深層学習を用いた自然言語処理の入門として、BoW (Bag-of-Words) モデルをPyTorch で実装します。
練習用データ
UCI の Machine-Learning Repository の SMS Spam Collection データセットを使います。与えられた文章から、それがスパムかどうかを判定する問題です。
import os
import requests
from zipfile import ZipFile
import io
import csv
save_file_name = os.path.join("temp", "temp_spam_data.csv")
# もしも元データがなければダウンロードする
if not os.path.exists("temp"):
os.makedirs("temp")
if not os.path.isfile(save_file_name):
zip_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip"
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read("SMSSpamCollection")
text_data = file.decode()
text_data = text_data.encode('ascii', errors='ignore')
text_data = text_data.decode().split("\n")
text_data = [x.split("\t") for x in text_data if len(x) > 1]
with open(save_file_name, "w") as temp_output_file:
writer = csv.writer(temp_output_file)
writer.writerows(text_data)
# もし元データがあればそれを読み込む
else:
text_data = []
with open(save_file_name, "r") as temp_output_file:
reader = csv.reader(temp_output_file)
for row in reader:
text_data.append(row)
texts = [x[1] for x in text_data]
target = [x[0] for x in text_data]
説明変数であるテキスト(文章)は、こんな感じ。
texts[:10]
['Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...',
'Ok lar... Joking wif u oni...',
"Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's",
'U dun say so early hor... U c already then say...',
"Nah I don't think he goes to usf, he lives around here though",
"FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, 1.50 to rcv",
'Even my brother is not like to speak with me. They treat me like aids patent.',
"As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune",
'WINNER!! As a valued network customer you have been selected to receivea 900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.',
'Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030']
目的変数は、スパムか、スパムじゃないかという2値分類です。
target[:10]
['ham', 'ham', 'spam', 'ham', 'ham', 'spam', 'ham', 'ham', 'spam', 'spam']
テキスト(文章)の個数は
len(target)
5574
そのうち、スパムの数は
sum([1 for x in target if x == 'spam' ])
747
ということで、偏ったデータになります。
データの前処理
語彙の最終的なサイズを減らすために、テキストを正規化します。具体的には、テキストの大文字小文字の区別をなくしたり、数字を除いたり、余分なスペースを除いたり、句読点を除いたりします。
# 小文字に変換
texts = [x.lower() for x in texts]
# 数字を削除
texts = ["".join(c for c in x if c not in '0123456789') for x in texts]
# 余分なホワイトスペースを除去
texts = [" ".join(x.split()) for x in texts]
import string
# 句読点を削除
texts = ["".join(c for c in x if c not in string.punctuation) for x in texts]
文の最大長も決定します。そのために、テキストの長さの分布を調べます。
import matplotlib.pyplot as plt
# テキストの長さをヒストグラムとしてプロット
text_lengths = [len(x.split()) for x in texts]
text_lengths = [x for x in text_lengths]
plt.hist(text_lengths, bins=100)
plt.show()
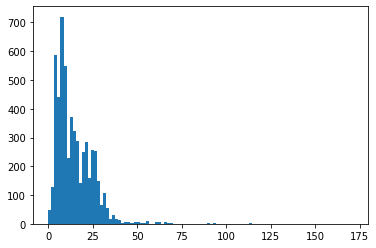
ここでは、1つの文あたりの単語数を 25 とし、3 回以上出現しない単語も取り除きます。
sentence_size = 25
min_word_freq = 3
そのためのクラス VocabularyProcessor を作りました。
class VocabularyProcessor:
def __init__(self, sentence_size, min_frequency=3):
self.sentence_size = sentence_size
self.min_frequency = min_frequency
self.freq = {}
self.vocabulary_ = []
self.vocab = {}
def fit_transform(self, texts):
freq = {}
for sentence in texts:
for word in sentence.split():
if word not in freq.keys():
freq[word] = 0
freq[word] += 1
for k, v in freq.items():
if v >= self.min_frequency:
self.freq[k] = v
self.vocabulary_ = self.freq.keys()
transformed_texts = []
for sentence in texts:
transformed_sentence = []
for word in sentence.split():
if word in self.freq.keys():
if word not in self.vocab:
self.vocab[word] = len(self.vocab)
transformed_sentence.append(word)
if len(transformed_sentence) >= self.sentence_size:
break
transformed_sentence = " ".join(transformed_sentence)
transformed_texts.append(transformed_sentence)
return transformed_texts
次のようにして、前処理します。
vocab_processor = VocabularyProcessor(sentence_size, min_frequency=min_word_freq)
texts = vocab_processor.fit_transform(texts)
データ分割
データをトレーニングセットとテストセットに分割します。
import numpy as np
train_indices = np.random.choice(len(texts), round(len(texts) * 0.8))
test_indices = np.array(list(set(range(len(texts))) - set(train_indices)))
texts_train = [x for ix, x in enumerate(texts) if ix in train_indices]
texts_test = [x for ix, x in enumerate(texts) if ix in test_indices]
target_train = [x for ix, x in enumerate(target) if ix in train_indices]
target_test = [x for ix, x in enumerate(target) if ix in test_indices]
説明変数と目的変数をまとめます
train_data = [(x, y) for x, y in zip(texts_train, target_train)]
test_data = [(x, y) for x, y in zip(texts_test, target_test)]
BoW 分類モデル
import torch
class BoWClassifier(torch.nn.Module):
def __init__(self, num_labels, vocab_size):
super(BoWClassifier, self).__init__()
self.linear = torch.nn.Linear(vocab_size, num_labels)
def forward(self, vec):
return self.linear(vec)
文をBoWベクトルに変換する関数
def make_bow_vector(sentence, vocab):
vec = torch.zeros(len(vocab))
for word in sentence.split():
vec[vocab[word]] += 1
return vec.view(1, -1)
ラベルを数字に変換する関数
def make_target(label, labels):
return torch.LongTensor([labels[label]])
学習
ボキャブラリーとラベルの設定をします。
vocab = vocab_processor.vocab
VOCAB_SIZE = len(vocab)
NUM_LABELS = 2
labels = {"ham": 0, "spam": 1}
分類モデル、損失関数、最適化手法の設定をします。
model = BoWClassifier(NUM_LABELS, VOCAB_SIZE)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
学習を開始します。
loss_history = []
for epoch in range(100):
total_loss = 0
for data, label in train_data:
model.zero_grad()
bow_vec = torch.autograd.Variable(make_bow_vector(data, vocab))
target = torch.autograd.Variable(make_target(label, labels))
output = model(bow_vec)
loss = loss_function(output, target)
total_loss += loss.detach().numpy()
loss.backward()
optimizer.step()
loss_history.append(total_loss)
結果
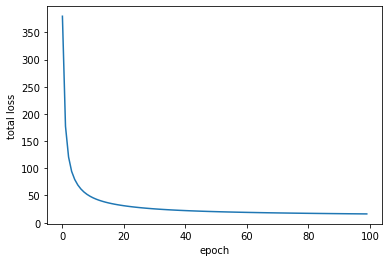
学習曲線は次のようになりました。
import matplotlib.pyplot as plt
plt.plot(loss_history)
plt.xlabel("epoch")
plt.ylabel("total loss")
plt.show()
学習に用いなかったデータの予測を行います
TP = 0
FN = 0
FP = 0
TN = 0
for data, label in test_data:
bow_vec = torch.autograd.Variable(make_bow_vector(data, vocab))
output = torch.argmax(model(bow_vec)).detach().numpy()
if labels[label] == 1: #positive
if output == 1:
TP += 1
else:
FN += 1
else: # negative
if output == 1:
FP += 1
else:
TN += 1
TP, FN, FP, TN
(299, 38, 8, 2201)
正解率は次のようになりました。
accuracy = (TP + TN) / (TP + FN + FP + TN)
accuracy
0.9819324430479183