今回はマルコフ解析を用いて文章を生成することに挑戦してみた。実装を行うので前提として何らかのプログラミング言語の経験が必要である。
マルコフ過程とマルコフ連鎖
マルコフ過程とはロシアの数学者であるアンドレイ・マルコフ(1856〜1922)が考案した確率過程のことである。その内容は「未来に起こる事象の確率が、現在の状態のみに依存し、過去の状態に一切依存しない。」(デジタル大辞泉「マルコフ過程」参考)というものである。
また、マルコフ過程のもとで未来の状態が決まるようなモデルのことをマルコフ連鎖という。
文章のマルコフ解析
概要
英語の文章をマルコフ連鎖を用いて解析(以下、マルコフ解析とする)するときのモデルの一例を示してみる。
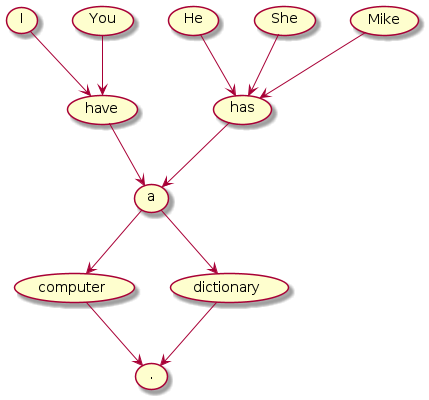
見ての通り、上の図は単語またはシンボルをノードとした有向グラフとなっている。ここで、このグラフで各々のノードは状態を表しており、あるノードから別のノードに向かうエッジをランダムに一つ選ぶとき、現在のノードの状態にのみ依存し、過去にいたノードの状態には一切依存していないということに留意してほしい。
実際に上のグラフでエッジの入次数が0となっているノード("I"、"You"、"He"、"She"、"Mike")のいずれかから出発して、終端子となっているノード(".")に至るまで矢印に従ってノードをランダムに進み、そこで通ったノードに書かれていた単語を順番に並べると正しい文章になることが分かるであろう。
このロジックを用いればおおよそ文法的に正しい文章を生成できそうである。
実装
今回は、上の例のように単語をノードとした有向グラフを用いて解析を行う。具体的にはValueがSet(Python3ではset)であるHashMap(Python3ではdict)を用いることによりグラフを表現する。(Setに格納されるのは次に遷移することができる単語郡)
言語はPython3を用いて実装を進める。ただし、特別なライブラリを用いたりせずプリミティブな要素のみを利用するため他の言語を用いても容易に実装することができるであろう。
また、グラフを構築するためのデータセットとして不思議の国のアリス(Project GutenbergよりAlice's Adventures in Wonderland by Lewis Carroll https://www.gutenberg.org/ebooks/11 )とシャーロック・ホームズ(Project GutenbergよりThe Adventures of Sherlock Holmes by Arthur Conan Doyle https://www.gutenberg.org/ebooks/1661 )を利用させていただく。それぞれのファイルはプログラムを配置したディレクトリと同じディレクトリに"alice.txt"、"sherlock.txt"というファイル名で配置する。
実装は以下のとおりだ。
import re
import random
import os
class MarkovModel:
# Delimiters
SPLIT_CHARS = "\n\s\t\r\f"
# Strip characters
STRIP_CHARS = "\"'()[]{}"
# End of sentences
EOS_CHARS = ".!?"
# Symbols to recognize as a word
SYMBOL_CHARS = ",;:" + EOS_CHARS
__model = dict()
def construct(self, filename):
"""
Construct a model from the specified dataset.
"""
words = self.__read_words(filename)
self.__add_words(words)
def __read_words(self, filename):
"""
Returns a word list from a file with the specified path.
"""
buf = ""
with open(filename, encoding="ascii", errors="ignore") as istream:
buf = istream.read()
return self.__extract_words(buf)
def __extract_words(self, buf):
"""
Extracts words from the specified string and returns them as a list.
"""
chunks = re.split(f"[{self.SPLIT_CHARS}]", buf)
words = list()
for chunk in chunks:
chunk = chunk.strip(self.STRIP_CHARS).lower()
if len(chunk) > 0 and chunk[-1] in self.SYMBOL_CHARS:
words.append(chunk[:-1])
words.append(chunk[-1])
else:
words.append(chunk)
words = filter(lambda word: len(word) > 0, words)
return list(words)
def __add_words(self, words):
"""
Add the specified word list to the model.
"""
for i in range(len(words) - 1):
if not words[i] in self.EOS_CHARS:
self.__add_word(words[i], words[i + 1])
def __add_word(self, key, word):
"""
Connect 'key' and 'word' with an edge extending from 'key'.
"""
if key in self.__model:
self.__model[key].append(word)
else:
self.__model[key] = [word]
def clear(self):
"""
Clear the model.
"""
self.__model.clear()
def generate_sentence_at_random(self, current_word):
"""
Randomly generate sentence with 'current_word' as first word.
"""
current_word = current_word.lower()
words = list()
while current_word in self.__model:
words.append(current_word)
current_word = random.choice(list(self.__model[current_word]))
words.append(current_word)
return ' '.join(words)
def __str__(self):
"""
For debugging.
"""
chunks = list()
for k, v in self.__model.items():
chunks.append(f"{k}:[{','.join(v)}]")
return os.linesep.join(chunks)
if __name__ == "__main__":
model = MarkovModel()
model.construct('alice.txt')
model.construct('sherlock.txt')
for i in range(6):
print(model.generate_sentence_at_random('i'))
詳しくはプログラムを読んで理解してほしい。実行してみると以下のような6つの文章が帰ってきた。
i beg that you mean , heres another question the cat .
i must have asked him credit card donations to france , what i should or not a small streets which lined with the work appears from grosvenor square which i shall certainly speak severely tried to reason for this mean that no one crazy !
i see no doubt of the official detective in in one side of making such as well !
i felt quite forgot that i think i turned with cotton wadding and good-night .
i saw the duchess , too , you scoundrel .
i shall be connected with extras ?
この結果はランダムに変わるので必ずしも上のようにはならないが、どのような文が出力されても文法的な側面に焦点を当ててみるとおおよそ正しいことが分かるであろう。
意味的な部分はどうだろうか?上の出力をGoogle翻訳( https://translate.google.co.jp/?hl=ja )にかけて日本語訳してみると以下のような文章が帰ってきた。
私はあなたが意味することをお願いします、ここに猫の別の質問があります。
私は彼にフランスへのクレジットカードの寄付を頼んだに違いありません、私がすべきかどうかは、作品が並ぶ小さな通りがグロブナースクエアから現れます。
作り方の片側にもオフィシャル探偵に疑いの余地はありません!
綿の詰め物とおやすみで向きを変えたと思うのをかなり忘れてしまいました。
私も公爵夫人を見ました、あなたは悪党です。
私はエクストラと接続しますか?
意味は不明である。今回書いた解析プログラムではあくまでも単語間の関係しか解析することができないため意味に関しては全く持って生半可な文章が生成される。しかし、何度も文章を生成していけば文法が正しくてかつ意味も通る文章が生成されることも珍しくないであろう。
最後に
今回はマルコフ解析を用いて簡単な英語の文章を生成してみた。もちろんマルコフ解析は文章の解析だけではなく他の幅広い分野にも応用できる。また、このアルゴリズムを拡張するともっと精度が高い文章を生成することもできそうだ。このように手軽でかつ拡張性も高く面白いアルゴリズムだと私は感じた。今後は生成される文章の精度を向上させたり、他の分野でこのアルゴリズムを適用してみたりといったことに挑戦してみたいと考えている。
最後にここまで読んでくださった読者の方に感謝を申し上げてこの記事を閉じたいと思う。
参考
・ThinkPython:How to Think Like a Computer Scientist(2nd Edition) 日本語訳
https://cauldron.sakura.ne.jp/thinkpython/