まえがき
こんにちは、 Webエンジニアをやっているますみんと申します。機械学習が巷では流行りに流行っていますね。自分も大学の講義でなんとなーくやった記憶があるのですが、もう既に覚えてません。さすがにチュートリアルくらいやっておかないと流行についていけないだろうという若干後ろめたい気持ちがドリブンにドリブンを重ねたので、今回はTensorFlowのニューラルネットワークのチュートリアルをやってみることにします。
注意
この記事は、Pythonを触ったこともない初心者がドキュメントあさりながらあーだこーだやった記録です。やったこと、思ったことをそのまま書いていますので、読みやすさは保証できかねます。
環境構築
何から手を付けたらいいのかすらよく分からないけれど、自分の中ではとりあえず「機械学習といえばPython + TensorFlow」っていうイメージなので、TensorFlowをインストールします。TensorFlowってGoogleが作ってるんですね。初めて知りました。
Pythonバージョン確認
$ python
Python 2.7.16 (default, Apr 12 2019, 15:32:40)
Pythonは2.x系と3.x系で全然別モノだから気をつけろって誰かに言われた気もしますが、まだ触ったこともないのでそんなのは知りません。とりあえず既にMacに入っていた2.x系で進めることにします。
pipのアップデート
参考: 公式ドキュメント "Install TensorFlow 2"
公式ドキュメントのインストール手順に従い、インストールを進めていきます。GitHubによると、2020/01/12時点でのTensorFlowの最新Versionは2.1.0のようです。
Pythonではpip(Pip Installs Packages)というパッケージ管理ツールで各種パッケージをインストールできるようですね。TensorFlowもこのpipを使ってインストールします。ちなみにちなむと、pipはRubyでいうところのGem、PHPでいうところのComposerみたいなやつです。
まずはpip自体のアップデートをします。
$ pip install -U pip
DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7.
Collecting pip
Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB)
100% |████████████████████████████████| 1.4MB 7.8MB/s
Installing collected packages: pip
Found existing installation: pip 19.0.3
Uninstalling pip-19.0.3:
Successfully uninstalled pip-19.0.3
Successfully installed pip-19.3.1
いきなり悲しいメッセージが表示されました。なんと2020年1月1日でPython2.7はその生涯に幕を下ろしたとのこと😭pipも今後のバージョンアップでPython2.7のサポートを終了すると書いてありますね...。Macにはいっているのはガッツリ2.7系のPythonなので、これは困りました...。
それじゃあせっかくなのでTensorFlowがサポートしている中で最新のPythonをインストールしましょう。
2020/01/12時点でPython自体の最新版はVer. 3.9.0a2ですが、TensorFlowでは3.4〜3.7系をサポートしているようなので、3.7.x系で最新の安定版であるVer. 3.7.6をインストールすることにします。
Python 3.7.6のインストール
pyenvのインストール
公式ドキュメントに従って直接Pythonをインストールしてもよいのですが、後々またバージョンの違いに泣かされるのは嫌なので、Pythonのバージョン管理ツールを使ってインストールすることにします。
ツールはいろいろあるみたいですが、自分の周りでも結構触ってる人が多いのでpyenvを使うことにしました。
pyenvのREADME曰く、MacならHomebrewでインストールできるようですね。ではさっそくインストールしましょう🍺
$ brew update
$ brew install pyenv
$ pyenv
pyenv 1.2.16
...
pyenv 1.2.16が無事インストールされました!
pyenvでPython 3.7.6をインストール
インストールしといてアレなんですが、そもそもpyenvでインストールできるバージョンの中に本当にVer. 3.7.6が含まれているのかが分かりません。インストールできるバージョンを確認してみます。
まずはinstallコマンド自体のヘルプを確認してみます。
$ pyenv install -h
Usage: pyenv install [-f] [-kvp] <version>
pyenv install [-f] [-kvp] <definition-file>
pyenv install -l|--list
pyenv install --version
-l/--list List all available versions
-f/--force Install even if the version appears to be installed already
-s/--skip-existing Skip if the version appears to be installed already
python-build options:
-k/--keep Keep source tree in $PYENV_BUILD_ROOT after installation
(defaults to $PYENV_ROOT/sources)
-p/--patch Apply a patch from stdin before building
-v/--verbose Verbose mode: print compilation status to stdout
--version Show version of python-build
-g/--debug Build a debug version
For detailed information on installing Python versions with
python-build, including a list of environment variables for adjusting
compilation, see: https://github.com/pyenv/pyenv#readme
どうやら pyenv install -l もしくは pyenv install --listでインストールできるバージョン一覧を表示できるようです。
ではこのコマンドを打って、 Ver. 3.7.6がインストールできるか確認してみましょう。
$ pyenv install -l
Available versions:
2.1.3
2.2.3
...
3.7.6
...
おお、ちゃんとインストールできるみたいですね!一安心です。では改めて、pyenvでVer. 3.7.6をインストールしましょう。
$ pyenv install 3.7.6
python-build: use openssl@1.1 from homebrew
python-build: use readline from homebrew
Downloading Python-3.7.6.tar.xz...
-> https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xz
Installing Python-3.7.6...
python-build: use readline from homebrew
python-build: use zlib from xcode sdk
Installed Python-3.7.6 to /Users/<ユーザー名>/.pyenv/versions/3.7.6
インストールが終わったようです。でもインストールしただけではまだバージョンが切り替わっていません。
$ python --version
Python 2.7.16
pyenvで使用するPythonのバージョンを指定
もう2.7系は使わないので、pyenvにてMac全体で使用するPythonのバージョンを3.7.6に指定してしまいましょう。
$ pyenv global 3.7.6
指定をしたので、再度シェルからPythonのバージョンを確認してみます。
$ python --version
Python 2.7.16
おや、バージョンが切り替わっていません。よくあるパスの問題ですね。pyenvでインストールしたPythonにパスが通っておらず、pythonコマンドで使える状態になっていません。
pyenvでインストールしたPythonのありかにパスを通す
パスを通しましょう。自分はMacのshellをbashのままにしている(macOS Catalinaからはzshがデフォルトになっている)ので、bash_profileに以下を追記します。
export PYENV_ROOT="$HOME/.pyenv" # /Users/<ユーザー名>/.pyenv
export PATH="$PYENV_ROOT/bin:$PATH" # パス一覧に最優先で $PYENV_ROOT/bin を追加(パスは左側が優先される)
eval "$(pyenv init -)" # $PYENV_ROOT/shimsディレクトリ追加、指定したバージョンのPythonをshimsにコピーする。終わったら$PYENV_ROOT/shimsを$PATHに追加
追記が終わったらsourceコマンドで設定を反映させます。
$ source ~/.bash_profile
設定を反映したので、シェルからpythonコマンドのパスを確認してみます。
$ which python
/Users/<ユーザー名>/.pyenv/shims/python
pyenvでインストールしたPythonの方に向いていますね!これでOKです。再度グローバルのバージョンを設定し、バージョンを確認してみます。
$ pyenv global 3.7.6
$ python --version
Python 3.7.6
ちゃんとバージョンが切り替わってますね!これでようやくTensorFlowのインストールに戻れます!
ちょっと脱線「パスって何?」
「パスって何?」っていう人は、「コマンド名を打った時に実際に実行されるファイルのありか」って覚えておけばOKです。
今回はpythonって打った時にpyenvでインストールしたPythonを使いたかったのですが、実際に実行されるファイルのありかにpyenvでインストールしたPythonのありかが入っていなかったので使えなかった、ということになります。もちろん実行ファイル自体は存在していますので、実行ファイルを直指定すれば使うことができます。
$ ~/.pyenv/versions/3.7.6/bin/python --version
Python 3.7.6
pipのアップデート
pipもpyenv配下のものを使うように変わったので、改めてアップデートをしておきます。
$ pip --version
pip 19.2.3 from /Users/<ユーザー名>/.pyenv/versions/3.7.6/lib/python3.7/site-packages/pip (python 3.7)
$ pip install -U pip
Collecting pip
Using cached https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-19.3.1
アップデートが完了しました!
TensorFlowをインストール
だいぶ遠回りをしてしまいましたが、ようやく諸問題が片付きました。ではpipでTensorFlowをインストールしてみましょう。
TensorFlowの公式ドキュメント曰く、
- 最新の安定版をインストールする場合 ...
pip install tensorflow - 最新の開発版をインストールする場合 ...
pip install tf−nightly
とするようです。最新の安定版をインストールしたいので、今回は前者のコマンドになります。
$ pip install tensorflow
インストールが完了しました!いい感じ!!
Pythonスクリプトを実行してみる
全くの初心者なので、そもそもPythonをどうやって動かすのかよく分かっていません。なのでまず最初にHello Worldしてみたいと思います。
試しにHello, Worldとだけ表示するスクリプトを書いてみます。Pythonでは変数の標準出力はprint()関数で行えるようです。
print('Hello, World')
このPythonスクリプトをコマンドラインから実行してみます。
$ python sample.py
Hello, World
おおっ、Hello Worldができました!調子いいですね🥳
ちなみにpythonとだけ打つと、対話型のPython実行環境が立ち上がります。いちいちスクリプト書いて実行するの面倒ならこちらでもいいかもしれません。
TensorFlowのチュートリアルをやってみる
TensorFlow 公式ドキュメント "はじめてのニューラルネットワーク:分類問題の初歩"
さ、ようやく本題のTensorFlowのチュートリアルです😂
初心者向けチュートリアルの中に「身につけるモノの写真分類」といういかにもそれっぽいお題があったので、今回はそれをやってみることにします。ちなみにこのチュートリアルで取り上げられている機械学習の手法はニューラルネットワークといって、生物の神経回路に似せた構造になっています。
from __future__ import absolute_import, division, print_function, unicode_literals
# TensorFlow と tf.keras のインポート
import tensorflow as tf
from tensorflow import keras
# ヘルパーライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
ふむふむ。はじめにPythonのインポートシステムというのを使って他のモジュールを使えるようにしているのですね。fromはモジュールの中の特定属性だけimportするときに使う構文のようです。__future__というモジュールが提供しているいろいろな機能を使えるようにしているわけですね。
で次に、pipでさっきインストールしたtensorflowをインポートするわけですが、名前が長いからtfという名前でモジュールを扱えるようにしてある、と。なるほど。このへんはJavaScriptとかでも見るやつですね。PHPもuse asで名前空間のエイリアス作成できますね。おんなじや!
次の行をみると、tensorflowの中にkerasという機能が盛り込まれているようですね。これもそのままインポートするとtf.kerasってなるはずですが、頻繁に使われるからkerasだけで呼べるようにしてある、ということですかね。ふむ〜。
あとは同じですね。numpyをnpで呼べるようにした上でインポート、matplotlib.pyplotをpltで呼べるようにした上でインポートしています。な〜んだ、初期化だけじゃんか!
そして最後にtf.__version__で、インストールしたTensorFlowのバージョンを表示して終了です。楽勝楽勝!🤩
では一旦これで実行してみましょう。
$ python tutorial.py
Traceback (most recent call last):
File "tutorial.py", line 9, in <module>
import matplotlib.pyplot as plt
ModuleNotFoundError: No module named 'matplotlib'
お、楽勝かと思っていたらさっそくエラー。コピペでうまく動かない箇所が出てきました。matplotlibというパッケージがインストールされていないようですね。どうやらこのmatplotlibというパッケージは標準パッケージではないので、pipでのインストールが必要だったみたいです。
numpyも標準パッケージではないようですが、こちらはPythonのインストールの仕方によっては同梱されてるらしいです。以前ちらっとだけPython触ったときにもしかすると入っちゃったのかな?(無知)
matplotlibパッケージをインストール
$ pip install matplotlib
無事にインストールが完了したら、再度tutorial.pyを実行します。
$ python tutorial.py
2.1.0
今度はうまくいきました!バージョン2.1.0のTensorFlowがインストールされていることを確認できました!
ファッションMNISTデータセットのダウンロード
機械学習には、学習するためのデータセットが必要です。チュートリアルで使用するデータセットをダウンロードする行をスクリプトに追加しましょう。追記した行だけ表示すると、以下のようになります。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
kerasっていうのはPythonで使えるニューラルネットワークライブラリのことらしく、TensorFlowにも組み込まれています。読み方は「ケラス」っぽいです(公式ドキュメントで名前に触れている部分と、ギリシャ語表記の方のGoogle翻訳結果)。TensorFlowでは、よく使われるデータセットはこのtf.keras.datasets モジュールのAPIで呼び出せるようです。
ってか公式のドキュメント見てて思ったんですが、TensorFlow公式も自身のことtfって略して表記するの推奨なんですね。まぁ確かに、何回もコード内に出てきたらちょっと見づらいかもです😳
まま、さっそくダウンロードをば。
$ python tutorial.py
2.1.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 2s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 1us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
ダウンロードが完了しました!一度ダウンロードしてしまったあとは、もうダウンロードの必要はないみたいですね。
ちなみにダウンロードしてきたファイルは~/.keras/datasets/<データセット名>/に保存されます。keras APIのドキュメントを見ると保存先のパスを渡せるみたいなので、TensorFlowで用意されたラッパーではなく元のAPIを使えば任意の場所に保存できます。
$ ls ~/.keras/datasets/fashion-mnist/
t10k-images-idx3-ubyte.gz t10k-labels-idx1-ubyte.gz train-images-idx3-ubyte.gz train-labels-idx1-ubyte.gz
ちょっと脱線「MNISTデータセット(MNIST Database)って何?」
機械学習では、大量のデータ群を学習させることでモデルを作り出します。この大量のデータ群というのがミソで、数十というオーダーではまず足りません。さらに集めたデータ群は入力のフォーマットが揃うように前処理が必要となるため、データ集めだけで骨が折れるというのがこの分野でよく言われること(らしい)です。これでは初心者の参入障壁が爆上がりしてしまう(学習させられるだけのデータ群を用意できずに挫折する)ということで、初学者向けのチュートリアル等では予め用意されたデータセットを使うことが多いようです。
機械学習界隈で有名なデータセットの1つにNIST Databaseがあります。これはもともとアメリカ国立標準技術研究所(NIST)のSRD(Standard Reference Data)で頒布されていた手書き文字のデータ群であり、このNIST Databaseをより使いやすく改修したのがMNIST Database(MNISTのMはModifiedのM)です。MNIST Databaseは機械学習のいわばHello Worldといえます。TensorFlowのtf.keras.datasetsモジュールでももちろんMNIST Databaseが使えます。
TensorFlowのチュートリアルでは、単純かつ使われすぎてしまったMNISTデータセットを置き換える目的で作られたファッションMNISTデータセットを使用しています。
学習データの用意
機械学習の大枠の流れとしては、
- モデルを作成
- 学習データをモデルに流し、学習させる
- 学習が済んだモデルにテストデータを流し、精度を確認する
- 学習が済んだモデルに実データを流す
という感じです。ただモデルを作っただけではダメで、分類やらなんやらのコツを学習するための学習データ、モデルの精度を確認するためのテストデータが必要ということですね。ファッションMNISTデータセットには、学習データとテストデータの両方が含まれています。試しに以下をtutorial.pyに追記して、学習データの1番目を表示してみます。
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
pltは import matplotlib.pyplot as pltでインポートした機能でした。matplotlibはおそらくmatrix plot libraryの略称かと思われますが、要は行列に格納されたデータからいい感じの図を作ってくれるモジュールです。このモジュールのうち、pyplotっていう機能を使うやで〜ってことですね。公式曰くpyplotはMATLABライクなインターフェースで図を描くことができるとのことで、用意された関数やその使い方は確かにMATLABっぽさがある...かも。
新しい図を作成して、図に画像を貼り付けてカラーバー表示して、グリッド消して図を表示する。MATLABのimagesc()とかそのへんに近いですね。じゃあスクリプトを実行して学習データの1番目を表示してみましょう。
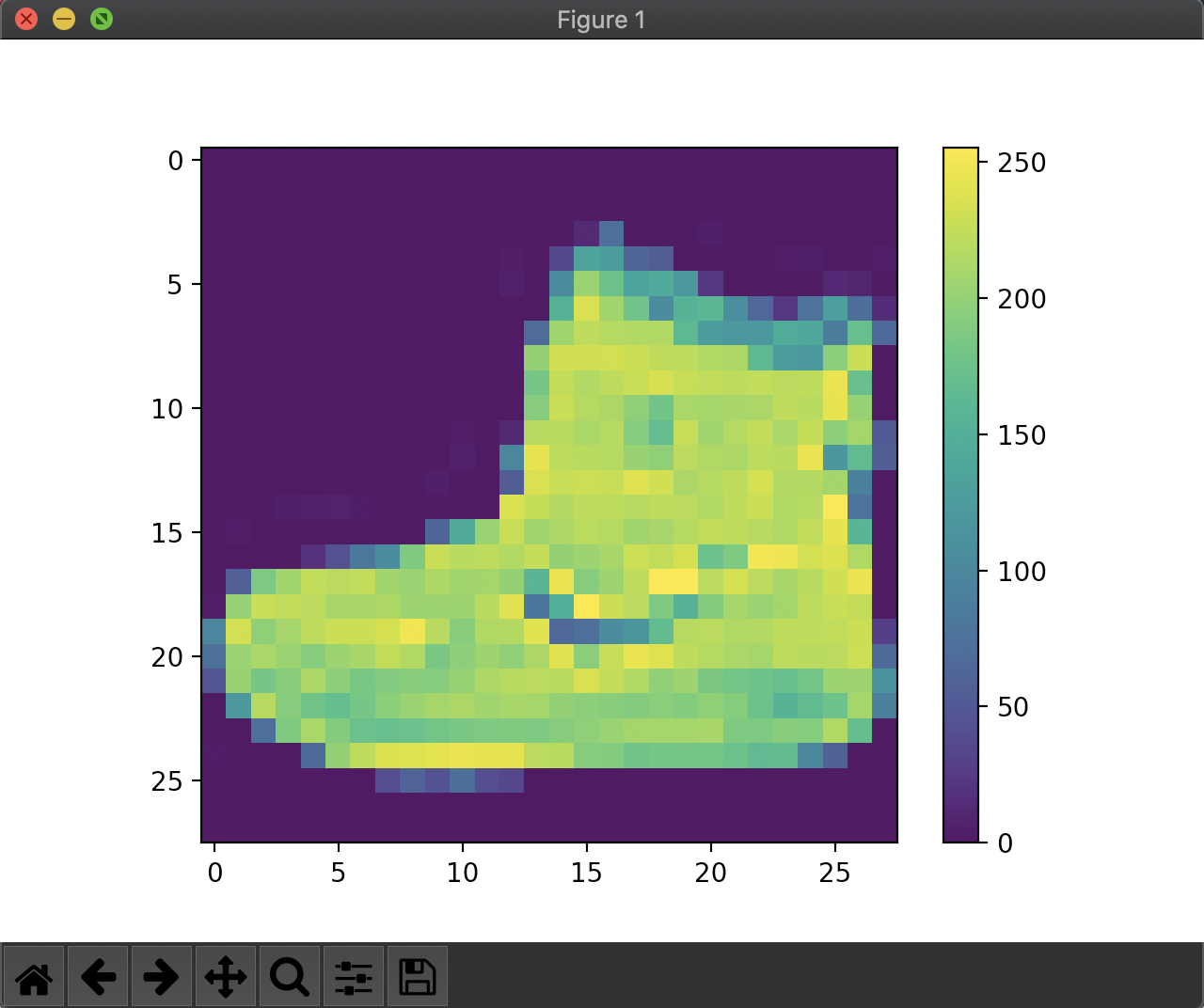
これは...ブーツですね!こんな感じで、0〜255の値が入った28px × 28pxの画像が60,000枚入っています。じゃあこれをさっそくニューラルネットワークに...といきたいところですが、それぞれの画素の値を0〜1の値にしてから突っ込みたいのでここでちょっとデータを加工。いわゆる前処理というやつですね。なるほど。
train_images = train_images / 255.0
test_images = test_images / 255.0
なにげな〜く書いていますが、配列の各要素を一気に割り算できるあたり、やはりPythonだな〜って感じがします。PHPとかRubyとかだとfor文で要素を1つずつ割っていかないといけないですからね。Pythonだと行列計算しやすいっていうのはこういう実装がされているからなんだな〜としみじみ感じます。
さて、各データセットには「その画像が実際何の画像なのか」を表すラベルが付いています。しかしラベルは文字列ではなく整数で格納されているので、クラス(それぞれの振る舞いを表すもの)の名称に衣料品の名前を付け、クラスとラベルとを対応付けます。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
例えばclass_names[0]はT-shirt/top、class_names[1]はTrouser(ズボンのこと)といった具合になります。
念の為、正しいクラス名になっているかどうかを確認しましょう。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
先に結果を見てみるとこんな感じ。

おお、チュートリアルページに載っているのと同じですね!(当たり前)
正しいラベルが振られていることが確認できました。後はモデルを作ってデータをブチ込むだけです!🥳
コードをちょっと追ってみます。といってもほぼ「matplotlib.pyplotのドキュメント読め」で終わる話ではあるんですが😉
figsizeはインチ指定です。この場合10インチ * 10インチの図を作るってことですね。ドキュメントによると、デフォルトは6.4インチ * 4.8インチです。
range()関数(正確には、作成後値が変更できない(イミュータブルという)Pythonの型)は、引数1こ(nとする)だけ取った場合n未満を常に満たすようにして、0から1ずつカウントアップしたものを返します。先述の通りrangeは型扱いなので、配列とはちょっと違うみたいですね。といってもインデックス指定して要素取ってくる操作は配列のそれと何ら変わりありませんが。
for文まで来ました。Pythonのfor文は結構独特な書き方するんですね🤨他の言語のcase文っぽさがあります。Pythonにおいてインデントは非常に重要らしく、for文でインデントがないとエラーになってしまいます。まぁRubyとかと違ってendとかないし、そりゃそうだよねって感じです。
で画像を1枚1枚図に貼り付けていきます。5行5列の配置場所に対し、左上から始まり右端へ向けて画像を貼っていき、右端にきたら次の行に進む、という感じですね。plot()関数は1つの画像やグラフ表示、subplot()関数は複数の画像やグラフを表示するときに使うようですね。
xticks()、yticks()はそれぞれグラフの縦軸の目盛り、横軸の目盛りの刻みを取得 or 設定します。空の配列を渡すことで目盛りなしに出来ます。今回は画像を貼るので目盛りはいらないですね。なので空配列を渡しています。グリッド表示もいらないので、grid()にはFalseを渡しています。Pythonのbool型って頭文字が大文字なんですね。小文字でも判定できるようにするモジュールも用意されているようですが、使う時明示しないといけないのでちと面倒ですね。なんでこういう実装なんだろう。
imshow()はさっきやったので、xlabel()を見てみましょう。ってかgrid()もさっきあったな。まぁいいや。
xlabel()はx軸方向(今は横方向)に表示するラベルです。画像が属するクラスの名前を表示していますね。これをylabel()に変えると、y軸方向にラベルが表示されます。
参考までに、4行7列で画像を表示してy軸方向にラベルをつけるとこんな具合になります。

だんだんわかってきたぞ!🥳
モデルを構築する
ここからは主にkeras APIを使うことになるので、説明はしょった部分はAPIのドキュメントみて補完してください。
いよいよモデルの構築に入ります。このチュートリアルではニューラルネットワークを構築しているといいましたが、ニューラルネットワークにおいて重要なのが層と呼ばれる概念です。入力があったらなにかしら重み付けをして出力するものだと思ってもらえればいいかと。この層を順に積んで作るモデルを、kerasではSequentialと呼んでいるようですね。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
モデルの中身がそれぞれ何をしているかはチュートリアルのページを是非見てほしい(逃げの姿勢!)のですが、平たく言うと
- 入力された画像(要素数28 * 28の2次元配列)を、1次元配列に変換(厳密にはこの層はニューラルネットワークの前処理をする層)
- 128個の人工ニューロンからなる全結合層を作り、ReLUという種類の伝達関数(活性化関数)に入力し値を加工、出力する
- 10個の人工ニューロンからなる全結合層を作り、ソフトマックスという種類の伝達関数(活性化関数)に入力し値を加工、出力する(出力は各ラベルに属する確率になる)
って感じです。まぁなんとなく分かったところで、モデルをコンパイルしてみましょう。
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
ここもなんとなく理解する程度にとどめておきます(ホントはこのあたりが一番面白いところだけど、ガッツリ数学なので)。ざっくり見ると、コンパイルには以下の3つが必要だということらしいですね。
- 損失関数(loss function) ... 誤差関数とも呼ばれるやつ。学習中のモデルの正確さを表す。値が低いほど正確。今回はsparse_categorical_crossentropyというやつを使う
- オプティマイザ(optimizer) ... モデルの更新方法。今回はAdamというアルゴリズムを用いている。
- メトリクス(metrics) ... モデルの更新ステップで何を監視するかを指定。今回はモデルの正解率を監視する
なんのこっちゃって感じになってきましたね。でも「機械学習を使ってとりあえず何かする」だけなら、この辺はあまり深く追わなくてOKです。何層で何をして、どういう更新方法使って...とかいう部分は全て、正解率を上げるための変数の1つに過ぎません。より正解率の高いモデルを作りたくなったら、その時初めて数学を学べばよいでしょう。ということで、今はこの辺スルーでいきます😝
モデルに学習させる
学習用のデータセットをモデルに読み込ませて、学習をさせます。ニューラルネットワークに大量の画像を突っ込み、「この画像はこのクラスに分類されるやで〜🤓」っていうのを覚えさせるわけですね。かんたんかんたん!やってみましょう。
model.fit(train_images, train_labels, epochs=5)
学習用のデータセットとラベルを使って、同じデータで5回学習させるわけですね。ふむふむ。いざ実行!
$ python tutorial.py
2020-01-12 23:53:12.524687: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2020-01-12 23:53:12.684666: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7ff1c0a736e0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-01-12 23:53:12.684725: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 4s 65us/sample - loss: 0.4982 - accuracy: 0.8242
Epoch 2/5
60000/60000 [==============================] - 3s 50us/sample - loss: 0.3763 - accuracy: 0.8648
Epoch 3/5
60000/60000 [==============================] - 3s 48us/sample - loss: 0.3373 - accuracy: 0.8773
Epoch 4/5
60000/60000 [==============================] - 3s 48us/sample - loss: 0.3142 - accuracy: 0.8849
Epoch 5/5
60000/60000 [==============================] - 3s 54us/sample - loss: 0.2967 - accuracy: 0.8902
「GPUではなくCPUで頑張って学習しちゃってるけど大丈夫か〜?」ってPythonに言われてるけど、大丈夫なので無視します。ちゃんと学習できてるみたいですね!素晴らしい!最終的には正解率89%くらいのモデルが出来上がりました!
正解率の評価
学習に使っていないテスト用データセットにも、ラベルがついています。これを学習が終わったモデルに流し込むことで、モデルにデータ突っ込んだら実際どのくらいの正解率になるのかを予測してみます。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
$ python tutorial.py
10000/10000 - 0s - loss: 0.3457 - accuracy: 0.8752
Test accuracy: 0.8752
ほほう、87.5%...学習の最後のステップよりちょっと正解率下がりましたね。チュートリアル曰く、この差はいわゆる過学習の一例とのことです。学習用データセットで正解率が高くなるような学習の仕方をしすぎたせいで、他のデータが入ってきたときにモデルが「オレが知ってるデータと違う...」と疑心暗鬼になってしまう状態のことですね。な〜るほど。まぁここも今はスルーして、とりあえず実際にデータ突っ込んで結果を見てみましょう。
学習が終わったモデルで新しいデータを分類してみる
とうとうチュートリアルのゴールにたどり着きました!完成したモデルにデータを投げて、ちゃんと分類されているか見てみましょう。
predictions = model.predict(test_images)
print(predictions[0])
print('\n This image shows ', class_names[np.argmax(predictions[0])])
$ python tutorial.py
[1.1950669e-06 2.0900355e-08 8.5691376e-08 2.0669324e-07 5.3152036e-07
1.7759526e-02 7.3810802e-06 3.2051697e-02 1.6501182e-05 9.5016277e-01]
This image shows Ankle boot
数字だらけの配列は 入力された画像がそれぞれのラベルに分類される確率 を表しています。で、結果としてこのモデルは入力された画像群の1番目をブーツであると分類したわけですね。
確認のためにtest_images[0]を図示してみると...
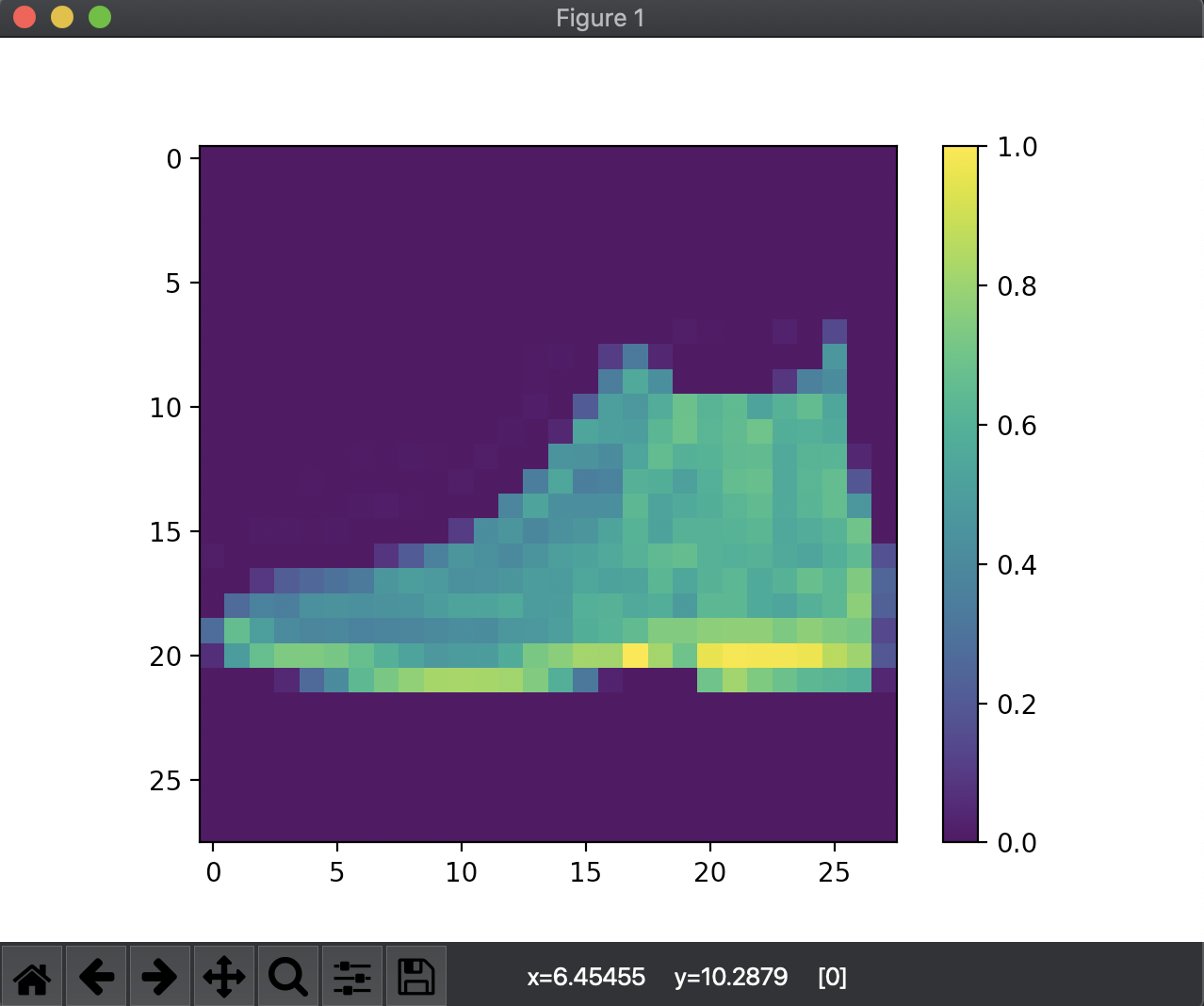
うむ、ブーツですね!!素晴らしい!!🥳
ということで、チュートリアルを終え無事に身につけるモノ画像分類器が完成しました!
基礎の基礎ができたので、今回はここまで!PythonもTensorFlowも完全に理解した!😆(初心者特有の謎の自信)
学習に使う関数とかは確かに難しいのですが、「機械学習でなんやかんやする」だけなら細かいロジック覚えなくてもまぁなんとかなりそうだなっていうことが分かりました。
ただどっかにも書きましたが、実際にモデル構築するときはとにかくデータセット作成がめちゃくちゃ大変だなって気がします。チュートリアルでは既存のデータセットを使ったので簡単に実装できますけど、これ1から自分でデータ用意するのまじで骨折れますね...ま、次は自前でなんか作ってみます🥳