0. はじめに
VectorStoreを用いた質問応答モデルは、生成AIの分野で急速に進化しています。langchain ライブラリの ConversationalRetrievalChainはシンプルな質問応答モデルの実装を実現する方法の一つです。この記事では、その使い方と実装の詳細について解説します。
1. ConversationalRetrievalChainの概念
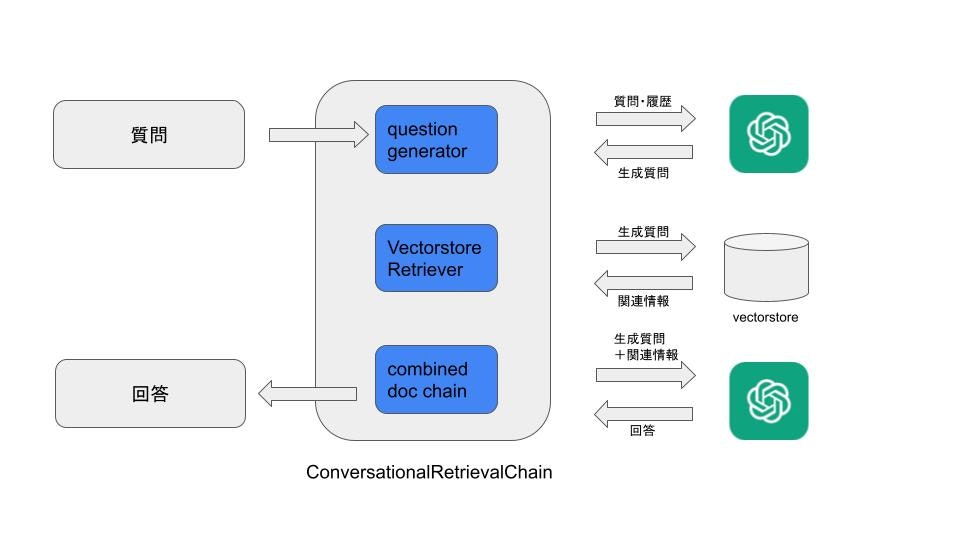
- ConversationalRetrievalChainでは、まずLLMが質問と会話履歴を受け取って、質問の言い換え(生成質問)を行います。
- 次に、言い換えられた質問をもとにVectorStoreに関連情報(チャンク群)を探しに行きます。
- 生成質問にVectorStoreからの関連情報を合わせて、再度LLMに問い合わせ、最終的な回答を得ます。
このような一連の操作がこのモジュールの中で行われています。会話履歴をもとに質問の言い換えを行うため、質問者との会話のラリーがある程度スムースにできることになります。テクニカルにはトークン数の制限などで、ラリーの回数が制限されますが、実用上は2、3回のラリーに耐えられれば、まあそんなに違和感なく使えるのかな、というところです。
2. VectorStore Retrieverの用意
OpenAIEmbeddingsを使用して、VectorStore (今回はChroma DB)をロードします。
loaded_db = Chroma(
persist_directory='testdb',
embedding_function=OpenAIEmbeddings()
)
3. ChatOpenAIモデルの設定
今回使うLLMも定義しておきます。
# ChatOpenAIモデルの設定
LLM = ChatOpenAI(
model_name='gpt-3.5-turbo',
temperature=0
)
4. PromptTemplateの作成
質問応答のためのプロンプトテンプレートを作成します。上記の概念図から分かるように、Conversational RetrievalChain内では2回LLMにクエリを投げることになるので、プロンプトも2種類用意する必要があります。
最初のQuestion generatorの部分に関しては、デフォルトではCONDENSE_QUESTION_PROMPTが使われますが、もちろん書き換えてもOKです。ちなみにCONDENSE_QUESTION_PROMPTを日本語で書くとこんな感じです。
template_qg = """
次の会話に対しフォローアップの質問があるので、フォローアップの質問を独立した質問に言い換えなさい。
チャットの履歴:
{chat_history}
フォローアップの質問:
{question}
言い換えられた独立した質問:"""
prompt_qg = PromptTemplate(
template=template_qg,
input_variables=["chat_history", "question"],
output_parser=None,
partial_variables={},
template_format='f-string',
validate_template=True,
)
そして、最終のcombined document chainに使う方のプロンプトはこんな感じです。
prompt_template_qa = """You are a helpful assistant. Please answer in Japanese! If the context is not relevant, please answer the question by using your own knowledge about the topic.
{context}
Question: {question}
Answer in Japanese:"""
prompt_qa = PromptTemplate(
template=prompt_template_qa,
input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": prompt_qa}
5. ConversationalRetrievalChainの初期化
プロンプトが完成したら、Question Generation, VectorStore Retrieval, Combined document Chainを全てConversational RetrievalChainに入れ込みます。chain_typeにstuffを使っていますが、他のchain_type (refine, map_reduceなど)でもOKです。stuffはトークン数はかさみますが、他のchain_typeよりも圧倒的に早いです。トークン数が増えれば増えるほど顕著です。
retriever = loaded_db.as_retriever()
question_generator = LLMChain(llm=LLM, prompt=prompt_qg)
doc_chain = load_qa_chain(llm=LLM, chain_type="stuff", prompt=prompt_qa)
qa = ConversationalRetrievalChain(
retriever=retriever,
question_generator=question_generator,
combine_docs_chain=doc_chain,
)
chat_history = []
6. 質問の処理
作成したConversationalRetrievalChainを使用して、質問のリストを処理します。
questions = [
'○○社にはどのようなDX支援サービスがありますか',
...
]
for query in questions:
print(f"Q: {query}")
result = qa.run({"question": query, "chat_history": chat_history})
print(f"A: {result}")
chat_history.append((query, result))
7. まとめ
ConversationalRetrievalChainは、質問応答モデルの構築に非常に役立つツールです。このブログを通じて、その使い方と実装の詳細を理解できたことを願っています。
最後にインポートが必要なライブラリのリストです。
import os
import openai
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.chains import ConversationalRetrievalChain
from langchain.chains.question_answering import load_qa_chain
from langchain.chains.conversational_retrieval.prompts import CONDENSE_QUESTION_PROMPT
*本記事はcode snippetをもとにChatGPTに作らせています。