前回に引き続き、タイトル記事の翻訳です。
尚、著者のJannik Zürn氏には、許可を頂き翻訳を掲載させて頂いております。
この記事の目的は、ニューラルネット、具体的には完全畳み込みニューラルネットが、事例から学習することで障害物の周りの流体の流れを学習する方法の概要を説明することです。
このシリーズは3つのパートに分かれています。
パート1:CFDに対するデータ駆動型の手法
パート2:技術的詳細
パート3:結果
パート1では、CFDへのデータ駆動型アプローチの概要と、それを機能させるために必要な手順を学びました。 後半では、CFDへのデータ駆動型アプローチの2つの重要なステップであるネットワークアーキテクチャと精度測定の技術的詳細を調査しました。
この最後のパートでは、最初に必要なトレーニングサンプルの数と、ニューラルネットの最も有望なタイプの活性化関数について説明します。 次に、ニューラルネットによる結果の視覚化を確認し、最後に、データ駆動型アプローチの性能について説明します。
パラメータスタディ
大量のシミュレーションデータのサンプルを生成することは、CFDへのデータ駆動型アプローチのうち計算負荷の高いサブタスクです。 この計算負荷のため、最適な量の訓練データを見つけることが重要です。 訓練データは十分に大きくして、ニューラルネットがまだ見ぬジオメトリに一般化できるようにして、パラメーターの過学習を回避する必要がありますが、同時に不当に大きくしてはいけません(訓練データの生成に時間がかかりすぎるため)。
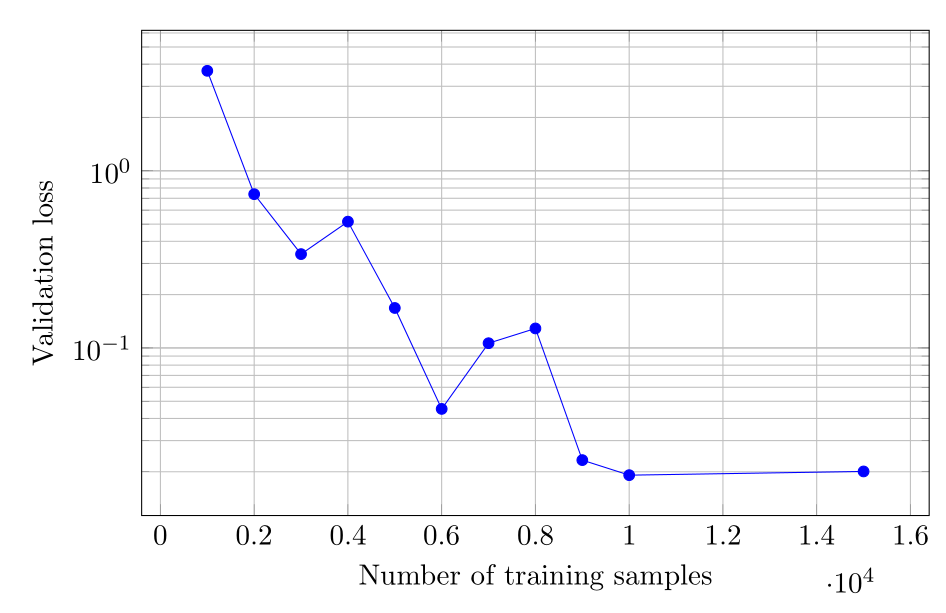
上の図は、訓練データの数を変化させたときの15000の訓練ステップ後の最終のバリデーションロスを視覚化しています。 5000未満の訓練データのサイズでは、最終のバリデーションロスは0.1を超えますが、訓練用サンプルの数が増えると、最終損失は0.02に収束します。 訓練用サンプルの数を10000を超えて増やしても、最終のバリデーションロスはさらに減少しません。 検証用データと訓練データの両方で最小限の損失を得るには、10000個の訓練データで十分です。
活性化関数への特定の選択の影響を判断するために、4つの活性化関数タイプが検証されました。
・指数線形ユニット(ELU)
・連結指数線形ユニット(連結ELU)
・整流線形ユニット(ReLU)
・連結整流線形ユニット(Concat Relu)
次の図は、4つのテスト済み検証機能の訓練途中のステップ数についてバリデーションロスの推移を関数として示しています。
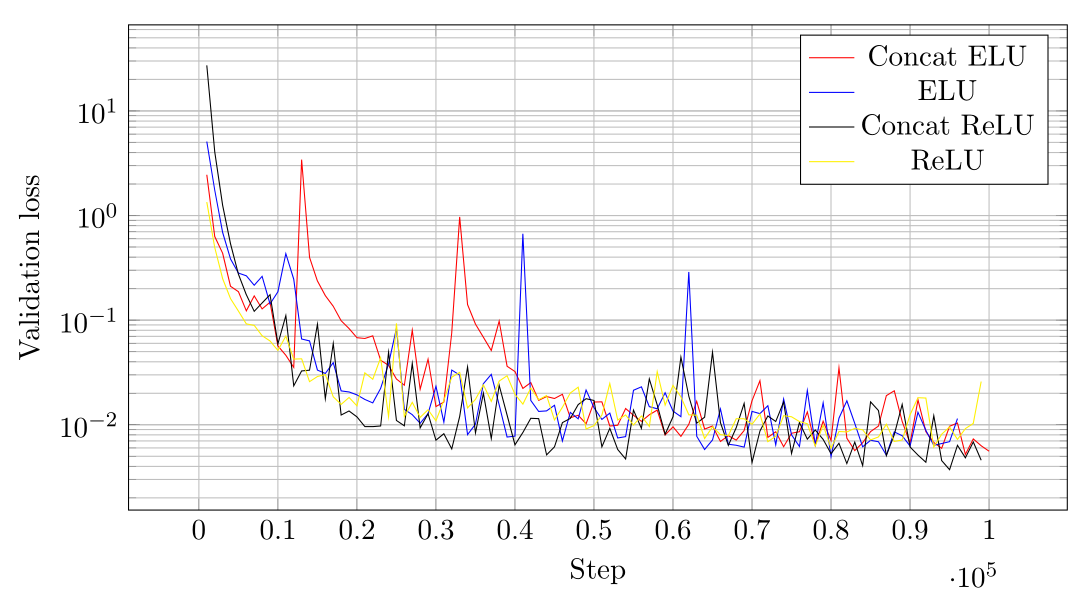
特にConcat ELUおよびELUを使用したトレーニングの場合、訓練の初期段階で、バリデーションロスの著しいスパイクが発生します。 スパイクは、Adamオプティマイザーによるミニバッチ勾配降下の避けられない結果です。 いくつかのミニバッチには偶然に不幸なデータがあり、バリデーションロスのスパイクを引き起こします。 したがって、バリデーションロスの小さなスパイクは、評価されたすべてのタイプの活性化関数に存在します。
ReLUの活性化関数が選択されたのは、訓練途中のバリデーションロスに大きなスパイクが存在しないことと、訓練の収束に向かって全体的に最小のバリデーションロスが約0.007であったためです。
結果
次の表では、64 x 64、128 x 128、および256 x 256セルの格子の解像度について、ニューラルネットの最終のバリデーションロスと精度がリストされています。
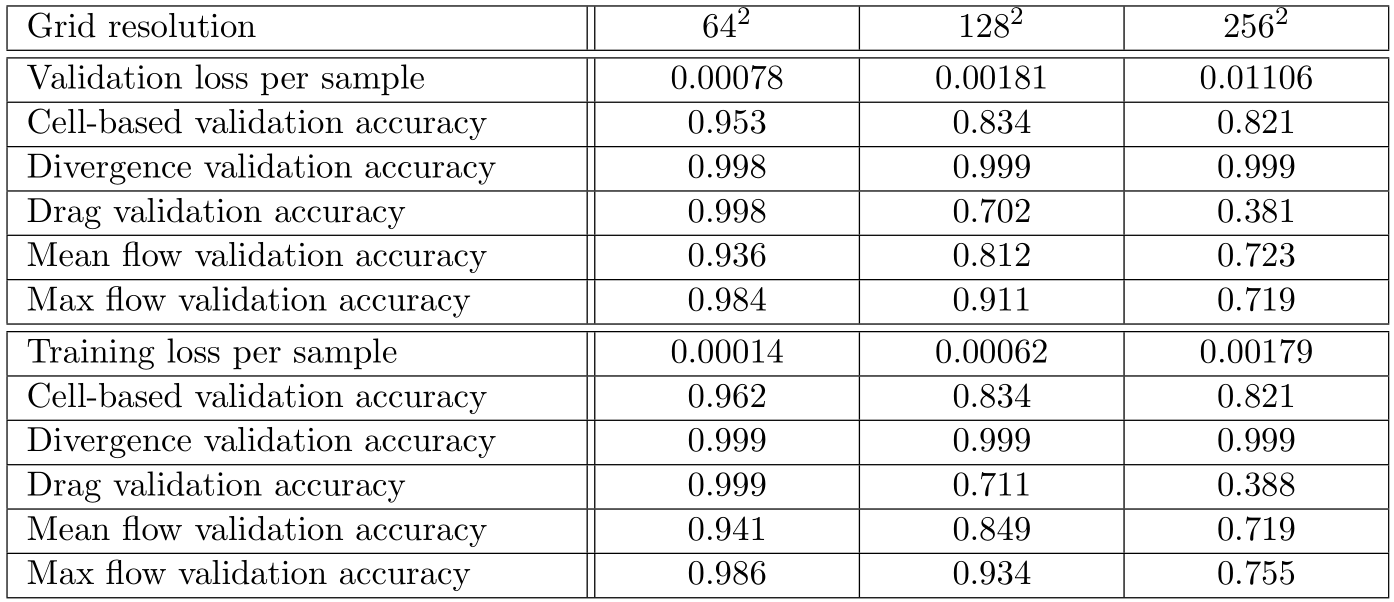
全体的に、ロスは格子の解像度で正規化されていないため、格子の解像度の増加に伴ってロスの値は増加します。したがって、格子の解像度が高いとロスが大きくなります。 64 x 64セルの格子の解像度の場合、測定されたすべての精度は93%を超える高い値になります。特に、テストされたすべての格子の解像度で発散精度が非常に高くなります。したがって、ニューラルネットは、特定のボクセル化された障害物のジオメトリに対して、NSEの物理的に賢明な解決策を予測します。セルベース、抵抗ベース、および最大流量ベースの精度は、格子の解像度の増加とともに大幅に低下します。この観測の原因の1つは、高い格子の解像度を使用する場合、ニューラルネットが最低の格子の解像度で測定された精度と同様の精度を達成できるようにするために、決定された必要数の10000を超える訓練用サンプルが必要になることです。より多くの訓練データにより、ニューラルネットは、より高い格子の解像度で訓練データに含まれるより詳細なシミュレーションデータをよりよく近似できます。格子のサイズが大きくなると予測精度が低下するもう1つの理由は、ネットワークアーキテクチャです。格子のサイズが大きいと、フローに含まれる機能が多くなり、格子のサイズが小さい場合の機能と同じ精度でネットワークで推定することはできません。ニューラルに残差ブロックを追加すると、予測精度が向上する場合があります。
以下の2つの画像は、グラウンドトゥルースのベクトル場(シミュレーションで取得)とニューラルネットの予測(CFDへのデータ駆動型アプローチで取得)を示しています。しかし、どれがどれでしょうか?
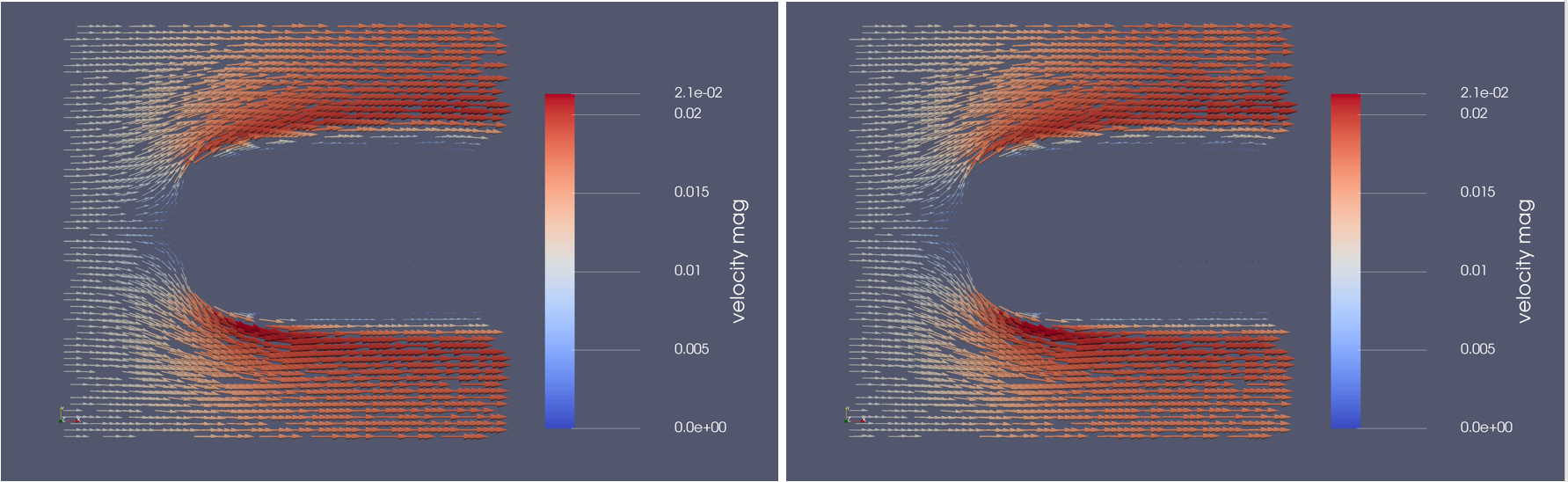
視覚的には、シミュレーションとデータ駆動型予測のベクトル場は、すべての格子の解像度で互いに大きく異なることはありません。各セルの絶対誤差(下図に示す)は、シミュレーションと予測の間に大きな差が見られるシミュレーション内のドメインを示しています。流体の流れがオブジェクトにぶつかる前部に沿った線は、シミュレーションと予測されたすべての解像度の予測の間に最も大きな不一致があります。この振る舞いは、流体が自由流動速度からゼロに減速する際の障害物前面に沿った高速勾配によって説明できます。ニューラルネットは、入力の大きな勾配が優先する場合に困難を抱える傾向があります。高い絶対誤差は、流体の流れのx方向のy軸に沿って高い勾配がある障害物の背後のスリップストリームの領域の境界でも発生します。これは、すべての格子の解像度に等しく当てはまります。障害物自体に追加の予測エラーが発生します。ここで、流体の流速は定義ごとにゼロです。ここで、ニューラルネットは、流体の流れをゼロに完全に予測することはできません。ただし、この誤差は、高速勾配の領域で発生する誤差よりも小さくなります。

ブロック形状の予測アーティファクトは、障害物の背後のスリップストリームの外側の出口に近いフロー領域で支配的です。 これらのアーティファクトは、ブロックが1つの畳み込み層から次の層への視覚入力領域に対応する可能性があるため、ニューラルネットの畳み込みフィルターによって引き起こされる可能性があります。 訓練データの数が不十分であるか、訓練途中のニューラルネットの重みの収束が不十分であることが、アーティファクトの原因である可能性があります。 入口付近の流れ領域および障害物のスリップストリームでは、低い予測誤差が支配的です。 これは、これらが均一な流速の領域であるという事実によって説明できます。 入口付近では、流速は入口境界条件速度に非常に近く、スリップストリーム内の障害物の背後では流速はほぼゼロです。 これらの単純な流れの特性は、ニューラルネットワークで簡単に学習できます。
性能
CFDへのデータ駆動型アプローチの利点を評価するには、最先端のCFDソルバーに関するアプローチの精度だけでなく、提起された問題の解決策を導き出すのにかかる時間も決定する必要があります。 。
外部の2次元シミュレーションデータセットの10000サンプルの作成には、使用されたマシンで約13時間かかります。 データセットの作成時間に加えて、ニューラルネットのトレーニング期間を考慮する必要があります。 次の表は、さまざまなグリッド解像度の訓練に要す期間と、ニューラルデータがシミュレーションデータセットで訓練された後の1秒あたりのシミュレーション予測数、およびOpenFOAMシミュレーションと比較した速度上昇度合を示しています。

シミュレーションデータセットに最小数の10000サンプルを作成するには、特に3次元シミュレーションの場合、かなりの時間がかかります。 ニューラルネットのj訓練プロセスは、必要な計算能力の点でも同様に要求が厳しく、ニューラルネットがデータセットで十分に訓練されるまで、同様の時間がかかります。 十分なサンプルで必要なデータセットを作成することは、CFDへのデータ駆動型アプローチの実質的な計算オーバーヘッドを構成すると結論付けることができます。
ただし、ニューラルネットがシミュレーションデータセットで訓練されると、CFDへの従来のシミュレーションベースのアプローチと比較して大幅な高速化が見られます。 入力格子セルの数が少ないため、解像度が最も低い格子では最大の高速化が得られます。 256 x 256格子セルで達成された約57の最小の高速化でさえ、最先端のSimpleFoam CFDソルバーよりも1倍以上高速です。 CFDへのデータ駆動型アプローチのシミュレーション速度により、テストされたすべてのシミュレーション設定のリアルタイムの流れ場の予測が可能になります。 最低の予測率は、流体の流れのリアルタイム予測を可能にするのに十分高速です。
まとめ
提案されたCFDへのデータ駆動型アプローチの目的は、ニューラルネットが以前に訓練されたシミュレーションの設定で、従来のシミュレーション駆動型CFDを上回ることです。訓練用サンプルの作成とそれらのニューラルネットの訓練にはかなりの計算オーバーヘッドがありますが、これらの計算はユーザーの操作なしでオフラインで実行できます。 したがって、エンジニアの待ち時間を必要としません。 既存のCFDの領域の近似されたシミュレーションモデルと比較して、ニューラルネットにより、速度場全体の効率的な推定が可能になります。 さらに、設計者およびエンジニアは、余分な低次元サロゲートモデルを訓練することなく、CNN近似モデルを設計スペース探索アルゴリズムに直接適用できます。
流れの予測の結果は、格子の解像度が増加すると、予測の全体的な精度が低下することを示しています。 この望ましくない動作の理由は、訓練用サンプルの不足とネットワーク設計にあります。 訓練用サンプルの数とネットワークアーキテクチャは、低解像度の格子サイズと2次元の流体データに対して提案されたニューラルネットを訓練するには十分ですが、格子にエンコードされるより多くの流体情報を含むより大きな格子サイズにはこの設定は不十分です。 より多くの訓練用サンプルは、より多くのパラメーターを備えたより深いまたはより広いネットワークアーキテクチャを学習するための幅広い流れ場を提供し、サンプルのより詳細な流れのパターンを見つけることを約束し、予測精度を潜在的に向上させます。
データ駆動型のアプローチは、設計調査の初期段階でリアルタイムの設計反復のための即時フィードバックを提供できます。 すぐにフィードバックできるため、エンジニアやデザイナーは、クリエイティブなプロセスを中断することなく、クリエイティブな設計プロセス中に設計を探索できます。 テストされた最高のグリッド解像度の0.01秒を大幅に下回る推論時間は、人間の脳の待ち時間のしきい値を下回っています。
CFDへのデータ駆動型アプローチは、既存のCFDソフトウェアの代替として意図されたものではありません。 ただし、製品開発プロセスの最初のステップのツールとしては頷けます。 次のステップでは、高性能シミュレーション駆動型CFDを使用して、CFDへのデータ駆動型アプローチの結果をさらに改良し、わずかな誤差で定量的な製品シミュレーションデータを保証します。 機械学習ベースのCFDへのアプローチの主張は、物理ベースの数値ソルバーを完全に置き換えることではなく、高解像度CFDシミュレーションの時間と計算リソースがまばらな場合の流体挙動の十分な近似法として機能することです。 CFDへのデータ駆動型アプローチの精度は数値CFDソルバーの精度に決して達することはできませんが、CFDへのデータ駆動型アプローチの適切な応用先として、高精度は必要としないが非常に速い実行時間のコンピューターゲームが含まれます。
このパート3は、定常状態の流体の流れを予測するためのニューラルネットに関する3部構成シリーズの終わりを示しています。 あなたが私と同じように旅を楽しんだことを願っています。
読んでくれてありがとう! 👨💻🎉