PyTorch を Google Colaboratory 上で使って RankNet っぽいランキング学習を行なってみます。ランキング学習は、目的変数の値を直接使うことができず、その大小関係しか分からない場合に使える方法です(浅い理解)。今回は特別なライブラリを使うことなく PyTorch だけで実装します。
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device
'cuda'
テーブルデータで RankNet
ランキング学習は画像解析を題材とする例が多いと思いますが、ここでは簡単な MLP (Multi-Layer Perceptron) を使って、テーブルデータを取り扱いたいと思います。
class MLP(torch.nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(MLP, self).__init__()
self.l1 = torch.nn.Linear(n_input, n_hidden)
self.l2 = torch.nn.Linear(n_hidden, n_hidden)
self.l3 = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = torch.sigmoid(self.l1(x))
x = torch.sigmoid(self.l2(x))
return self.l3(x)
アヤメのデータ
まずは、みんな大好きアヤメのデータを使ってみます。
from sklearn.datasets import load_iris
dataset = load_iris()
dataset.data.shape, dataset.target.shape
((150, 4), (150,))
PairDataset と RankNet Loss
データセットの作り方と損失関数の定義がちょっと特殊で、ここがランキング学習の味噌となる部分です。
import numpy as np
from torch.utils.data import TensorDataset
class PairDataset(TensorDataset):
def __getitem__(self, i: int):
x1, t1 = super().__getitem__(i)
r = np.random.randint(len(self))
x2, t2 = super().__getitem__(r)
return x1, x2, (1.0 if t1 > t2 else 0.0 if t1 < t2 else 0.5)
def ranknet_loss(s1, s2, y):
o = torch.sigmoid(s1 - s2)
return (-y * o + torch.nn.functional.softplus(o)).mean()
トレーニングとテスト用の関数は次のようにしました。
def train(model, optimizer, dataloader):
model.train()
total_loss = 0
for i, (x1, x2, y) in enumerate(dataloader):
optimizer.zero_grad()
s1 = model(x1.to(device))
s2 = model(x2.to(device))
loss = ranknet_loss(s1, s2, y.to(device))
loss.backward()
optimizer.step()
total_loss += loss.detach().cpu().numpy()
return total_loss
def test(model, optimizer, dataloader):
model.eval()
with torch.no_grad():
total_loss = 0
for i, (x1, x2, y) in enumerate(dataloader):
s1 = model(x1.to(device))
s2 = model(x2.to(device))
loss = ranknet_loss(s1, s2, y.to(device))
total_loss += loss.detach().cpu().numpy()
return total_loss
学習の流れ
説明変数と目的変数をそれぞれ training データと test データに分割します。
import numpy as np
import torch
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
PairDataset を作り、データローダーにロードします。
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
各種パラメータを指定してモデルとオプティマイザを初期化します。
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = MLP(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
学習を実行し、ベストモデルを保存します。
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 26.47366, Test Loss: 27.33113
Epoch: 003, Train Loss: 27.00965, Test Loss: 27.33028
Epoch: 004, Train Loss: 26.37072, Test Loss: 27.10028
Epoch: 006, Train Loss: 27.23989, Test Loss: 26.96639
Epoch: 011, Train Loss: 26.43203, Test Loss: 26.65583
Epoch: 012, Train Loss: 25.93402, Test Loss: 26.34778
Epoch: 014, Train Loss: 26.12102, Test Loss: 25.95435
Epoch: 029, Train Loss: 26.86516, Test Loss: 24.66878
Epoch: 042, Train Loss: 26.04172, Test Loss: 24.60587
Epoch: 057, Train Loss: 25.97948, Test Loss: 24.50113
Epoch: 058, Train Loss: 24.88898, Test Loss: 24.14320
Epoch: 081, Train Loss: 25.98607, Test Loss: 23.95453
Epoch: 094, Train Loss: 26.53609, Test Loss: 23.57657
Epoch: 121, Train Loss: 25.08349, Test Loss: 23.33208
Epoch: 134, Train Loss: 26.19501, Test Loss: 22.89397
Epoch: 167, Train Loss: 24.52558, Test Loss: 22.86631
Epoch: 364, Train Loss: 25.65985, Test Loss: 22.48119
学習曲線は次のようになりました。
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()
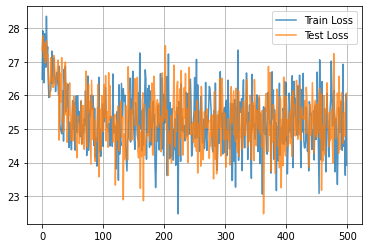
学習結果を、目的変数の真の値を横軸に、学習後モデルの出力を縦軸にしてプロットすると、次のようになりました。
plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data, dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()
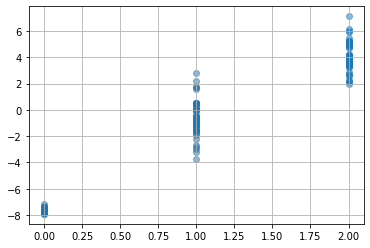
目的変数の直接の値を使わず(使えず)とも、その大小関係だけで、ある程度その関係を予測することができてますね。
乳がんデータセット
続いて、乳がんデータセットを使ってみます。データのロードは当然違いますが、それ以外のコードはアヤメのデータの場合と全く同じです。
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
dataset.data.shape, dataset.target.shape
((569, 30), (569,))
import numpy as np
import torch
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = MLP(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 102.23338, Test Loss: 101.55876
Epoch: 006, Train Loss: 100.61672, Test Loss: 101.11941
Epoch: 007, Train Loss: 100.32332, Test Loss: 100.47400
Epoch: 010, Train Loss: 98.51334, Test Loss: 99.43504
Epoch: 011, Train Loss: 99.60449, Test Loss: 99.14325
Epoch: 013, Train Loss: 98.10006, Test Loss: 98.64621
Epoch: 019, Train Loss: 98.51830, Test Loss: 98.57915
Epoch: 020, Train Loss: 96.72516, Test Loss: 98.33670
Epoch: 024, Train Loss: 98.17321, Test Loss: 95.34284
Epoch: 231, Train Loss: 96.64361, Test Loss: 94.84193
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()
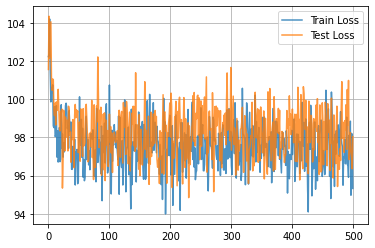
plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data, dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()

うーん、このデータを分けるのはうまくできなかったようですね...
ワインのデータセット
続いて、ワインのデータセットを使ってみます。データのロードは当然違いますが、それ以外のコードはアヤメのデータの場合と全く同じです。
from sklearn.datasets import load_wine
dataset = load_wine()
dataset.data.shape, dataset.target.shape
((178, 13), (178,))
import numpy as np
import torch
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = MLP(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 32.58194, Test Loss: 32.32423
Epoch: 002, Train Loss: 32.95397, Test Loss: 31.06405
Epoch: 038, Train Loss: 32.52927, Test Loss: 30.69924
Epoch: 064, Train Loss: 30.65910, Test Loss: 30.47935
Epoch: 065, Train Loss: 32.68333, Test Loss: 30.39005
Epoch: 066, Train Loss: 30.26714, Test Loss: 30.36727
Epoch: 082, Train Loss: 31.53777, Test Loss: 30.14709
Epoch: 093, Train Loss: 32.01807, Test Loss: 29.75395
Epoch: 103, Train Loss: 30.51099, Test Loss: 29.71479
Epoch: 120, Train Loss: 31.44133, Test Loss: 29.36976
Epoch: 217, Train Loss: 30.65907, Test Loss: 28.96202
Epoch: 277, Train Loss: 30.11092, Test Loss: 28.76284
Epoch: 308, Train Loss: 28.00539, Test Loss: 28.65389
Epoch: 318, Train Loss: 29.95649, Test Loss: 28.52343
Epoch: 362, Train Loss: 31.02163, Test Loss: 27.83746
Epoch: 388, Train Loss: 31.11847, Test Loss: 27.54669
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()

plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data, dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()
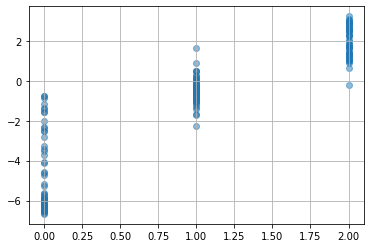
ある程度は分けれたけど、まだまだ...。
手書き文字データセット
続いて、手書き文字データセットを使ってみます。データのロードは当然違いますが、それ以外のコードはアヤメのデータの場合と全く同じです。
from sklearn.datasets import load_digits
dataset = load_digits()
dataset.data.shape, dataset.target.shape
((1797, 64), (1797,))
import numpy as np
import torch
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = MLP(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 324.22680, Test Loss: 327.35557
Epoch: 002, Train Loss: 324.07453, Test Loss: 321.37264
Epoch: 003, Train Loss: 316.69756, Test Loss: 315.82363
Epoch: 004, Train Loss: 316.71192, Test Loss: 315.54580
Epoch: 005, Train Loss: 314.77777, Test Loss: 313.96614
Epoch: 006, Train Loss: 304.91621, Test Loss: 311.26495
Epoch: 009, Train Loss: 305.59595, Test Loss: 307.55472
Epoch: 010, Train Loss: 309.46713, Test Loss: 305.55599
Epoch: 011, Train Loss: 311.31422, Test Loss: 304.97257
Epoch: 012, Train Loss: 305.45961, Test Loss: 302.45935
Epoch: 018, Train Loss: 299.30367, Test Loss: 301.39967
Epoch: 019, Train Loss: 300.33058, Test Loss: 300.50853
Epoch: 022, Train Loss: 294.72060, Test Loss: 293.95089
Epoch: 042, Train Loss: 294.06268, Test Loss: 293.68401
Epoch: 047, Train Loss: 296.32044, Test Loss: 291.73970
Epoch: 050, Train Loss: 296.64509, Test Loss: 289.41437
Epoch: 051, Train Loss: 299.19273, Test Loss: 288.82378
Epoch: 069, Train Loss: 295.12235, Test Loss: 288.74877
Epoch: 094, Train Loss: 291.28113, Test Loss: 288.16852
Epoch: 095, Train Loss: 297.59466, Test Loss: 286.67425
Epoch: 131, Train Loss: 291.30947, Test Loss: 285.94876
Epoch: 270, Train Loss: 285.84894, Test Loss: 285.90531
Epoch: 277, Train Loss: 286.35726, Test Loss: 285.56720
Epoch: 282, Train Loss: 292.25496, Test Loss: 282.57644
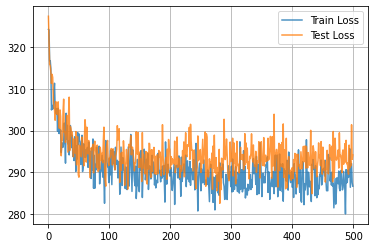
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()
plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data, dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()
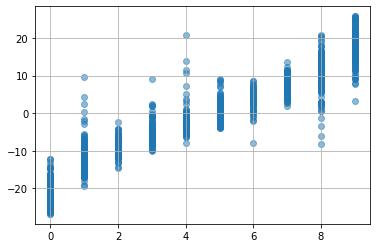
目的変数の大小関係が、なんとなく分かれてますね(まだまだ改善の余地ありそうですが...)。
この手書き文字は画像データなので、 CNN を使ってみましょう。こんな感じで。
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv_layers = torch.nn.Sequential(
torch.nn.Conv2d(in_channels = 1, out_channels = 16, kernel_size = 2, stride=1, padding=0),
torch.nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 2, stride=1, padding=0),
)
self.dence = torch.nn.Sequential(
torch.nn.Linear(32 * 6 * 6, 128),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(128, 64),
torch.nn.Sigmoid(),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(64, 1),
)
def forward(self,x):
x = self.conv_layers(x)
x = x.view(x.size(0), -1)
x = self.dence(x)
return x
def check_cnn_size(self, size_check):
out = self.conv_layers(size_check)
return out
model = CNN().to(device)
import numpy as np
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :].reshape(-1, 1, 8, 8), dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :].reshape(-1, 1, 8, 8), dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = CNN().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 324.00428, Test Loss: 327.52363
Epoch: 002, Train Loss: 320.58252, Test Loss: 317.33973
Epoch: 003, Train Loss: 314.04230, Test Loss: 309.33507
Epoch: 005, Train Loss: 303.88695, Test Loss: 307.33255
Epoch: 006, Train Loss: 306.97226, Test Loss: 303.32797
Epoch: 012, Train Loss: 299.62310, Test Loss: 300.88313
Epoch: 013, Train Loss: 299.50133, Test Loss: 297.45900
Epoch: 021, Train Loss: 301.00256, Test Loss: 294.34406
Epoch: 023, Train Loss: 298.81884, Test Loss: 293.57468
Epoch: 037, Train Loss: 293.86147, Test Loss: 293.45324
Epoch: 052, Train Loss: 293.71391, Test Loss: 291.58396
Epoch: 069, Train Loss: 291.77022, Test Loss: 290.49314
Epoch: 075, Train Loss: 288.71287, Test Loss: 289.32459
Epoch: 086, Train Loss: 285.77597, Test Loss: 285.26845
Epoch: 183, Train Loss: 295.70264, Test Loss: 283.19464
Epoch: 394, Train Loss: 288.65467, Test Loss: 282.65600
Epoch: 456, Train Loss: 289.18865, Test Loss: 281.49259
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()

plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data.reshape(-1, 1, 8, 8), dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()
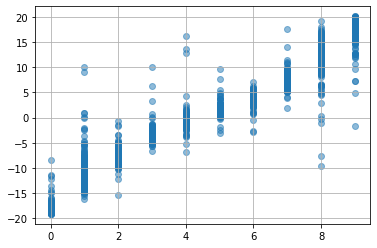
ちょっとは良くなった...のか? 微妙w
糖尿病データセット
最後に、糖尿病データセットです。今までは目的変数が離散値、つまり分類問題を取り扱ってきましたが、全く同じコードで回帰問題(目的変数が連続値)を取り扱うことができます。
from sklearn.datasets import load_diabetes
dataset = load_diabetes()
dataset.data.shape, dataset.target.shape
((442, 10), (442,))
import numpy as np
import torch
index = np.arange(dataset.target.size)
train_index = index[index % 2 != 0]
test_index = index[index % 2 == 0]
X_train = torch.tensor(dataset.data[train_index, :], dtype=torch.float)
Y_train = torch.tensor(dataset.target[train_index], dtype=torch.float)
X_test = torch.tensor(dataset.data[test_index, :], dtype=torch.float)
Y_test = torch.tensor(dataset.target[test_index], dtype=torch.float)
from torch.utils.data import DataLoader
D_train = PairDataset(X_train, Y_train)
D_test = PairDataset(X_test, Y_test)
batch_size = 2
D_train = DataLoader(PairDataset(X_train, Y_train), batch_size=batch_size, shuffle=True)
D_test = DataLoader(PairDataset(X_test, Y_test), batch_size=batch_size, shuffle=True)
epochs = 500
n_hidden = 64
n_output = 1
lr = 1e-4
model = MLP(X_train.shape[1], n_hidden, n_output).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
import copy
train_hist = []
test_hist = []
best_score = None
for epoch in range(1, epochs + 1):
train_loss = train(model, optimizer, D_train)
test_loss = test(model, optimizer, D_test)
train_hist.append(train_loss)
test_hist.append(test_loss)
if best_score is None or best_score > test_loss:
best_score = test_loss
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch:03d}, Train Loss: {train_loss:.5f}, Test Loss: {test_loss:.5f}')
Epoch: 001, Train Loss: 80.24731, Test Loss: 81.86786
Epoch: 002, Train Loss: 81.11598, Test Loss: 81.73393
Epoch: 003, Train Loss: 80.48554, Test Loss: 81.47450
Epoch: 005, Train Loss: 81.34048, Test Loss: 76.09816
Epoch: 039, Train Loss: 78.01942, Test Loss: 75.31030
Epoch: 046, Train Loss: 80.24249, Test Loss: 75.22265
Epoch: 054, Train Loss: 77.77754, Test Loss: 74.25989
Epoch: 057, Train Loss: 77.72677, Test Loss: 73.24117
Epoch: 059, Train Loss: 78.10728, Test Loss: 72.91239
Epoch: 143, Train Loss: 74.59952, Test Loss: 72.23986
Epoch: 205, Train Loss: 78.24532, Test Loss: 71.60373
Epoch: 209, Train Loss: 77.72721, Test Loss: 71.60078
Epoch: 248, Train Loss: 77.51718, Test Loss: 70.69653
import matplotlib.pyplot as plt
plt.plot(train_hist, alpha=0.8, label="Train Loss")
plt.plot(test_hist, alpha=0.8, label="Test Loss")
plt.grid()
plt.legend()
plt.show()

plt.scatter(dataset.target,
best_model(torch.tensor(dataset.data, dtype=torch.float).to(device)).detach().cpu().numpy(),
alpha=0.5)
plt.grid()
plt.show()
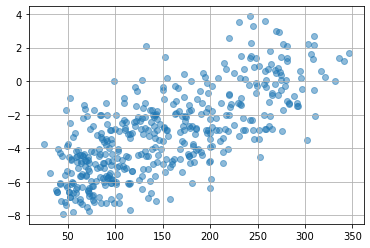
真の目的変数と、予測された目的変数との間に相関関係がありそうな結果になりました。がっちりとした予測ができたわけではありませんが、大小関係しか学習に使わない(使えない)という制約条件の中では、こんなもんでOKといったところでしょうか。