背景
SQL の再帰は,なかなか分かりにくいです.
そこで,自分なりに図解してみました.
準備
以下の図のような木構造のデータを考えます.

これを,以下のようになテーブルで表すとします.
p は 親(parent), c は 子(child), n は必要な個数とします.
A を作るのに B が 1つ, C が 4つ 必要であることを示しています. C は, A を作るときにも B を作るときにも使います.ネジみたいな感じです.

再帰する SQL
再帰の処理として,以下の SQL を考えます.
WITH RECURSIVE r AS (
SELECT * FROM tree WHERE p = "A"
UNION ALL
SELECT tree.* FROM tree, r WHERE tree.p = r.c
)
SELECT * FROM r
では,処理を追いかけてみます.
最初のステップ
先の SQL で, UNION ALL の上の部分
SELECT * FROM tree WHERE p = "A"
は,(ORACLE では?)初期化ブランチと呼ばれており,ここが最初に実行されます.
その結果が, WITH で指定された r というテーブルに書き込まれます.

再帰 1回目
先の SQL の, UNION ALL の下の部分
SELECT tree.*
FROM tree, r
WHERE tree.p = r.c
は,(ORACLE では?)再帰的ブランチと呼ばれており,ここが再帰的に実行されます.
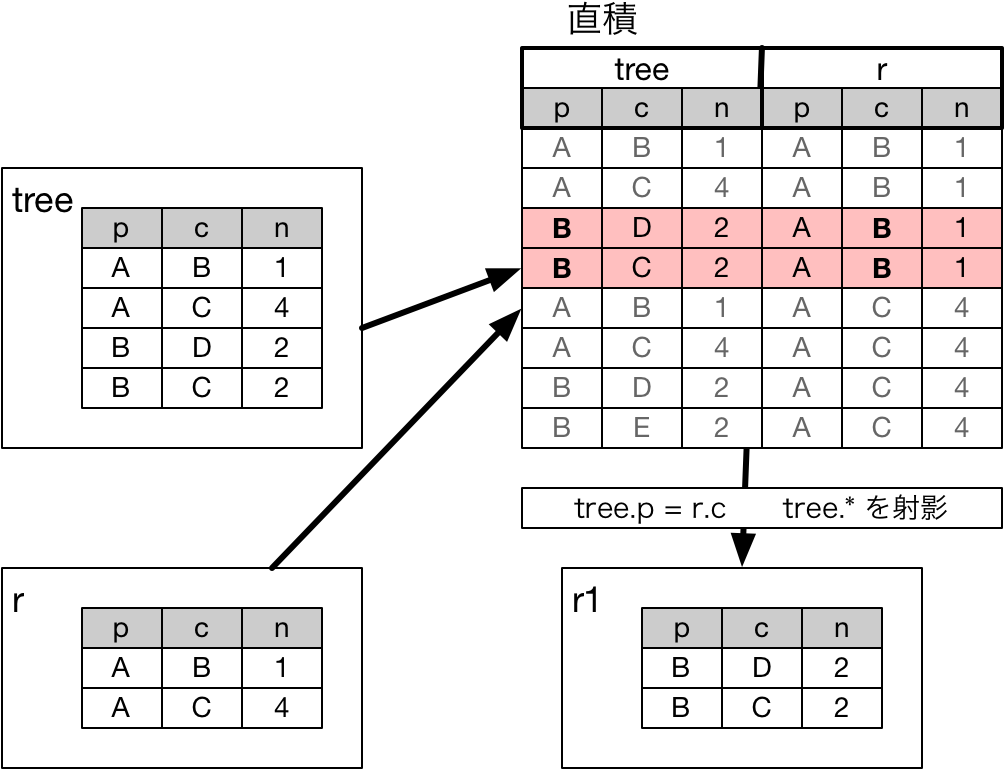
まず 1回目として,
FROM tree, r
に従って,tree と,上で生成された r から,直積のテーブルが生成されます.
そして
WHERE tree.p = r.c
により tree.p と r.c が一致するレコードが選択され,
SELECT tree.*
により tree の部分だけ取り出されます.
これが r に書き込まれますが,前の r と区別するために r1 に書き込まれることとします,
再帰 2回目
再帰処理ですので,次は,
FROM tree, r
の処理を,tree と,上で生成された r1 に対して行います.
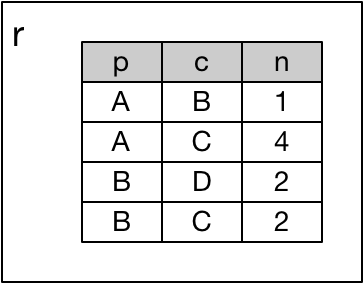
しかし,tree と r1 の直積のテーブルには, tree.p と r.c が一致するレコードがないため,次の r ここでは r2 を呼ぶこととしますが,これには何も書き込まれません.
結果が空だったので,ここで再帰は終了します.

結合
最後に
UNION ALL
によって, r, r1, r2 が結合され,以下のような出力が得られます.
UNION と UNION ALL
UNION と UNION ALL の違いを見てみましょう.
再帰の処理として,以下の SQL を考えます.
WITH RECURSIVE r AS (
SELECT c FROM tree WHERE p = "A"
UNION ALL
SELECT tree.c FROM tree, r WHERE tree.p = r.c
)
SELECT * FROM r
この SQL は,r へ c のみを出力します.
このため,上で追いかけた処理は,以下のようになります.
再帰 1回目

再帰 2回目

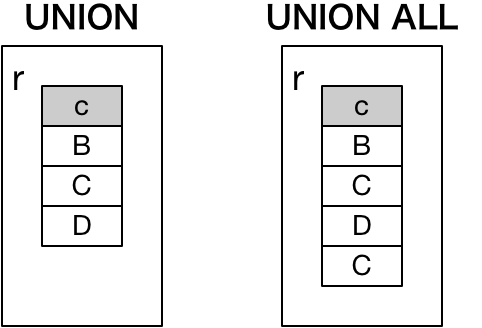
この結果が結合されますが,
UNION は重複を排除する
UNION ALL は重複を排除しない
という処理になることから,以下のように, r r1 で重複している 値C の出力が異なることになります.
まとめ
SQLの再帰を図解しているものをいくつか見ましたが,途中で再帰的に生成されるテーブルを書いた方が分かりやすいかなと思い,自分なりに図解してみました.
最後に,再帰的ブランチを
SELECT tree.* FROM tree, r WHERE tree.p = r.c
のように,直積(クロス結合)で書いている例がほとんどですが,個人的には
WITH RECURSIVE r AS (
SELECT * FROM tree WHERE p = "A"
UNION ALL
SELECT tree.* FROM tree INNER JOIN r ON tree.p = r.c
)
SELECT * FROM r
のように,内部結合で書いた方が分かりやすいんじゃないかと思っています.