必要なパッケージ
今回必要となるパッケージです。
library(tidyverse)
library(purrr)
Rにデータを読みこむ
csvファイルとしてGoogle Formsからダウンロードした前提で進めます。
data <- read_csv("questionnaire.csv")

(おまけ)ランダムなIDを追加する
新しいデータを追加するのに便利なのは、mutate関数です。以下のコードでは、IDという新しい列に、1~200の中のランダムな数値を、データの数だけ生成し(ID = sample(1:200, nrow(data)))、3列目(名前)の前に(before = 3 )挿入するという処理をしています。
追記(2024/01/23):
今回使用しているsample関数ですが、引数のreplaceをTRUEにしてしまうと、重複するIDを生成してしまいます。初期値はFALSEになっていますので、よほどのことがない限りIDを生成する場合はFALSEのままにしておく方がよいです。
data2 <- data %>%
mutate(ID = sample(1:200, nrow(data)), .before = 3)

同じ回答を削除する
例えば、回答を修正するため、別の回答を送ったりなど、全く同じ人が回答を二回送信しているということもあり得ます。
同一人物の回答がないか確認
回答数が多い回答者ごとに降順に並び変えています。
山内一豊さんが回答を二回送信していることが分かります。
data2 %>%
group_by(名前) %>%
summarize(Responses = n()) %>%
arrange(desc(Responses))

回答の削除
今回は、二回目の回答のデータを残す処理を紹介します。
Google Formsには、タイムスタンプと呼ばれるデータが必ず1列目に入っています。これは何かと便利な変数なので、削除せずにデータに残しておきましょう。
タイムスタンプを日時型に変換
現在、タイムスタンプは文字型のデータとなっています。これを、日時のデータ(POSIXctオブジェクト)に変更します。
引数のformatは、タイムスタンプに合わせて変更してください。
data2$タイムスタンプ <- as.POSIXct(data2$タイムスタンプ, format = "%Y/%m/%d %H:%M")
# タイムスタンプに秒まで記録されている場合
# data2$タイムスタンプ <- as.POSIXct(data2$タイムスタンプ, format = "%Y/%m/%d %H:%M:%S")
一つ目の回答を削除
各参加者のデータを、タイムスタンプが早い順に並び替えます。
data2 %>%
group_by(名前) %>%
arrange(タイムスタンプ)
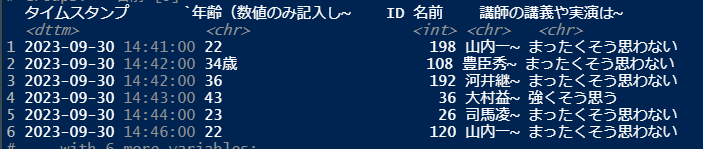
二つ目の山内一豊のデータ(回答が二回目)をslice関数で削除します。以下のコードは、一つ目のデータを削除するコードですので、もし他にも複数回答者がいた場合も、一つ目のデータが削除されます。処理を一つずつ解説すると、まずgroup_by(名前)で回答者ごとに回答をまとめる。次にarrange(desc(タイムスタンプ))でタイムスタンプを降順に並べ替えます。つまり、回答が新しい順に並び替えます。slice(1)で各回答者の最初の行を選択します。つまり、各回答者の最新の回答のみを選択し残します。最後に、ungroup()でグループ化を解除します。
data3 <- data2 %>%
group_by(名前) %>%
arrange(desc(タイムスタンプ))%>%
slice(1) %>%
ungroup()

データを縦型に変形
現在のデータは、いわゆる横型のデータで、人間は解釈しやすいかもしれませんが、コンピュータには優しくないそうです。これを縦型のデータ、いわゆるtidyなデータに変換します。以下のコードでは、data2の5から11列までを(cols = 5:11)、questionsという新しい列に設問を格納し(names_to = "questions")、それらの回答を、answerという新しい列に格納しています(values_to = "answer")。
data3_long <- data3 %>%
pivot_longer(
cols = 5:11,
names_to = "questions",
values_to = "answer"
)
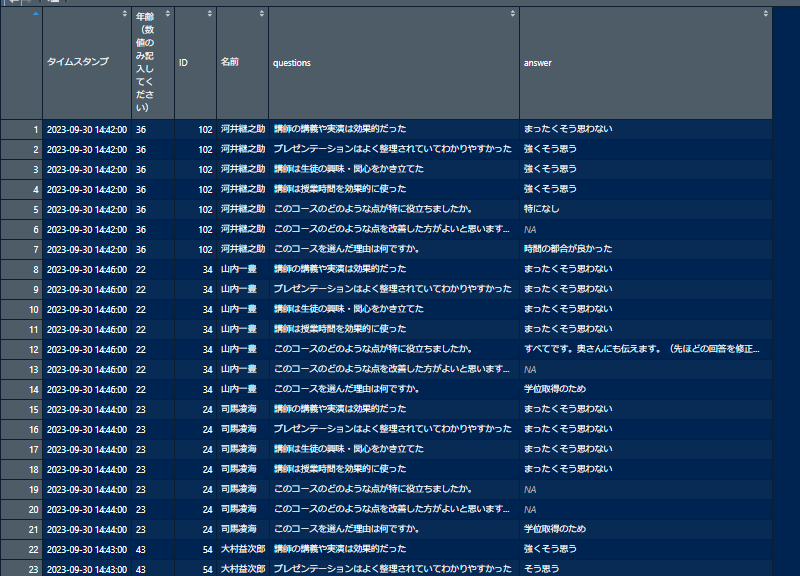
データの整形をする
欠損値(NA)の処理
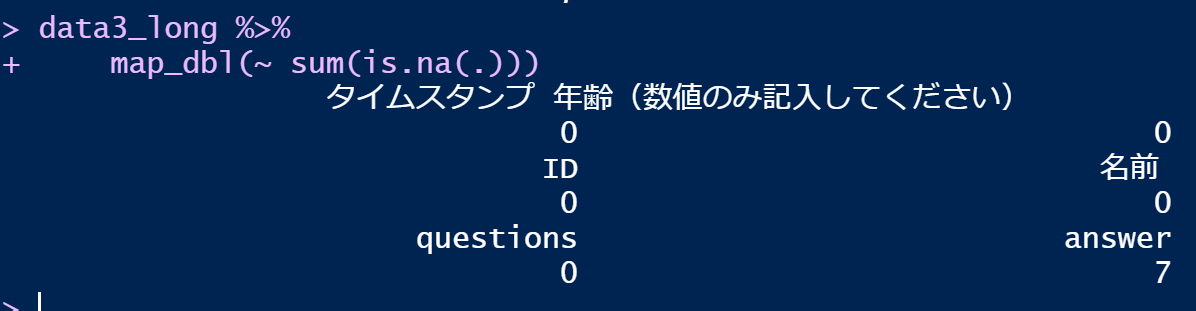
まず。欠損値がいくつあるか数えます。
data3_long %>%
map_dbl(~ sum(is.na(.)))
answerの列に7つ欠損値があることが分かります。
欠損値を任意の値に置き換える
answerの列に7つあることが分かりました。よって、これらのセルは、「無回答」という単語で埋めることにします。replace_na(list(answer = "無回答"))では、replace_na関数を使用して、欠損値(NA)を「無回答」という文字列に置き換えます。
data3_long2 <- data3_long %>%
replace_na(list(answer = "無回答"))
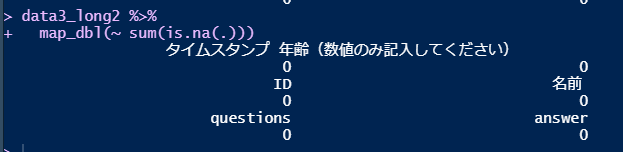
再度欠損値の数を調べると、answerの列の欠損値の数が0になっています。
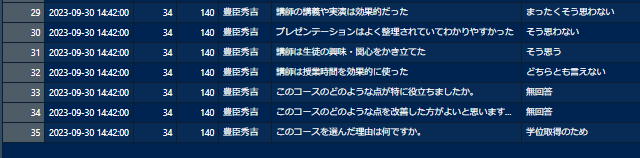
余計な値を削除
いくら指定をしていても、必ず回答者がそのように回答するかはわかりません。例えば、豊臣秀吉は数値ではなく「34歳」と入力しています。この「歳」を削除しましょう。

今回は正規表現を使います。mutate関数を使用して「年齢」列内のテキストから数値だけを抽出し、その結果を元のデータフレームに上書きしています。
data3_long3 <- data3_long2 %>%
mutate(`年齢(数値のみ記入してください)` = as.numeric(gsub("[^0-9]+", "", `年齢(数値のみ記入してください)`)))
(おまけ)全角を半角に変換
あらかじめ、Google Formsで、数値入力を半角にするのが一番いいですが、忘れていた時のために書いておきます。
例えば、以下のデータのように、年齢のデータがすべて全角文字で入力されていると仮定します。このデータに先ほど説明した正規表現を使った方法で「歳」をとると、数値も全角なのでデータが消えてしまいます。
参考:https://qiita.com/tex_owleyes/items/5d795f40f0ce67730c93
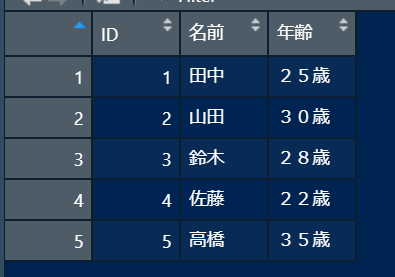
データの作成
data_frame <- data.frame(
ID = 1:5,
名前 = c("田中", "山田", "鈴木", "佐藤", "高橋"),
年齢 = c("25歳", "30歳", "28歳", "22歳", "35歳"),
)
実行
まず、「歳」を削除します。そのあとで、残った全角数字をstri_trans_general関数で変換します【1】。今回はわかりやすいように、年齢_tmpという新しい列に追加しています。
data_frame <- data_frame %>%
mutate(年齢 = str_replace(年齢, "歳", "")) %>%
mutate(年齢_tmp = stri_trans_general(年齢 , "Fullwidth-Halfwidth"))

データを横型に戻す
横型で分析をやるように求められることもあります。縦型から横型に戻すときはpivot_wider関数を使います【2】。
data3_long4 <- data3_long3 %>%
pivot_wider(names_from = questions, values_from = answer)

最後に
修正点や、もっと便利な方法がある場合は、コメント等で教えてください!
参考記事
1 R言語でデータフレームの全角半角変換、記号削除、大文字小文字変換など ※「chartr」追加
2 Rのtidyrのpivot_longerとpivot_widerの使い方メモ