書籍化されました 
- 本記事をベースに監修者の村上さんが1冊の本にまとめてくれました(感謝)
- データサイエンティストのキャリア面やポートフォリオの細かい部分をさらに追加・ブラッシュアップした内容になっています。
まえがき
はじめに
皆さん、「データサイエンティスト」という職種をご存知でしょうか?
この数年間で、AIやディープラーニングといったバズワードと共にデータサイエンティストというワードも、よく耳にするようになりました。最新の技術を扱えて、年収も高い非常に魅力的な職業なため、データサイエンティストへの転職を検討されている方もいらっしゃるのではないでしょうか?
実際、データサイエンティスト職への就職・転職希望者は年々増加しています。しかし、未経験の人材を育成できる会社はまだまだ少なく、未経験からの転職は転職希望者の増加に伴い高まっています。
データサイエンティストは求められるスキルの幅が広く、それぞれの習得にも時間がかかるといった理由から道半ばで諦めてしまう方も多くいるという話も見聞きします。私自身も、画像解析系の研究開発の経験とエンジニアリングに関する経験があるにも関わらず、データサイエンティストとしての転職活動に非常に苦戦しました。
こちらの記事では、そういった 「データサイエンティストに転職したくてデータサイエンスの勉強をしたけど、もう一歩足らない」 という方に対して、転職に役立つポートフォリオの作り方に関して解説させて頂きます。
データサイエンティストへの就職・転職成功率を上げる為には、現場で活躍できることを示すためのポートフォリオが役に立ちます。ポートフォリオがあれば、自身の能力を客観的に評価してもらえ、他の候補者とも差別化することができるからです。本記事では、ポートフォリオ作成に当たって必要となる以下の内容を解説していきます。
・データサイエンティストとして転職する際の検討事項
・ポートフォリオの種類とその解説
・ポートフォリオの作成イメージと作成手順
本記事では、データサイエンティストからデータエンジニア、機械学習エンジニアといった、目指しているデータ系領域に合わせて適切な情報を提供できるように努めました。こちらの記事がデータ系人材への転職を目指している方への一助になれますと幸いです。
対象読者と必要な事前知識
本記事は、以下のような読者を想定して執筆しています。
- データサイエンティストへの転職を考えている方
- 基礎的な学習を終えたが、次に何をやればいいかが分からない方
- データ系職種への転職において、どのようなポートフォリオを作れば良いか知りたい方
本記事では、以下の事前知識がある方を想定して執筆しています。作成するポートフォリオによって求められる前提知識も変わって来るので必ずしも全てが必須ではないですが、以下のような知識に関しては理解している前提で解説を記載しています。
- Pythonでのプログラミング
- Webの知識(HTTP)
- コンピュータアーキテクチャの知識
- 基本統計量の知識
- 機械学習に対する基礎知識
- こちらのデータラーニングスクールのカリキュラムが終わった方
- データサイエンス入門のための学習書籍・コンテンツ(2020年4月版)に記載している学習が半分程度終わった方
本記事の構成
本記事は、以下のような構成になっています。
第1部 データサイエンティストの職務分類とポートフォリオ
前半の第1章〜第3章では、データサイエンティストの仕事内容と、それに対応したポートフォリオがどのようなものなのかを解説します。
| 章 | 概要 |
|---|---|
| 1章 | データサイエンティストの仕事内容や職務分類の解説 |
| 2章 | データサイエンティスト転職にポートフォリオが有効な理由 |
| 3章 | データ系職種で求められるポートフォリオ種別 |
第2部 事例で学ぶポートフォリオ作成ガイドライン
後半では、データラーニングギルドで実際に取り組んだプロジェクトを参考に、どのようなポートフォリオを作成すると良いのか、事例ベースで解説を行って行きます。
| 章 | 概要 |
|---|---|
| 4章 | ユーザー検索プロジェクト概要説明 |
| 5章〜9章 | ポートフォリオ作成ガイドライン |
データサイエンティストの仕事内容やデータサイエンティストに転職を成功させるポイントが知りたい方は1章、2章を、具体的なポートフォリオの種類が知りたい方は3章を、ポートフォリオの作成イメージを知りたい方は4章〜9章を読んで頂ければと思います。
目次
- まえがき
- 第1部 第1章 データサイエンティストという仕事
- 第1部 第2章 データサイエンティスト転職を成功させるためのポートフォリオ
- 第1部 第3章 データサイエンティストのポートフォリオの種類と概要
- 第2部 第4章 ユーザー検索プロジェクトの紹介
- 第2部 第5章 ①機械学習モデルの作成
- 第2部 第6章 ②機械学習モデルを利用するためのWebAPIの開発
- 第2部 第7章 ③ダッシュボードの構築
- 第2部 第8章 ④データパイプラインの構築
- 第2部 第9章 ⑤分析レポートの作成
- 補足
- おわりに
第1部 第1章 データサイエンティストという仕事

この数字は、Googleにおいて、1日あたりに「データサイエンティスト」というキーワードで検索された回数を10年前と現在(*1)で比較した際の増加率です。
*1:Google Trendsより
昨今、「データサイエンティスト」というワードを「AI」や「ディープラーニング」といったバズワードと共にいろんなところで耳にするようになりました。本記事をご覧になっている皆さまの中にも、そういったワードを最近よく耳にするようになった方もいらっしゃるのではないでしょうか?
Google Trends 「データサイエンティスト」の検索数 (2010/09/30 - 2020/09/30)

※2013年頃に大幅に増加しているのは、2013年2月頃に出版されたハーバードビジネスレビューでデータサイエンティストが取り上げられたことでバズったのが要因のようです。
本記事では、データサイエンティストに転職するためのポートフォリオ作成方法を中心に解説していますが、その前にデータサイエンティストがどんな仕事をするのか、どういったスキルや経験が求められるのか、といったことを改めて整理しておきたいと思います。データサイエンティストという言葉は、使う人や使うシーンによって若干意味が異なることが多い言葉です。そこで、本書における「データサイエンティスト」を先に定義し、後述の解説でご認識を与えないようにしたいと思います。
また、どんなマインドを持ってポートフォリオ作成及び就職・転職活動に取り組めばいいかを考えるきっかけにもなるのではないかと思います。
1.1. データサイエンティストとは
データサイエンティストという仕事は、非常に職務の範囲が広い職種です。統計や機械学習のみとどまらず、エンジニアリング、プロジェクトマネジメントなどの多種多様な専門領域を道具として使い、ビジネス課題を解決することを求められます。
また、肩書はデータサイエンティストであっても、所属する企業によって実際にやっていることが異なるなんてことはよくあります。そういう意味で、「データサイエンティストとは何か?」という答えを一言で述べるのは難しいことです。
さて、ご存知の方もいらっしゃるとは思いますが、データサイエンティスト協会という団体があります。主に「データサイエンティストに必要となるスキル・知識を定義し、育成のカリキュラム作成、評価制度の構築など、高度IT人材の育成と業界の健全な発展への貢献、啓蒙活動」などを行っている団体で、業界を代表するデータサイエンティストの方が多く所属しております。
幸いなことにデータサイエンティスト協会のスキル定義委員会の方が、「データサイエンティストとは?」という問いに対する答えを用意してくれていますので、そちらを引用させて頂きます。
データサイエンティストとは、
データサイエンス力、データエンジニアリング力をベースにデータから価値を創出し、ビジネス課題に答えを出すプロフェッショナル引用元:
データサイエンティストのためのスキルチェックリスト/タスクリスト概説 | データサイエンティスト協会 スキル定義委員会/情報処理推進機構
少し補足しておくと、ここで言う「データサイエンス力」「データエンジニアリング力」とは、データサイエンティスト協会が提唱するデータサイエンティストに求められる3つのスキルの内の2つを指しています。3つのスキルの説明は次節を御覧ください。
また、「プロフェッショナル」という言葉も、以下のような明確な定義がなされています。
• 体系的にトレーニングされた専門性を持つスキルを持ち、
• それをベースに顧客(お客様、クライアント)にコミットした価値を提供し、
• その結果に対し、認識された価値の対価として報酬を得る人
この定義文では、「具体的にどんな仕事をするのか」という部分がまだ分かりにくいと思います。そこで、次節以降では、データサイエンティストに求められる3つのスキルを説明した後、データサイエンティスト職を役割の違いで分類し、具体的な仕事内容を説明します。
1.2. データサイエンティストに求められるスキル
『データサイエンティストのためのスキルチェックリスト/タスクリスト概説』によれば、データサイエンティストに求められるスキルは、大きく3つのスキルセットに分類されます。「データサイエンス力」「データエンジニアリング力」「ビジネス力」です。
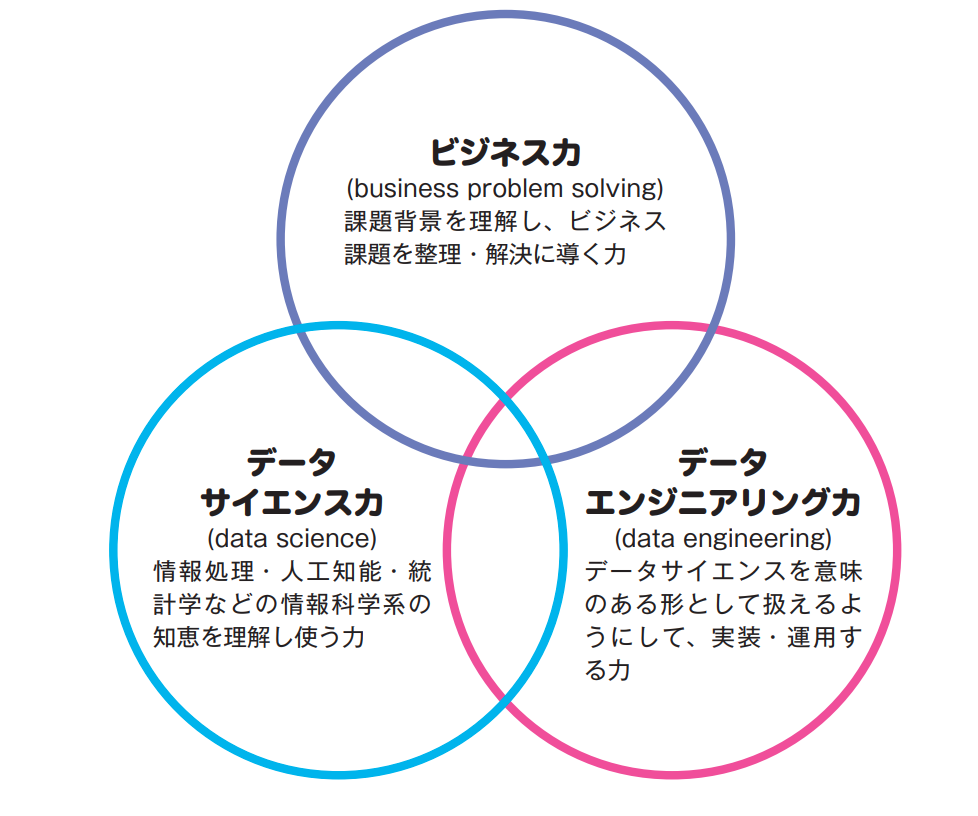
引用元:データサイエンティストのためのスキルチェックリスト/タスクリスト概説
これら3つのスキルセットは、データサイエンティストとして成果を出す上で重要なファクターです。どれか一つでも欠けてしまうと、十分な力を発揮することができません。

引用元:データサイエンティストのためのスキルチェックリスト/タスクリスト概説
しかし、一つ誤解してはいけないのは、 これらのスキルセットをすべて高水準で保持する必要はない ということです。データサイエンティストに要求されるスキル定義は、一人で全てをこなすことを想定して作られたものではなく、各領域に秀でたメンバーを集め、チームとしてすべての領域をカバーできていれば良いのです。
とはいえ、自身が得意とする領域以外の知識や経験も持っておいた方が望ましいのは確かです。そうすることで、他のチームメンバーとのコミュニケーションが円滑に進みますし、課題に対する考察も深みを増すからです。
1.3. データ領域の職種分類
本節では、データ領域の職種を役割の違いで分類し、より具体的な仕事内容を解説していきます。こちらの解説を元に分類しています。
データサイエンティスト関連職種の職種名は、様々な呼び名があり、定義も一つに定まったものがある訳ではありません。したがって、ここで述べるのは、あくまでも「本記事における職種の定義」であることをご理解いただき、読み進めていただければと思います。
次の表は、データ領域の職種一覧です。職務における3つのスキルを活用するシーンの割合を★で示しています。(必要とするスキルのレベルではありません)
| 職種名 | BZ | DS | DE | 仕事内容 |
|---|---|---|---|---|
| データサイエンティスト | ★★☆ | ★★★ | ★☆☆ | 機械学習や統計を用いたモデリングに加え、検証結果のレポーティングなどを主に担当する。高い数学的素養が求められる。 |
| 機械学習エンジニア | ★☆☆ | ★★☆ | ★★☆ | 機械学習モデルをシステムに組み込む部分を主に担当する。モデルを理解できるレベルの数学的素養とシステムに組み込めるだけのエンジニアリングスキルが求められる。 |
| データエンジニア | ★☆☆ | ★☆☆ | ★★★ | データの集計・抽出の仕組みを作る部分を主に担当する。大規模データの負荷分散処理やデータの自動更新の仕組みなどを実装するのに必要な高いエンジニアリング力が求められる。 |
| データアーキテクト | ★★☆ | ★☆☆ | ★★☆ | 主にデータ活用のためのシステム間連携を実現する。データエンジニアと比べて、より俯瞰的にシステムを把握し、どのようにビジネス価値の向上に繋げられるかを考えることが必要であり、ビジネス力も求められる。 |
| BIエンジニア | ★★☆ | ★☆☆ | ★★☆ | ビジネス・インテリジェンス(Business Intelligence、BI)という技術を用いてデータを可視化する。BIツールと呼ばれるツールを用いることが多い。見るべき数値(KPI)を可視化するだけでなく、数値自体を定義する場面もあり、データサイエンス力に加えてビジネス力が求められる。 |
| プリセールス | ★★★ | ★☆☆ | ★☆☆ | 抽象度の高い顧客要望をデータ分析の課題に落とし込む部分を主に担当する。ビジネスの構造をよく理解しておく必要があり、それを具体的な分析課題に落とし込む為のデータサイエンス力が求められる。 |
| ビジネスアナリスト※1 | ★★★ | ★★☆ | ★☆☆ | 統計的な分析を用いてビジネスの施策を導き出す。検定や効果検証といった技術を用いて、打った施策の効果の分析やビジネスの現場でおきる出来事の原因分析を行う。統計分析に必要なデータサイエンス力が求められる。 |
| PM・コンサル※1 | ★★☆ | ★★☆ | ★★☆ | データ分析プロジェクトを成功させるためのディレクションを主に担当する。ここまでに紹介した様々な職種のメンバーとコミュニケーションをとり、適切な意思決定をする為にビジネス力・データサイエンス力・データエンジニアリング力全体をバランス良く持っておく必要がある。 |
※1…データ領域外でも同名の職種がありますが、ここではデータ領域における狭義のビジネスアナリスト、PM、コンサルを指します
※2…BZ:ビジネス力/DS:データサイエンス力/DE:データエンジニアリング力
※3…★★★:主に利用するスキル/★★☆:主に利用するスキル(他に併用する主に利用するスキルがある)/★☆☆:ベースとして保持しておくべきスキル
第1部 第2章 データサイエンティスト転職を成功させるためのポートフォリオ
2.1. ポートフォリオとは?
ポートフォリオを作ることで、データサイエンティストとしての転職活動をかなり有利に進めることができます。では、この「ポートフォリオ」とは一体何なのでしょうか?
ポートフォリオの解説に移る前に「ポートフォリオ」という言葉自体に馴染みが無い方も多くいらっしゃるかと思いますので、転職におけるポートフォリオに関して簡単に紹介したいと思います。
ポートフォリオという言葉に関しては、金融、教育、クリエイティブ領域でそれぞれ別の意味で使われ、用語の意味としては以下のような意味となります。
| 領域 | 用語の意味 |
|---|---|
| 金融 | 現金、預金、株式、債券、不動産など、投資家が保有している金融商品の一覧や、その組み合わせの内容 |
| 教育 | 生徒たちが学習過程で残したレポートや試験用紙、活動の様子を残した動画や写真など |
| クリエイティブ | クリエイターの作成した作品集 |
今回解説するポートフォリオは教育のポートフォリオに最も近いため、こちらの解説に関してマイナビクリエイター様の記事より引用させて頂きます。
教育用語としてのポートフォリオは、教育における個人評価ツール(パーソナルポートフォリオ)を指しています。これは、生徒たちが学習過程で残したレポートや試験用紙、活動の様子を残した動画や写真などを、ファイルに入れて保存する評価方法です。従来の科目テストや知力テストだけでは測れない、個人能力の総合的な学習評価方法(質的評価方法)とされ、学校教育だけではなく自己啓発など、さまざまな教育分野で取り入れられています。
由来は、1980年代後半にイギリスやアメリカで取り入れられ、1990年代後半に日本に入ってきた、ロンドン大学のS=クラーク教授を中心に考案された外来語です。教師とともに生徒自身も自己評価を行いながらステップアップしていくというものであるため、保存する情報は生徒たちが自分のことを客観的に見ることができるよう、意義のあるものを取捨選択していく方式となります。
このような評価するために収集されたもの、もしくはそれらを評価する方法を、教育分野ではポートフォリオと呼んでいます。転職用のポートフォリオとは趣が大きく異なりますが、「結果(完成作品)だけでなく、それに至る経緯を共有する」という点で、転職用のポートフォリオに役立てたいポイントを下記のように見いだせるでしょう。
・作品を作ったそもそもの目的や意図を明確にし、実際に達成できたのかを説明することによって作品を強く印象付け、理解を深めてもらう
・制作に至った背景や制作時の状況・環境などの情報を作品に添え、自分の仕事への取り組み姿勢や人材としての強みなどをアピールする材料とする
・仕事のプロセス(問題解決プロセス)を知ってもらうことで、「これからどのように成長していく人材か?」という判断材料を与える
引用元:ポートフォリオとは - Portfolioの意味と3つの業界での使い方
上記のように、教育で扱われる「ポートフォリオ」という用語に関しては学習に関する情報をひとまとめにしたものを指します。本記事で扱う「ポートフォリオ」に関してもこちらをベースに、成果物及びその成果物の作成に至るまでの検討事項や思考プロセスなどを効率良く共有できるようなアウトプットを指すことにします。
2.2. ポートフォリオをなぜ作るのか
ポートフォリオの意義を考えるに当たって、データサイエンティスト就職・転職市場を、「就職・転職希望者」と「企業」の視点で考えてみましょう。
本記事冒頭でも示したように、データサイエンティスト職への就職・転職希望者はここ最近増加しています。データサイエンティスト就職・転職市場における競争率が上昇している為、データサイエンティストへの就職・転職を成功させるためには、他の候補者との差別化をはかることがより一層重要になっています。
企業視点では「データサイエンティストが足りない」という話をよく耳にします。国内の多くの企業はデータサイエンティスト不足に悩まされています。今後も5Gによる高速通信やクラウドサービスの普及により、これまでより一層膨大なデータを分析するケースが増えることは容易に予想できます。
データサイエンティストになりたい人が増えたにも関わらず、企業もデータサイエンティストの不足に頭を抱えている。このミスマッチは一体なぜ起こっているのでしょうか?
それは、企業が求めているのが **「実課題を解決できる」**データサイエンティストだからです。
そのため、勉強した内容を実務に活かした経験や実務に近い分析の成果がないと企業が「データサイエンティストとして採用したいレベル」の人材にはなれません。
そこで、ポートフォリオの作成がデータサイエンティスト転職において以下のように役立ちます。
・実際の分析業務に近い経験をすることで、業務レベルのスキルを身につけることができる
・自分が「企業がデータサイエンティストとして採用したいレベル」であることを証明することができる
とはいえ、「データサイエンティストのポートフォリオ」というのは、あまり一般化していないように思います。「エンジニア」や「デザイナー」の方は、自身の技術力を示すためによくポートフォリオを作成しますが、それと比較して、データサイエンティストのポートフォリオの事例は非常に少ないと言えるでしょう。
実際、基本的な統計学、機械学習、PythonやRのプログラミングを勉強したはいいものの、次に何をすればいのだろうか?といった悩みをよく聞きます。
また、実務に近い実戦形式の学びを得たいが、そういった環境を個人で用意するのが難しい、といった声もあります。データサイエンティストの実務に近い経験を得たいならば、一定の規模を持つデータ(さらに何らかのインテリジェンスを得る価値のあるデータ)を用意する必要があります。すでに前処理がなされたきれいなオープンデータは、「実務に近い経験」を求めるケースでは不向きでしょう。
データサイエンティストに求められる基礎数学やコンピュータ・サイエンスなどの教材は、昨今非常に豊富に取り揃えられているのですが、教材で学ぶレベルと実務で知識を生かすレベルとの間に大きな隔たりがあることが、現在の課題と私は考えます。
そこで、この記事では、「データサイエンティストに必要そうな基礎技術を学んだけど、次に何をすればいいのか分からない」という課題に対するソリューションを提供したいと考えています。
2.3. データサイエンティストのポートフォリオとはどんなものか
では、具体的にデータサイエンティストのポートフォリオとはどんなものかを考えていきましょう。本節では、データサイエンティストの実務内容とそこで求められるスキルを概観した後、その中でポートフォリオの題材にできそうなケースを切り取っていきます。
データ分析プロセスから考えるデータサイエンティストの成果や実績
データサイエンティストの実務を概観する場合は、データサイエンティスト協会スキル定義委員が取りまとめている「スキルチェックリスト」とIPAがまとめている「タスク構造・タスクリスト」が参考になります。
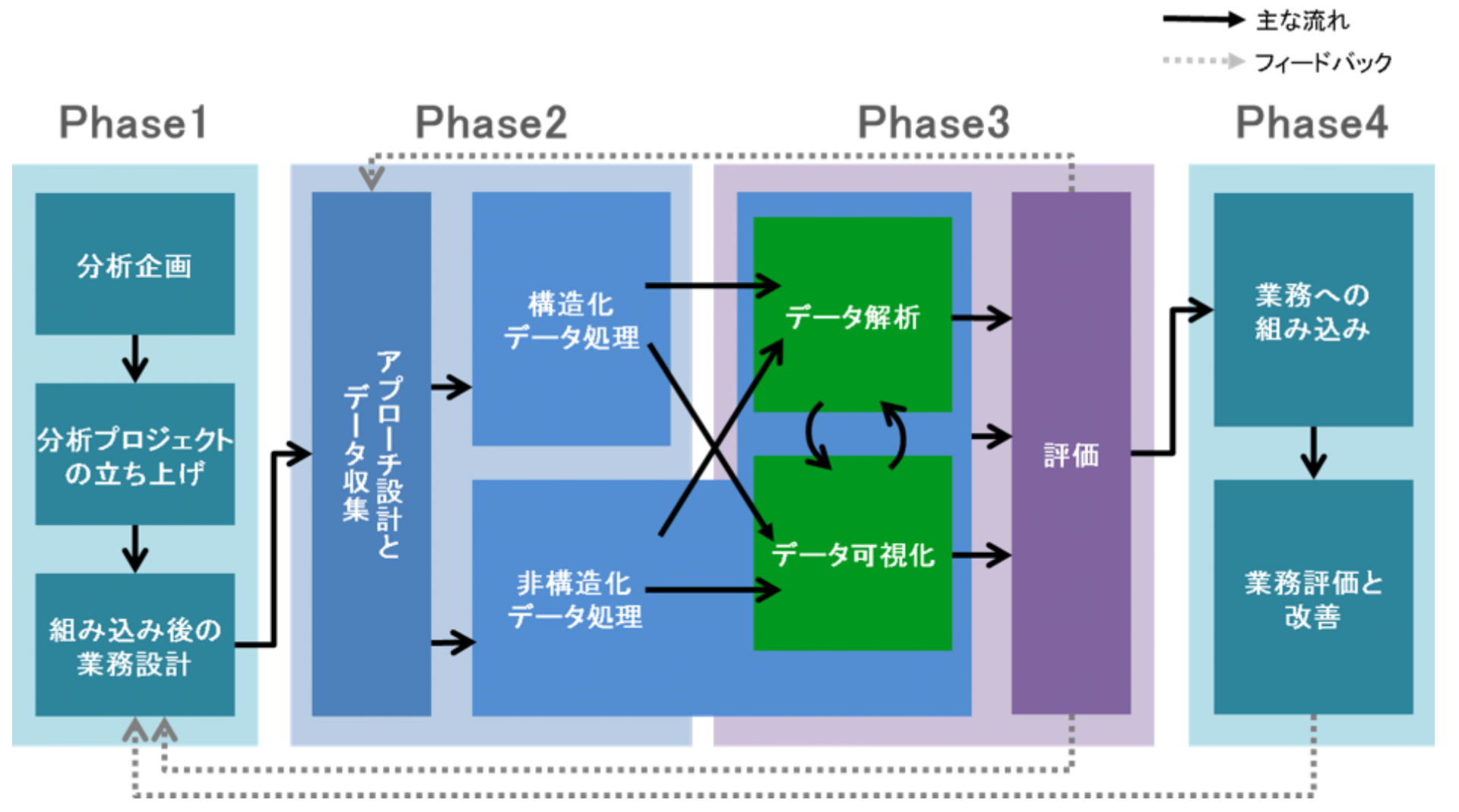
データサイエンティストの業務は、大別すると4つのフェーズで構成されます。
- Phase1:企画立案〜プロジェクト立ち上げ
- Phase2:アプローチの設計〜データ収集・処理
- Phase3:データの解析〜データ可視化
- Phase4:業務への組み込み〜業務の評価・改善
次の図は、各フェーズの構成要素と全体の流れをまとめたものです。
上記のプロセスを通して出力される具体的な成果物は以下のようになります。
- プロジェクト計画書
- データに関するレポート(収集・説明・調査・品質)
- フォーマットされたデータセット
- 分析課題の解決に特化した独自性の高い(機械学習を用いた)モデル
- ビジネス課題に対するモデルの性能評価レポート
- データ収集・前処理のためのパイプライン
- データ監視用のダッシュボード
これらの成果物の中で、ポートフォリオに適している成果物はどの成果物なのでしょうか?
ポートフォリオに向いている成果物
上記で説明したデータ分析プロジェクトにおける成果物例の内で個人では制作が難しいものはポートフォリオには向きません。
例えば、以下のような制作物に関しては、実際のプロジェクトや、実際のビジネスシーンでないと作成が難しいためポートフォリオとしては不向きです。
- プロジェクト計画書
- データに関するレポート
- フォーマットされたデータセット
- ビジネス課題に対するモデルの性能評価レポート
したがって、データサイエンティストのポートフォリオとして採用しやすいものは以下になります。
①分析課題の解決に特化した独自性の高い(機械学習を用いた)モデル ②機械学習モデルを用いたWebサービス ③データ監視用のダッシュボード ④データ収集・前処理のためのパイプライン ⑤分析レポート2.4. 良質なポートフォリオを作るには
ここまで、データサイエンティストのポートフォリオ例やポートフォリオを作ることの重要性を説明してきましたが、ただ作りさえすれば良いというものでもありません。可能な限り良質なものを作ることが望ましいでしょう。
良質なポートフォリオの定義
さて、良質なポートフォリオとは何でしょうか?
様々な定義が考えられますが、本記事では以下のように定義します。

現場で求められるスキルがあることをアピールする
では、「企業が(データサイエンティストとして)採用したくなる人材」とはどういった人物でしょうか。現場で求められるスキルが既にある、あるいは高速で身につけられる素養を持っている人材です。
もちろん、会社のビジョンへの共感度やチームとのマッチング度合いなども重要な指標になりますが、ポートフォリオ制作との関連性が低いので、ここでは割愛しています。
現場で求められるスキルは、データサイエンティスト協会が発行している『スキルチェックリスト』(以下、スキルチェックリスト)が参考になります。
スキルチェックリストでは、データサイエンティストを「シニア・データサイエンティスト」「フル・データサイエンティスト」「アソシエイト・データサイエンティスト」「アシスタント・データサイエンティスト」の大きく4つのレベルに分けています。

『データサイエンティストのためのスキルチェックリスト/タスクリスト概説』
データサイエンティストに転職することを目指す皆さまは、まず「アシスタント・データサイエンティスト(見習いレベル)」を目標とすることになります。
スキルチェックリストでは、各レベルごとにどのスキルをどれだけ持っていると良いかが定められています。アシスタントデータサイエンティストになるには、スキルチェックリストの★一つのスキルを70%以上満たしていることが求められます。

一般社団法人データサイエンティスト協会 スキルチェックリストより引用
すなわち、(未経験からの転職希望者として)企業の欲しい人材になるには、スキルチェックリストに記載された★1つのスキルを如何に多く保持しているかをアピールすることが重要だと言えます。
良質なポートフォリオ作りで意識すべきポイントまとめ
とはいえ、全てのスキルについて、逐一「このスキルをアピールするためにはポートフォリオをどう作るか?」などと確認しながら、ポートフォリオ制作に取り組むのは現実的ではありません。(2020年10月現在、スキルチェックリストver3.01において、アシスタント・データサイエンティストに求められるスキルは146個掲載)
そこで、本記事では、アシスタント・データサイエンティストに求められるスキルをベースに、「そのスキルを持つ」と評価してもらうために、最低限どういった点に注意してポートフォリオ制作や面接に臨むと良いかをまとめました。
本まとめを参照していただければ、全スキルをご自身で逐一確認しながらポートフォリオ制作に臨むより効率よく進められると思います。是非ご活用ください。
※ただし、本まとめは最低限抑えておくべきポイントでしかないため、一度スキルリスト全体に目を通すことをおすすめします。
1. ビジネス力
| 項番 | ポイント | 関連するスキルカテゴリ |
|---|---|---|
| 1 | 分析課題の目的やゴールを言語化すること | 行動規範/ビジネスマインド |
| 2 | データの捏造・改ざん・盗用をしていないこと | 行動規範/データ倫理 |
| 3 | 個人情報関連の法令に抵触していないこと | 行動規範/コンプライアンス |
| 4 | 文章が論理的に矛盾なく記述できていること | 論理的思考/ドキュメンテーション |
| 5 | 分析結果の意味合いを正しく言語化できていること | 論理的思考/言語化能力 |
| 6 | 仮説を持ってデータの観察・分析や仮説検証に取り組み、適切に改善を施すことができている |
ビジネス観点のデータ理解/データ理解ビジネス観点のデータ理解/意味合い抽出、洞察
|
2. データサイエンス力
| 項番 | ポイント | 関連するスキルカテゴリ |
|---|---|---|
| 1 | 統計量の計算、ベクトル・行列の演算、微分・積分の計算を適切な目的のために正しく利用できていること |
基礎数学/統計数理基礎基礎数学/線形代数基礎基礎数学/微分・積分基礎
|
| 2 | 予測モデルを作る際は、課題に応じた評価指標を利用できていること、またその意味を説明できること | 予測/評価 |
| 3 | 要素技術を正しい目的に使うことができている(説明できる)こと | 全般 |
| 4 | データの前処理(ダミー変数化、標準化、外れ値・異常値・欠損値の変換、除去など)を施していること | データ加工/データクレンジング |
| 5 | データ可視化において、目的に沿ったデザイン(データ量を適切に減らす、データインク比の調整、適切な軸だし)ができていること |
データ可視化/軸だしデータ可視化/データ加工データ可視化/表現・実装技法
|
3. データエンジニアリング力
| 項番 | ポイント | 関連するスキルカテゴリ |
|---|---|---|
| 1 | 数十万レコード規模のデータベースの定常運用(バックアップ・アーカイブ作成)ができること | 環境構築/システム運用 |
| 2 | データベースからSQLその他の手段でデータを抽出し、目的に応じたデータセットを作ることができている | 環境構築/システム企画 |
| 3 | 対象プラットフォームに用意された機能やWebクローリング技術を使って、所望のデータをデータ収集先に格納できる(機能を実装できる)こと |
データ収集/クライアント技術データ収集/通信技術
|
| 4 | RDB、NoSQLデータストア、オブジェクトストレージなどにAPIを介してアクセスし、情報取得や登録できること |
データ蓄積/分散技術データ蓄積/クラウド
|
| 5 | 数十万レコード規模のデータに対して、サンプリング、集計、ソート、フィルタリング処理を実行できること |
データ加工/フィルタリング処理データ加工/サンプリング処理データ加工/集計処理
|
| 6 | 小規模な構造化データ(CSV、RDB、JSON、XMLなど)に対して、(ときにはAPIなどを経由して)抽出、加工、分析できていること |
プログラミング/基礎プログラミングプログラミング/データインターフェース
|
| 7 | Jupyter NotebookやRStudioなどの対話型開発環境を用いて、データの分析やレポートを記述できていること | プログラミング/分析プログラム |
アシスタント・データサイエンティストに求められるスキルは、スキルチェックリスト本編よりご確認ください。
今後、データサイエンティストの転職市場はより活性化していくでしょう。すると、ポートフォリオを作成する候補者が増加し、これまでアピールできたはずのポートフォリオも陳腐化し、さらに高いレベルの成果物が求められる現象が起きる可能性が高いです。実際、エンジニアの転職市場でそういった現象が起きています。
本節で述べた「良質なポートフォリオとは何か?」が、他の候補者と差別化できるポートフォリオ作成の一助になれば幸いです。
第1部 第3章 データサイエンティストのポートフォリオの種類と概要
データサイエンティスト職の現場では、プロジェクトのフェーズや課題の内容・目的に応じて、「データサイエンス」「データエンジニアリング」「ビジネス」の3つのスキルをそれぞれ活用して、多種多様な成果物を残すことになります。したがって、データサイエンティストのポートフォリオは、いくつかの種類があります。
ここでは、データサイエンティスト職への就職・転職に役立つポートフォリオの種類とそれぞれの特徴をまとめます。
3.1. データサイエンティストのポートフォリオの類型
ここでは、2.3節で説明した以下の5つの「ポートフォリオに向いている成果物」に関して具体的に解説していきます。
① 機械学習モデルの作成
② 機械学習を用いたWebサービスの開発
③ データ監視用のダッシュボード構築
④ データ収集・前処理のためのパイプライン構築
⑤ 分析レポート作成
各ポートフォリオに関して、それぞれ以下の流れで解説していきます。
- どんな職種を目指す人に向いているか
- アウトプットの形式
- アピールしたいポイント
- 必要な要素技術
尚、必要な要素技術を表すキーワードは、原則として、スキルチェックリストより引用しており、「Python」などの具体的な固有名詞は、筆者の判断で記述しています。
3.2. ① 機械学習モデルの作成
まず一つ目のポートフォリオサンプルが機械学習モデルです。データサイエンスに関するアウトプットを思い浮かべた際に、真っ先に思い浮かぶのがこちらの成果物かと思います。
ある特定の問題に対して、予測値や分類結果を返す機械学習モデルの構築です。モデルの構築だけであればscikit-learnなどを用いれば用意に実装できるため、適切な課題設定ができているか、データの取り扱いや特徴量エンジニアリングや評価指標は適切かといった、データ分析における一連の流れにおけるアプローチが適切であることをアピールできるようなポートフォリオが求められます。
どんな職種を目指す人に向いているか
- 機械学習エンジニア
- データサイエンティスト
- データエンジニア ※学習データの収集、再学習などのシステム構築に注力した場合
機械学習モデルの構築を主に担当するデータサイエンティストはもちろんのこと、機械学習をサービスに適用する部分を主に担当する機械学習エンジニアの方に関しても効果的なポートフォリオとなります。各アルゴリズムの特徴を捉えることで適切なパフォーマンスチューニングやリファクタリング、システム設計に繋がるからです。
また、データエンジニアを目指されている方に関しては、DevOpsの類似領域であるMLOpsと言われる領域を担当する際に機械学習モデルの性質を理解しておく必要があるため、かけ合わせの技術として機械学習のモデリングに関する知識を持っていることがプラスに働きます。
アウトプットの形式
機械学習のモデル構築では、機械学習の一連のプロセスに加え「何故その手法を選択したのか?」であったり、「モデリングがスムーズに行かなかった際の試行錯誤の履歴」が重要になってきます。そのため、最終成果物としてのコードに加え、試行錯誤の履歴をレポートとしてまとめておくことをオススメします。
また、何らかの解決すべき課題をテーマとして決めた上で取り組むことで、その課題に対するアプローチが適切であることを示すことができます。そのため、仮の課題でも良いので「XXを解決するための機械学習モデル」というテーマを決めて取り組むのがベターです。
以下に、具体的な成果物のイメージ、共有・展開方法の例を一覧表にしたものを記載します。
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| 構築したモデルの解説 | 記事形式でまとめて、オンラインで見れる所にまとめてURLを共有 |
| モデル学習・予測用コード | Jupyter Notebook形式でGitHubに公開 |
| モデルの検証用コード | Jupyter Notebook形式でGitHubに公開 |
| 構築したモデルの実行方法 | GitHubのreadme.mdなどに記載 |
| 構築したモデルの検証結果 | 記事形式でまとめて、オンラインで見れる所にまとめてURLを共有 |
アピールしたいポイント
機械学習のモデルを構築する際は、見習いの段階ではある程度予測問題まで落とし込まれた状況で着手できることが多いと思いますが、独り立ちレベルのデータサイエンティストの場合、課題設定〜コードの実装、評価までの一連のプロセスが求められます。
そのため、将来的にそういった一連のプロセスを任せられることができそうだと思ってもらうことが重要になってきます。以下のようなポイントをアピールできるよう意識してポートフォリオを作成できると、評価されやすいポートフォリオを作ることができます。
- 機械学習で解くべき課題設定の妥当性
- 課題を機械学習の問題へ落とし込む際の妥当性
- 実装コードの可読性
- ベースラインとして使うモデルの妥当性
- モデルのチューニングの妥当性
- 利用するデータの前処理の妥当性
- 性能を評価する指標を適切に選択していること
- 設定した問題に対して良い性能を出していること
必要な要素技術を表すキーワード
| 大分類 | 中分類 | キーワード |
|---|---|---|
| データサイエンス | データ加工 | データクレンジング, 特徴量エンジニアリング |
| 分析プロセス | アプローチ設計 | |
| データの理解・検証 | データ確認, データ理解 | |
| 機械学習技法 | 機械学習, 深層学習, 強化学習, 時系列分析 | |
| その他分析技法 | 言語処理, 画像・動画処理, 音声・音楽処理 | |
| データエンジニアリング | 環境構築 | アーキテクチャ設計 |
| データ収集 | クライアント技術, 通信技術 | |
| データ構造 | データ構造基礎知識, テーブル定義, テーブル設計 | |
| データ加工 | クレンジング処理, 集計処理, 変換・演算処理 | |
| プログラミング技術 | プログラミング | Python |
| ライブラリ・フレームワーク | TensorFlow, PyTorch, scikit-learn, etc... |
3.3. ② 機械学習を用いたWebサービスの開発
二つ目のポートフォリオは、機械学習を用いたWebサービスです。これは、プログラムのロジックに機械学習モデルが組み込まれているWebサービスを指します。
例えば、文章情報をJSON形式でリクエストすると、文章の要約結果がレスポンスとして返ってくるWebAPIなどがこれに当たります。機械学習モデルを利用する場合はWeb技術を用いるケースがほとんどなので、Webサービスを開発することで機械学習に加えてWebプログラミングの技術も身につけることができます。
機械学習を用いたサービスがベターではありますが、場合によっては、データベースに蓄積されているデータを集計、フィルタリングして返却するようなサービスでもエンジニアリングの能力を示すことができるので、機械学習まで手が出ないという方はまず簡単なデータ返却のAPIなどから取り組んでみると良いかもしれません。
どんな職種を目指す人に向いているか
- 機械学習エンジニア
- データエンジニア
Webサービスの開発に関してはエンジニアリングの要素が多く求められるので、機械学習エンジニアやデータエンジニアといった、エンジニア系の職種を目指す方にオススメなポートフォリオです。機械学習に加えて、Webシステム化する際のモデルの更新の仕組みなども検討する必要があるため、機械学習を用いたWebサービスを開発することで、エンジニアリングと機械学習の両方に精通していることがアピールできるはずです。
アウトプットの形式
機械学習を用いたWebサービスでは、Webサービス形式になっているので、作成したサービスそのものが最も重要になってきます。そのサービスがどのようなサービスなのか、どういった用途やシーンで使われることを想定して作られているかなどの解説をして、サービスの意図をしっかりと理解してもらいましょう。機械学習を用いたWebサービスを構築した際のアウトプット形式の例を以下に記載します。
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| サービス開発の内容を要約した記事 | 技術ブログサービスなどに開発内容をまとめ、公開 |
| WebAPIと仕様書 | 実装したコードをGitHubで公開(WebAPI設計書と使い方をREADMEに記述) |
| 実際に操作できるWebAPI | WebAPIをサーバー上でホスティング |
アピールしたいポイント
機械学習を用いたWebサービスをポートフォリオとして選択する理由としては、「開発と機械学習のどちらも分かる」ということをアピールするためです。以下のようなポイントを意識してポートフォリオ作りができると魅力的なポートフォリオの作成ができるはずです。
- 納得感のあるユースケースを設定していること
- 使用している機械学習のモデルが適切であること
- 自身で作成した機械学習のモデルを用いてシステムが構築されていること
- 機械学習モデルの更新を考慮したシステム設計になっていること
- モデルを利用しやすいインターフェイスになっていること
- わかりやすいAPI設計書を記述していること(OpenAPIの形式に沿っているとなお良い)
- 実装したコードの可読性
- テストコードが必要十分に記述されていること、また妥当なテストであること
- クラウドインフラを用いてWebサービスをホスティングしていること(プロダクション環境を想定した冗長化やパフォーマンスチューニングもできているとなお良い)
- CI/CDパイプラインを構築していること
必要な要素技術を表すキーワード
| 分類 | キーワード |
|---|---|
| データエンジニアリング | データ共有, データ出力, データ展開, データ連携 |
| プログラミング | 基礎プログラミング, アルゴリズム, 拡張プログラミング, リアルタイム処理 |
| システム開発 | Web開発, サーバ構築, API, データインターフェース, Webフレームワーク, マイクロサービス |
| データベース処理・分散処理 | SQL, Pig, HiveQL, SparkSQL(データの規模によって必要可否が変わる) |
| ITセキュリティ | セキュリティ基礎知識, プライバシー, 攻撃と防御手法, 暗号化技術 |
3.4. ③ データ監視用のダッシュボード構築
ダッシュボードとは、一般に、様々な情報を一箇所に集めて、全体をひと目で俯瞰できるようにする機能、あるいはページそのものです。
データ分析の文脈では、主に複数のデータソースから情報を引っ張ってきて、迅速な意思決定を支援するための情報(KPIなど)をひと目で見れるようにデザインしたものを指します。主にBIツールを用いて構築されます。
どんな職種を目指す人に向いているか
- データアーキテクト
- データサイエンティスト
- BIエンジニア
BIツールを用いたダッシュボードは、データ活用プロジェクトを推進する上で必須の要素となってきます。データを定期的に更新して表示する仕組みの検討、基幹システムや各種SaaSとの連携、ダッシュボードの閲覧可能範囲の切り分けなどを検討する必要が出てくるため、データ活用の全体像を設計するデータアーキテクトを目指す方にとっても有効なポートフォリオとなります。
また、データサイエンティストの分析結果を元に重要な指標をダッシュボードに表示するので、データサイエンティストの転職においても分析ダッシュボードがポートフォリオとして有効に働きます。
BIツールの開発、設計を中心に行うBIエンジニアに関しては、作成するポートフォリオはほぼこの一択になるかと思います。
アウトプットの形式
データ監視用のダッシュボード構築では、作成したダッシュボードが主な成果物となります。ただ、ダッシュボードを見ただけでは、そのデータがどのような意図で集計されているのかであったり、データの定義などは分かりません。そのため、補助書類としてダッシュボードに関する解説用のドキュメントを整備できると良いかと思います。
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| BIツールを用いたダッシュボード | 公開したダッシュボードのリンク |
| ダッシュボード仕様書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| ダッシュボード構築の内容を要約した記事 | 技術ブログサービスなどにダッシュボード構築における狙いやポイントをまとめ、公開する |
アピールしたいポイント
ダッシュボード構築において重要な要素は、大きく分けると配置の色のバランスや図表の選び方といったデザイン面と、ビジネスの状況を正しく把握できる指標になっているかといったビジネス面の2種類に分かれます。そのため、以下のようなアピールポイントを意識してダッシュボードを構築すると良いでしょう。
- 適切な図表をも用いてダッシュボードが構築されていること
- ダッシュボードにおける必要な情報の可視性、説明文の可読性
- ユーザーの導線に沿った操作性になっていること
- 何を目的としたダッシュボードであるかが明確になっていること
- 目的を達成するために見るべき数値が適切に選定されていること
- 表示されている指標を元にどのような意思決定に繋がるかイメージできること
- 分かりやすい操作説明書がある
必要な要素技術を表すキーワード
| 大分類 | 中分類 | キーワード |
|---|---|---|
| ビジネス | 行動規範 | ビジネスマインド, データ倫理, コンプライアンス |
| 論理的思考 | MECE, 構造化能力, 言語化能力, ストーリーライン, ドキュメンテーション, 説明能力 | |
| 着想・デザイン | データビジュアライゼーション | |
| 課題の定義 | KPI, スコーピング, アプローチ設計 | |
| ビジネス観点のデータ理解 | データ理解, 意味合いの抽出、洞察 | |
| データサイエンス | データ可視化 | 方向性定義, 軸だし, データ加工, 表現・実装技法, 意味抽出 |
| データの理解・検証 | 統計情報への正しい理解, データ確認, 俯瞰・メタ思考, データ理解, データ粒度 | |
| 意味合いの抽出、洞察 | 因果, 認知バイアス, 帰納的推論, 演繹的推論 | |
| データエンジニアリング | データ加工 | 集計処理, 変換・演算処理 |
| BIツール | Tableau, Looker, Dataportalといったダッシュボード構築機能を持ったツールの操作技術 |
3.5. ④ データ収集・前処理のためのパイプライン構築
データパイプラインとは、データ活用・分析システムにおけるデータの流れ、または滞りなくデータが流れるように構築されたシステム自体を指します。
例えば、Webサービスを運営する事業会社が、アプリケーションログから顧客のインサイトを取得したいとします。
この場合、分析に必要な情報をまとめたり、分析ができる場所を確保するためにデータウェアハウス(以下、DWH)を用意することがあります。
その際に、アプリケーションログ情報から、必要な情報を抽出、適宜変換し、DWHに安定的に取り込める仕組みが必要になります。これがデータパイプラインです。
どんな職種を目指す人に向いているか
- データエンジニア
- データアーキテクト
DWHの構築やデータ連携、自動更新の仕組みを作ることが中心になるデータエンジニア、それより一段高い所で全体の流れを設計するデータアーキテクトなどの職種がこのポートフォリオ作成に向いています。データパイプラインの構築などは、実務以外で取り組んでい居る方が少ない領域ですので、このポートフォリオがあることで他の候補者の方と大きな差をつけることができるはずです。
アウトプットの形式
データパイプラインの構築に関しては、サーバーにアクセスするなどしないと確認ができない部分が多く、実際に動くものを見せづらい側面があります。そのため、アウトプットに関してはどうしても地味になりがちです。実行のステップや使用したデータの詳細、どのような部分で工夫したかなどが伝わるように、ドキュメントをしっかりと書いて伝える必要が出てきます。以下に具体的な成果物の形の例と共有・展開方法の例を記載します。
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| アーキテクチャ設計書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| データベース定義書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| データ加工のフロー図 | 技術ブログサービスなどにETL処理を行う際の処理の流れを図式化したものをまとめ、公開 |
| データパイプライン構築の経緯を要約した記事 | 技術ブログサービスなどにデータパイプラインの仕様や使い方、ポイントなどをまとめ、公開 |
| データパイプライン構築の際に書いたコードなど | 実装したコードをGitHubで公開 |
アピールしたいポイント
データパイプラインに関しては、データにおけるインフラを支える重要な役割を果たす機能です。データが更新される仕組みが構築されているのはもちろんのこと、以下のような部分でアピールできるよう、取り組んだ内容に関してアピールすると良いでしょう。
- データ取得、データ蓄積、データ加工の一連の流れが構築できていること
- データを利用する人が使いやすい環境が構築できていること
- データを利用する人が使いやすいデータ形式にデータが変形されていること
- 各処理の実行に活用しているサービスが適切であること
- 目的や必要な性能に応じて適切なサービスを使っていること
- ワークフローエンジンなどを用いてジョブの実行管理が行われていること
- パフォーマンスを考慮した設計になっていること
- データ量が増えた際のスケーラビリティを考慮した設計になっていること
- データの形式が変わった際の対応が検討できていること
- 予期せぬデータが発生した際のリトライ処理や例外処理が考慮されていること
- クラウドインフラベンダーのベストプラクティスに沿った設計ができていること
必要な要素技術を表すキーワード
| 大分類 | 中分類 | キーワード |
|---|---|---|
| ビジネス | 行動規範 | データ倫理, コンプライアンス |
| データ入手 | ||
| データエンジニアリング | 環境構築 | システム運用, システム企画, アーキテクチャ設計 |
| データ収集 | クライアント技術, 通信技術, データ収集, データ統合 | |
| データ構造 | データ構造, 要件定義, テーブル定義, テーブル設計 | |
| データ蓄積 | DWH, クラウド, 分散技術, キャッシュ技術, リアルタイムデータ分析, 検索技術 | |
| データ加工 | フィルタリング処理, ソート処理, 結合処理, 集計処理, サンプリング処理, クレンジング処理, マッピング処理, 変換・演算処理 | |
| データ共有 | データ出力, データ展開, データ連携 | |
| プログラミング | 基礎プログラミング, データインターフェース, アルゴリズム, 拡張プログラミング, データ規模, リアルタイム処理, | |
| データベース処理・分散処理 | SQL, Pig, HiveQL, Spark SQL, 分散処理技術 | |
| クラウドプラットフォーム | AWS, Azure, GCP, etc... | |
| ワークフローエンジン | Digdag, Airflow, etc... | |
| ETLツール | Embulk, Fluentd, etc... | |
| ITセキュリティ | セキュリティ全般 | セキュリティ基礎知識, プライバシー, 攻撃と防御手法, 暗号化技術 |
3.6. ⑤ 分析レポート作成
分析レポートとは、分析結果を相手に分かりやすくまとめたレポートです。
分析では、何かしらの目的が必ずあります。目的を達成するために、データを探索し、仮説を立て、またデータを用いて仮説を検証し、検証結果に応じて意思決定をします。
分析レポートは、どういった目的で、何を実行して、何がわかったのか、次にどのようなアクションをとるべきなのか、といった情報をデータ分析の依頼元(主に、意思決定者)に分かりやすく伝えるための手段です。
どんな職種を目指す人に向いているか
- データサイエンティスト
- BIエンジニア
- プリセールス
- ビジネスアナリスト
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| 分析内容を記述したドキュメントや記事(JupyterNotebook形式でまとめた場合) | GitHubで公開 |
| 分析内容を記述したドキュメントや記事(PowerPointなどプレゼンテーション形式でまとめた場合) | SlideShareやSpeakerDeckで公開 |
| 分析内容を記述したドキュメントや記事(ブログ記事としてまとめた場合) | 自身のブログや技術ブログサービスで公開 |
アピールしたいポイント
- 適切な課題設定ができること
- 設定した課題に対して、妥当なアプローチをとっていること
- 妥当な論理展開がなされていること
- 数学的、統計学的に誤りのない展開がなされていること
必要な要素技術を表すキーワード
| 大分類 | 中分類 | キーワード |
|---|---|---|
| ビジネス | 行動規範 | ビジネスマインド, データ倫理, コンプライアンス |
| 論理的思考 | MECE, 構造化能力, 言語化能力, ストーリーライン, ドキュメンテーション, 説明能力 | |
| 着想・デザイン | データビジュアライゼーション | |
| 課題の定義 | KPI, スコーピング, アプローチ設計 | |
| データサイエンス | データ可視化 | 方向性定義, 軸だし, データ加工, 表現・実装技法, 意味抽出 |
| データの理解・検証 | 統計情報への正しい理解, データ確認, 俯瞰・メタ思考, データ理解, データ粒度 | |
| 意味合いの抽出、洞察 | 因果, 認知バイアス, 帰納的推論, 演繹的推論 | |
| その他 | ライティング | テクニカルライティング |
第2部 第4章 ユーザー検索プロジェクトの紹介
前章までで、「データサイエンティストに転職するためのポートフォリオ作成」の概略をご説明しました。第2部では、実際のプロジェクトを参考に、ポートフォリオ作成ガイドに入ります。
ポートフォリオの具体的な作成手段をいきなり説明する前に、今回のポートフォリオのベースとなっているユーザー検索基盤に関して紹介させて頂きます。全体像を把握して頂くことで、各ポートフォリオがどのような役割を果たしているのかのイメージを持って頂けるので、5章以降のポートフォリオの解説に関する理解度を深めて貰うためです。
第4章で本記事で題材とするユーザー検索基盤の目的と課題の概要、ユーザー検索基盤のシステムの全体像をご説明します。その後、第5章以降でポートフォリオの類型ごとの作成方法をご説明させて頂きます。
4.1. ユーザー検索基盤とは?
ポートフォリオの作成に入る前に、本記事で扱うサンプルの分析プロジェクト、「ユーザー検索プロジェクト」をご紹介します。
ユーザー検索プロジェクトは、データラーニングギルド(*1)内で実際に取り組んでいるプロジェクトです。このプロジェクト内で開発するシステムをユーザー検索基盤と呼んでいます。
*1:データラーニングギルド・・・株式会社データラーニングが運営する日本最大級のデータ分析人材のコミュニティ
4.2. ユーザー検索プロジェクトの背景・課題
データラーニングギルドのSlackには約170名のメンバーがいます。日々、様々な分野に関する情報が投稿され、各メンバーの多様なバックグラウンドに基づいた考察や議論がなされています。
データラーニングギルドの特徴をまとめると以下のようになります。
- データサイエンスに関するコミュニティのため、取り扱われるトピックの幅が非常に広い
- 多様な技術的バックグラウンドを持つ約170人のメンバーで構成されている
これにより、「誰がどのような技術トピックに詳しいのか、興味を持っているのかが分からない」という現象が起きていました。
仮に、任意の技術トピックに詳しいメンバーが分かっていれば、適切な回答を得られる確率が向上します。また、任意の技術トピックに興味を持っているメンバーが分かっていれば、勉強会を開く時に勧誘した方がいいメンバーが分かりやすくなる、といったメリットを享受することができます。
そこで、「誰がどのような技術トピックに詳しいのか、興味を持っているのかを教えてくれるシステム(基盤)をつくる」というユーザー検索プロジェクトが立ち上がりました。
4.3. 自然言語処理を用いた解決アプローチ
ユーザー検索プロジェクトでは、前節の課題を以下の手順で解決しようと試みています。
- Slackの会話情報からユーザーの発言内容の特性を数値化する
- 任意の技術トピックを数値化する
- ユーザーの発言内容の特性と任意の技術トピックをマッチングする
上記の手段を用いる理由はいくつかあります。分析の視点と学習の視点に分けて説明します。
分析の視点
- 各メンバーに興味のある技術トピックを挙げてもらう場合、アンケートを取る側も答える側も膨大なコストを要する
- 日々様々な技術トピックに関する議論がなされているSlackの会話情報には、各メンバーの興味のある技術トピックを割り出す為の特徴が含まれている可能性が高い
学習の視点
- 自然言語処理に関する学びを得られる
- Slackの会話情報は、ノイズを含んだデータなのでデータ分析の実践演習になる
以降の章では、このユーザー検索プロジェクトをサンプルとして扱っていくこととします。
4.4. ユーザー検索機能の使い方
ここからは、ユーザー検索基盤のロジックにフォーカスして、各種機能の使い方、システム全体のアーキテクチャや各部の役割を簡単に説明していきます。システムの全体像を把握していただくことで、第6章の具体的なシステム構築手段の話にスムーズに入っていけるようにすることが狙いです。
まずは、ユーザー検索基盤を用いた「任意トピックに詳しいユーザーリストの取得」イメージを示します。本記事では、この機能をユーザー検索機能と呼称します。
下図のように、Slashコマンド で質問文を入力すると、当該内容に関心のある、または熟知している可能性の高いユーザーの名前がスコアと共に返ってくる機能です。
Slashコマンドとは、Slackに搭載されているカスタマイズ機能の一つです。Slackのチャット画面で「/(スラッシュ)」から始まるコマンドを入力することで様々な処理を実行することができます。
詳細は、Slack のスラッシュコマンドをご参照ください。
本機能は、2つのステップから成ります。
(1)SlackのSlashコマンドで質問文を投稿する
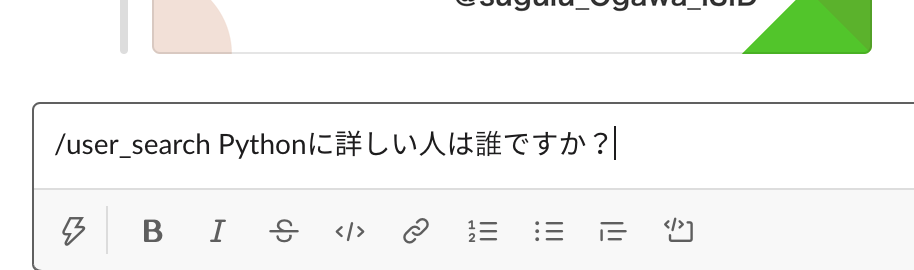
「/user_search」というコマンドを入力し、引数に質問文(例では、「Pythonに詳しい人は誰ですか?」)を入力しています。

コマンドを入力すると、バックグラウンドで処理が実行されている旨のメッセージがBotから返ってきます。(例では、「Working on it! ![]() 」)
」)
(2)質問した内容に詳しいメンバーのレコメンド結果がBotから返される

Slashコマンド入力後、しばらくするとレコメンド結果が返ってきます。レコメンド結果の情報は、ユーザーの名前とメンション、おすすめ度を示すスコアから構成されます。
4.5. ユーザー検索ロジックの説明
本節では、ユーザー検索のロジックを説明します。次の図は、ユーザー検索基盤のロジックを模式的に表したものです。
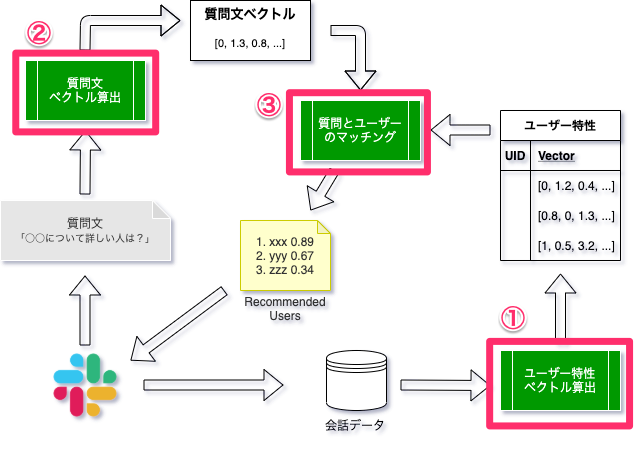
ロジックのポイントは大きく3つあります。
- Slackでの会話データからユーザーごとの特性ベクトルを算出するロジック(図中①)
- 任意トピックに関する質問の特性ベクトルを算出するロジック(図中②)
- 質問特性にマッチするユーザーをレコメンドするロジック(図中③)
4.5.1. 自然言語処理基礎〜文章のベクトル化
それぞれのロジックを解説する前に、少しだけ自然言語処理技術の基本について触れておきます。
自然言語とは、私達が日常的な会話や文章作成時に使う言語情報を指します。自然言語処理とは、自然言語を入力として、様々な課題解決を試みる学術分野です。代表的な技術として、形態素解析、構文解析、意味解析、文脈解析などがあります。
文章、つまりテキストデータは、構造化されていないデータです。構造化されていないデータは、四則演算などの数値計算に適用することができず、様々なアルゴリズムの恩恵を受けられません。
したがって、構造化され、かつ様々な数値演算アルゴリズムの適用をするには、ベクトル情報に変換する必要があります。
機械学習モデルを用いて文章をベクトル化する際の流れは、おおよそ以下のようになります。
| ステップ | 処理の概要 |
|---|---|
| データセット用意 | 対象となるデータセットをプログラムで扱える形式で準備します。 |
| 学習 | |
| クリーニング処理 | 文章に含まれるノイズを除去します。今回のケースにおける代表的なノイズは、スタンプやメンションの文字列なので、そういった文字列を除去します。 |
| 文章の単語分割 | 文章を単語ごとに区切ります。ほとんど同じ意味で形態素解析という表現が使われることもあります。形態素解析エンジン(Mecab)など 、辞書(IPAdic)を用いて文章を単語に分割します。 |
| 単語の正規化 | 単語の表記のばらつきを正します。ほとんど同じ意味で名寄せという表現が使われることもあります。文字種の統一、数字の置き換え、辞書を用いた表記ゆれの修正、口語表現の代表化などの処理を行います。 |
| ストップワード除去 | 文章からストップワード(文章の意味理解や特徴抽出に役立たない語)を除去します。代表的なストップワードは、「あなた」「です」「ます」など指示代名詞や助詞といった機能語です。 |
| 文章のベクトル化 | ベクトル化のための手法を用いて文章をベクトル化します。代表的な物では、単語の出現頻度を単純にカウントしただけのカウントベクタライザなど手法があります。 |
このように、ベクトル化を行う前に、非常に多くのステップが存在します。次節からは、ユーザー検索基盤の各モジュールのロジックに触れていきます。
4.5.2. ユーザーごとの特性ベクトルを算出する
ベクトルを算出するための前処理が完了したら、ユーザーごとの会話情報を元に各ユーザーの特性を表すベクトル情報を算出します。ユーザー検索プロジェクトでは、Doc2Vecというアルゴリズムを用いてベクトル化しています。
Doc2Vecは、GoogleのQuoc Le氏らによって発表された文章を固定長のベクトルに変換するアルゴリズムです。Doc2Vecのアルゴリズムを使うことで、単語を以下のように低次元に圧縮することができます。
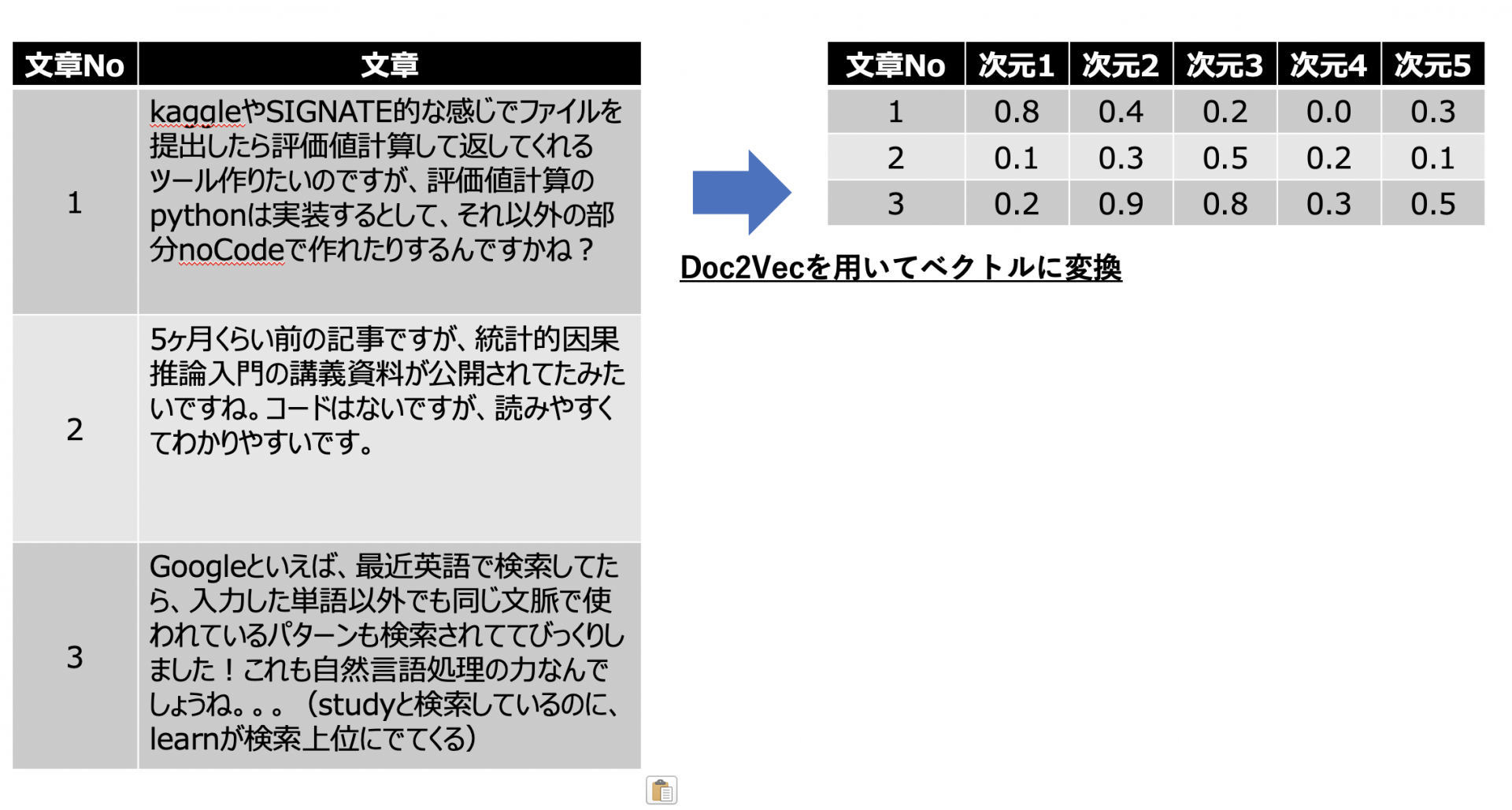
Doc2Vecの詳細なロジックに関しては、割愛しますが、以下のようなDoc2Vecには以下のようなメリットがあるため、今回はDoc2Vecによるベクタライズを採用しました。
- 低次元にベクトルを圧縮することができるので、類似度計算を行う際に次元の呪いに陥りにくい
- ユーザー単位、文章単位でベクトル化を行うことができる
質問文のベクトル化に関しても、同様に質問文データを元にDoc2Vecを用いてベクトルの算出を行っています。
4.5.3. 質問特性にマッチするユーザーをレコメンドする
質問特性にマッチするユーザーをレコメンドする流れとしては、下図のようになっています。4.6.2項のロジックで算出した各ユーザーの特性ベクトルと質問文のベクトルを比較して、類以度が高いユーザーをマッチ度の高いユーザーとして判定するようなロジックで構築されています。類似度の計算後、図中のレコメンドの条件に従って、レコメンドするユーザーを決定します。
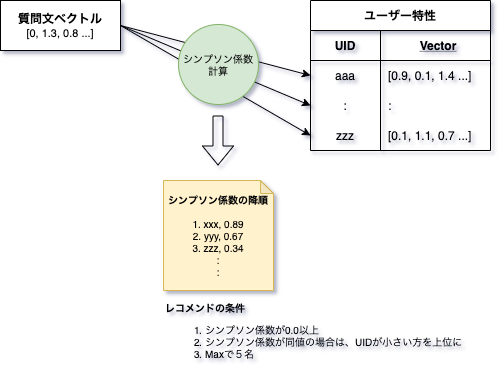
ユーザー検索ロジックに関しては、このようにユーザーの投稿メッセージと質問文をベクタライズし、それを比較することで実現されています。データの前処理やベクタライズの処理に自然言語処理への理解が、ユーザーのマッチングの部分に類似度計算の理解が必要になってくることが分かったかと思います。
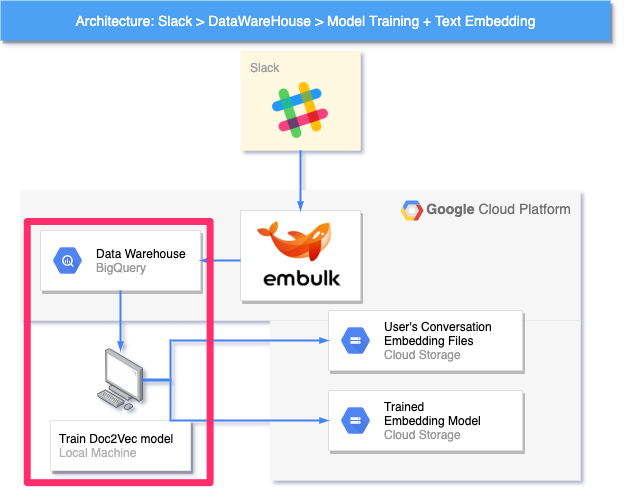
4.6. ユーザー検索基盤全体アーキテクチャ
前節で解説したロジックをslackから呼び出せるようにした、ユーザー検索基盤全体のシステムアーキテクチャ図についてご説明します。
システムアーキテクチャ図とは、それなりに規模の大きなシステムを構築・運用する際によく使われる可視化手段の一つで、システムを構成する要素の一覧と要素ごとのつながりを明確にするものです。
ユーザー検索基盤のアーキテクチャは、大きく「推論モジュール」「ベクトル算出モデル/ユーザー特性ベクトル作成モジュール」という2つのモジュールで構成されます。
推論モジュール
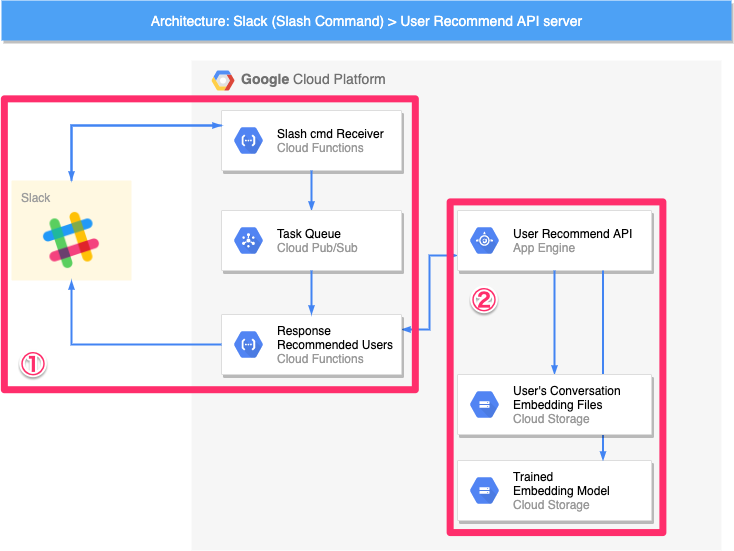
本モジュールは、4.4.節で示した「ユーザー検索機能」を実行したタイミングで動作するモジュールで、大きく2つのグループ(図中①②)に分けることができます。
① Slackとやりとりする部分
SlackとHTTPリクエスト/レスポンスを介して、直接やりとりする部分です。SlackからのHTTPリクエストを受け付ける Slash cmd Receiver と Slackに推論結果をPOSTリクエストで送る Response Recommended Users が主なパーツです。Task Queue については、後述します。
② 推論処理の核となる部分
前節のロジックに基づいてレコメンドするユーザーを推論する核の部分です。推論に用いるファイルが2つのオブジェクトストレージ(User's Conversation Embedding Files / Trained Embedding Model)に格納されており、これらを利用して、WebAPI(User Recommend API)がレコメンド結果を返します。
ベクトル算出モデル/ユーザー特性ベクトル作成モジュール
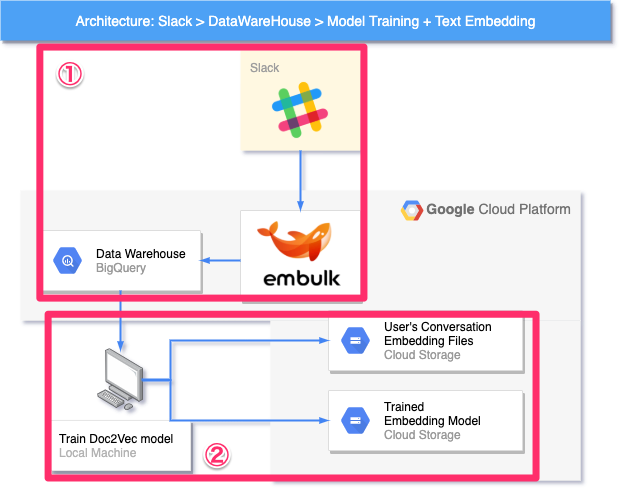
本モジュールは、ユーザー検索機能を実現するための準備をするモジュールで、大きく2つのグループ(図中①②)に分けることができます。
① SlackデータをDWHに取り込む部分
データウェアハウス(Data Warehouse : DWH)とは簡単に言うと、分析用途に特化したデータの格納庫です。分析に必要なデータを様々な場所(今回で言えば Slack )から適切な周期で取り込み、分析に携わるメンバーがアクセスしやすい場所に公開します。
ここでは、データの取り込みに Embulk というオープンソースソフトウェアを利用しています。
② 学習の実行及び学習の成果物をアップロードして格納しておく部分
「学習の成果物」とは、訓練済みの機械学習モデル(Trained Embedding Model)と各ユーザーの発言特性ベクトル(User's Conversation Embedding Files)を指します。
DWHから所望のデータをロードし、機械学習モデルの訓練をローカルマシンで実行します。訓練が終わると、訓練済みモデルで(DWHからロードした)各ユーザーの発言をベクトル化し、アップロードします。また、訓練済みモデルもアップロードします。
本節では、ユーザー検索基盤全体のアーキテクチャについて概観を示しました。次節以降で、推論モジュール、ベクトル算出モデル/ユーザー特性ベクトル作成モジュールに関して解説を行いたいと思います。機械学習が関わる処理のロジックを解説し、より詳細な動作の仕組みをご説明します。
4.7. 推論モジュールの挙動解説
このモジュールでは、Slackから入力された質問文を元に、適切なユーザーをレコメンドする処理を実現します。処理の流れとしては以下のようになっています。
- Slackから質問文を送信
- 質問文のベクタライズ
- ユーザー特性ベクトルで類以度検索
- レコメンドユーザーをSlackに返信
以降、各ステップについて説明します。
4.7.1. Slackから質問文を送信
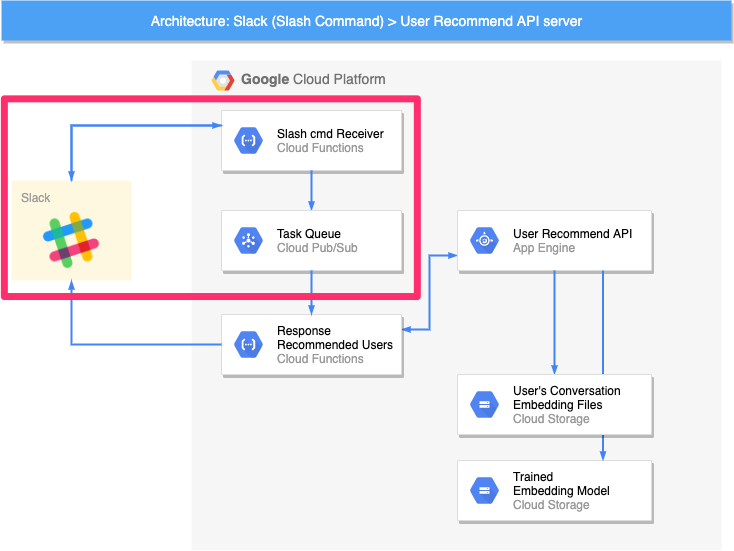
推論処理のトリガーとなる部分です。以下の4つの処理を実行することで推論モジュールの計算が開始され、Slackを処理結果が返ってくるまで待機させることができます。
- ① Slash Command で質問文をシステムに送信
- ② Cloud Functions でSlash Commandを受取
- ③ User Recommend APIに推論処理を依頼し、非同期で処理を開始
- ④ 処理が問題なく開始されたか否かをSlackに返す
※補足
実は、Slashコマンドには「3秒以内にレスポンスが返ってこない場合は、タイムアウトエラーになる」というルールがあります。そのため、本関数(図中 Slash cmd Receiver)では、APIの結果をまたずすぐにSlackにレスポンスを返し、レコメンド処理は非同期で実行する必要があるのです。
4.7.2. 質問文のベクタライズ
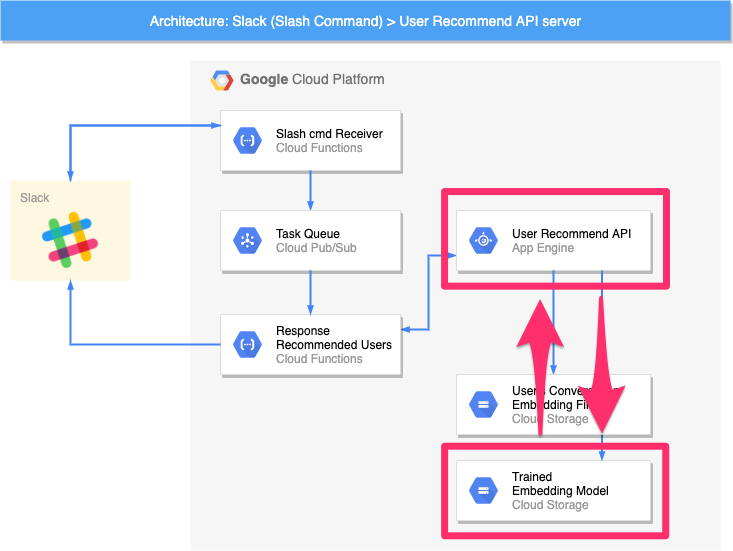
質問文をベクタライズする際には、4.5.節で解説したDoc2Vecの学習済みモデルを使用します。(図中Trained Embedding Model)学習済みモデルに関しては、次節で解説するモジュールを用いて作成したものをストレージに保存しておき、API側から読込を行うことで、最新の学習結果を元に質問文をベクタライズすることができます。
4.7.3. ユーザー特性ベクトルで類以度検索

質問文のベクタライズが完了したら、作成した質問文ベクトルをキーとして、ユーザー特性ベクトル群(図中User's Conversation Embedding Files)を検索します。質問文と最も類以度の高い発言をしているユーザーをレコメンド候補としてリスト化します。
4.7.4. レコメンドユーザーをSlackに返信
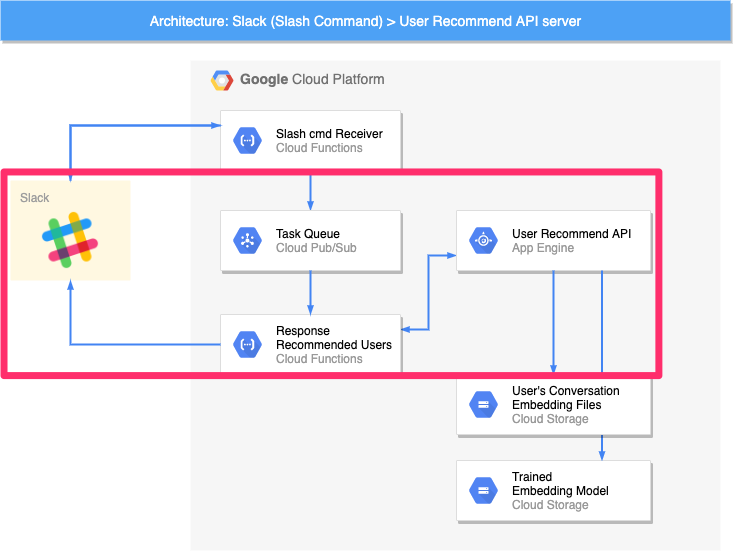
4.7.3.節で抽出したユーザーのリストをCloud Functionsを用いてSlackに返します。この処理を実行することで、Slack上に質問文に対応したユーザー一覧が表示されます。
4.8. ベクトル算出モデル/ユーザー特性ベクトル作成モジュールの挙動解説
このモジュールでは主に以下の処理を実現することで、ユーザー検索基盤のデータを最新にし、最新のデータに基づいたユーザーベクトル、ベクトル算出モデルを作成します。
- Slackの会話情報を(日次で)DataWareHouseに記録
- DataWareHouseのSlack会話データを元にDoc2Vecモデルを学習
- 学習済みDoc2Vecモデルと各ユーザーの特性ベクトルをアップロード
以降、各ステップについて説明します。
1. Slackの会話情報を(日次で)DataWareHouseに記録
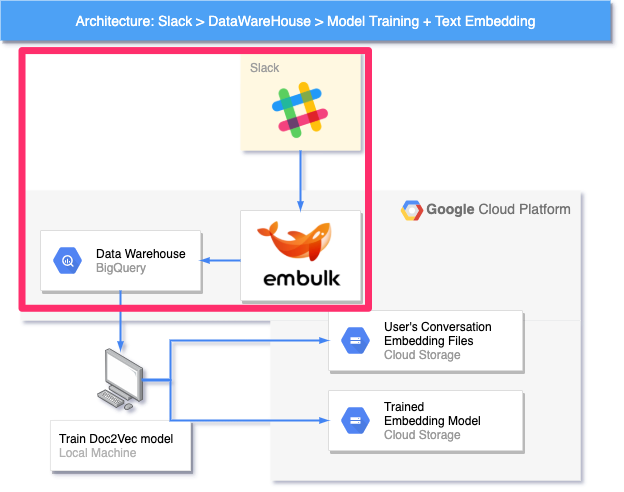
オープンソースの ETLツール であるEmbulkを利用して、Slackの会話データを分析処理に使いやすい形でDataWareHouse(BigQuery)に保存します。この処理を日次で実行することにより、DWHに蓄積されるデータを日々最新のものにすることができます。
2. DataWareHouseのSlack会話データを元にDoc2Vecモデルを学習
この処理では、DWHに蓄積されている最新のデータを元に、Doc2Vecモデルを学習させます。この処理に関しては、クラウド上ではなく、ローカルのPC上で学習処理を実行しています。モデル作成のために、以下の3つの処理を実行します。
- ① データセット作成
- DataWareHouseからユーザーごとの会話データをロード
- 前処理(2.1.1)と単語に分割
- ② 学習
- データセットを用いてDoc2Vecの重みを更新する
- ③ ユーザーの特性ベクトルを計算
- 作成したDoc2Vecと最新の会話データを元にユーザーの特性ベクトルを再計算
※会社で作成するような場合だと、学習時のみスポットで利用するGPUインスタンスを作成するなどの選択肢も考えられますが、今回は予算と開発時間の兼ね合いからローカルマシンで学習させるという選択肢を取っています。ポートフォリオとして考えた場合、全てがクラウドで完結した方がベターではあるので、今後改善予定のポイントです。
3. 学習済みDoc2Vecモデルと各ユーザーの特性ベクトルをアップロード
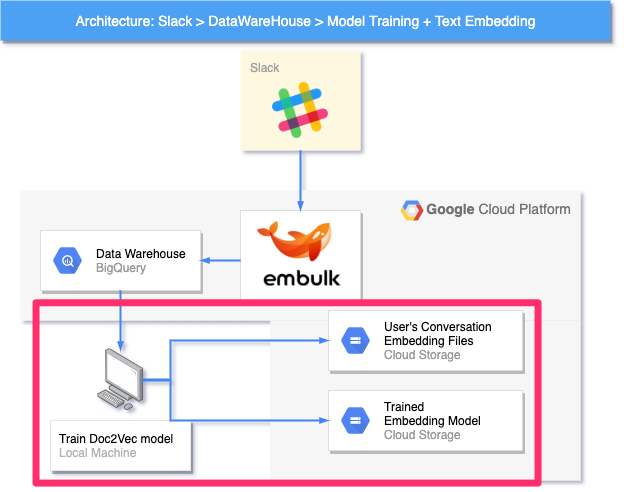
直前のステップで作成した学習済みモデル(図中Trained Embedding Model)と各ユーザーごとの特性ベクトル(図中User's Conversation Embedding Files)をCloud Storageバケットに、アップロードします。
このような手続きでアップロードした「学習済みモデル」と「ユーザー特性ベクトル群」を推論モジュール(5.3)で利用するという仕組みになっています。
ここまでの説明で、あくまでも概要ではありますが、ユーザー検索基盤の全体的な構造がわかったかと思います。
4.9. ユーザー検索プロジェクトとポートフォリオの関係
こちらのユーザー検索プロジェクトですが、3章で解説したポートフォリオの類型に関して、ほぼほとんどの領域をカバーする内容となっています。以下に、ポートフォリオの類型とユーザー検索基盤の対応を記載します。
| ポートフォリオの類型 | ユーザー検索基盤を元にしたポートフォリオ |
|---|---|
| ①機械学習モデルの作成 | Slackの会話データを元に、質問文とユーザーをマッチングするモデル |
| ②機械学習モデルを用いたWebサービス | 質問文のベクタライズ結果、レコメンド結果を返すAPI |
| ③データ監視用のダッシュボード | DWHに蓄積されたデータを元にしたユーザー傾向把握のためのダッシュボード |
| ④データ収集・前処理のためのパイプライン | SlackのAPIからDWHへデータを日次更新するパイプライン |
| ⑤分析レポート | DWHに蓄積されたデータを元に分析したレポート |
5章以降で、ユーザー検索プロジェクトで開発した内容を元にポートフォリオを作成する場合、どのような所に気をつけて作成すれば良いのかを解説していこうと思います。
第2部 第5章 ①機械学習モデルの作成
5章以降では、4章で紹介したユーザー検索基盤を例にとり、3章で紹介したポートフォリオ5種類に関して具体的なアウトプットや作成手順を解説していきます。ポートフォリオとしてどのようなものを作成すれば良いかを中心にするため、各ポートフォリオのサンプル、作成手順のステップなどに関しては、今回の記事では割愛させて頂きます。
各ポートフォリオのサンプル、作成手順の解説記事に関しては、希望される方が多いようでしたら今後別の記事にて執筆する予定です。
解説に関してはそれぞれ独立した内容となっていますので、ご自身の興味のあるポートフォリオに関して解説を読んで頂ければと思います。
5.1. 概要
まず最初に、今回のユーザー検索プロジェクトのコアとなるロジックである、Slackの会話情報をベクタライズする機械学習モデル作成に関するポートフォリオ作成を解説します。
ユーザー検索プロジェクトの検索ロジックは以下のような仕組みで「質問文に詳しそうな人をピックアップする。」という機能を実現するロジックでした。
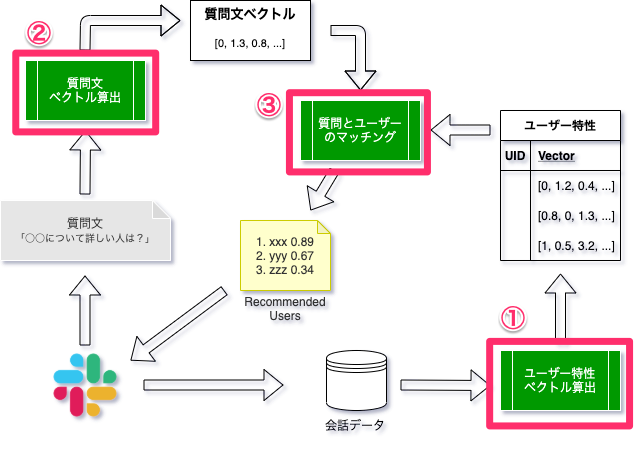
その中で、①〜③のそれぞれのロジックは、以下のようなロジックを担っています。
- Slackでの会話データからユーザーごとの特性ベクトルを算出するロジック(図中①)
- 任意トピックに関する質問の特性ベクトルを算出するロジック(図中②)
- 質問特性にマッチするユーザーをレコメンドするロジック(図中③)
これらのロジックを元にポートフォリオを作成するに当たって、どのような所に注意すれば評価されるポートフォリオを作ることができるのでしょうか?
ここで一度3.1.節に記載した内容を再掲しますので、アウトプットの形式、アピールしたいポイントに関して振り返ってみましょう。
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| 構築したモデルの解説 | 記事形式でまとめて、オンラインで見れる所にまとめてURLを共有 |
| モデル学習・予測用コード | Jupyter Notebook形式でGitHubに公開 |
| モデルの検証用コード | Jupyter Notebook形式でGitHubに公開 |
| 構築したモデルの実行方法 | GitHubのreadme.mdなどに記載 |
| 構築したモデルの検証結果 | 記事形式でまとめて、オンラインで見れる所にまとめてURLを共有 |
アピールしたいポイント
- 機械学習で解くべき課題設定の妥当性
- 課題を機械学習の問題へ落とし込む際の妥当性
- 実装コードの可読性
- ベースラインとして使うモデルの妥当性
- モデルのチューニングの妥当性
- 利用するデータの前処理の妥当性
- 性能を評価する指標を適切に選択していること
- 設定した問題に対して良い性能を出していること
5.2. ポートフォリオ作成のポイント
それでは、上記のアウトプットにおいてアピールしたいポイントに関して解説していきたいと思います。以下のポイントに気をつけることで、課題設定〜モデルの評価までの一連の流れがより良いものとなるはずです。
具体的な課題に紐付いていて解決しやすいテーマを選ぶ
機械学習のポートフォリオを作るに当たって、一番難しいと言っても過言ではないのが「テーマ選び」です。こちらに関しては、なんとなく身近なテーマであったり、勉強した内容に近いテーマを選んでしまいがちです。このテーマ選びが大きく結果を左右すると言っても過言ではありません。個人的には、テーマ選びに2〜3割くらいの時間を割いても良いくらいだと思います。
何故そんなにテーマ選びが重要なのかというと、テーマ選定によってアピールできるポイントが決まるからです。例えば、「写真を元にどこのラーメン店か当てる」というネタ寄りの機械学習のモデルを作った場合、面白さはありますが、「課題に対して適切なモデルを作れる人なのか?」という疑問に対しては評価することが難しくなってしまいます。
また、課題設定とデータ選定が適切ではないため、機械学習のモデルとしては適切なアプローチを取っているにも関わらず、全く予測成果が芳しくないという結果になる可能性もあります。
そういった事態を避けるためにも、「具体的な課題に紐付いていて」、「解決しやすい」テーマを選ぶことが重要になってきます。あくまで目安ではありますが、以下のような所を気をつけると良いでしょう。
例えば、今回のユーザー検索プロジェクトの場合はポートフォリオ作成において、以下のようなメリットがあります。
- コミュニティの具体的な課題に紐付いている
- アウトップットがユーザーのランキングという形で見えるのでイメージしやすい
- ベクトル化する処理の中でディープラーニング系の技術を使用できる
- 仮にレコメンドの精度が良くなかったとしても、レコメンド機能自体は実現できる
このように、評価されやすい課題を設定することがポートフォリオ作成における重要な第一歩となります。
機械学習の一連の流れをカバーする
機械学習モデルのポートフォリオでは、「機械学習の一連のプロセスをカバーする」という所を意識して取り組んでみると良いかと思います。
教師あり学習であれば、以下のような流れで機械学習モデルを開発することが一般的かと思います。(参考:『Pythonで儲かるAIをつくる』(著:赤石雅典))
1. データ読み込み
2. データ確認
3. データ前処理
4. データ分割
5. アルゴリズム選択
6. 学習
7. 予測
8. 評価
9. チューニング

機械学習をするに当たって、アルゴリズム選択〜評価までのプロセスが評価されがちですが、実際の業務に当てる時間は、データの準備や前処理、チューニングに当てる時間の方が長かったりします。そのため、一連の流れをカバーできるようにすると良いでしょう。
使用する技術に関しても、SQLを利用できることをアピールするために、前処理の部分はSQL、その後の特徴量エンジニアリングはPythonを使って行うなどの工夫をすることで、幅広い技術をアピールすることもできます。
ユーザー検索プロジェクトの場合は教師なし学習で次元圧縮と類似度計算が主なロジックとなるため、以下のような流れとなります。
1. データ読込・データ前処理
2. ベクトル化モデルの学習
3. ユーザーごとの発言全体のベクトルを算出
4. ユーザー検索シミュレータを実装
5. 動作確認
ユーザー検索プロジェクトの場合は教師なし学習なので、流れが少し違いますね。自然言語処理ならではの辞書管理、固有名詞抽出や設定、ストップワードの設定、抽出する品詞の選定などを行ったりする点が前処理としてのアピールポイントになるかと思います。
また、教師なし学習だから評価ができないという訳ではなく、定性的な評価方法、教師なし学習に関するどのような定量指標などを用いることで評価のプロセスも追加することができます。評価しにくい教師なし学習を適切に評価することができれば、それもまたアピールポイントになるかと思います。
ユーザー検索プロジェクトの場合、定性評価をスピーディーに行うため、以下のような簡単な計算結果を返すための仕組みを構築しています。(4.ユーザー検索シミュレータ)
コマンドラインから入力された質問文に対して、ユーザー名と類似度を返すpythonスクリプトで、例えば以下は「Pythonに詳しい人は誰ですか?」という質問に対する類似度の検索結果です。
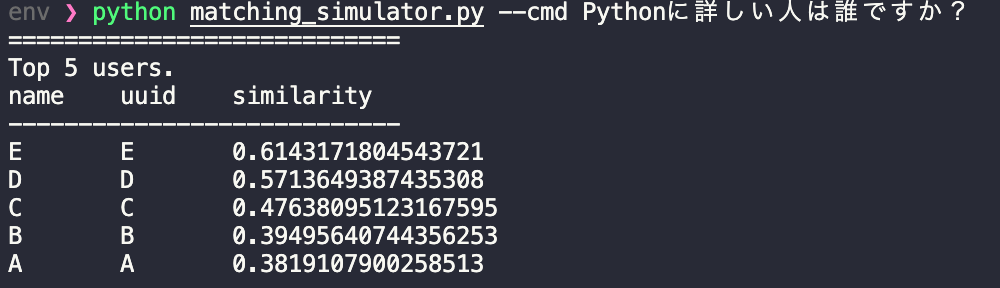
以下が検索の元になっているサンプルデータです。E〜Aの順に「Pythonが好き」というフレーズがより多く含まれているので、想定した通りの動きが期待できそうです。
[
{
name: "A",
talk: "Pythonが好き。Javaが好き。Javaが好き。Javaが好き。Javaが好き。"
},
{
name: "B",
talk: "Pythonが好き。Pythonが好き。Javaが好き。Javaが好き。Javaが好き。"
},
{
name: "C",
talk: "Pythonが好き。Pythonが好き。Pythonが好き。Javaが好き。Javaが好き。"
},
{
name: "D",
talk: "Pythonが好き。Pythonが好き。Pythonが好き。Pythonが好き。Javaが好き。"
},
{
name: "E",
talk: "Pythonが好き。Pythonが好き。Pythonが好き。Pythonが好き。Pythonが好き。"
}
]
このように、評価であったりシミュレーションの仕組みであったりまで準備することで、より実践を意識した開発ができているということをアピールすることができます。モデルの構築だけではなく、運用や改善までを視野に入れた、できる限り幅広い領域をカバーしたポートフォリオを構築できるように意識してみましょう。
5.3. アウトプットイメージ
構築したモデルの解説・検証結果
モデル作成のポートフォリオに当たって、一番大事になってくるのがこちらのモデル解説かと思います。「予測モデルを作りました!」と言われてコードを提出されても、見る側としては妥当性の判断のしようが無いからです。Web開発やクリエティブのポートフォリオの場合は目に見えるものがあるので、それを起点に評価ができますが、データサイエンスの場合は簡単に目に見える訳ではありません。そのため、構築したモデルの解説が重要になってきます。
構築したモデルの解説には、以下のような内容が盛り込めると良いかと思います。
- どのような課題があり、何を解決するためのモデルなのか?
- 何故その課題に取り組もうと思ったのか?
- その課題が解決できるとどのように嬉しいのか?
- どのような技術や手法を用いて実現したのか?
- どのようなアプローチで基礎分析・モデル構築を進めたのか?
- そのモデルの結果はどうだったのか?
例えば、今回のユーザー検索プロジェクトの場合、以下のような章立てで作成することで魅力的なモデル解説を作ることができます。
| 見出し | 概要 |
|---|---|
| 背景・課題・概要 | slackコミュニティにおいて、誰がどんな話題に詳しいか分からないという課題があり、その解決方法として検索ロジックを開発したこと、slackの発言ログを元にマッチングアルゴリズムを開発したことを記載 |
| 活用イメージ | slackにおいて、どのような形で利用されるのかのイメージを画面キャプチャなどを使用して解説、コミュニティでの交流を促すという副次的なメリットも記載 |
| 今回構築したロジック | ユーザー検索プロジェクトの全体の概要ロジック(概要に掲載した図)を元にロジックの解説を記載 |
| ユーザー特性ベクトル算出の仕組 | ユーザー特性ベクトル算出の仕組、使用するアルゴリズムなどを記載 |
| 今回のロジック作成に用いたデータ | どのようなデータを用いたかに関する情報を記載、基礎統計のサマリーも記載 |
| 質問文ベクトル算出の仕組 | 質問文ベクトル算出の仕組、使用するアルゴリズムなどを記載 |
| 質問文とユーザーのマッチング方法 | 質問文ベクトル算出の仕組、使用するアルゴリズムなどを記載 |
| 各種ロジックの検証方法 | どのような方法を用いてベクトル算出、マッチ度合いの妥当性を検証したのかを記載 |
| 各種ロジックの検証結果 | 上記検証方法に基づいてどのような検証結果になったのかを記載 |
| マッチ度合いの高い文章の例 | 実際に質問文に対してマッチ度が高いユーザーをピックアップし、ユーザーのコメント例を記載 |
| 課題点と考察、今後のアプローチ | 上手くいった点、行かなかった点をとりまとめ、次のステップとしてどのようなことに取り組めば良いかを記載 |
| 個別の詳細な実装方法 | 各種ロジックなどの細かな実装方法、データクリーニング、はずれ値や異常値の処理、ロジックで工夫した点などを記載 |
部分的に4章5節(ロジックの解説)に近い内容になるので、そちらの解説などを見て頂くとなんとなくイメージが付くのではないかと思いますので、そちらも参考にしてみてください。
モデルの学習・予測・検証用コード
モデルの学習、予測用コード、検証用コードに関してはJupyter NotebookやPython、Rコードなどを共有することになります。ここで気をつけなければいけないのは、採用側のエンジニアの方は、じっくりとコードの内容まで深堀りしてレビューする時間がないということです。会社によって採用にかける時間は様々なので、一概に言える訳ではないのですが、少なくともある程度選考が進むまでは、コードの詳細まで読み込んで貰えないものだと考えて良いでしょう。
そのため、**パッと見てどのような処理をおこなっているか分かるようする工夫が重要になってきます。**開発用のコードというより、解説記事や仕様書のような形でJupyter Notebookに記載ができると良いでしょう。
その上で、以下のようなポイントに気をつけてコーディングを行えると良いかと思います。
- 可読性の高いコードが書けているか?
- リファクタリングはしっかりと行っているか?
- ソースコードの解説は適切か?
- 適切にライブラリを活用できているか?
- 多重ネスト構造などのパフォーマンスが悪いコードが排除できているか?
通常のプログラミングの場合、日本語のコメントの利用に関しては議論が分かれますが、ポートフォリオの場合は評価者が分かりやすいように日本語でコメントを入力することをオススメします。
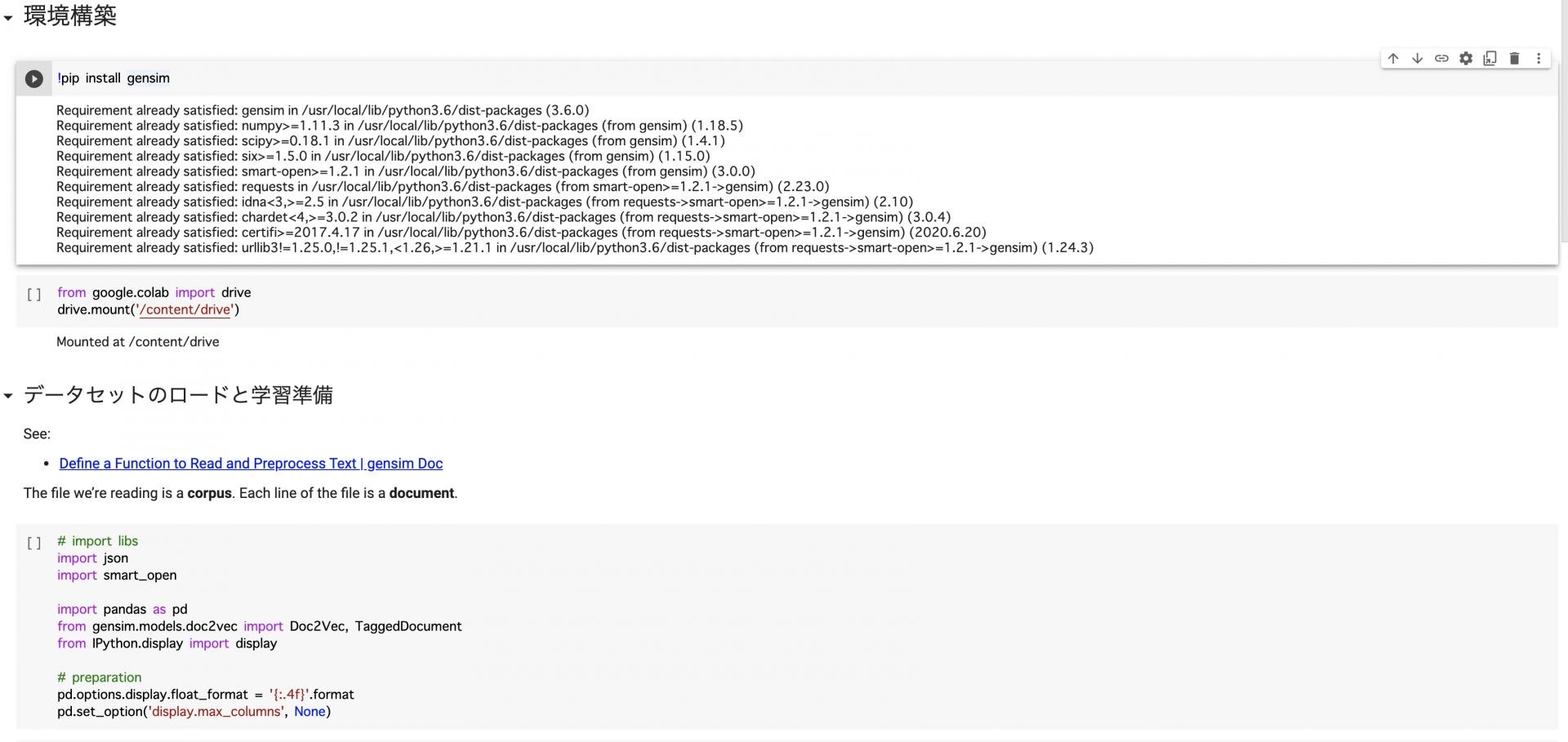
以下、notebookの可読性を高めるためのBeforeAfterを記載しますので、こちらを参考にnotebookを構築して頂ければ、評価されるポートフォリオを作成できるようになるかと思います。
Before
シンプルに環境構築、データセットのロードと学習といった処理の分割をしているのみで、初めてこのコードを見た方にはどのような意図で書かれたコードなのか、全体の処理がどういった機能を果たしているのか分からない内容となっています。読み手の側が意図を理解して読み解く必要のあるコードなので、改善が必要です。
After
修正後のコードでは、冒頭でnotebookの冒頭にどんな目的で書かれたコードなのか、どのような前提でコードが書かれているのかなどの解説と処理の流れを追加してあります。冒頭に全体感を記載することで、読み手の方に、コード作成の意図を伝えることができます。

また、それぞれの個別の処理に関しても、使用したライブラリとその用途、コードの流れ、想定しているインプットやアウトプットの解説を加えて上げることでグッとnotebookが解釈しやすいものになります。
読み手を意識したコードを書くことはポートフォリオの作成に限らず重要です。ちょっとの気遣いではありますが、このようにnotebookを修正してあげることで、作成したコードの内容も正しく伝わりますし、そういった気遣いができる人だということも伝わるので一石二鳥です。

5.4. ポートフォリオサンプル
ポートフォリオとして提出するには、もう少し解説などを追加する必要がありますが、以下にサンプルのソースコードやデータセットへのリンクを記載します。
第2部 第6章 ②機械学習モデルを利用するためのWebAPIの開発
6.1 概要
本節では、機械学習モデルをWebAPI経由で利用できるようなサービスを作ってみます。機械学習モデルは、文章データをベクタライズするモデルであれば何でも良いです。ここでは、第5章で作成したものを用いる想定で進めます。
今回作ろうとしているWebAPIの機能と周辺モジュールの動きを確認します。5.2節で説明した推論モジュールのアーキテクチャ図をもう一度見てみましょう。
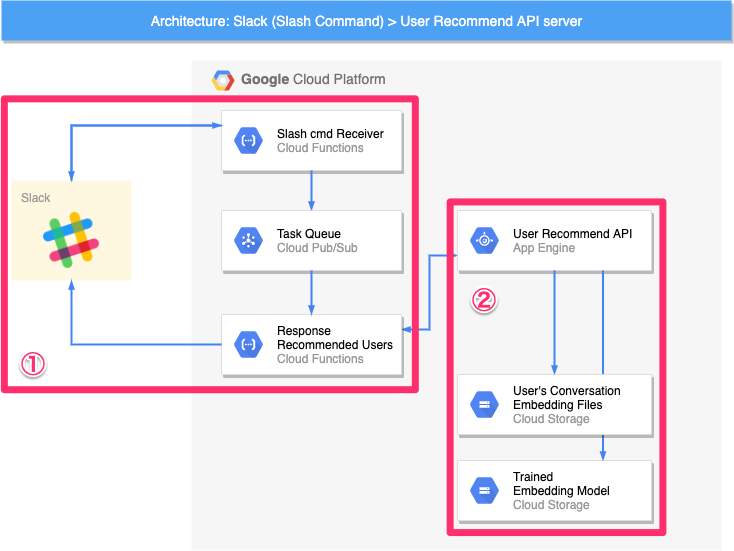
今回作るWebAPIのコア部分は上図②の User Recommend API です。周辺には、API呼び出しのインターフェイスを担うSlashコマンド、機械学習モデルを格納したクラウドストレージがあります。各セグメントの意味や役割は、「5.4 推論モジュールの挙動解説」をご参照ください。
これらのロジックを元にポートフォリオを作成するに当たって、どのような所に注意すれば評価されるポートフォリオを作ることができるのでしょうか?
ここで一度3.2.節に記載した内容を再掲しますので、アウトプットの形式、アピールしたいポイントに関して振り返ってみましょう。
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| サービス開発の内容を要約した記事 | 技術ブログサービスなどに開発内容をまとめ、公開 |
| WebAPIと仕様書 | 実装したコードをGithubで公開(WebAPI設計書と使い方をREADMEに記述) |
| 実際に操作できるWebAPI | WebAPIをサーバー上でホスティング |
アピールしたいポイント
- 納得感のあるユースケースを設定していること
- 使用している機械学習のモデルが適切であること
- 自身で作成した機械学習のモデルを用いてシステムが構築されていること
- 機械学習モデルの更新を考慮したシステム設計になっていること
- モデルを利用しやすいインターフェイスになっていること
- わかりやすいAPI設計書を記述していること(OpenAPIの形式に沿っているとなお良い)
- 実装したコードの可読性
- テストコードが必要十分に記述されていること、また妥当なテストであること
- クラウドインフラを用いてWebサービスをホスティングしていること(プロダクション環境を想定した冗長化やパフォーマンスチューニングもできているとなお良い)
- CI/CDパイプラインを構築していること
6.2 ポートフォリオ作成のポイント
それでは、上記のアウトプットにおいてアピールしたいポイントに関して解説していきたいと思います。以下のポイントに気をつけることで、設計〜サービスのホスティングまでの一連の流れがより良いものとなるはずです。
ステップ・バイ・ステップで小さく拡張していく
データサイエンティストを目指す方の中には、Web系エンジニア出身でない方も多くいらっしゃると思います。そういった方にとって、「バックエンド開発」「クラウドインフラストラクチャ構築」「サービスのデプロイ」「機械学習モデルサービング」といった複数の領域を一気に片付けようとすると、行き詰まってしまう可能性が高まるかもしれません。このような場合は、ステップ・バイ・ステップで小さく始めて、少しずつプログラムを拡張していくことをおすすめします。
今回の場合、以下のように細かいステップを踏んで、開発しました。
1. 空のAPIサーバーを作成(内部処理はダミー)
2. 空のAPIサーバーをGAEにデプロイして公開
3. 機械学習モデルをAPIサーバーから利用する
4. APIサーバーの内部処理を作る
5. Slashコマンドの全体像を整理する
6. Slashコマンドを受け取る関数を作る
7. Slashコマンドを受け取る関数でバックグラウンド処理をトリガーする機能を追加する
8. バックグラウンド処理を実行する関数を作る
9. バックグラウンド処理結果をSlackに返す機能を追加する
こうすることで、「バックエンド開発」「クラウドインフラストラクチャ構築」「サービスのデプロイ」「機械学習モデルサービング」といった複数の領域で詰まりそうなポイントを分散し、どうしようもなくなる状態を回避することが可能になります。実際の開発現場でも、小さく進めることは大切なので、現場でも活かされる知見と考えています。
他のサービスとどのように連携するかを示す
機械学習モデルを利用するWebAPIには、「機械学習タスクを実行する」部分と「機械学習基盤と連携する」部分が存在すると言えます。したがって、APIサーバー単体で完結することはなく、高確率で他のサーバーやクラウドストレージと連携します。これらの連携の様子を明確に示すことが必要と考えます。
今回の例で言えば、以下の図のように推論部分として「①Cloud Functions, Cloud Pub/Subを介したSlackとの連携」、機械学習モデルや推論に必要なメタデータを利用する部分として「②Cloud Storageとの連携」があります。
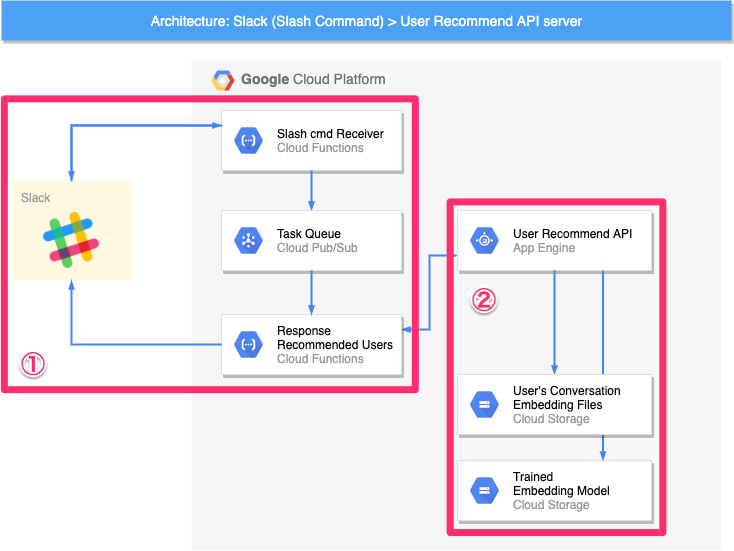
複数のサービスが連携する場合、こういったアーキテクチャの図説は必須でしょう。それに加えて、各セグメントの役割を明確にすることで、「何を考えて設計・実装したのか」という点をアピールできるかと思います。
6.3 アウトプットイメージ
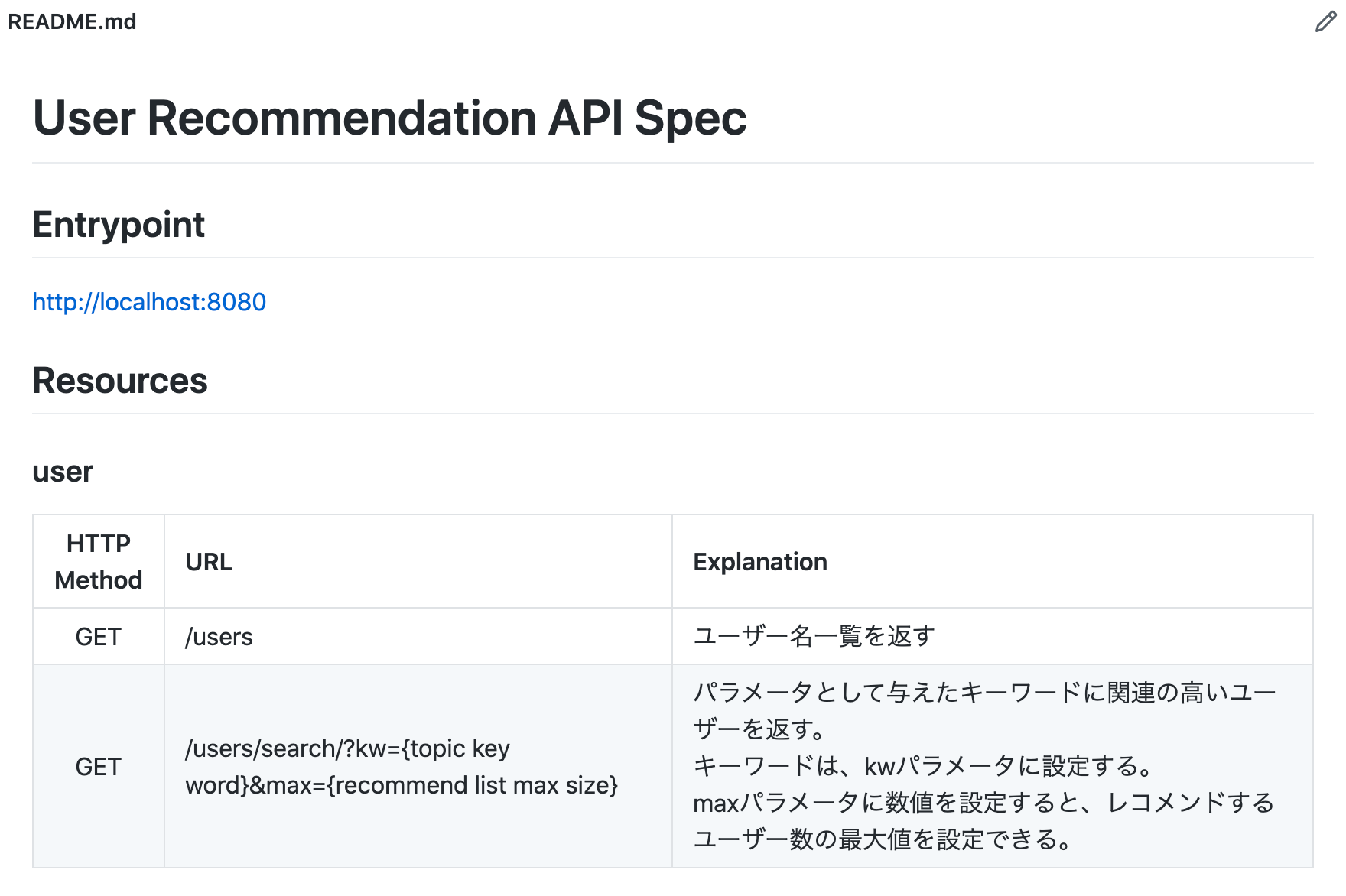
WebAPIと仕様書
WebAPIをポートフォリオとして提出した際に、採用担当者がまず目にするのがこちらかと思います。採用の初期段階では特に、ポートフォリオを隅々まで確認してもらえることは期待しない方が良いでしょう。採用担当者は、業務の合間を縫って、多くの資料に目を通さなければならないからです。したがって、短時間で全体像を把握しやすいリポジトリにすることを心がけることが大切かと思います。
具体的には、パッと見ただけで「どんなメソッドが用意されているのか」「どうやって使うのか」がわかる状態であると良いと思います。
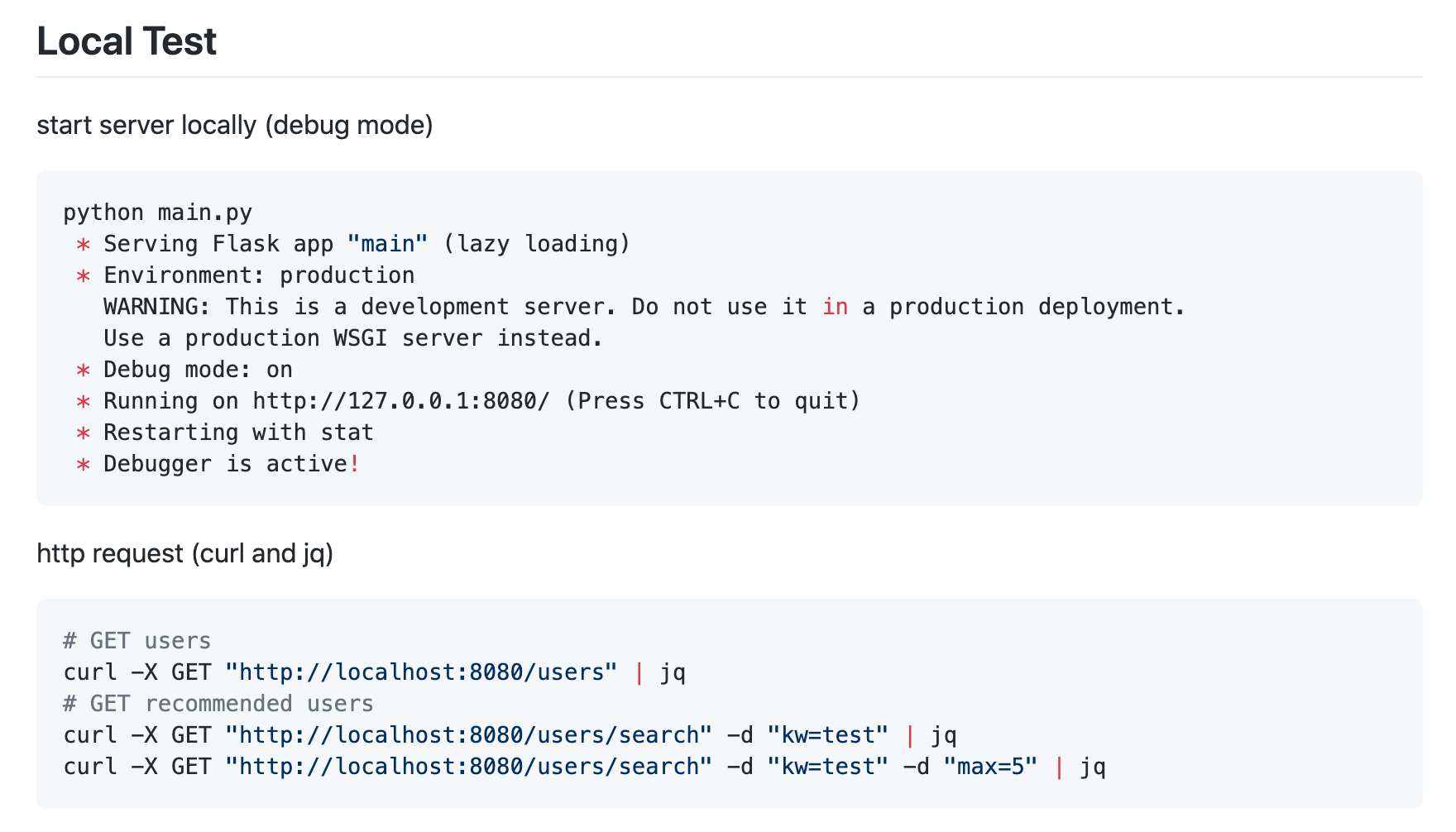
実際に操作できるWebAPI
WebAPIは、データサイエンティストを目指す方が作るポートフォリオの中で最も共有しやすい成果物と言えます。したがって、実際に操作できるWebAPIがない場合、むしろマイナス評価になりえます。(もちろん、個人製作なので費用の都合上スリープ状態にしている場合などはあると思います)
共有方法はいたってシンプルでWebAPIのホスティングURLを共有するだけで事足りるでしょう。ただし、前項に記載したAPI仕様書もセットで提供します。WebAPIに関するポートフォリオを採用担当者の方に見てもらう場合は、下図のような3つのステップが考えられます。採用の初期段階では、ソースまで細かく見てもらうことはあまり期待できませんが、それぞれ評価してもらえるように注力することが望ましいでしょう。

6.4 ポートフォリオサンプル
ポートフォリオとして提出するには、もう少しリファクタリングやテストを追加実施する必要がありますが、以下にサンプルのソースコードやデータセットへのリンクを記載します。
第2部 第7章 ③ダッシュボードの構築
7.1. 概要
本章では、Slackのログ情報を用いてオンラインコミュニティの活発度を示すダッシュボードをベースに解説します。作成する成果物としては以下のようなダッシュボードを想定しています。
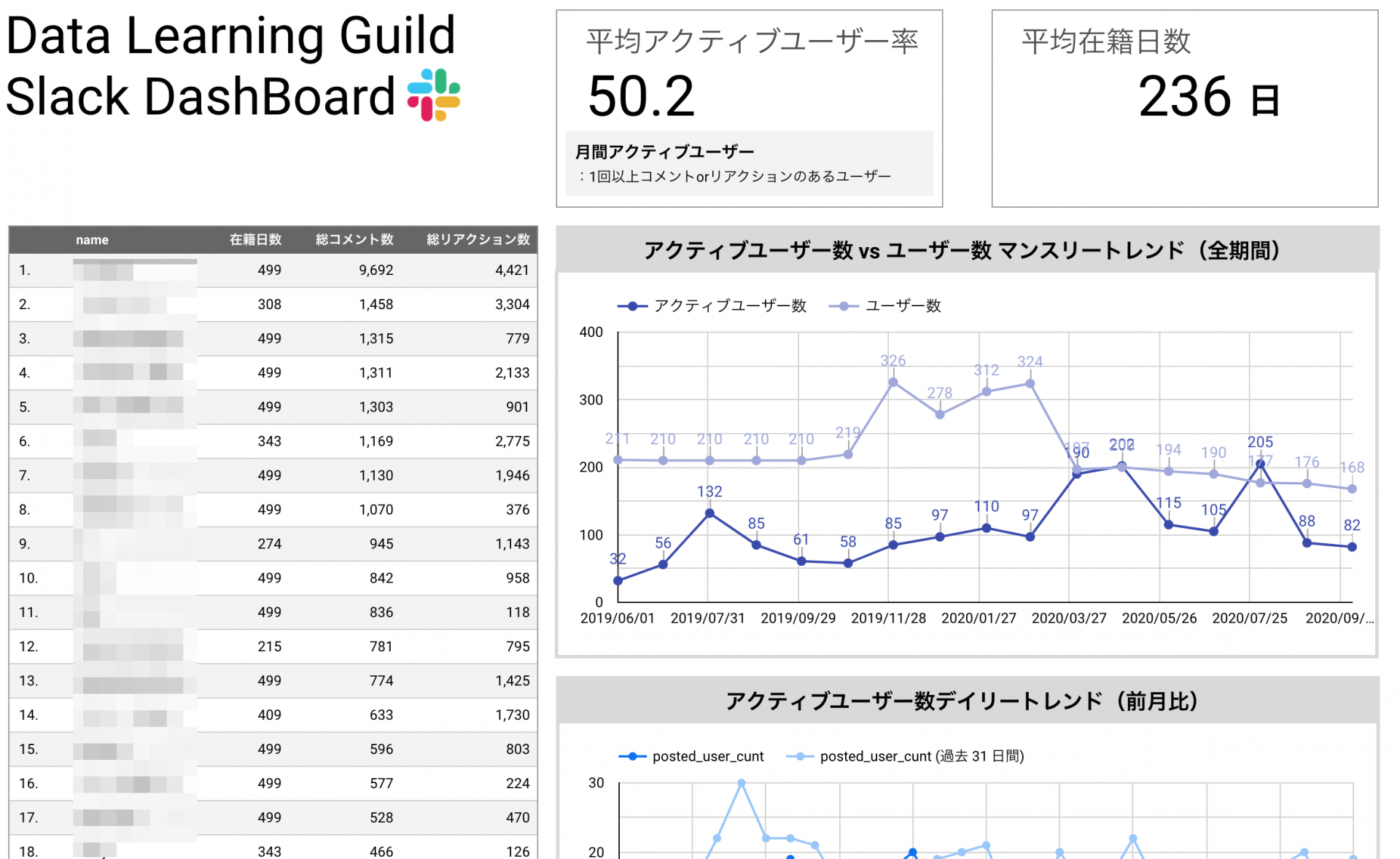
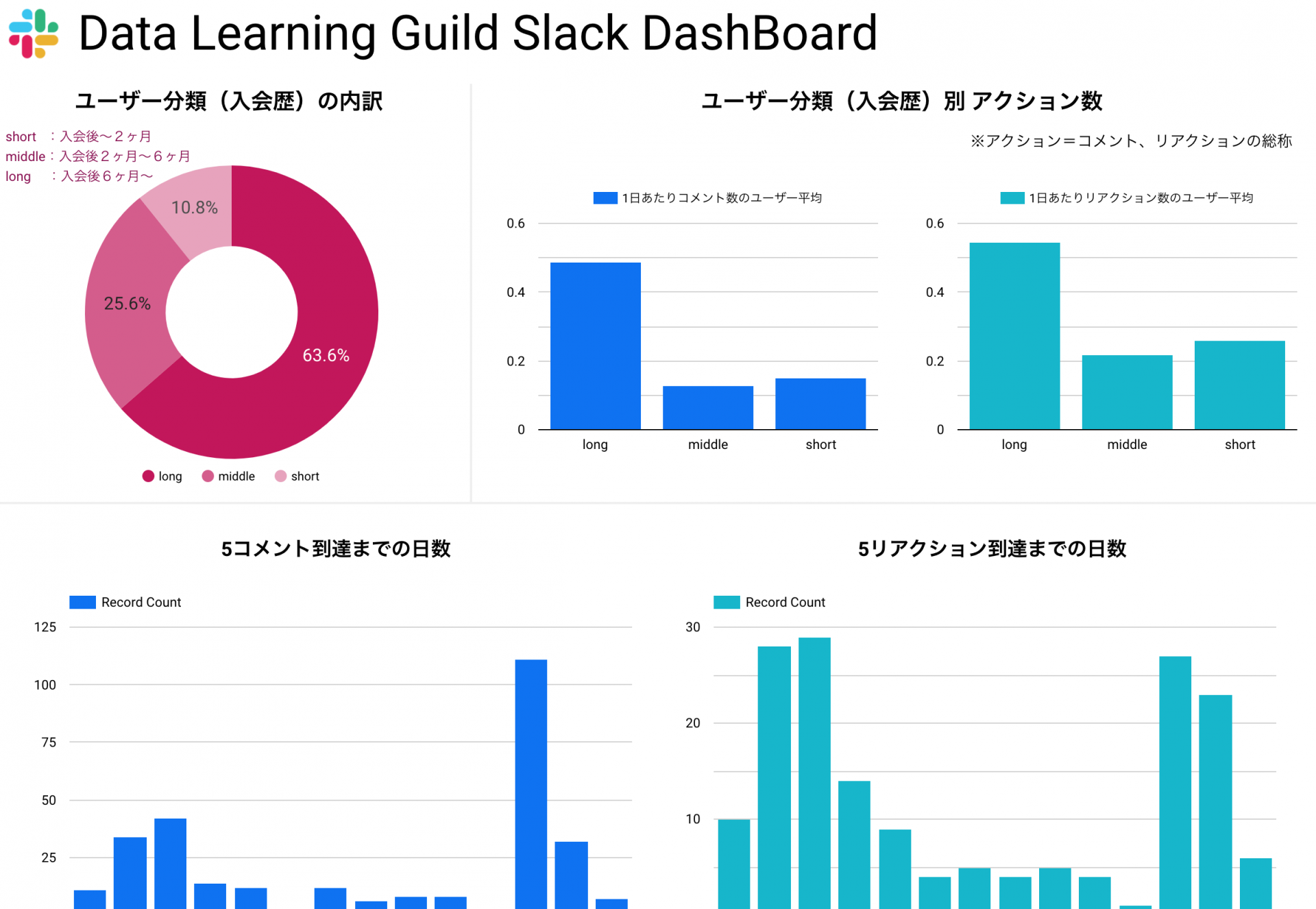
こちらのダッシュボードに関しては、ユーザー検索プロジェクトで蓄積されたデータを元に構築されたダッシュボードです。ユーザーにきちんとコミュニティを活用して貰えているかを測るために作成しました。このようなダッシュボードを作る上で、どのようなポイントに気をつければ良いのか、ダッシュボード以外のアウトプットとしてどのようなものを作成すれば良いのかに関して解説をしたいと思います。
「3.4. ③データ監視用のダッシュボード構築」でも述べたように、データ分析の文脈におけるダッシュボードとは、主に複数のデータソースから情報を取り込み・変換し、迅速な意思決定を支援するための情報(KPIなど)をひと目で見られるようにデザインしたページを指します。
ダッシュボードは、データを見る人(以降、オーディエンスと表記)の事前知識、データを見る目的、利用方法など様々な要素によって各シーンごとに最もフィットする形が変わります。したがって、ここで示すダッシュボードの内容が正解という訳ではありません。
ここで一度3.3.節に記載した内容を再掲しますので、アウトプットの形式、アピールしたいポイントに関して振り返ってみましょう。
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| BIツールを用いたダッシュボード | 公開したダッシュボードのリンク |
| ダッシュボード仕様書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| ダッシュボード構築の内容を要約した記事 | 技術ブログサービスなどにダッシュボード構築における狙いやポイントをまとめ、公開する |
アピールしたいポイント
- 適切な図表をも用いてダッシュボードが構築されていること
- ダッシュボードにおける必要な情報の可視性、説明文の可読性
- ユーザーの導線に沿った操作性になっていること
- 何を目的としたダッシュボードであるかが明確になっていること
- 目的を達成するために見るべき数値が適切に選定されていること
- 表示されている指標を元にどのような意思決定に繋がるかイメージできること
- 分かりやすい操作説明書がある
7.2. ポートフォリオ作成のポイント
ダッシュボードの構築においては、大きく分けると配置の色のバランスや図表の選び方といったデザイン面と、ビジネスの状況を正しく把握できる指標になっているかといったビジネス面の2種類の項目が重要でした。
また、ダッシュボードを構築するに当たってSQLで再度集計したりすることは良くあるので、データ加工も合わせて行えると良いでしょう。
ダッシュボードの利用シーンを明確にする
ダッシュボードに限った話ではありませんが、「何のために実施するのか」というWhyの部分を常に意識しておくことは重要です。作業を始めて、いろんな課題に直面した時、当初定めたWhyを振り返ることで的外れでない意思決定をするための助けになるからです。
『データ視覚化のデザイン』(著:永田ゆかり)を参考に要求事項をまとめることで、具体的なダッシュボードの利用シーンを設定できるでしょう。
■ 背景
ダッシュボードが必要になった背景や用意できる情報、スコープなどを整理します。
■ オーディエンス
最終的にこのダッシュボードを「見る人」・「使う人」が誰なのかということを明確にします。
■ 目的
オーディエンスが何の目的でこのダッシュボードを利用するのか、
もう少し具体的に言うと、「どんな意思決定をするために」利用するのかを明確にします。
■ 利用方法
このダッシュボードが、どんな頻度でどのような手段で利用されるのか、
どんな場面で見られるのかを整理します。
複雑性の高い集計項目も指標として採用する
ダッシュボードの設計の種別は「論理設計」と「視覚化設計」に分けることができます。まずは論理設計に関して説明します。
論理設計とは、ダッシュボードに載せる情報の論理的な整合性や妥当性を設計する作業です。もう少し具体的に言うと、「何の情報」を「どんな順序で」提示するかを決めるとも表現できるでしょう。論理設計におけるポイントを簡単に述べると、以下のようになります。
- 提示すべき情報の列挙
- 整理した要求に応える要素が漏れなく含まれていること
- 情報の提示順序の決定
- 漏れなくダブりなく提示できていること
- 先に概要、後に詳細という流れになっていること
まずは、上記のポイントがカバーされていることが重要になってきます。その上で、提示すべき情報の中に、複雑でかつ元の情報より質の高い情報を含めておくことをオススメします。
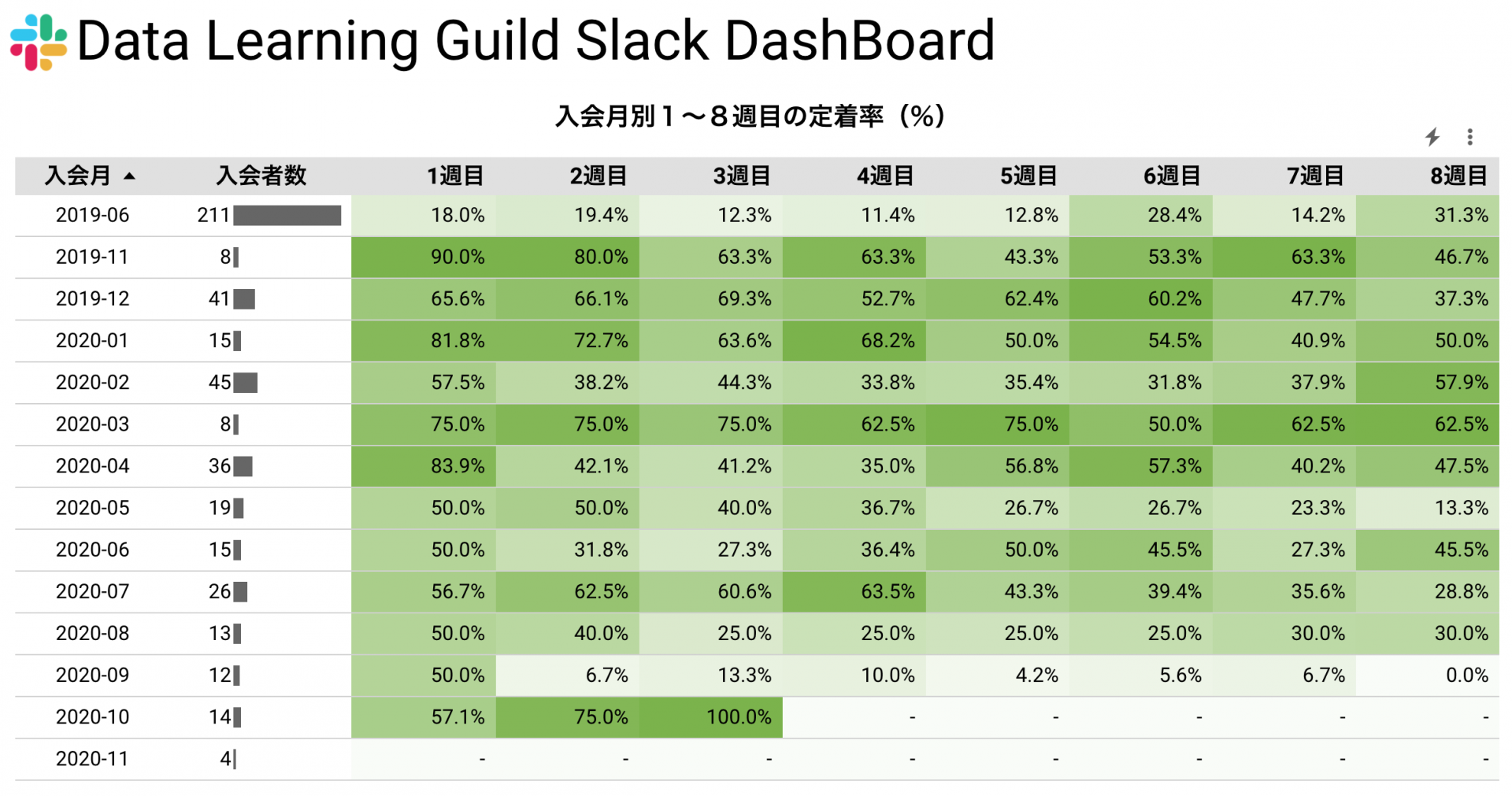
例えばユーザー検索プロジェクトの場合、「ユーザーが継続して使ってくれているか?」ということを表現する指標を作成する際に、「ユーザーがある該当月に発言したか?」という指標よりも「ユーザーが該当月に5回以上発言したか?」という指標にしたほうがより複雑でより質の高い情報となります。
上記のような定義にすることで、1回だけ発言したユーザーの中に、自己紹介のみ投稿して離脱してしまっているユーザーを除いたアクティブユーザーを抽出することができます。5回という数値を、継続して活用しているユーザーの中央値などで設定してあげても良いでしょう。
実務においては単純で効果の高い指標も多いですが、複雑な指標も理解した上で選択できることをアピールするためには、このような複雑な指標もいくつか混ぜておくと実力を示すことができるポートフォリオになるでしょう。
見ごたえのある分析ダッシュボードを作成する
前節で紹介した視覚化設計とは、どのような見た目にするかを設計する作業です。より具体的には、「各データをどのチャートで表現するか」「チャートをどう配置するか」を決定する作業といえます。視覚化設計には、「フォントサイズ・カラーやチャートカラーを決める」作業も含まれると思いますが、これについては、実装しながら、試行錯誤していく側面も多いので、どちらかといえば、実装フェーズの作業に分類されると筆者は考えています。
視覚化設計の基本でも特に重要なものの一つが、チャート選びです。チャートとは、棒グラフ、円グラフなどデータの可視化手法のことです。チャートは、普段テレビ番組やWebサイトでよく目にすると思いますが、各チャートの長所や短所、主な目的というのは、意外と知られていないものです。
適切にチャートを選択するには、チャートごとの特徴を理解しておくことが重要です。ここでは、『データビジュアライゼーションの教科書』(著:藤俊久仁/渡部良一)を参考に本節で利用するチャートの特徴をまとめます。
1. 棒グラフ(縦)
棒の高さでデータを表し、カテゴリ別の指標値を絶対的にも相対的にも正確に表現できる。
2. 折れ線グラフ
横軸で連続的な値に対して縦軸の数量を比較するために使われる。
時系列比較などでよく利用される。
3. 円グラフ
全体に対する内訳を表現するためによく使われる。
カテゴリの数が4つ以上の場合は、棒グラフや積み上げ棒グラフで代替する。
4. 数表・テーブル
軸ごとの集計値を表で表したもの。
5. ヒートマップ
1軸、あるいは2軸のマトリックス上の数値を彩度で表す。
6. ヒストグラム
数値のインターバルの出現頻度を通じて分布を示すことを目的とする。
棒グラフはカテゴリ別の比較を促進するという点において、ヒストグラムとは異なる。
他にも様々な図表がありますが、ポートフォリオとしてアピールする上では、単一のグラフのみではなく複数のグラフを適切に使えていたり、ドリルダウンの機能を扱えていたりすることが重要になってくるので、サンプルのダッシュボードのように棒グラフ、円グラフ、折れ線グラフ、テーブルなどを適切に組み合わせたダッシュボードを構築すると良いでしょう。
URLでダッシュボード画面が共有できるBIツールを選択する
ポートフォリオとして作成をするのであれば、最終的にはダッシュボードとして共有する必要が出てきます。その際に、気をつけるべきポイントがURLでダッシュボードが共有できるBIツールを選定することです。
BIツールによってはサーバー構築から必要になってくるため共有に手間がかかるものや、共有する際に有償が前提のツールなどもあったりするので、BIツールを選ぶ前にURLベースでの共有が可能なBIツールなのかを調査しておきましょう。
7.3. アウトプットイメージ
ユーザー検索プロジェクトで作成したダッシュボードに関して、どのようなアウトプットが必要になりそうか、ユーザー検索プロジェクトに紐づけて見てみましょう。
| アウトプット種別 | 概要 |
|---|---|
| ダッシュボード本体 | Google DataPortalで作成したダッシュボードを共有URLを用いて共有 |
| データマート定義書 | ユーザー分析用マート、チャンネル分析用マートなど分析用に構築したデータマートの定義書(後述)をmarkdown形式で執筆し技術ブログサービスなどに公開 |
| ダッシュボード仕様書 | ダッシュボードのキャプチャをダッシュボードごとに撮影し、グラフ要素ごとに項番を付けデータの集計定義を解説した記事を作成、技術ブログサービスなどに公開 |
| ダッシュボード構築の内容を要約した記事 | ダッシュボードで表示することになった指標や、不採用とした指標などに関して、作成の経緯をまとめて技術ブログサービスなどに公開 |
データマート定義書に関しては馴染みがない方が多いと思いますので、以下でデータマート定義書がどのようなものなのか解説します。
データマート定義書
データマート定義書という変わった名前にはしていますが、作成するものは一般的にデータベース定義書、テーブル定義書と呼ばれるドキュメントになります。では、何故あえてデータマート定義書という名前をつけているのでしょうか?
ダッシュボードを構築する際に、データベースの内容をそのまま使用することは少なく、分析単位ごとにダッシュボード用のテーブルを作成することが一般的です。ダッシュボードで効果的に可視化、ドリルダウン、フィルタリングするためには少しシステムで使用するテーブルとは違った形のテーブルを構築する必要があります。
例えば、ユーザー検索プロジェクトのユーザー分析用のマートでは以下のようなテーブルを作成しています。ユーザーの分析に必要な要素をひたすら列として追加した内容となっており、クロス集計するだけで様々な分析ができるような構造になっています。
| 項目名 | 項目内容 | データ型 |
|---|---|---|
| user_id | ユニークユーザーID[ PK(=PRIMARY KEY) ] | STRING |
| name | ユーザー名 | STRING |
| deleted | 退会済みフラグ | BOOL |
| register_date | 入会日 | DATE |
| staying_days | 所属日数 | INT |
| latest_staying_date | 最終所属確認日 | DATE |
| essential_ch_join_date | 必須チャンネル参加開始日(最初に参加しているもの兼同日に複数) | DATE |
| optional_ch_join_date | 任意チャンネル参加開始日(必須チャンネル以降に参加しているもの) | DATE |
| first_comment_date | 1回目コメント日 | DATE |
| fifth_comment_date | 5回目コメント日 | DATE |
| tenth_comment_date | 10回目コメント日 | DATE |
| latest_comment_date | 最新コメント日 | DATE |
| first_react_date | 1回目リアクション日 | DATE |
| fifth_react_date | 5回目リアクション日 | DATE |
| tenth_react_date | 10回目リアクション日 | DATE |
| latest_react_date | 最新リアクション日 | DATE |
| total_comments | 総コメント数 | INT |
| total_reactions | 総リアクション数 | INT |
| enrollment_preriod_type | 入会歴区分 | STRING |
| retention_1_week | 1week定着フラグ | INT(0/1) |
| retention_2_week | 2week定着フラグ | INT(0/1) |
| retention_3_week | 3week定着フラグ | INT(0/1) |
| retention_4_week | 4week定着フラグ | INT(0/1) |
| retention_5_week | 5week定着フラグ | INT(0/1) |
| retention_6_week | 6week定着フラグ | INT(0/1) |
| retention_7_week | 7week定着フラグ | INT(0/1) |
| retention_8_week | 8week定着フラグ | INT(0/1) |
7.4. ポートフォリオサンプル
第2部 第8章 ④データパイプラインの構築
8.1 概要
次に、今回のユーザー検索プロジェクトを縁の下から支えるデータパイプラインに関するポートフォリオ作成を解説します。
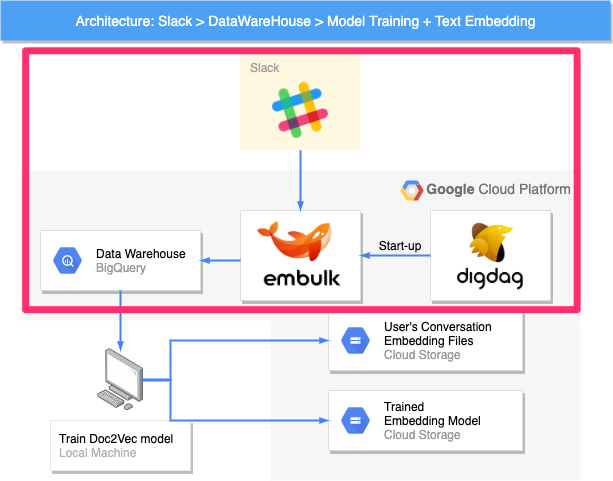
ユーザー検索プロジェクトのデータパイプラインは、以下のような流れで「Slackの会話情報やメタ情報を日次でBigQueryに保存する」という機能を実現するものでした。
今回は、ETLツールとしてEmbulk、ワークフローエンジンとしてdigdagという2つのオープンソースソフトウェアを利用して、パイプラインのコア部分の処理を実装します。また、インフラストラクチャの構築はGCPのサービスを用いて実現します。
これらのソフトウェア及びサービスを用いてポートフォリオを作成するに当たって、どのような所に注意すれば評価されるポートフォリオを作ることができるのでしょうか?
ここで一度3.4.節に記載した内容を再掲しますので、アウトプットの形式、アピールしたいポイントに関して振り返ってみましょう。
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| アーキテクチャ設計書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| データベース定義書 | Excelやスプレッドシートなどで作成し、ファイルやリンク形式で共有 |
| データ加工のフロー図 | 技術ブログサービスなどにETL処理を行う際の処理の流れを図式化したものをまとめ、公開 |
| データパイプライン構築の経緯を要約した記事 | 技術ブログサービスなどにデータパイプラインの仕様や使い方、ポイントなどをまとめ、公開 |
| データパイプライン構築の際に書いたコードなど | 実装したコードをGitHubで公開 |
アピールしたいポイント
- データ取得、データ蓄積、データ加工の一連の流れが構築できていること
- データを利用する人が使いやすい環境が構築できていること
- データを利用する人が使いやすいデータ形式にデータが変形されていること
- 各処理の実行に活用しているサービスが適切であること
- 目的や必要な性能に応じて適切なサービスを使っていること
- ワークフローエンジンなどを用いてジョブの実行管理が行われていること
- パフォーマンスを考慮した設計になっていること
- データ量が増えた際のスケーラビリティを考慮した設計になっていること
- データの形式が変わった際の対応が検討できていること
- 予期せぬデータが発生した際のリトライ処理や例外処理が考慮されていること
- クラウドインフラベンダーのベストプラクティスに沿った設計ができていること
8.2 ポートフォリオ作成のポイント
それでは、上記のアウトプット、アピールしたいポイントに関して解説していきたいと思います。以下のポイントに気をつけることで、アーキテクチャプランニング〜パイプライン実装までの一連の流れがより良いものとなるはずです。
データパイプライン全体が俯瞰しやすいアーキテクチャ設計書を作る
データパイプラインの機能や構成を説明する時、通常は、データ入力元、出力先や変換処理の内容や実行頻度など多くの情報を整理する必要があります。したがって、アーキテクチャ設計書が分かりにくい場合、説明を受ける側が混乱してしまう恐れがあります。この「説明を受ける側」とは、転職活動ではポートフォリオをレビューするエンジニアや人事の方ですが、実務では、データ活用に携わる他部署のメンバー及び開発チームメンバーです。そういった意味で、良質なポートフォリオを作る上でも、今後の実務で良い成果を出すためにも全体を俯瞰する図や解説資料を作成することに力を注ぐことは重要です。
3.5節でも述べたように、データパイプラインは、成果物そのものを共有することが難しいという側面があります。したがって、「どんなものを作ったのか」を分かりやすく伝えることの重要性が、他のポートフォリオに比べて大きいと言えるでしょう。
また、データパイプラインの構造だけでなく、「なぜそういう設計にしたのか」という設計の意図を伝えることも重要です。データパイプラインの構築に利用できるソフトウェアやサービスは様々ありますが、それぞれ長所と短所があります。実務では、データ活用の目的や自社のリソースの性質、既存のインフラストラクチャの状態に合わせて、適切なソフトウェアを選択することが求められます。したがって、データパイプラインの構築力、データエンジニアリング力をアピールする上で、状況に応じた設計ができるように意識することと設計の意図を分かりやすく伝えることがポイントの一つと言えるでしょう。
他の人が再現できるような成果物を作る
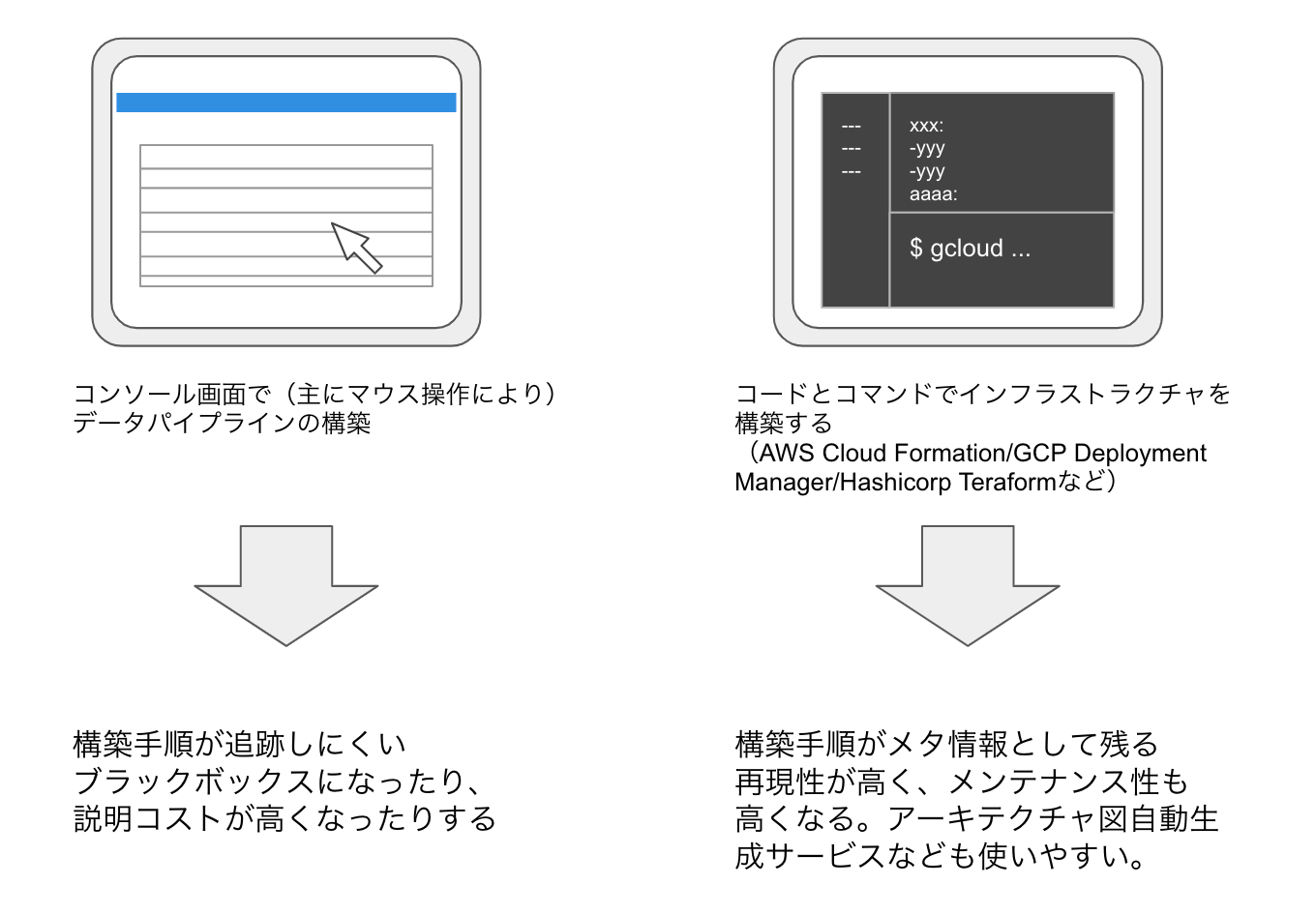
データパイプラインを構築する上で、難しいことの一つに「再現性を担保すること」が挙げられると思います。データパイプライン構築業務において、他者が再現できるように構築手順を追跡可能にしておくこと、人に依存しないように構築処理をコード化(Infrastructure as Code:IaC)することを意識しなければ、簡単に「構築した本人しかわからないブラックボックス」になりがちです。
「本人しかわからないブラックボックス」になり、再現性が担保できなくなると、ポートフォリオ作成の観点から言えば以下のようなデメリットがあります。
- どのように構築したのかわからないため、成果を適切に評価してもらえない
- 実務において、「ブラックボックスなデータパイプライン」を作る人材と判断されてしまう
- 面接の現場などで説明しづらい
では、再現性を担保するためには、どうやってデータパイプラインを構築すると良いのでしょうか?
いくつか手段が考えられますが、例えば以下のような手段を利用することで解決できると考えます。
最も実務的な解決のしかたとしては、IaCサービスを使う方法が挙げられます。IaCサービスを使えば、一定の学習コストを払えば、インフラストラクチャ構築をコード化することができます。インフラストラクチャ構築をコードかすると、「構築手順が形あるものとして残る」「構築手順をGitなどバージョン管理ツールで管理できる」「手作業によるミスが減る」といったメリットがあります。具体的なサービス名としては、例えば以下のようなものが挙げられると思います。
- Cloud Formation(AWS)
- Deployment Manager(GCP)
- Terraform(Hashicorp)
こうしたデータパイプライン構築をサポートするソフトウェアやサービスを上手く使うことで、再現性のあるデータパイプライン構築能力や既存のソフトウェアに関する知見をアピールできるでしょう。
モダンな技術の利用に積極的にチャレンジする
実際は、現場のデータ活用の目的や環境によっては、サーバー1台にMySQLとcronを立ち上げれば事足りることも多いと思います。しかし、いずれそういった現場でもデータ活用のフェーズが進み、活用領域が広がると、よりスケーラブルで可用性の高いシステムが要求されることになるでしょう。もちろん、業種的に大規模データを高速に処理しなければならないデータ活用先進企業の現場では、すでに多くのモダンな技術を活用し、スケーラビリティや可用性、メンテナンス性の高いシステムが稼働しています。
したがって、ワークフローエンジンや学習マシンをKubernetesで冗長化させたり、BigQuery, Athenaで分析基盤を構築にチャレンジし、モダンな技術を使えることとキャッチアップする姿勢をアピールすることが大切かと思います。ただし、過度にリッチになりすぎないように気をつける必要はあるかもしれません。
8.3 アウトプットイメージ
アーキテクチャの解説やデータ加工のフロー図
データパイプラインは、成果物そのものを共有することが難しいという側面がある為、「何を考え、どんなものを作ったか」を文書で伝えることが他のポートフォリオより重要という旨を述べました。したがって、データ加工の流れや各モジュールの仕様・性質を解説は重要なアピールポイントとなるでしょう。
また、採用過程(特に初期段階)では、ポートフォリオをじっくり隅々まで見てもらえることは期待しないほうが良いでしょう。採用担当者は、多くの候補者の資料に目を通さなければならないからです。したがって、アーキテクチャ解説もざっと見て全体がわかるような形式になっていることが大切です。そこで重要になるのが、アーキテクチャ図やデータ加工のフロー図でしょう。
アーキテクチャ図の作成では、正確な図を描くことはもちろん、可読性を高めるために、例えば以下のような点に注意すると良い図を描けるかと思います。
- アーキテクチャ図のタイトルを記載する
- 各セグメントの役割を記載する
- 矢印の意味を凡例として明示する
- 色分けや配置を工夫して、同種のものをグルーピングする
以下、アーキテクチャ図の可読性を高めるためのBeforeAfterを記載しますので、こちらを参考にアーキテクチャ図を作成して頂ければ、評価されるポートフォリオを作成できるようになるかと思います。
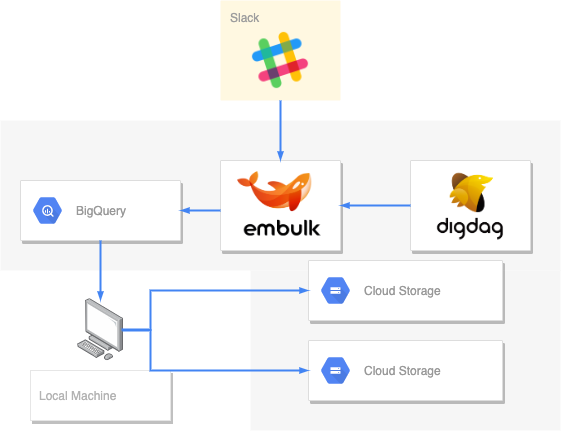
Before
After
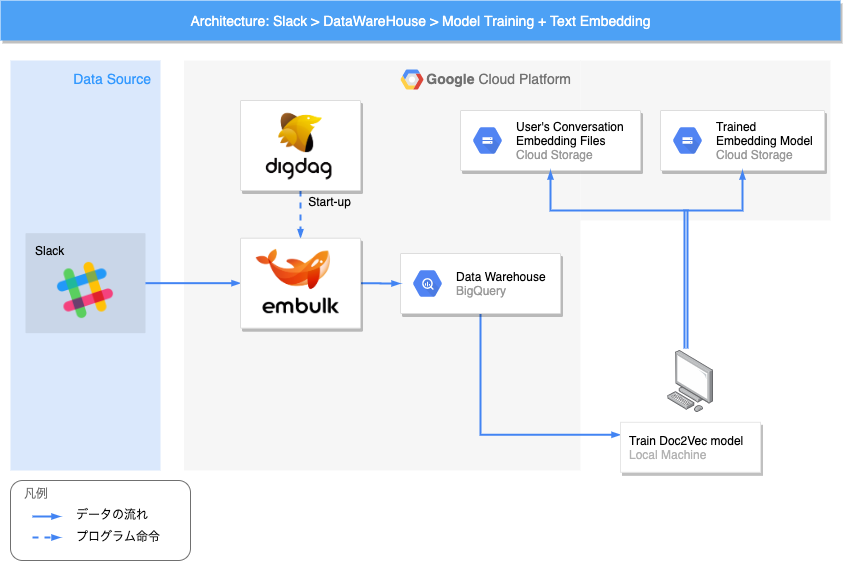
上図は、ユーザー検索プロジェクトのアーキテクチャ図の事例です。アーキテクチャ図では、各種クラウドベンダーのサービスアイコンや各種ソフトウェアのロゴを用いて表現することが多いです。そうすることで、情報量が多くなりがちなアーキテクチャ図をシンプルに保ちつつ、記述すべき情報を書き記すことができます。
今回の場合データの入力元がSlackのみであり、ETL処理も非常にシンプルですので、構造が複雑でわかりにくくなることはあまりないのですが、改善後アーキテクチャ図のほうが、一つ一つのセグメントの役割や設計意図が伝わりやすくなると思います。表現方法の改善例として、ご参考までに共有します。
データパイプライン構築の経緯を要約した記事
データパイプライン構築で工夫した点や学んだ点など自身のアピールしたいポイントを書きやすいのが、こちらの要約記事かと思います。前項でも述べたように成果物そのものを共有しにくいデータパイプラインにおいて、この要約記事の内容が重要な判断材料になります。
データパイプライン構築の要約記事には、以下のような点を盛り込めると良いかと思います。
- どのようなデータ活用を目的としたデータパイプラインなのか?
- なぜそのようなデータ活用に取り組もうと思ったのか?
- データはどんな順序でどんな頻度で流れるのか?
- どのようなサービス、ソフトウェアやミドルウェアを用いて実現したのか?
- なぜそのサービス、ソフトウェアやミドルウェアを使ったのか?
- パフォーマンスやメンテナンス性を高めるためにどういった点を工夫したのか?
- ログ情報はどのように収集しているのか?
例えば、今回のユーザー検索プロジェクトであれば、以下のような章立てで作成することで、アピールしたいポイントを載せながらわかりやすい要約記事を作れるのではないでしょうか。
| 見出し | 概要 |
|---|---|
| 背景・課題・概要 | slackコミュニティにおいて、誰がどんな話題に詳しいか分からないという課題があり、その解決方法として検索ロジックを開発したこと、slackの発言ログを元にマッチングアルゴリズムを開発したことを記載 |
| 活用したサービス一覧 | データパイプライン構築に利用したソフトウェアやサービスの一覧を記載し、読む前にどのような技術スタックに関することなのか俯瞰できるようにする |
| データパイプラインの目的 | データ活用によってどのような課題を解決しようとしているのか、データパイプライン構築の目的を記載 |
| アーキテクチャ概観 | 今回構築したアーキテクチャの全体像をアーキテクチャ図と共に解説 |
| 個別モジュール解説 | アーキテクチャ概観で示した、各モジュールの役割や設計のポイントを記載 |
| 工夫したポイント | 設計時のソフトウェア・サービス選択や、実装時のコーディング、デプロイ方法など気をつけた点や工夫した点を記載 |
| 動作確認 | データパイプラインのログやダッシュボード画面のキャプチャと共に実際の動きがわかるような内容を記載 |
| 課題点と考察、今後のアプローチ | 上手くいった点、行かなかった点をとりまとめ、次のステップとしてどのようなことに取り組めば良いかを記載 |
アーキテクチャ図や各サービスの選定条件など、アーキテクチャ定義書などと一部重なるところはあると思いますが、アーキテクチャ定義とは関係ない部分(例:今後改善していきたいこと)も書き加えることができるので、アピールできるポイントが多くなるかと思います。
8.4 ポートフォリオサンプル
(現在鋭意製作中です…)
第2部 第9章 ⑤分析レポートの作成
9.1. 概要
本章では、ユーザー検索プロジェクトで蓄積したデータに基づいて分析レポートを作成することを題材に、分析レポートのポートフォリオ作成で気を付ける部分を解説します。ユーザー検索プロジェクトのデータの元となっているのはデータラーニングギルドでの会話ログなので、Slackでの会話ログを用いた分析レポートを想定して解説を進めます。
以下に実際にデータラーニングギルドのイベントで実施したネットワーク分析のレポートを掲載します。分析レポートのポートフォリオでは、このような分析レポートの作成を目指します。

以下に、アウトプットの形式、アピールしたいポイントを再掲します。
アウトプットの形式
| 具体的な成果物の形の例 | 共有・展開方法の例 |
|---|---|
| 分析内容を記述したドキュメントや記事(JupyterNotebook形式でまとめた場合) | Githubで公開 |
| 分析内容を記述したドキュメントや記事(PowerPointなどプレゼンテーション形式でまとめた場合) | SlideShareやSpeakerDeckで公開 |
| 分析内容を記述したドキュメントや記事(ブログ記事としてまとめた場合) | 自身のブログや技術ブログサービスで公開 |
アピールしたいポイント
- 解くべき価値のある課題設定されていること
- その課題の背景情報が説明されていること
- 類似の分析事例や外部の調査結果をベースに分析アプローチを決定していること
- 設定した課題に対して、妥当なアプローチをとっていること
- 分析によって得られた事実とそこから得られたインサイトや推論が区分されていること
- 独自の観点に基づいて論理的な考察がなされていること
- 意思決定に繋がるストーリーが展開されていること
- 数学的、統計学的に誤りのない展開がなされていること
9.2. ポートフォリオ作成のポイント
分析レポートのアウトプットは他のポートフォリオとは大きく異なり、「どのような物を作ったか?」ではなく、「どのような結果が得られたか?」が重要になってきます。そのため、分析によって良い結果が得られたのか、再現性を持って良い分析ができるのかといった所が評価ポイントとなってきます。
以下のようなポイントを意識してポートフォリオを作成すると評価されるポートフォリオが作りやすくなります。
テーマ選びに明確な意志を持つ
データサイエンティストに重要な素養として「良き問を立てられる」という素養があります。つまり「どのようなテーマを選んだか?」ということ自体がアピールポイントとなるのです。例えば、テーマを選定する場合に、以下のような質問を自問自答してみると良いでしょう。
- 本当に分析する価値のある問なのか?
- よりコストのかからない他の方法で似たような分析結果を得られる方法はないか?
- 他にもっと取り組むべき問はないのか?
- 分析をすることで良い結果が得られる見込みは立っているのか?
例えば、冒頭で紹介したネットワーク分析に関しては、以下のようなメリットがあり、他の手法では代替しにくい分析となっているため、比較的良いテーマと言えるでしょう。
- コミュニティが大きくなると把握しにくくなるユーザー間の関係を可視化できる
- コミュニティの中で重要な役割を果たしているユーザーを特定し、ケアすることができる
- 各種中心性指標を算出することで、単純なコメント数などでは把握できない重要なユーザーを特定できる
- 発展的な分析でコミュニティを検出できるので、コミュニティ応じたイベントを企画できる
文章の構成パターンを意識する
分析レポートを作成する際は、目的に合わせたレポートの方を用いてレポートを作成すると良いでしょう。コンサル要素の強いレポートではPREP法、研究開発お色が強い分析レポートではIMRAD形式を用いてレポートを作成すると読みやすいレポートが作れるようになるはずです。
冒頭で共有したネットワーク分析の分析レポートを例に、どのような構成にすると良いのかを考えてみましょう。
PREP法
PREP法に関しては、結論から話すことで主張を分かりやすくしたフォーマットで、コンサルタントの方などが良く使う方法です。結論・要点(Point)、理由(Reason)、事例・具体例(Example)、結論・要点(Point)の順序で文章を構成します。
ネットワーク分析の分析レポートをPREP法を用いて分析すると以下のようになります。
| 項目 | 例 |
|---|---|
| 結論・要点(Point) | コミュニティの発展に伴って相互の関係が育まれつつある |
| 理由(Reason) | ネットワークのパスの下図が増え、媒介中心性の偏りも減っている |
| 事例・具体例(Example) | ネットワーク図の時系列変化を見るとネットワークが構築されている |
| 結論・要点(Point) | 方向性としては間違っていないので、同様のアプローチで継続して良い |
IMRAD形式
IMRAD形式は論文などでよく使われるフォーマットで、序論(Introduction)、材料と方法(Materials and Methods)、結果と考察(Results and Discussion)、結論(Conclusion)という構成からなります。背景情報を共有していない方に分析結果を伝えるのに適切なフォーマットとなっているので、複雑な分析をした際はこちらのフォーマットに従って実施すると良いでしょう。
特に、材料と方法(Materials and Methods)に関しては抜けがちな項目なので注意しましょう。ネットワーク分析のレポートをIMRAD形式で表現すると以下のようになります。
| 項目 | 例 |
|---|---|
| 序論(Introduction) | コミュニティおいて何が課題で、何を解決したいと考えているのかを共有する |
| 材料と方法(Materials and Methods) | 使用したデータの期間や有効グラフの定義を共有する |
| 結果と考察(Results and Discussion) | ネットワーク分析の結果とそれに基づいた分析 |
| 結論(Conclusion) | コミュニティの発展に伴って相互の関係が育まれつつある |
集計を中心とした分析と機械学習を用いた分析の両軸で分析する
データ分析の実務では、集計を中心とした分析を行い、より高度な分析がしたいときに機械学習を用いて分析を行うという順序が一般的です。データサイエンティストとして活動する上では、どちらの分析も行える必要があります。
そのため、集計を元に結論を導き出す分析、機械学習で結論を導き出したり、予測・分類結果を算出するような分析の両方をレポートに含められると良いでしょう。具体的には、基礎集計をして課題を抽出し、その課題に対して機械学習を用いるというアプローチを取ればストーリーとしても適切で、アピールもしやすいポートフォリオになるかと思います。
9.3. アウトプットイメージ
アウトプットに関しては分析レポートほぼ一択になるので、詳細な説明は割愛させて頂きますが、「どのようなテーマを選ぶか?」が重用になってくるので、以下にSlackの会話データを用いたテーマ案を列挙しておきます。
- 解約ユーザー、非解約ユーザーとその行動傾向に関する分析レポート
- コアに使っているユーザーと離脱してしまうユーザーの違いに関する分析レポート
- チャンネルごとの話題の傾向の差に関する分析レポート
- ユーザーの発言内容を元にしたユーザークラスタリング
- コミュニティの中で盛り上がりやすい話題に関する分析レポート
- コミュニティの利用時間帯とその時間帯ごとの用途に関する分析レポート
上記のレポートは一例ですが具体的なアクションに繋げられるような分析テーマとなっています。このような、分析結果が具体的なアクションに紐付いている分析テーマ選んでポートフォリオを作成することで、魅力的なポートフォリオを作ることができます。
9.4. ポートフォリオサンプル
ワードクラウドとネットワーク分析でslackコミュニティの1年を振り返る
はじめてのデータ分析 ~Slackデータを分析してみた~
補足
データラーニングスクールとは?
本記事は、データラーニングの運営している「データラーニングスクール」の卒業生のレベルを想定して執筆したものとなっています。
私もパーソナルメンタリングを実施しているメンターなのですが、その中で「スクールを卒業したけどどうしたら良いか分からない」という声を多く頂いたため執筆に至りました。
データラーニングスクールの学習内容やカリキュラムに関しては以下の記事にまとめてありますので、どのようなカリキュラムの終了を想定しているのか気になる方は以下の記事をチェックしてみて下さい。
データラーニングギルドとは?
記事中で度々出てきたデータラーニングギルドですが、参加者約170人のデータサイエンティストのための相互扶助組織で、日々データサイエンスに関する情報交換や企画などが行われています。
本記事で取り扱ったユーザー検索プロジェクトに関しても、「実務に近い環境で学習する」という目的のためにギルド内のプロジェクトの一貫として立ち上がりました。ユーザー検索プロジェクト以外にも、以下のような活動が日々行われています。
- ユーザー同士のオンライン懇親会
- AIのビジネスモデルをフィードバックを貰いながら作成するAIビジネス企画コンテスト
- 統計、機械学習の書籍を回し読みしながら学習する輪読会
- データサイエンスに関する質問とそれに対する回答
気になる方は以下のデータラーニングギルドのページをチェックしてみて下さい。
おわりに
大変長い記事となってしまいましたが、最後まで読んでいただき、ありがとうございます。私自身まだまだ駆け出しですが、これからデータサイエンティストになりたい方に少しでも役に立てる記事になっていれば幸いです。本稿には実装の解説を含んでおりませんので、そちらはまた別の記事で共有できればと思っております。
尚、本稿を執筆するにあたって、データラーニングギルド代表 村上さんにレビュアー・編集者としてご協力いただき、数多くの貴重なご指摘をいただけました。この場を借りてお礼を申し上げます。