はじめに
こんにちは!今回は、データサイエンスのコンペティションプラットフォーム「SIGNATE」で取り組んだ「Quest: 食品ロスの削減」と【練習問題】お弁当の需要予測についてお話しします。実務的なテーマに挑戦するQuestの課題と、基礎スキルを磨くための練習問題の両方に取り組むことで、それぞれの強みを活かした学びを得られました。この記事では、課題を通じて得た経験や気づきを共有します!
Quest: 食品ロスの削減とは?
「Quest: 食品ロスの削減」は、食品ロス削減を目指す実務に近い課題です。販売データを基にして需要を予測し、無駄な在庫を減らす方法を考えるという、データサイエンスの社会的な活用を学べる魅力的なテーマです。
提供されるデータは次のような詳細情報を含んでおり、分析の自由度が高い点が特徴です:
- 販売数量と関連する特徴量
- 天気や季節などの外部条件
- 商品ごとの販売履歴
この課題では、需要予測の基本を押さえつつ、実務的な意思決定に繋がるデータ分析力を求められます。
取り組みの流れ
-
データの理解
販売履歴データを観察し、天気や曜日、商品の特徴がどのように需要に影響するかを分析しました。これには、PandasやSeabornを使った可視化が役立ちました。 -
データ前処理
欠損値補完やカテゴリ変数のエンコーディングを実施。
天気や季節データを新しい特徴量として追加。
# 先頭行のみを抽出
tmp = train.head()
# isnull関数を使って変数tmpの欠損値有無を確認
print( tmp.isnull() )
# 欠損値の有無、True or False
judge = tmp.isnull().any().any()
-
モデル構築
初めは線形回帰でベースラインモデルを作成し、その後XGBoostやランダムフォレストを試して精度向上を図りました。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(train_X, train_y)
-
予測結果の評価
RMSE(Root Mean Squared Error)を指標に、予測精度を比較。さらに、具体的なビジネスインパクトを考えながら結果を分析しました。
from sklearn.metrics import mean_squared_error, r2_score
predictions = model.predict(test_X)
print("R^2 Score:", r2_score(test_y, predictions))
print("RMSE:", mean_squared_error(test_y, predictions, squared=False))
# 評価データの販売数は、変数test_yに代入されています。
# 販売数の予測値は、変数pred1に代入されています。
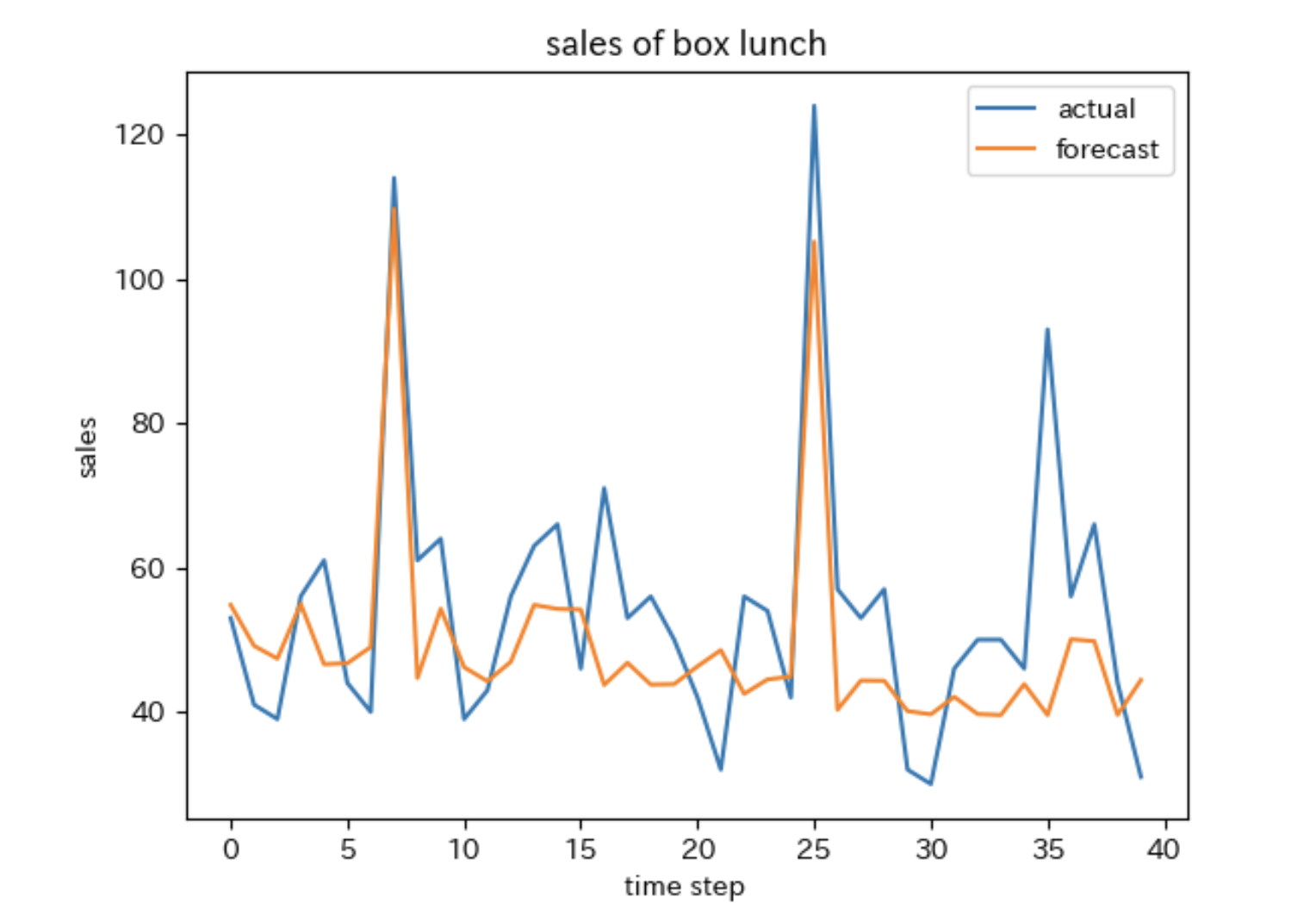
# 折れ線グラフを描画します。
# 評価データの販売数でグラフを描く
plt.plot(test_y.values, label="actual")
# 予測値でグラフを描く
plt.plot(pred1, label="forecast")
plt.title("sales of box lunch")
plt.xlabel("time step")
plt.ylabel("sales")
plt.legend()
plt.show()
【練習問題】お弁当の需要予測で基礎を学ぶ
Questに挑戦する前に取り組んだのが【練習問題】お弁当の需要予測です。この課題は、データサイエンス初心者が基礎を学ぶのに最適で、需要予測の基本的な流れを体験できます。
課題の内容
この課題では、お弁当の販売データを基にして、曜日や天気、気温などから販売数を予測します。データはシンプルですが、基本的なデータ処理やモデル構築の流れを身につけるのに役立ちました。
学んだこと
-
データの理解
曜日ごとの販売傾向や天気の影響を可視化し、需要に影響を与える要因を特定。 -
データ前処理
欠損値を補完し、曜日や天気などのカテゴリ変数をエンコーディング。気温データをスケーリングしてモデルに適した形に整えました。 -
モデル構築
- 線形回帰:基礎的なモデルで初回スコアを確認。
- XGBoost:高精度なモデルで、パフォーマンスを向上。
【練習問題】を通じて得たスキルは、Quest: 食品ロスの削減での応用に直結しました。
Questと練習問題から得た学び
-
データ分析の基礎から応用まで学べる
【練習問題】で学んだデータの扱い方やモデル構築の基礎が、Questの実務的な課題に挑戦する際に大きな助けとなりました。基礎を固めた上で応用的な課題に取り組むことで、スキルを段階的に伸ばせました。 -
実務に近い経験が得られる
Questの課題では、単なるモデルの精度向上だけでなく、食品ロス削減という具体的なビジネス課題に対するインサイトを考える必要がありました。このプロセスを通じて、実務で求められる視点を養うことができました。 -
試行錯誤の楽しさ
モデルの調整や特徴量エンジニアリングを繰り返す中で、スコアが少しずつ改善していく喜びを感じました。課題を深く掘り下げることの面白さを実感しました。
まとめ
SIGNATEで【練習問題】お弁当の需要予測に取り組むことで、データサイエンスの基礎を固めることができました。その経験を活かして、Quest: 食品ロスの削減のような応用課題にも挑戦でき、スキルの幅を広げることができました。
初心者の方は、まずQuestで基本的な流れを学び、次に【練習問題】のような実務に近い課題に挑戦するステップをおすすめします。この流れは、効率的にデータ分析スキルを習得できる方法だと感じています。
この記事が、SIGNATEで挑戦を始める方の参考になれば嬉しいです!