Lesson4のFrogRiverOneは位置1から位置Xまでいく最短の時間を求めるというものです。具体例で確認してみましょう。
例えば長さ4の配列[4,1,2,3]について、4に行く(X=4)には時間はどのくらいかかるでしょうか?
今回の問題設定では各配列の要素が位置を表し、0,1,2…インデックス番号が時間を表していると考えてください。
つまり、
時間0(インデックス番号0の時)の時は4の位置が現れ、
時間1(インデックス番号1の時)の時は1の位置が現れ、
時間2(インデックス番号2の時)の時は2の位置が現れ、
時間3(インデックス番号3の時)の時は3の位置が現れます。
時間3の時になって初めて1~4の全てと数字が登場するので4秒後になって初めて位置4まで移動できます。なので今回の場合、最短で位置4まで行くための時間は3であることがわかります。
つまり今回考える設定は至ってシンプルであり、
『初めて1~Xまでの全てが登場するのは配列の何番目の時か』を問われているのです。
今回の場合ポイントとなるのは、いかに二重ループを回避してコードを書くかということでした。
アルゴリズムはいくつか思い浮かびますが
例えば、1~Xが出きった時点で終了にすることから
1 空リストを用意する(以下num_listと称する)
この空リストが1~Xの値でいっぱいになったらその時点を返す
2 値A[0]を空リストnum_listに追加していく
3 値A[1]をnum_listに追加する。ただし、num_listにすでにA[1]の値が含まれていたら重複してしまうので、num_listにA[1]が含まれているかを判定する必要がある。
この時点で、二重ループが避けられないことがわかる。
ではどのようにしたら二重ループは回避できるのでしょうか?
ヒントはカウントしていくということです。
アルゴリズムは以下の通りです。 1~Xの間の値が出現したら、カウントする。カウント回数がXになったら、つまりX個の数字が登場したことになるのでその時点のインデックス番号を返す。
また重複(例えば2が重複して登場する場合)に関して回避する方法としては、
あらかじめ全要素0からなる長さXの配列を用意しておき1~Xの間の値が登場した場合は『その値番目』に1を代入する。
そうすることで、あるか、ないかの判定が可能となる。
コードは以下の通りです。
def research_zero(A): すでに1~Xの中の値が登場しているかを判定する 0があれば登場していない数字があるということ
len_A = len(A)
for i in range(len_A):
if A[i] == 0:
return True
def solution(A,X):
nums_list = [0]*(X)
len_A = len(A)
i = 0
count_num = 0 #1~Xまで存在することを確認するための変数
while i < len_A and count_num < X:
if nums_list[A[i]-1] == 0 and A[i] <= X: #すでにその数字が確認用リスト内にあるか調べる 確認用のリストになく、
nums_list[A[i]-1] += 1
count_num +=1
i +=1
if research_zero(nums_list) or count_num > X:
return -1
return i-1
さて結果は。。。。?
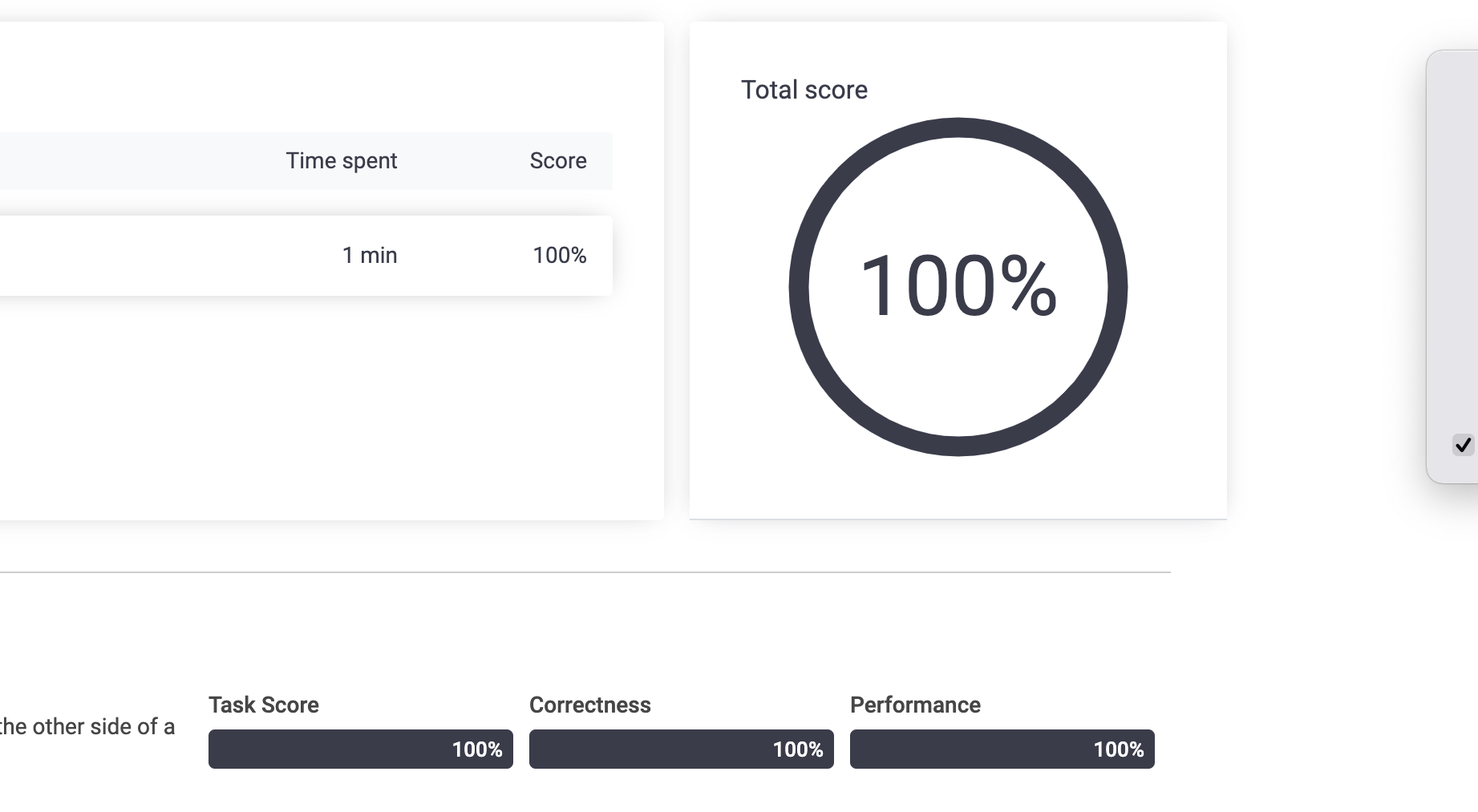
やったー、100%です!二重ループはカウントを使うと回避できるんですね!