あるライブラリのバインディングを作成するにあたって、
FFI、hsc2hs、inline-cの基本的な使い方をまとめ、その選定基準を調べてみました。
FFI、hsc2hsの使い方については、RWHにもっと網羅的に書かれていましたので、学習用途ではそちらを参照されたほうがよろしいかと思います。この記事は、使う時にさっと確認するという意図で書かれています。
ちなみに、筆者の環境ですが、OSはWindowsです。MinGWを使いました。
間違いの指摘などあれば、コメント頂けると嬉しいです。
1 FFIでCの関数を利用
まず、C言語で単純な関数を用意します。
int plus(int a)
{
return a + 1;
}
int minus(int a)
{
return a - 1;
}
これを利用するコードをHaskellで書きます。
module Main where
import Foreign.C.Types
foreign import ccall "plus" c_plus :: CInt -> IO CInt
foreign import ccall "minus" c_minus :: CInt -> IO CInt
plus :: Int -> IO Int
plus = fmap fromIntegral . c_plus . fromIntegral
minus :: Int -> IO Int
minus = fmap fromIntegral . c_minus . fromIntegral
main :: IO ()
main = do
print =<< plus 5
print =<< minus 5
実行ファイル作成
まずは愚直にやってみます。
.cファイルをコンパイルして、.oファイルを作成。
それをHaskellのファイルとまとめてコンパイルします。
gcc -c plus.c // plus.oが生成される
gcc -c minus.c // minus.oが生成される
ghc main.hs plus.o minus.o // main.exeが生成される
実行する。
$ main
6
4
想定どおりの動作です。
ライブラリを作成
Cのソースは、まとめてライブラリにしておいた方が都合がよいことがあります。
ということで、Cのライブラリを作成してからリンクする方法を示します。
最初に流れを図示しておきます。
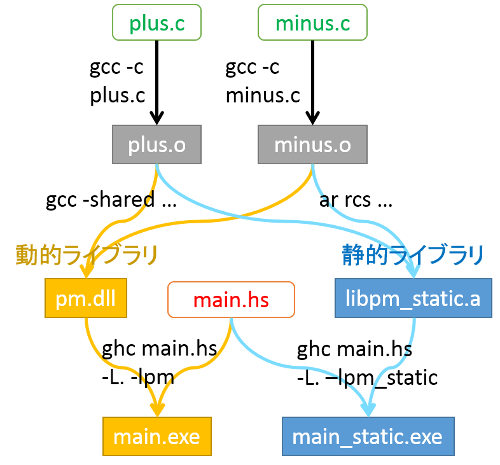
1.1 静的ライブラリ
まずは静的なライブラリを作成します。
先ほど作成しておいた.oファイルから、libpm_static.aという名前のライブラリを作成します。
ar rcs libpm_static.a plus.o minus.o
コンパイルします。
-L.で現在のディレクトリからライブラリを探すようにして、
-lpm_staticでライブラリを指定する。
-l名前で、"lib名前.a"というライブラリが読み込まれます。
ghc main.hs -L. -lpm_static
以下のように、直接指定しても大丈夫です。
ghc main.hs libpm_static.a
1.2 動的ライブラリ
次に動的ライブラリDLLを作成します。
.oファイルから-sharedオプションでDLLを作成します。
gcc -shared -o pm.dll plus.o minus.o // DLL(pm.dll)が作成される
そしてコンパイル。
ghc main.hs -L. -lpm
この方法で作成された実行ファイルは、pm.dllを動的にリンクするので、pm.dllが無いと動作しません。
2.hsc2hsで定数や構造体とやり取りする
関数とやり取りする方法は分かりました。
今度は、hsc2hsというツールの力を借りて、
Cの定数や構造体とやり取りします。
2.1.定数
2.1.1.#const(1つ)
単純な例として、定数1をHaskell側に取り込むということをやってみます。
# define ONE 1
module Main where
import Foreign.C.Types
# include "foo.h"
myone :: CInt
myone = #const ONE
main :: IO ()
main = print myone
hsc2hsを使って、#const ONEの部分を置き換えます。
これで、main.hsが生成されます。
$ hsc2hs main.hsc
main.hsの中身を見ると、#const ONEの部分が、Cで定義されていた1に変換されています。
myone :: CInt
myone = 1
あとは、このソースをコンパイルするだけです。
$ ghc main.hs
$ main
1
2.1.2.#enum(複数)
enumを使えば、複数の定数を取り込みを自動化できます。
# define ONE 1
# define TWO 2
# define THREE 3
enumは以下のように指定します。
#enum 型, 構築子, 値, 値, ...
module Main where
# include "foo.h"
data Number = N Int
# {enum Number, N
, mnOne = ONE
, mnTwo = TWO
, mnThree = THREE
}
main = mapM_ print [mnOne, mnTwo, mnThree]
すると、このように変換されます。
mnOne :: Number
mnOne = N 1
mnTwo :: Number
mnTwo = N 2
mnThree :: Number
mnThree = N 3
$ hsc2hs main.hsc
$ ghc main.hs
$ main
N 1
N 2
N 3
ということは、そのままIntで欲しいならば、
型をIntにして、構築子を空にしておけばよいのですね。
module Main where
# include "foo.h"
# {enum Int,
, mnOne = ONE
, mnTwo = TWO
, mnThree = THREE
}
main = mapM_ print [mnOne, mnTwo, mnThree]
変換します。
$ hsc2hs main.hsc
そのままIntで得られました。
mnOne :: Int
mnOne = 1
mnTwo :: Int
mnTwo = 2
mnThree :: Int
mnThree = 3
2.2.構造体
構造体とのやり取りには、ポインターを使います。
構造体の作成
まず、C言語側で二次元ベクトルの構造体CVectを作ります。
参考のため、無駄に文字列を持たせています。
typedef struct {
int x;
int y;
char *label;
} CVect;
操作する関数の実装
# include "CVect.h"
# include <stdio.h>
// CVectを表示する
void printCVect(CVect *v) {
printf("CVect: %d %d '%s'\n", v->x, v->y, v->label);
}
// CVectのメンバをインクリメントするだけ
void add(CVect *a) {
a->x++;
a->y++;
}
Haskell側で利用できるようにする
この構造体CVectをHaskell側で扱えるようにします。
Cから直接構造体を読み取ったり、Cへ直接渡したりすることはできませんが、
メモリを通してやり取りするような仕組みが提供されています。
データ型Vectを作り、これをStorable型にすると、ポインタを通して読み書きできるになります。
Cの構造体CVectと、HaskellのデータVectをマーシャリングできるようにします。
peekで読み、pokeで書き込みます。その際、型を合わせる必要があります。これが間違っていても、コンパイラは何も教えてくれませんので、注意してコーディングします。
pokeで書き込む時には、IntからCIntを、StringからCStringを作ります。注意すべきことは、CStringの実体は、Ptr Charなので、メモリ管理に気をつけることです。ですので、Vect型に直接CStringを持たせた場合、メモリリークのほのかな香りが感じられて怖いです。
ちなみに、私はまだalignmentについてあまり理解しておりませんので、そこらへんが怪しいです。
色々とネット上で調べてみると、alignment _ = undefined的な感じになっているソースが多いので、それでもよいのでしょうか。。
module Vect where
import Foreign.C.Types
import Foreign.C.String (withCString, peekCString)
import Foreign.Ptr (Ptr)
import Foreign.Marshal.Utils (with)
import Foreign.Storable
import Control.Applicative ((<$>), (<*>))
# include "CVect.h"
-- alignmentのためのマクロ
-- ただし#letはクロスコンパイル未対応なので気をつける
# let alignment t = "%lu", (unsigned long)offsetof(struct {char x__; t (y__); }, y__)
data Vect = Vect
{ x :: Int
, y :: Int
, label :: String
} deriving Show
instance Storable Vect where
sizeOf _ = #{size CVect}
alignment _ = #{alignment CVect}
peek ptr = Vect <$> (toInt <$> #{peek CVect, x} ptr)
<*> (toInt <$> #{peek CVect, y} ptr)
<*> (peekCString =<< #{peek CVect, label} ptr)
where
toInt :: CInt -> Int
toInt = fromIntegral
poke ptr (Vect x y label) = do
#{poke CVect, x} ptr x'
#{poke CVect, y} ptr y'
withCString label $ \cstr ->
#{poke CVect, label} ptr cstr
where
x' = fromIntegral x :: CInt
y' = fromIntegral y :: CInt
foreign import ccall "printCVect" c_printCVect :: Ptr Vect -> IO ()
foreign import ccall "add" c_add :: Ptr Vect -> IO ()
printVect :: Vect -> IO ()
printVect vect = with vect c_printCVect
add :: Vect -> IO Vect
add v = with v $ \p -> c_add p >> peek p
試してみる
実際に使ってみます。
import Vect
main :: IO ()
main = do
let a = Vect 1 10 "label"
print a
printVect a -- C言語側で表示
putStrLn "-- add --"
b <- add a
print b
printVect b -- C言語側で表示
コンパイルします。
$ gcc -c CVect.c // CVect.oを生成
$ hsc2hs Vect.hsc // Vect.hsc --> Vect.hs
$ ghc main.hs CVect.o
そして実行。
$ main
Vect {x = 1, y = 10, label = "label"}
CVect: 1 10 'label'
-- add --
Vect {x = 2, y = 11, label = "label"}
CVect: 2 11 'label'
3.inline-cを使ってインラインでCのコードを書く
inline-cでは、Haskellのコード中にCのコードを書くことができます。
詳しい使い方の例は、inline-c-nagを参考にして、とのことでしたが、ボリュームがそこそこあってつらかったので、構造体を利用する例を作っておきました。
3.1.exp・pure・block
関数を使うくらいだったらこんなに簡単に書けます。
{-# LANGUAGE QuasiQuotes #-}
{-# LANGUAGE TemplateHaskell #-}
import qualified Language.C.Inline as C
C.include "<stdio.h>"
C.include "<math.h>"
main :: IO ()
main = do
let x = 0.5 :: C.CDouble
print =<< [C.exp| double{ sin( $(double x) ) } |] -- CDouble -> IO CDouble
print [C.pure| double{ sin( $(double x) ) } |] -- CDouble -> CDouble
[C.block| void{
double ans = sin( $(double x) );
printf("cos(%.2f) = %f\n", $(double x), ans);
} |]
コンパイルはちょっと面倒ですが。
$ ghc -c Main.hs
$ gcc -c Main.c -o Main_c.o
$ ghc Main.o Main_c.o
実行します。
$ main
0.479425538604203
0.479425538604203
cos(0.50) = 0.479426
3.2.構造体とのやり取り
hsc2hsでやった時のように、データ型をStorableクラスのインスタンスにして、マーシャリングできるようにします。
さらに、それ用にContextを定義しておけば、Cのコードに埋め込めるようになります。
ただし、やはりポインタを通してですが。
構造体の定義
まずはメンバを1つだけ持つ単純な構造体Fooを定義し、
適当な関数を用意しました。
typedef struct {
int field;
} Foo;
void printFoo(Foo*);
void addFoo(Foo*);
# include "foo.h"
# include <stdio.h>
void printFoo(Foo *foo) {
printf("Foo: %d\n", foo->field);
}
void addFoo(Foo *foo) {
foo->field++;
}
対応するデータ型を準備
対応するデータ型Fooを作成し、Storableクラスのインスタンスにします。
例によって、.hscで書いておいて、hsc2hsで.hsに変換することを前提としています。
さらに、ここで一緒にContextも作成しています。
# let alignment t = "%lu", (unsigned long)offsetof(struct {char x__; t (y__); }, y__)
{-# LANGUAGE QuasiQuotes #-}
{-# LANGUAGE TemplateHaskell #-}
{-# LANGUAGE OverloadedStrings #-}
module Foo where
import Language.C.Inline
import Language.C.Inline.Context
import qualified Language.C.Types as C
import Control.Applicative ((<$>), (<*>))
import Foreign.Storable (Storable(..))
import Data.Monoid (mempty, (<>))
import qualified Data.Map as M
import qualified Language.Haskell.TH as TH
# include "foo.h"
include "foo.h"
data Foo = Foo {field :: CInt} deriving Show
instance Storable Foo where
sizeOf _ = #{size Foo}
alignment _ = #{alignment Foo}
peek ptr = Foo <$> (#{peek Foo, field} ptr)
poke ptr (Foo a) = #{poke Foo, field} ptr a
fooCtx :: Context
fooCtx = baseCtx <> ctx
where
ctx = mempty {ctxTypesTable = table}
table :: M.Map C.TypeSpecifier TH.TypeQ
table = M.singleton (C.TypeName "Foo") [t| Foo |]
実際にCコード内で利用するコードを書いてみます。
$(Foo *ptr)で取り込んでいます。
{-# LANGUAGE QuasiQuotes #-}
{-# LANGUAGE TemplateHaskell #-}
module Main where
import qualified Language.C.Inline as C
import Foreign.Marshal.Utils (with)
import Foreign.Storable (peek)
import Foo
C.context fooCtx
C.include "foo.h"
printFoo :: Foo -> IO ()
printFoo foo =
with foo $ \ptr -> [C.exp| void{ printFoo( $(Foo *ptr) ) } |]
addFoo :: Foo -> IO Foo
addFoo foo =
with foo $ \ptr -> do
[C.exp| void{ addFoo( $(Foo *ptr) ) }|]
peek ptr
main :: IO ()
main = do
let foo = Foo 100
print foo
printFoo foo
foo' <- addFoo foo
print foo'
printFoo foo'
コンパイルが複雑になるので、Cabalに任せることにします。
全てのソースをsrcフォルダに保存してから、以下のような設定を書きました。
executable foo
main-is: Main.hs
other-modules: Foo
hs-source-dirs: src
cc-options: -Wall -O2
c-sources: src/Main.c, src/foo.c
includes: src/foo.h
include-dirs: src
build-tools: hsc2hs
C言語側で、表示と加算ができたことが確認できました。
$ cabal run
Foo {field = 100}
Foo: 100
Foo {field = 101}
Foo: 101
4.まとめ(FFIとinline-cの使い分け)
FFIやinline-cを使えば、C言語のコードを利用できるのですが、どのように使い分ければよいのでしょうか。
motivation(これはlanguage-c-inlineのもので、inline-cとは違うようですが。源流は同じ?)などを読んで、私的に解釈した限りでは、大規模なライブラリのバインディングではinline-cを使うほうがベターだということでした。
確かに、大規模なライブラリのバインディングについては、作成が大変ですし、元のAPIがちょっと変更されただけで、コンパイルできなくなります。たとえ、変更箇所とは異なるAPIが使いたいだけなのに!という場合だとしても。従って、使いたいAPIだけを、inline-cを通じて使うというのは合理的だと思います。
しかし、FFIで完全なバインディングが用意されているという状況は、ライブラリのユーザーにとっては魅力的です。なぜならば、元のライブラリのAPIを理解するのが、バインディングの作成者だけで済むのですから。ユーザーは、Haskellのコードだけを扱えばよいことになります。
まとめると、ライブラリの安定性・規模、現在・将来的なユーザー数、などを考慮して決めるということでしょうか。
小規模・安定ならばFFIを。
大規模・不安定ならば、inline-cを。
ユーザー数については難しくて、多いならば一部の人がバインディングを作成した方が、プログラマ全体の効率は上がりそうですが、変更が多い場合はその都度作り直しになるので、絵に描いた餅になってしまいますね。