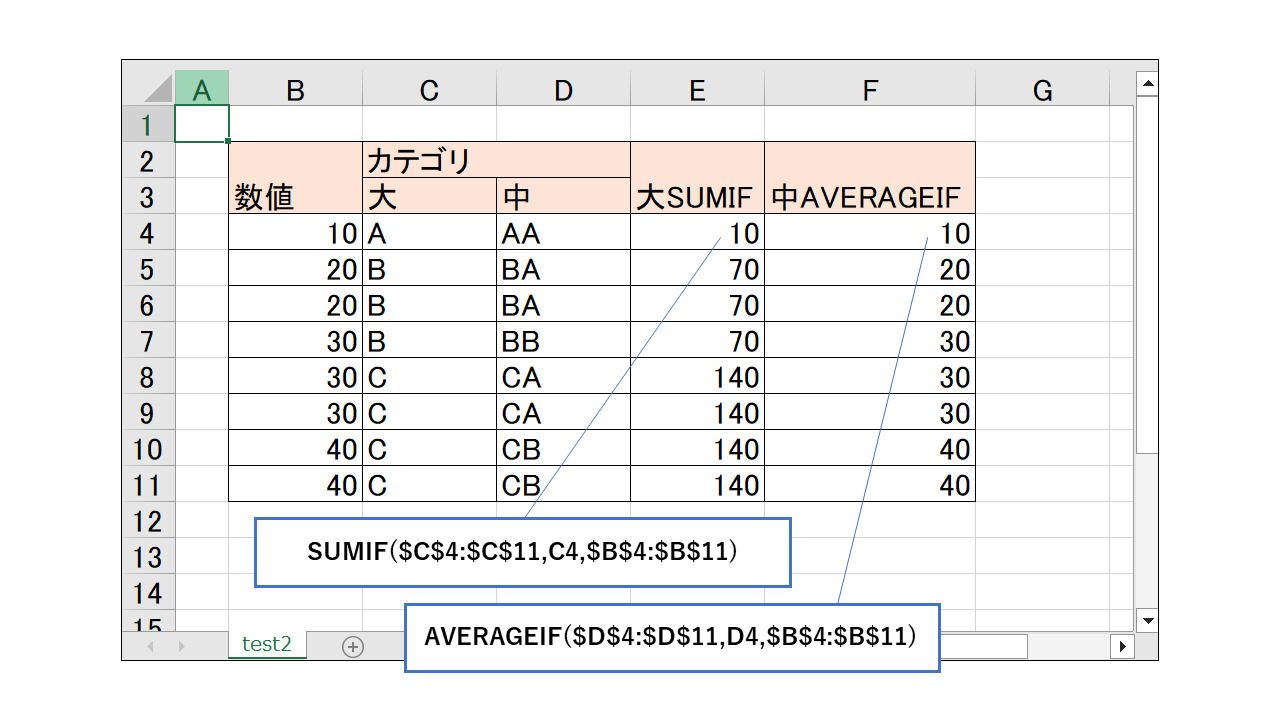
行挿入
コードは以下です。
import openpyxl
import numpy as np
import re
import copy
def insert_rows(ws, row_number):
"""
work sheetから行番号の行に空行を挿入する。
その際、結合セル、関数式の参照を自動修正するようにする
"""
merged_cells = copy.copy(ws.merged_cells.ranges) # 結合セル範囲の取得
# 結合セルは行挿入時に自動で値が消滅する危険があるため、事前に結合解除する
for merged_cell in merged_cells:
ws.unmerge_cells(str(merged_cell))
ws.insert_rows(row_number) # 行挿入
# 結合セルの修正&結合
for merged_cell in merged_cells:
start_row = merged_cell.min_row
end_row = merged_cell.max_row
start_col = merged_cell.min_col
end_col = merged_cell.max_col
if row_number < start_row: # 結合セルの上端が挿入行より下にあるなら、結合範囲を全体的に下にずらす
start_row = start_row+1
end_row = end_row+1
elif start_row == row_number: # 結合セルの上端行と挿入行が同じなら、結合範囲を全体的に下にずらす
start_row = start_row+1
end_row = end_row+1
elif (start_row < row_number)&(row_number < end_row): # 結合セルの上端行と下端行の間に挿入行があるなら、結合範囲の下端を下にずらす
end_row = end_row+1
elif end_row == row_number: # 結合セルの下端行と挿入行が同じなら、結合範囲の下端を下にずらす
end_row = end_row+1
ws.merge_cells(start_row=start_row, start_column=start_col, end_row=end_row, end_column=end_col)
# 関数式の修正
for row in ws:
for cell in row:
if (cell.value is None)or(cell.value==""): continue
if str(cell.value)[0] == "=": # 最初が「=」(=関数式)となっている値のみ処理
row_numbers = np.unique(re.findall(r"\$?[A-Z]+\$?(\d+)", cell.value)).astype('int32') # 関数式にある「A10:B20」のような値の行番号のみ取得する
trans_row = {} # 取得した行番号を修正するための置換辞書を用意
for func_row_number in row_numbers:
if row_number < func_row_number: # 関数式の参照行より上に行挿入している
trans_row[func_row_number] = func_row_number+1 # 修正行番号を辞書に追加
elif row_number == func_row_number: # 関数式の参照行と同じ行に行挿入している
trans_row[func_row_number] = func_row_number+1 # 修正行番号を辞書に追加
for bef_row, af_row in trans_row.items(): # 関数式の修正
cell.value = re.sub(fr"(\$?[A-Z]+\$?){bef_row}", lambda x: x.group(1)+str(af_row), cell.value)
wb = openpyxl.load_workbook("test2.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
insert_rows(ws, 6)
wb.save("output.xlsx")
結果は以下です。
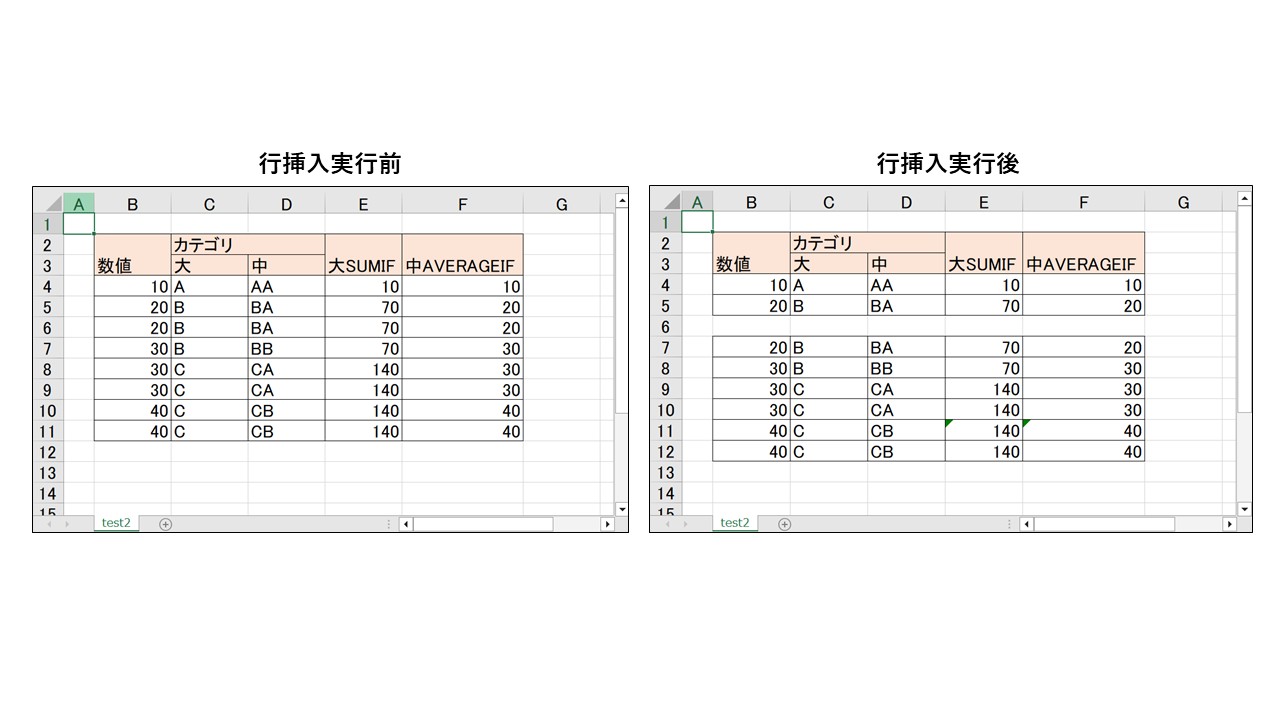
行挿入してもセルの結合や関数の範囲修正が自動でされます。
行削除
コードは以下です。
import openpyxl
import numpy as np
import re
import copy
def delete_rows(ws, row_number):
"""
work sheetから行番号の行を削除する。
その際、結合セル、関数式の参照を自動修正するようにする
"""
merged_cells = copy.copy(ws.merged_cells.ranges) # 結合セル範囲の取得
# 結合セルは行削除時に自動で値が消滅する危険があるため、事前に結合解除する
for merged_cell in merged_cells:
ws.unmerge_cells(str(merged_cell))
ws.delete_rows(row_number) # 行削除
# 結合セルの修正&結合
for merged_cell in merged_cells:
start_row = merged_cell.min_row
end_row = merged_cell.max_row
start_col = merged_cell.min_col
end_col = merged_cell.max_col
if row_number < start_row: # 結合セルの上端が削除行より下にあるなら、結合範囲を全体的に上にずらす
start_row = start_row-1
end_row = end_row-1
elif start_row == row_number: # 結合セルの上端行と削除行が同じなら、結合範囲を全体的に上にずらす
start_row = start_row-1
end_row = end_row-1
elif (start_row < row_number)&(row_number < end_row): # 結合セルの上端行と下端行の間を行削除するなら、結合範囲の下端を上にずらす
end_row = end_row-1
elif end_row == row_number: # 結合セルの下端行と削除行が同じなら、結合範囲の下端を上にずらす
end_row = end_row-1
ws.merge_cells(start_row=start_row, start_column=start_col, end_row=end_row, end_column=end_col)
# 関数式の修正
for row in ws:
for cell in row:
if (cell.value is None)or(cell.value==""): continue
if str(cell.value)[0] == "=": # 最初が「=」(=関数式)となっている値のみ処理
row_numbers = np.unique(re.findall(r"\$?[A-Z]+\$?(\d+)", cell.value)).astype('int32') # 関数式にある「A10:B20」のような値の行番号のみ取得する
trans_row = {} # 取得した行番号を修正するための置換辞書を用意
for func_row_number in row_numbers:
if row_number < func_row_number: # 関数式の参照行より上の行を削除している
trans_row[func_row_number] = func_row_number-1 # 修正行番号を辞書に追加
elif row_number == func_row_number: # 関数式の参照行と同じ行を削除している
trans_row[func_row_number] = func_row_number-1 # 修正行番号を辞書に追加
for bef_row, af_row in trans_row.items(): # 関数式の修正
cell.value = re.sub(fr"(\$?[A-Z]+\$?){bef_row}", lambda x: x.group(1)+str(af_row), cell.value)
wb = openpyxl.load_workbook("test2.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
delete_rows(ws, 6)
wb.save("output.xlsx")
結果は以下です。
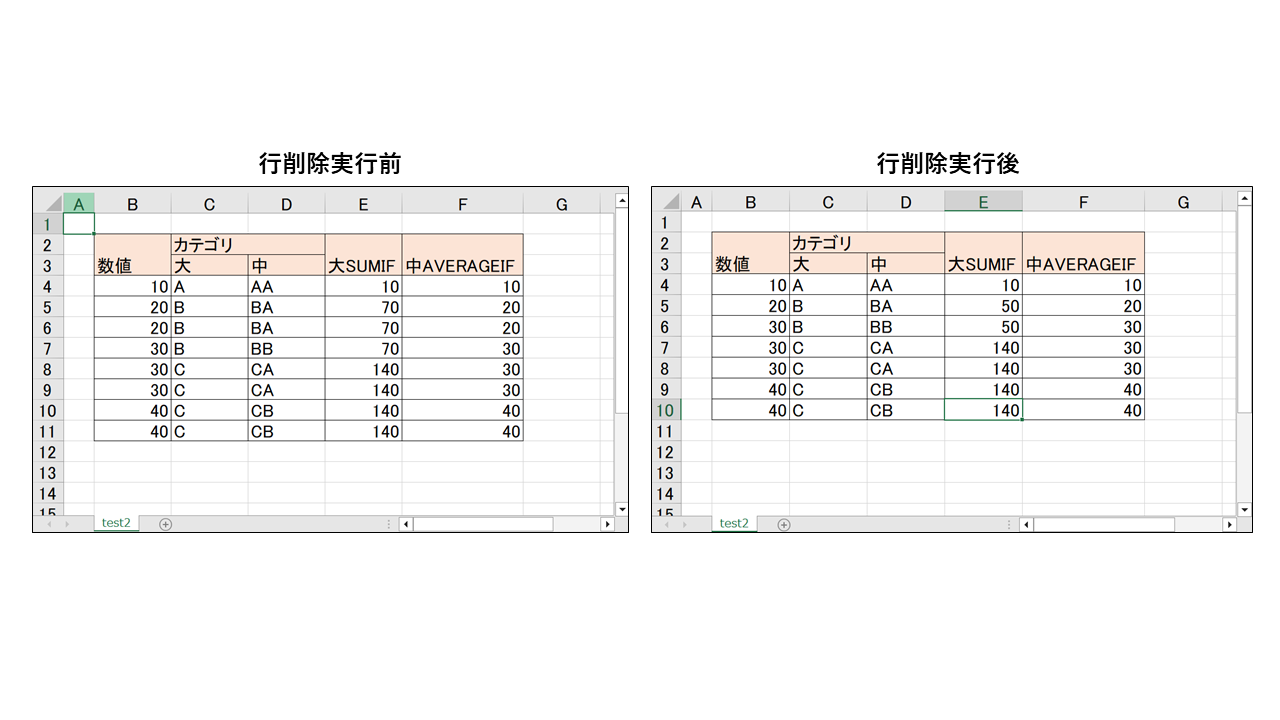
行削除してもセルの結合や関数の範囲修正が自動でされます。
列挿入
コードは以下です。
import openpyxl
import numpy as np
import re
import copy
def insert_cols(ws, col_number):
"""
work sheetから列番号の列に空列を挿入する。
その際、結合セル、関数式の参照を自動修正するようにする
"""
merged_cells = copy.copy(ws.merged_cells.ranges) # 結合セル範囲の取得
# 結合セルは列挿入時に自動で値が消滅する危険があるため、事前に結合解除する
for merged_cell in merged_cells:
ws.unmerge_cells(str(merged_cell))
ws.insert_cols(col_number) # 列挿入
# 結合セルの修正&結合
for merged_cell in merged_cells:
start_row = merged_cell.min_row
end_row = merged_cell.max_row
start_col = merged_cell.min_col
end_col = merged_cell.max_col
if col_number < start_col: # 結合セルの左端列が挿入列より右にあるなら、結合範囲を全体的に右にずらす
start_col = start_col+1
end_col = end_col+1
elif start_col == col_number: # 結合セルの左端列と挿入列が同じなら、結合範囲を全体的に右にずらす
start_col = start_col+1
end_col = end_col+1
elif (start_col < col_number)&(col_number < end_col): # 結合セルの左端列と右端列の間に挿入列があるなら、結合範囲の右端を右にずらす
end_col = end_col+1
elif end_col == col_number: # 結合セルの右端列と挿入列が同じなら、結合範囲の右端を右にずらす
end_col = end_col+1
ws.merge_cells(start_row=start_row, start_column=start_col, end_row=end_row, end_column=end_col)
# 関数式の修正
for row in ws:
for cell in row:
if (cell.value is None)or(cell.value==""): continue
if str(cell.value)[0] == "=": # 最初が「=」(=関数式)となっている値のみ処理
col_letters = np.unique(re.findall(r"\$?([A-Z]+)\$?\d+", cell.value)) # 関数式にある「A10:B20」のような値のアルファベットのみ取得する
trans_col_letters = {} # 取得したアルファベットを修正するための置換辞書を用意
for col_letter in col_letters:
func_col_number = openpyxl.utils.column_index_from_string(col_letter) # アルファベットを番号化
if col_number < func_col_number: # 関数式の参照列より左に列挿入している
trans_col_letters[col_letter] = openpyxl.utils.get_column_letter(func_col_number+1) # 修正アルファベットを辞書に追加
elif col_number == func_col_number: # 関数式の参照列と同じ列に列挿入している
trans_col_letters[col_letter] = openpyxl.utils.get_column_letter(func_col_number+1) # 修正アルファベットを辞書に追加
for bef_col, af_col in trans_col_letters.items(): # 関数式の修正
cell.value = re.sub(fr"(\$?){bef_col}(\$?\d+)", lambda x: x.group(1)+af_col+x.group(2), cell.value)
wb = openpyxl.load_workbook("test2.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
insert_cols(ws, 4)
wb.save("output.xlsx")
結果は以下です。
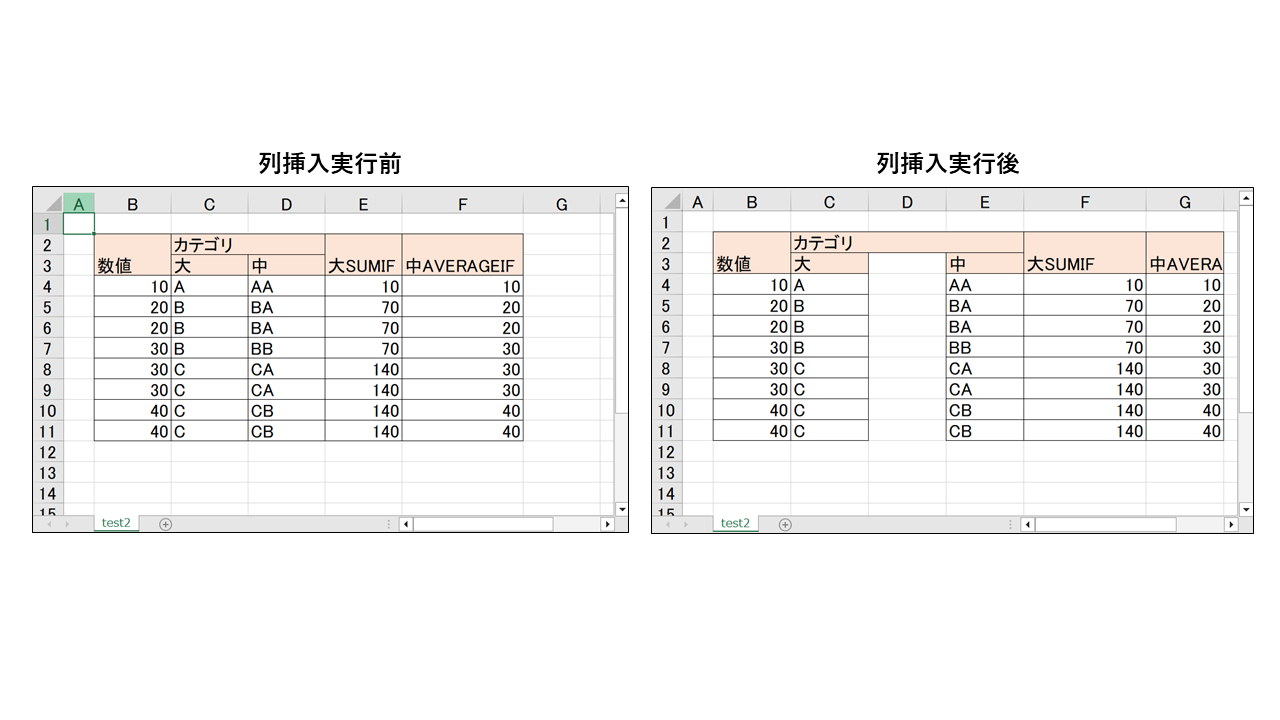
列挿入してもセルの結合や関数の範囲修正が自動でされます。
列削除
コードは以下です。
import openpyxl
import numpy as np
import re
import copy
def delete_cols(ws, col_number):
"""
work sheetから列番号の列を削除する。
その際、結合セル、関数式の参照を自動修正するようにする
"""
merged_cells = copy.copy(ws.merged_cells.ranges) # 結合セル範囲の取得
# 結合セルは列削除時に自動で値が消滅する危険があるため、事前に結合解除する
for merged_cell in merged_cells:
ws.unmerge_cells(str(merged_cell))
ws.delete_cols(col_number) # 列削除
# 結合セルの修正&結合
for merged_cell in merged_cells:
start_row = merged_cell.min_row
end_row = merged_cell.max_row
start_col = merged_cell.min_col
end_col = merged_cell.max_col
if col_number < start_col: # 結合セルの左端列が削除列より右にあるなら、結合範囲を全体的に左にずらす
start_col = start_col-1
end_col = end_col-1
elif start_col == col_number: # 結合セルの左端列と削除列が同じなら、結合範囲を全体的に左にずらす
start_col = start_col-1
end_col = end_col-1
elif (start_col < col_number)&(col_number < end_col): # 結合セルの左端列と右端列の間に削除列があるなら、結合範囲の右端を左にずらす
end_col = end_col-1
elif end_col == col_number: # 結合セルの右端列と削除列が同じなら、結合範囲の右端を左にずらす
end_col = end_col-1
ws.merge_cells(start_row=start_row, start_column=start_col, end_row=end_row, end_column=end_col)
# 関数式の修正
for row in ws:
for cell in row:
if (cell.value is None)or(cell.value==""): continue
if str(cell.value)[0] == "=": # 最初が「=」(=関数式)となっている値のみ処理
col_letters = np.unique(re.findall(r"\$?([A-Z]+)\$?\d+", cell.value)) # 関数式にある「A10:B20」のような値のアルファベットのみ取得する
trans_col_letters = {} # 取得したアルファベットを修正するための置換辞書を用意
for col_letter in col_letters:
func_col_number = openpyxl.utils.column_index_from_string(col_letter) # アルファベットを番号化
if col_number < func_col_number: # 関数式の参照列より左を列削除している
trans_col_letters[col_letter] = openpyxl.utils.get_column_letter(func_col_number-1) # 修正アルファベットを辞書に追加
elif col_number == func_col_number: # 関数式の参照列と同じ列を列削除している
trans_col_letters[col_letter] = openpyxl.utils.get_column_letter(func_col_number-1) # 修正アルファベットを辞書に追加
for bef_col, af_col in trans_col_letters.items(): # 関数式の修正
cell.value = re.sub(fr"(\$?){bef_col}(\$?\d+)", lambda x: x.group(1)+af_col+x.group(2), cell.value)
wb = openpyxl.load_workbook("test2.xlsx") # Excelファイルの読み込み
ws = wb["test2"] # シートの取得
delete_cols(ws, 1)
wb.save("output.xlsx")
結果は以下です。
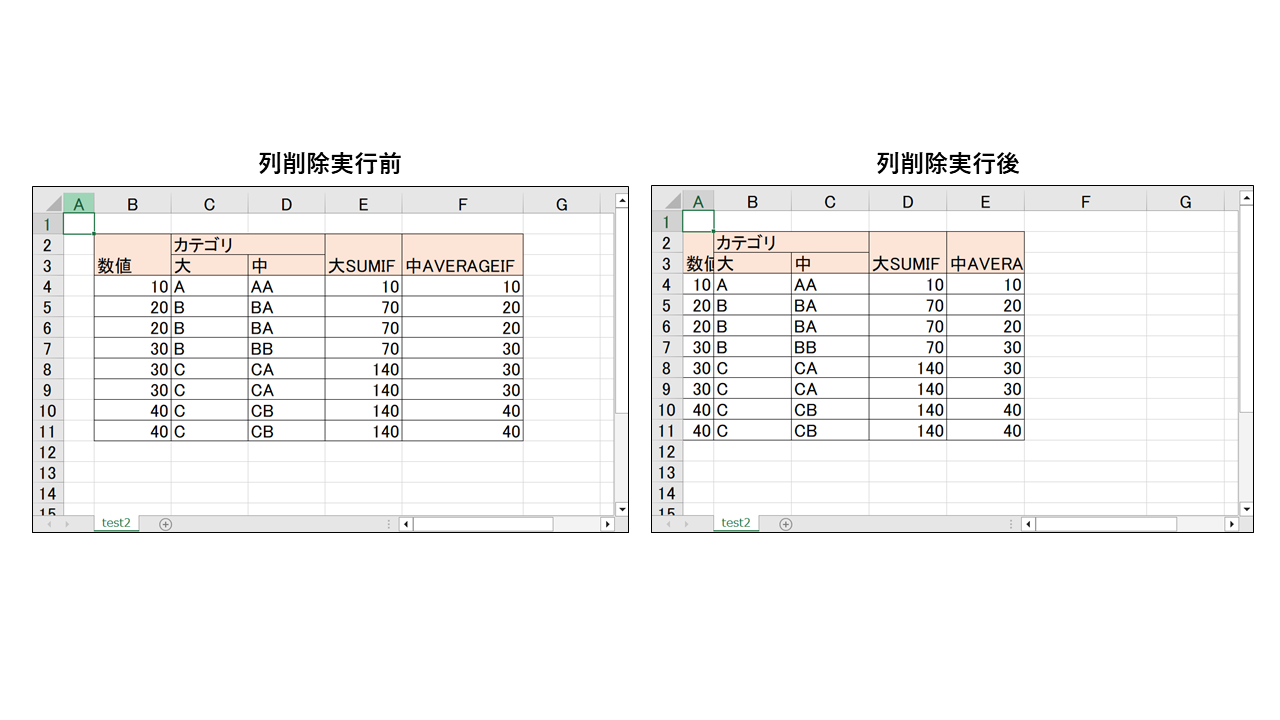
列削除してもセルの結合や関数の範囲修正が自動でされます。
まとめ
本記事ではopenpyxlについての操作方法をまとめました。
弊社でもpythonを使った支援は増えてきており、本記事のような技術を使って業務効率化を実施しています。
皆さんがレポーティング作業を自動化し、今以上に分析へ力や時間を注げるようになれると幸いです。
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。