- PythonでExcelファイルを開く
- Pythonで日本地図に色を塗る
この2つをここでは取り扱います。 Google Colaboratory 上で動きます。
日本地図に色を塗る
ライブラリ japanmap のインストール
!pip install japanmap
必要なライブラリのインポート
from japanmap import pref_names,pref_code,picture
都道府県の名前
print(pref_names)
['_', '北海道', '青森県', '岩手県', '宮城県', '秋田県', '山形県', '福島県', '茨城県', '栃木県', '群馬県', '埼玉県', '千葉県', '東京都', '神奈川県', '新潟県', '富山県', '石川県', '福井県', '山梨県', '長野県', '岐阜県', '静岡県', '愛知県', '三重県', '滋賀県', '京都府', '大阪府', '兵庫県', '奈良県', '和歌山県', '鳥取県', '島根県', '岡山県', '広島県', '山口県', '徳島県', '香川県', '愛媛県', '高知県', '福岡県', '佐賀県', '長崎県', '熊本県', '大分県', '宮崎県', '鹿児島県', '沖縄県']
都道府県コード
pref_code('東京都')
13
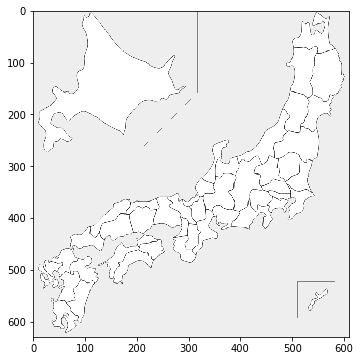
白地図の描画
%matplotlib inline
import matplotlib.pyplot as plt
from pylab import rcParams
rcParams['figure.figsize'] = 6, 6
plt.imshow(picture())
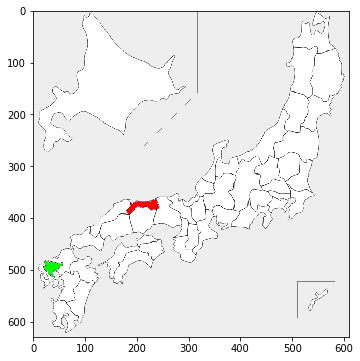
指定した都道府県の色ぬり
plt.imshow(picture({'鳥取':'red','佐賀':(0,255,0)}))
Excelファイルを開く
題材として、 帝国書院 様のホームページで公開している都道府県別統計データをエクセルファイル化したものを用いました。
ダウンロード
urllib はダウンロード用のライブラリですが、 Google Colab 上で使うと、Google Colab 上にアップロードすることになります。Google Colabでは、セッションが終わるとアップロードしたファイルは消えてしまうので、そのときは再度アップロードしましょう。
# urllibによるダウンロード
import urllib.request
url = "エクセルファイルが置いてあるURL"
urllib.request.urlretrieve(url, 'Teikoku-Shoin-Japan.xlsx')
Excel を開く
PythonでExcelファイルを開く方法は、私が把握している限り2つほどあります。
import pandas as pd
excel = pd.read_excel('Teikoku-Shoin-Japan.xlsx') # こっちの方法だとうまくいかないかも
import pandas as pd
excel = pd.ExcelFile('Teikoku-Shoin-Japan.xlsx') # こっちのほうがうまくいく気がする
Excel は csv などと違い、複数のシートから成っています。
for s in enumerate(excel.sheet_names):
print(s) # シートの名前と番号を列挙
(0, '面積\u3000〔2017年〕')
(1, '人口\u3000〔2018年〕')
(2, '人口密度\u3000〔2018年〕')
(3, '人口増加率\u3000〔2010~2015年〕')
(4, '老年(65歳以上)人口率\u3000〔2018年〕')
(5, '産業別人口割合(2015年)')
(6, '平均寿命(女)\u3000〔2015年〕')
(7, '平均寿命(男)\u3000〔2015年〕')
(8, '耕地面積〔2017年〕')
(9, '耕地率\u3000〔2017年〕')
(10, '森林率・人工林率〔2017年〕')
(11, '小麦の生産\u3000〔2018年〕')
(12, '米の生産\u3000〔2017年〕')
(13, 'さつまいもの生産\u3000〔2017年〕')
(14, 'じゃがいもの生産\u3000〔2017年〕')
(15, '大豆の生産\u3000〔2017年〕')
(16, '落花生の生産\u3000〔2017年〕')
(17, 'キャベツの生産\u3000〔2017年〕')
(18, 'きゅうりの生産\u3000〔2017年〕')
(19, 'すいかの生産\u3000〔2017年〕')
(20, 'だいこんの生産\u3000〔2017年〕')
(21, 'なたねの生産〔2017年〕')
(22, 'にんじんの生産\u3000〔2017年〕')
(23, 'ねぎの生産\u3000〔2017年〕')
(24, 'はくさいの生産\u3000〔2017年〕')
(25, 'ピーマンの生産\u3000〔2017年〕')
(26, 'ほうれん草の生産\u3000〔2017年〕')
(27, '茶(荒茶)の生産\u3000〔2017年〕')
(28, 'いちごの生産\u3000〔2017年〕')
(29, 'うめの生産\u3000〔2017年〕')
(30, 'メロンの生産\u3000〔2017年〕')
(31, '柿の生産\u3000〔2017年〕')
(32, 'さくらんぼの生産\u3000〔2017年〕')
(33, 'みかんの生産\u3000〔2017年〕')
(34, 'ももの生産\u3000〔2017年〕')
(35, 'りんごの生産\u3000〔2017年〕')
(36, '菊の出荷量 〔2017年〕')
(37, 'パンジーの出荷量 〔2017年〕')
(38, '洋ラン類(切り花)の出荷量\u3000〔2017年〕')
(39, 'ブロイラーの飼養羽数\u3000〔2018年〕')
(40, '豚の飼養頭数\u3000〔2018年〕')
(41, '肉牛の飼養頭数\u3000〔2018年〕')
(42, '乳牛の飼養頭数\u3000〔2018年〕')
(43, 'まゆの生産 〔2017年〕')
(44, '農業産出額\u3000〔2017年〕')
(45, '米の産出額\u3000〔2017年〕')
(46, '麦類の産出額\u3000〔2017年〕')
(47, '豆類の産出額\u3000〔2017年〕')
(48, 'いも類の産出額\u3000〔2017年〕')
(49, '野菜の産出額\u3000〔2017年〕')
(50, '果実の産出額\u3000〔2017年〕')
(51, '花きの産出額\u3000〔2017年〕')
(52, '工芸農作物の産出額\u3000〔2017年〕')
(53, '畜産の産出額\u3000〔2017年〕')
(54, '漁業生産量(漁業・養殖業)〔2016年〕')
(55, 'いかの漁獲量\u3000〔2016年〕')
(56, 'かつおの漁獲量\u3000〔2016年〕')
(57, 'さんまの漁獲量\u3000〔2016年〕')
(58, 'まいわしの漁獲量\u3000〔2016年〕')
(59, 'まぐろの漁獲量\u3000〔2016年〕')
(60, 'かきの養殖\u3000〔2016年〕')
(61, 'ほたてがいの養殖\u3000〔2016年〕')
(62, 'わかめの養殖\u3000〔2016年〕')
(63, '素材(原木)の生産\u3000〔2016年〕')
(64, '工業出荷額\u3000〔2016年〕')
(65, '果実酒の生産 〔2016年〕')
(66, '焼ちゅうの生産 〔2016年〕')
(67, '清酒(濁酒を含む)の生産\u3000〔2016年〕')
(68, 'ビールの生産\u3000〔2016年〕')
(69, '石油・石炭製品の生産 〔2016年〕')
(70, '半導体の生産\u3000〔2016年〕')
(71, '産業用ロボットの生産\u3000〔2016年〕')
(72, '自動車(二輪自動車を含む)の生産\u3000〔2016年〕')
(73, '繊維の生産\u3000〔2016年〕')
(74, '鉄鋼の生産\u3000〔2016年〕')
(75, '集積回路の生産\u3000〔2016年〕')
(76, '1人あたりの県民所得\u3000〔2015年〕')
(77, '1人あたりの都市公園面積\u3000〔2017年3月末〕')
(78, '1人あたりの電力需要量\u3000〔2015年〕')
(79, '1日1人あたりのごみ排出量\u3000〔2016年〕')
(80, '下水道の普及率\u3000〔2018年〕')
(81, '1世帯あたりの乗用車台数\u3000〔2018年〕')
(82, '小売業年間販売額\u30002015年')
(83, '公害苦情件数\u3000〔2017年〕')
適当なシートを選択してみます
sheet_index = 2
print(excel.sheet_names[sheet_index])
sheet = excel.parse(excel.sheet_names[sheet_index], header=None) # 2枚目のシートの中身を pandas 形式にする
人口密度 〔2018年〕
sheet.head() # データの形を確認する
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 出典:平成30年住民基本台帳人口・世帯数表、平成29年全国都道府県市区町村別面積調 | NaN | NaN |
| 1 | 県コード | 県名 | (人/km2) |
| 2 | 1 | 北海道 | 64 |
| 3 | 2 | 青森 | 136 |
| 4 | 3 | 岩手 | 83 |
データの加工
sheet.iloc[2:49, [0, 2]] # 必要部分を抜き出す
| 0 | 2 | |
|---|---|---|
| 2 | 1 | 64 |
| 3 | 2 | 136 |
| 4 | 3 | 83 |
| 5 | 4 | 317 |
| ... | ... | ... |
| 46 | 45 | 144 |
| 47 | 46 | 180 |
| 48 | 47 | 645 |
sheet.iloc[2:49, [0, 2]].values # pandas 形式を numpy 形式に変換する
array([[1, 64],
[2, 136],
[3, 83],
[4, 317],
[5, 87],
...,
[46, 180],
[47, 645]], dtype=object)
Excelのデータで日本地図に色を塗る
データの加工
values = sheet.iloc[2:49, [0, 2]].values
色の塗り方の指定
以下のコードは、
- 最大値は赤色
- 最大値の半分の値は黄色
- ゼロは青色
- データなしは白色
のカラーコードを出力します。
import numpy as np
def color_scale(value, max_value):
try:
v = value / max_value
if v >= 1.0:
return (255, 0, 0)
elif v <= 0:
return (0, 0, 255)
elif v > 0.5:
red = 1
green = int(255 * (2 - 2 * v))
blue = 0
return (red, green, blue)
else:
red = int(255 * 2 * v)
green = int(255 * 2 * v)
blue = int(255 * (1 - 2 * v))
return (red, green, blue)
except:
return (255, 255, 255)
使用例はこんな感じ。
for v in [0.0, 0.2, 0.5, 0.7, 1.0, "string"]:
print(v, color_scale(v, 1))
0.0 (0, 0, 255)
0.2 (102, 102, 153)
0.5 (255, 255, 0)
0.7 (1, 153, 0)
1.0 (255, 0, 0)
string (255, 255, 255)
最大値を求めます
max_value = np.max([a for a in values[:, 1] if not isinstance(a, str)])
都道府県ごとにカラーを決めます
data ={}
for code, value in zip(values[:, 0], values[:, 1]):
data[code] = color_scale(value, max_value)
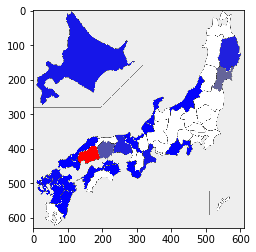
日本地図に色を塗ります
%matplotlib inline
import matplotlib.pyplot as plt
from pylab import rcParams
print(excel.sheet_names[sheet_index])
plt.imshow(picture(data))
人口密度 〔2018年〕

まとめ
別のデータで塗るとこんな感じ。データがない場所はしっかり白になってます。
sheet_index = 60
print(excel.sheet_names[sheet_index])
sheet = excel.parse(excel.sheet_names[sheet_index], header=None)
values = sheet.iloc[2:49, [0, 2]].values
max_value = np.max([a for a in values[:, 1] if not isinstance(a, str)])
data ={}
for code, value in zip(values[:, 0], values[:, 1]):
data[code] = color_scale(value, max_value)
plt.imshow(picture(data))
かきの養殖 〔2016年〕