本記事の構築したものは不完全なシステムとなります。
全て真似しても正常動作しない可能性が高いため参考程度にご覧ください
個人的なポリシーとして技術記事を書く時には「構成図」を描きたい思想があります。
ですが記事を書くよりも構成図がネックになって更新頻度が落ちてしまう。そんなジレンマを感じております。
そんな最中、最近巷で情報を小耳に挟みました。
Diagramsを使えばPythonコードで簡単に構成図が描けるヨ!🤩
Bedrockを触りたい私。ふと思いました。
Bedrock AgentsでPythonコードを吐き出してLambdaに実行させてS3にデータを出力すれば良いのでは??🤔
DiagramsもPythonで動くならLambdaでイケるだろうと。
もし、LambdaでDiagramsを動かしたい、そんな方にこの記事が届いてくれれば幸いです。
最初に結論
- LambdaのOSレイヤーから整える必要があり「コンテナLambda」構成が必要である
- Diagramsで必要なGraphvizのOS依存解消が必要だった
それErase AIで良いのでは?(言わない約束)
1.構成・概要
本記事では「Bedrock Agents→Lambda→S3」の箇所に絞って知見をshareします。
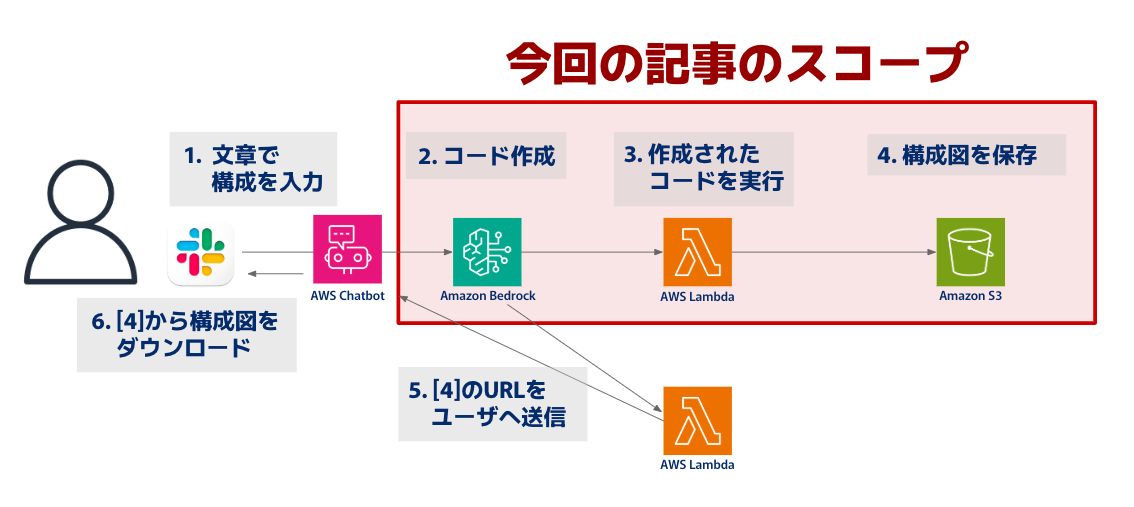
「5」のLambdaはもしかしたら不要かも?と思いながらも、マルチステップを試したい衝動からこの構成を検討した次第です。ただし、この記事内では動作のお話はしません。 (間に合わなかったデス...😵)
本当は、全て一連の流れが出来た!というもので出したかったのですが...。
Time is Moneyです。完成版はまた別の機会にお披露目致します。
Amazon Bedrock Agents
今回は下記の機能に注目して進めました。
- マルチステップでタスクの調整と実行をしてくれる
- 「Code Interpreter」で自らプログラムコードを生成して実行してくれる
Code Interpreterは2024/12月現在「Preview」機能となっています。
試す際はus-east-1など公開されているリージョンで試します。
Diagrams
構成図もコードで管理出来ると再現しやすいし使い回しが出来たりと良いことありますよね。
- クラウド システムのアーキテクチャをPython コードで描画
- 最新のAWSアイコンではない点に注意が必要
(IaCを元に生成AIで作ればいいじゃんは言わない約束)
2.Amazon Bedrock Agents 設定内容
今回検証するにあたって設定した内容をメモとして掲載します。
各設定値については精度が甘めな設定となる点ご容赦ください。
指示やパラメータをさらに詰めていけば、より精度の高い結果が出るため改良の余地ありとして参考情報程度にお願いします🙇
エージェント向けの指示
以下の指示を取り急ぎ設定。
ユーザの入力が曖昧すぎるとDiagramsに存在しないモジュールを出してきました。取り急ぎの処置として指示内に盛り込みます。
- ユーザからの依頼をもとにAWS構成に従ったPythonコードをdiagramsライブラリ用に生成してください
- ネットワークのモジュールに"Subnet"は存在しないため「from diagrams.aws.network import VPC, PublicSubnet, PrivateSubnet, InternetGateway, NATGateway」を基準として、必要に応じて追記してください
- 作成したPythonコードを実行し、実行結果の構成図画像をS3バケットに保存してください
- 作成した構成図画像のURLをユーザにSlackで送信してください

アクショングループ
本記事では「diagrams-python-code」が検証スコープとなります。
アクショングループ:send-slackに関しては動作検証不十分ですが、参考として掲載致します。
【Diagrams実行用】
- アクショングループ名: diagrams-python-code
- 説明: 与えられたトピックについて、Pythonコードをdiagramsライブラリ用に生成します。
| Name | Description | Type | Required |
|---|---|---|---|
| PythonCode | DiagramsのPythonコード | string | True |
【SlackへS3データ送信用】
- アクショングループ名: send-slack
- 説明: 作成されたpngファイルのURLをユーザーにSlack送信します。
| Name | Description | Type | Required |
|---|---|---|---|
| send-slack | 作成されたpngファイルのURLをユーザーにSlack送信します。 | string | True |
3.試行錯誤(バックエンド箇所)
ここからはBedrock Agentsが作成したPythonコードを実行する処理になります。
バックエンド処理で発生したエラーの試行錯誤を記載します。
Code Interpreter:モジュールエラー
まず試したのはBedrock Agentsの「Code Interpreter」です。
これが出来ればLambda自体もいらないと考えました。しかし簡単には行かない様子。
出力結果は「ゴメン、必要なライブラリが無くて出来ん」でした。
The diagrams library required to create the visual representation is not available in the execution environment.
エージェントのステップから追いかけると、Pythonコードは作成されているけどモジュールエラーが出ていることが確認できます。
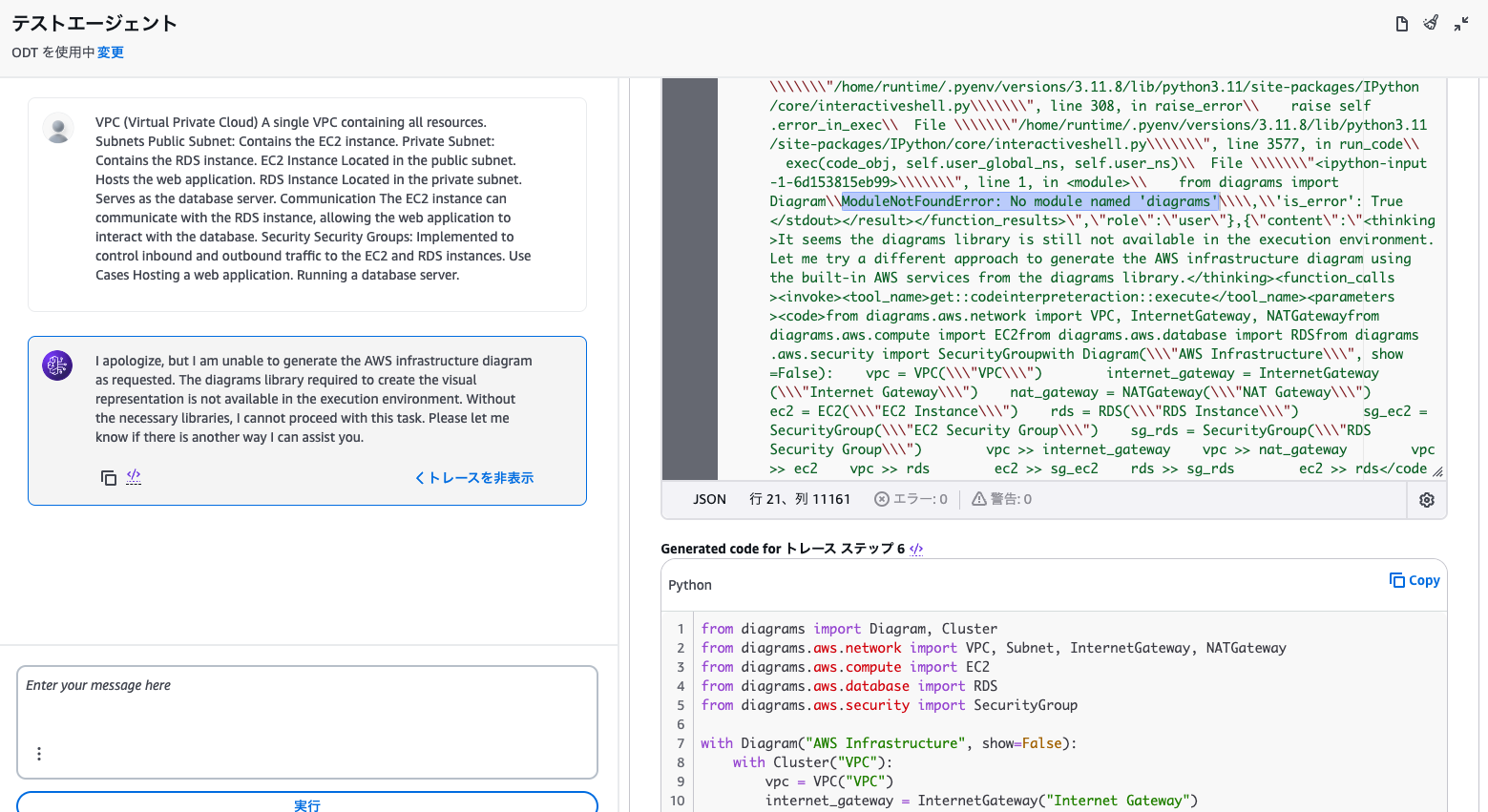
ModuleNotFoundError: No module named 'diagrams'
コード生成は出来るものの、実行環境が整っていない状況です。
Code InterpreterのみではDiagramsの実行は難しそうです。
LambdaでPython実行:モジュールエラー
では、Lambdaのカスタムレイヤーを使ってみましょう。
今回はCloudShell環境でカスタムレイヤー用のzipファイルを作成してみました。
$ python --version
Python 3.9.16
$ mkdir python
$ pip install -t python --platform manylinux2014_x86_64 --only-binary=:all: boto3 diagrams graphviz
$ zip -r layer.zip python
boto3は試行錯誤の末のおまじないです。本来不要です。
作成したlayer.zipをLambdaのカスタムレイヤーに登録しました。
満を持していざ実行
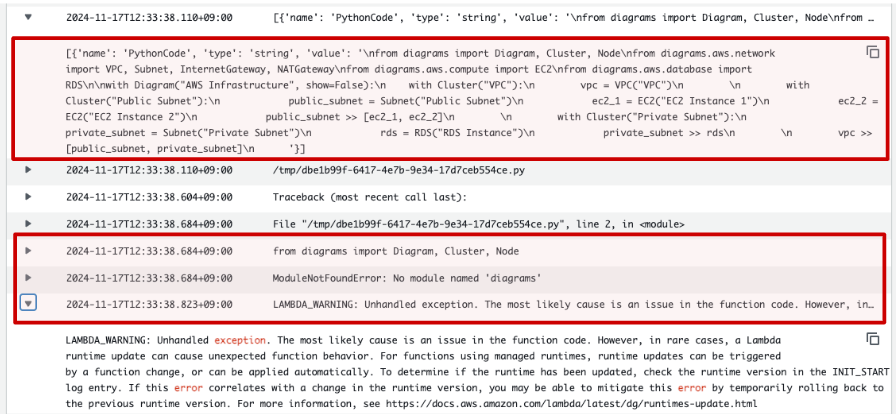
ModuleNotFoundError: No module named 'diagrams'
CodeInterpreterと同じく、モジュールが無いと怒られてしまいました。
カスタムレイヤーを設定しても解決しないのはドウイウコト...。
日曜AM6時:神からのお告げ
SNSで嘆いたのち、ふて寝したところ、みのるんさんからのお告げを頂きました。
(感謝っ・・・・!圧倒的感謝っ・・・・!)
どうやらGraphbizの必要パッケージをdnfやyumでインストールする必要がある様子。
Pythonモジュールの話だけではなく、OSレベルでの解決が必要になりました。
コンテナLambdaの構築を開始
Lambdaレイヤーに保存が可能なサイズに収まりきらないことが判明しました。
次の手としてECRからのビルドとして「コンテナLambda」に至ります。
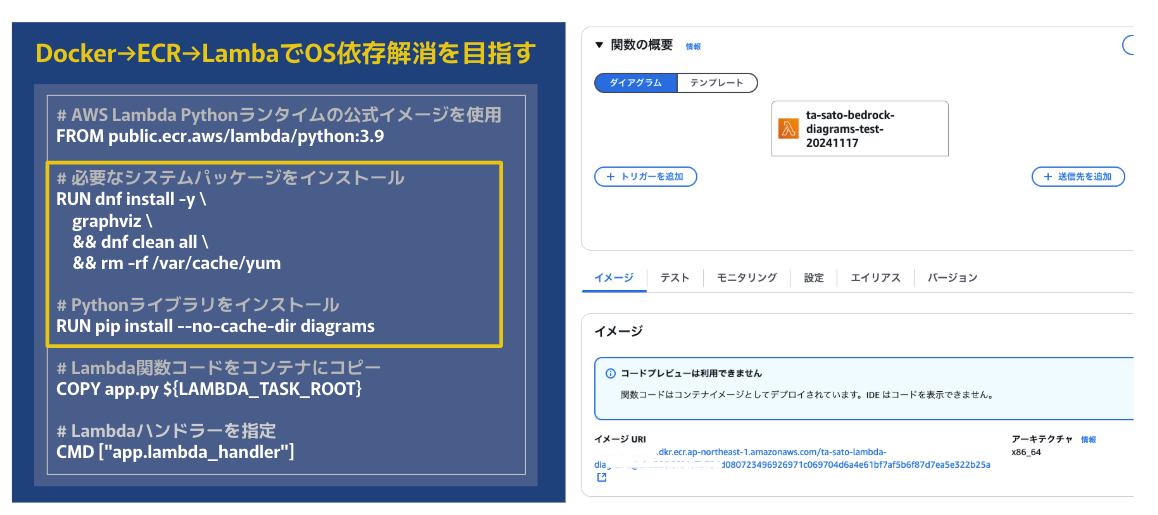
雑にDockerfileを作成します。
# AWS Lambda Pythonランタイムの公式イメージを使用
FROM public.ecr.aws/lambda/python:3.9
# 必要なシステムパッケージをインストール
RUN dnf install -y \
graphviz \
&& dnf clean all \
&& rm -rf /var/cache/yum
# Pythonライブラリをインストール
RUN pip install --no-cache-dir diagrams
# Lambda関数コードをコンテナにコピー
COPY app.py ${LAMBDA_TASK_ROOT}
# Lambdaハンドラーを指定
CMD ["app.lambda_handler"]
Lambda用のapp.pyもこんな感じで作成。
import json
import subprocess
import uuid
import os
import boto3
# Lambdaの環境変数からS3バケット名とS3保存用のファイル名を取得
S3_BUCKET_NAME = os.getenv("S3_BUCKET_NAME")
FILE_NAME = os.getenv("FILE_NAME")
def lambda_handler(event, context):
agent = event['agent']
actionGroup = event['actionGroup']
function = event['function']
parameters = event.get('parameters', [])
print(event)
print(parameters)
# パラメータからPythonコードを取得
python_code = next((item["value"] for item in event["parameters"] if item["name"] == "PythonCode"), "")
if not python_code:
raise ValueError("No Python code provided in parameters.")
# Pythonコードを一時ファイルに保存
temp_script_path = f"/tmp/{uuid.uuid4()}.py"
with open(temp_script_path, "w") as temp_script:
temp_script.write(python_code)
print (temp_script_path)
# 一時ファイルを実行して画像生成
subprocess.run(
["python", temp_script_path],
check=True,
cwd="/tmp"
)
file_name = FILE_NAME
file_path = f"/tmp/{file_name}"
output = subprocess.getoutput("ls -l /tmp")
print(output)
print(file_path)
# S3にファイルを保存する準備
s3 = boto3.client("s3")
bucket_name = S3_BUCKET_NAME
s3.upload_file(file_path, bucket_name, file_name)
# Execute your business logic here. For more information, refer to: https://docs.aws.amazon.com/bedrock/latest/userguide/agents-lambda.html
responseBody = {
"TEXT": {
"body": "The function {} was called successfully!".format(function)
}
}
action_response = {
'actionGroup': actionGroup,
'function': function,
'functionResponse': {
'responseBody': responseBody
}
}
dummy_function_response = {'response': action_response, 'messageVersion': event['messageVersion']}
print("Response: {}".format(dummy_function_response))
return dummy_function_response
DockerfileをECRへpush→Lambdaを構築しました。
いざ実行:成功
Bedrock Agentsの画面からプロンプトを実行したところ、生成されたPythonコードを元にS3バケットへデータが保存されました!
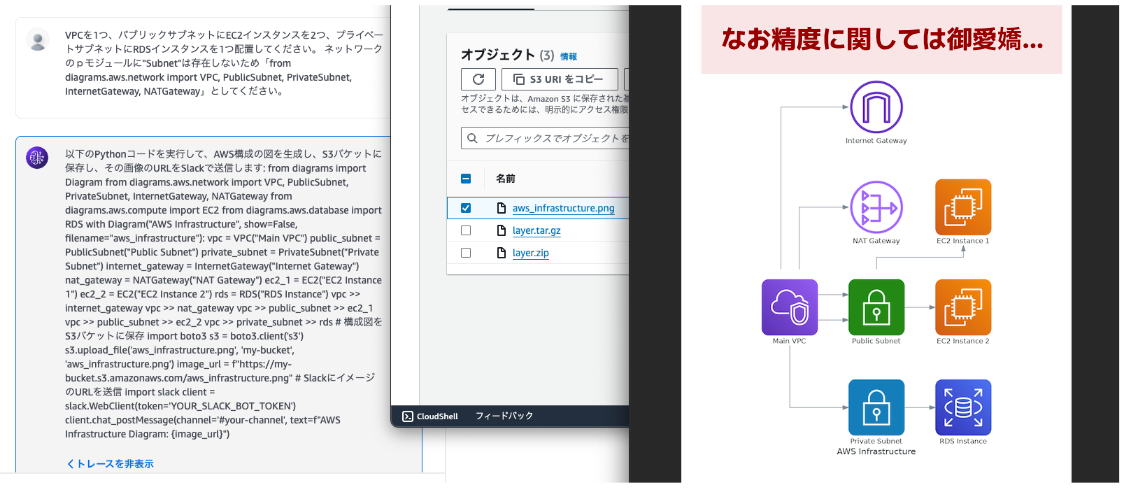
精度は御愛嬌...。
ですが、第一歩としてはバッチリです。
- Amazon Bedorock Agentsを利用してDiagramsのPythonコードを生成
- Lambdaで生成されたコードを実行
- S3バケットに作成したpngデータを保存
一連の流れが出来たので、ここからは精度を高めていく方法とSlackとの連携部分を詰める形となります。
研究課題は多いですがBedrockを使って生成AIを勉強する1歩として歯ごたえがありました。(主にLambdaでしたが)
最後に
ブログを書く際などに利用はまだ難しいですが、理想形の動きが出来るように引き続き作成したいと思います。
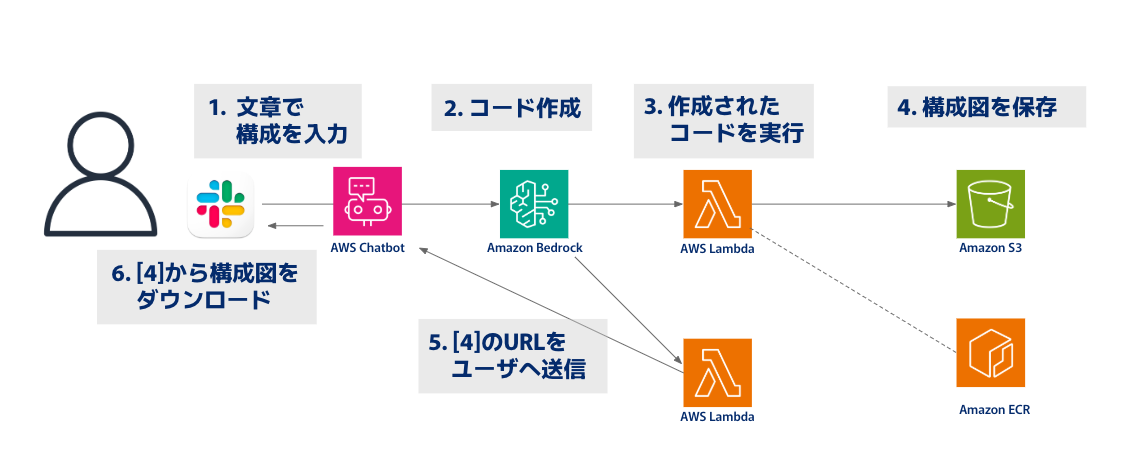
頂いた意見や個人的な改良点として以下メモになります。
- pngじゃなくてパワポとかに出して手動で修正出来ると幅広がりそう
- Pythonコードもあとから拾えれば自分で簡単に修正出来そう
- 実行する度にpngデータ上書きされているのでS3保存時のファイル名は検討必要そう
Bedrockでの開発をすることで、インフラエンジニアでもフロントエンドやバックエンドについて触ってみる機会も増えるので引き続き遊んでみたいと思います。
参考サイト
- AmazonBedrock BlackBelt Agents 自律型 AI の実現に向けて:
- 検討編 #04a
- 動作理解編 #04b
- 開発・運用編 #04c