PyTorch Metric Learning をGoogle Colaboratory 上で使って深層距離学習 (Deep Metric Learning) をしてみました。深層距離学習は、ラベルつきのデータに対して、同じラベルのデータは近くに、違うラベルのデータは遠くに位置するように「距離」を学習する深層学習です(浅い理解)。
PyTorch Metric Learning インストール
次のようにしてインストールします。
!pip install pytorch-metric-learning
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting pytorch-metric-learning
Downloading pytorch_metric_learning-1.5.2-py3-none-any.whl (111 kB)
[K |████████████████████████████████| 111 kB 30.4 MB/s
[?25hRequirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (from pytorch-metric-learning) (0.13.1+cu113)
Requirement already satisfied: torch>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-metric-learning) (1.12.1+cu113)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.7/dist-packages (from pytorch-metric-learning) (1.0.2)
Requirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from pytorch-metric-learning) (4.64.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from pytorch-metric-learning) (1.21.6)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch>=1.6.0->pytorch-metric-learning) (4.1.1)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->pytorch-metric-learning) (1.1.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->pytorch-metric-learning) (3.1.0)
Requirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->pytorch-metric-learning) (1.7.3)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision->pytorch-metric-learning) (7.1.2)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from torchvision->pytorch-metric-learning) (2.23.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision->pytorch-metric-learning) (1.24.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision->pytorch-metric-learning) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision->pytorch-metric-learning) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision->pytorch-metric-learning) (2022.6.15)
Installing collected packages: pytorch-metric-learning
Successfully installed pytorch-metric-learning-1.5.2
PyTorch をインポートし、GPUが使える環境なら使うようにしておきます。
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
エンコーダーの定義
エンコーダーを定義します。ここでは、簡単な MLP (Multi-Layer Perceptron) を用いたいと思います。出力は、結果を2次元で表示したいため2次元にします。
class Encoder(torch.nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Encoder, self).__init__()
self.l1 = torch.nn.Linear(n_input, n_hidden)
self.l2 = torch.nn.Linear(n_hidden, n_hidden)
self.l3 = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.sigmoid(self.l1(x))
x = torch.sigmoid(self.l2(x))
return self.l3(x)
学習とテスト用の関数
次のように学習とテスト用の関数を定義します。
def train(model, loss_func, mining_func, device, dataloader, optimizer, epoch):
model.train()
total_loss = 0
for idx, (inputs, labels) in enumerate(dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
embeddings = model(inputs)
indices_tuple = mining_func(embeddings, labels)
loss = loss_func(embeddings, labels, indices_tuple)
loss.backward()
optimizer.step()
total_loss += loss.detach().cpu().numpy()
return total_loss
def test(model, dataloader, device, epoch):
model.eval()
with torch.no_grad():
total_loss = 0
for idx, (inputs, labels) in enumerate(dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
embeddings = model(inputs)
indices_tuple = mining_func(embeddings, labels)
loss = loss_func(embeddings, labels, indices_tuple)
total_loss += loss.detach().cpu().numpy()
return total_loss
アヤメのデータセット
みんな大好きアヤメのデータを使ってみましょう。データのロードをして、念のため、データの形状も確認しておきます。
from sklearn.datasets import load_iris
dataset = load_iris()
dataset.data.shape, dataset.target.shape
((150, 4), (150,))
説明変数 X と目的変数 Y を設定し、training data と test data に分けます。
import numpy as np
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
それぞれデータローダーに格納します。
from torch.utils.data import DataLoader, TensorDataset
batch_size = 16
train_loader = DataLoader(TensorDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
test_loader = DataLoader(TensorDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
PyTorch Metric Learning の距離や損失関数などの定義をします。
from pytorch_metric_learning.distances import CosineSimilarity
from pytorch_metric_learning.reducers import ThresholdReducer
from pytorch_metric_learning.losses import TripletMarginLoss
from pytorch_metric_learning.miners import TripletMarginMiner
n_hidden = 64
n_output = 2
epochs = 1000
lr = 1e-6
distance = CosineSimilarity()
reducer = ThresholdReducer(low = 0)
loss_func = TripletMarginLoss(margin=0.2, distance=distance, reducer=reducer)
mining_func = TripletMarginMiner(margin=0.2, distance=distance)
model = Encoder(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
次のようにして学習し、学習履歴を控えながらベストモデルを保存します。
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, loss_func, mining_func, device, train_loader, optimizer, epoch)
test_loss = test(model, test_loader, device, epoch)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 0.99241, Test Loss: 0.99168
Epoch: 004, Train Loss: 0.99197, Test Loss: 0.99157
Epoch: 005, Train Loss: 0.99184, Test Loss: 0.99112
Epoch: 006, Train Loss: 0.99191, Test Loss: 0.99100
Epoch: 007, Train Loss: 0.99216, Test Loss: 0.99047
Epoch: 019, Train Loss: 0.99193, Test Loss: 0.99007
Epoch: 020, Train Loss: 0.99030, Test Loss: 0.98973
Epoch: 029, Train Loss: 0.98955, Test Loss: 0.98950
Epoch: 030, Train Loss: 0.98932, Test Loss: 0.98945
Epoch: 032, Train Loss: 0.99002, Test Loss: 0.98943
Epoch: 033, Train Loss: 0.98978, Test Loss: 0.98882
Epoch: 036, Train Loss: 0.98944, Test Loss: 0.98817
Epoch: 037, Train Loss: 0.98881, Test Loss: 0.98781
Epoch: 045, Train Loss: 0.98826, Test Loss: 0.98778
Epoch: 046, Train Loss: 0.98845, Test Loss: 0.98754
Epoch: 048, Train Loss: 0.98850, Test Loss: 0.98718
Epoch: 049, Train Loss: 0.98801, Test Loss: 0.98657
Epoch: 054, Train Loss: 0.98790, Test Loss: 0.98631
Epoch: 057, Train Loss: 0.98673, Test Loss: 0.98624
Epoch: 061, Train Loss: 0.98507, Test Loss: 0.98622
Epoch: 063, Train Loss: 0.98740, Test Loss: 0.98552
Epoch: 064, Train Loss: 0.98496, Test Loss: 0.98522
Epoch: 065, Train Loss: 0.98623, Test Loss: 0.98479
Epoch: 066, Train Loss: 0.98739, Test Loss: 0.98457
Epoch: 068, Train Loss: 0.98605, Test Loss: 0.98423
Epoch: 072, Train Loss: 0.98687, Test Loss: 0.98345
Epoch: 078, Train Loss: 0.98376, Test Loss: 0.98231
Epoch: 084, Train Loss: 0.98555, Test Loss: 0.98156
Epoch: 088, Train Loss: 0.98206, Test Loss: 0.98103
Epoch: 090, Train Loss: 0.98197, Test Loss: 0.97928
Epoch: 092, Train Loss: 0.98035, Test Loss: 0.97912
Epoch: 098, Train Loss: 0.98070, Test Loss: 0.97863
Epoch: 102, Train Loss: 0.97971, Test Loss: 0.97859
Epoch: 103, Train Loss: 0.98025, Test Loss: 0.97698
Epoch: 112, Train Loss: 0.97765, Test Loss: 0.97587
Epoch: 116, Train Loss: 0.97657, Test Loss: 0.97489
Epoch: 117, Train Loss: 0.97636, Test Loss: 0.97482
Epoch: 118, Train Loss: 0.97627, Test Loss: 0.97418
Epoch: 123, Train Loss: 0.97289, Test Loss: 0.97315
Epoch: 124, Train Loss: 0.97541, Test Loss: 0.97285
Epoch: 125, Train Loss: 0.97386, Test Loss: 0.97226
Epoch: 127, Train Loss: 0.97387, Test Loss: 0.97167
Epoch: 129, Train Loss: 0.97161, Test Loss: 0.97128
Epoch: 130, Train Loss: 0.97204, Test Loss: 0.96956
Epoch: 136, Train Loss: 0.96793, Test Loss: 0.96867
Epoch: 137, Train Loss: 0.96949, Test Loss: 0.96524
Epoch: 145, Train Loss: 0.96681, Test Loss: 0.96377
Epoch: 146, Train Loss: 0.96643, Test Loss: 0.96127
Epoch: 154, Train Loss: 0.96524, Test Loss: 0.95935
Epoch: 157, Train Loss: 0.96106, Test Loss: 0.95819
Epoch: 160, Train Loss: 0.95964, Test Loss: 0.95784
Epoch: 161, Train Loss: 0.96107, Test Loss: 0.95578
Epoch: 164, Train Loss: 0.95951, Test Loss: 0.95568
Epoch: 165, Train Loss: 0.95686, Test Loss: 0.95538
Epoch: 166, Train Loss: 0.95955, Test Loss: 0.95265
Epoch: 175, Train Loss: 0.95063, Test Loss: 0.95086
Epoch: 177, Train Loss: 0.95025, Test Loss: 0.94941
Epoch: 178, Train Loss: 0.95392, Test Loss: 0.94616
Epoch: 182, Train Loss: 0.94772, Test Loss: 0.94466
Epoch: 183, Train Loss: 0.95053, Test Loss: 0.94061
Epoch: 185, Train Loss: 0.94653, Test Loss: 0.93809
Epoch: 189, Train Loss: 0.93748, Test Loss: 0.93564
Epoch: 195, Train Loss: 0.93677, Test Loss: 0.93552
Epoch: 197, Train Loss: 0.93782, Test Loss: 0.93293
Epoch: 198, Train Loss: 0.93335, Test Loss: 0.92084
Epoch: 210, Train Loss: 0.91781, Test Loss: 0.91578
Epoch: 213, Train Loss: 0.92099, Test Loss: 0.91287
Epoch: 216, Train Loss: 0.91053, Test Loss: 0.91281
Epoch: 218, Train Loss: 0.91712, Test Loss: 0.90644
Epoch: 220, Train Loss: 0.90175, Test Loss: 0.89513
Epoch: 227, Train Loss: 0.89674, Test Loss: 0.89301
Epoch: 229, Train Loss: 0.89202, Test Loss: 0.88476
Epoch: 233, Train Loss: 0.88466, Test Loss: 0.88371
Epoch: 235, Train Loss: 0.88655, Test Loss: 0.87473
Epoch: 239, Train Loss: 0.87748, Test Loss: 0.87354
Epoch: 241, Train Loss: 0.86688, Test Loss: 0.87266
Epoch: 242, Train Loss: 0.87744, Test Loss: 0.87083
Epoch: 243, Train Loss: 0.85890, Test Loss: 0.86515
Epoch: 244, Train Loss: 0.87090, Test Loss: 0.86103
Epoch: 245, Train Loss: 0.86939, Test Loss: 0.85576
Epoch: 247, Train Loss: 0.86642, Test Loss: 0.85376
Epoch: 248, Train Loss: 0.85294, Test Loss: 0.85292
Epoch: 249, Train Loss: 0.85714, Test Loss: 0.84361
Epoch: 254, Train Loss: 0.85107, Test Loss: 0.84044
Epoch: 255, Train Loss: 0.84156, Test Loss: 0.83828
Epoch: 256, Train Loss: 0.84330, Test Loss: 0.83485
Epoch: 258, Train Loss: 0.82744, Test Loss: 0.82655
Epoch: 261, Train Loss: 0.82307, Test Loss: 0.81493
Epoch: 263, Train Loss: 0.82220, Test Loss: 0.80559
Epoch: 266, Train Loss: 0.80849, Test Loss: 0.78984
Epoch: 272, Train Loss: 0.79612, Test Loss: 0.74984
Epoch: 275, Train Loss: 0.76995, Test Loss: 0.74395
Epoch: 282, Train Loss: 0.75578, Test Loss: 0.72727
Epoch: 284, Train Loss: 0.75554, Test Loss: 0.72121
Epoch: 286, Train Loss: 0.74829, Test Loss: 0.70264
Epoch: 289, Train Loss: 0.68119, Test Loss: 0.70008
Epoch: 290, Train Loss: 0.67815, Test Loss: 0.69433
Epoch: 291, Train Loss: 0.69742, Test Loss: 0.69429
Epoch: 292, Train Loss: 0.69399, Test Loss: 0.67597
Epoch: 293, Train Loss: 0.67784, Test Loss: 0.64868
Epoch: 294, Train Loss: 0.70161, Test Loss: 0.64649
Epoch: 297, Train Loss: 0.67725, Test Loss: 0.63933
Epoch: 298, Train Loss: 0.62987, Test Loss: 0.63854
Epoch: 299, Train Loss: 0.64286, Test Loss: 0.62260
Epoch: 301, Train Loss: 0.62527, Test Loss: 0.61840
Epoch: 305, Train Loss: 0.63836, Test Loss: 0.57104
Epoch: 308, Train Loss: 0.60170, Test Loss: 0.54871
Epoch: 310, Train Loss: 0.55816, Test Loss: 0.54775
Epoch: 315, Train Loss: 0.53502, Test Loss: 0.54425
Epoch: 320, Train Loss: 0.57343, Test Loss: 0.54019
Epoch: 321, Train Loss: 0.53485, Test Loss: 0.53040
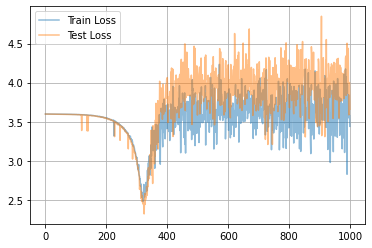
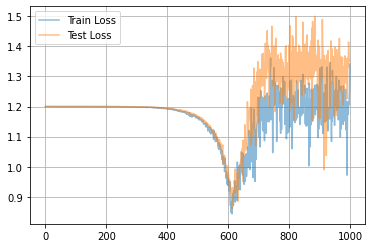
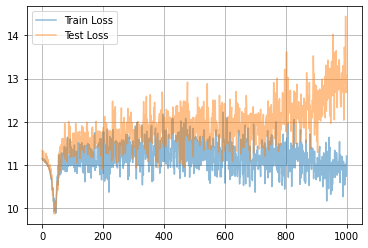
学習曲線は次のようになりました。
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.5, label="Train Loss")
plt.plot(test_hist, alpha=0.5, label="Test Loss")
plt.grid()
plt.legend()
plt.show()
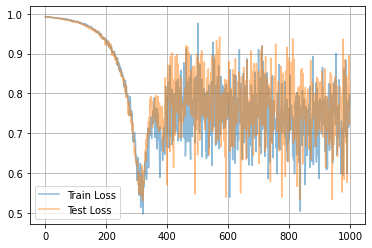
一旦ロスが落ちてから、また上がってますね...?
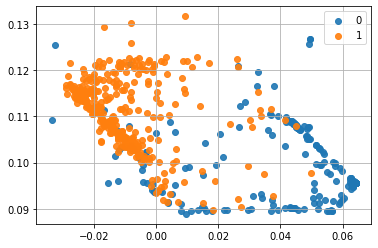
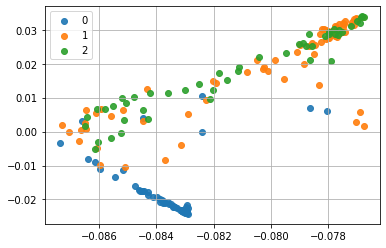
ベストモデルを使って説明変数を2次元にマッピングします。
embedding = {}
for X, Y in [[X_train, Y_train], [X_test, Y_test]]:
for z, label in zip(best_model(X.to(device)), Y):
z = z.detach().cpu().numpy()
y = int(label.detach().cpu().numpy())
if y not in embedding.keys():
embedding[y] = []
embedding[y].append(z)
for label, Z, in embedding.items():
plt.scatter([z[0] for z in Z], [z[1] for z in Z], alpha=0.9, label=label)
plt.legend()
plt.grid()
plt.show()
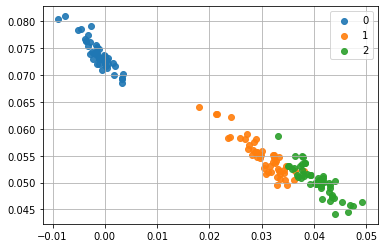
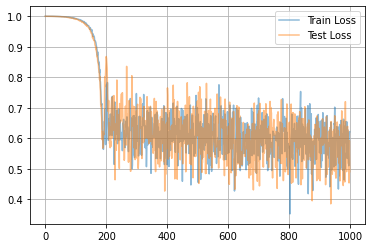
うん、皆さんがよく知ってるアヤメのデータですね。ちなみに、当然ですが学習するたびに結果は変わります。別の計算例を示すと、こんな感じです。
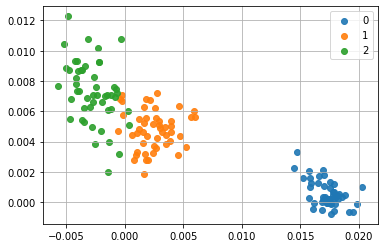
乳がんデータセット
続いて、乳がんデータセットをロードして、同様に深層距離学習してみましょう。
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
dataset.data.shape, dataset.target.shape
((569, 30), (569,))
上記のようにロードする部分は当然違うのですが、それ以外は同じコードを流用できます。
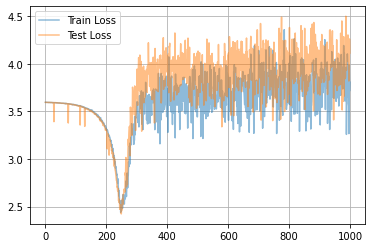
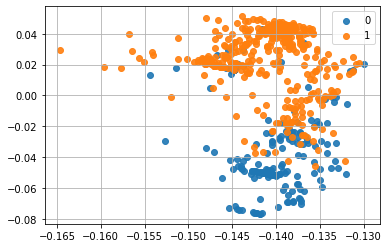
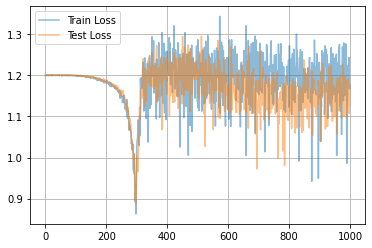
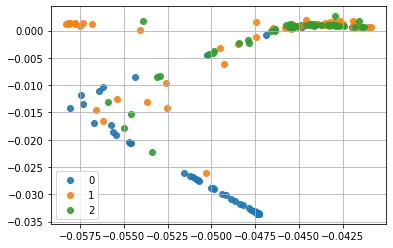
同じデータに対する別の計算例
ワインのデータセット
ワインのデータセットに関しても、ロードの部分以外は同じです。
from sklearn.datasets import load_wine
dataset = load_wine()
dataset.data.shape, dataset.target.shape
((178, 13), (178,))

手書き数字データセット
手書き数字データセットについても同様に。
from sklearn.datasets import load_digits
dataset = load_digits()
dataset.data.shape, dataset.target.shape
((1797, 64), (1797,))
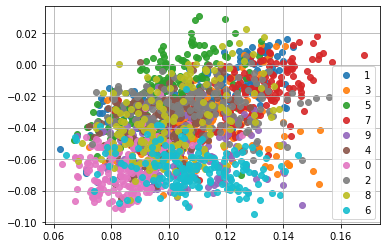
うーん、あまりキレイに分かれてないですね。
手書き数字データセットは画像データなので、次のように model を CNN に置き換えたら結果は良くなるでしょうか?
import numpy as np
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :].reshape(-1, 1, 8, 8), dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :].reshape(-1, 1, 8, 8), dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv_layers = torch.nn.Sequential(
torch.nn.Conv2d(in_channels = 1, out_channels = 16, kernel_size = 2, stride=1, padding=0),
torch.nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 2, stride=1, padding=0),
)
self.dence = torch.nn.Sequential(
torch.nn.Linear(32 * 6 * 6, 128),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(128, 64),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(64, 2),
)
def forward(self,x):
x = self.conv_layers(x)
x = x.view(x.size(0), -1)
x = self.dence(x)
return x
def check_cnn_size(self, size_check):
out = self.conv_layers(size_check)
return out
model = CNN().to(device)
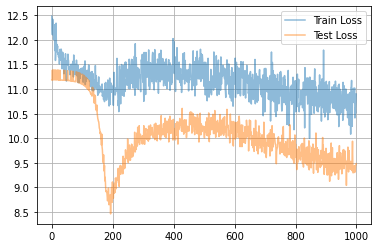
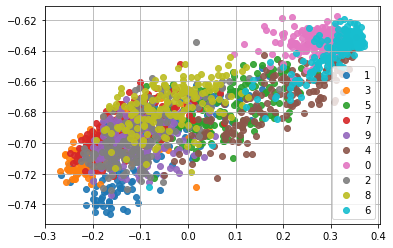
んー、あんま変わらんような...ちょっとは良くなったのかな?もうちょっと頑張って条件検討したら良くなるかも知れないけど。