はじめに
来月開催されるCVPR2018のHP内、main conference
http://cvpr2018.thecvf.com/program/main_conference
の中にsegmentation関係の論文があったので、arXivで検索して読んでみた、の2つ目。
[1] Z. Zhangらの「Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network」
https://arxiv.org/abs/1802.09655
概要
以下の図のように
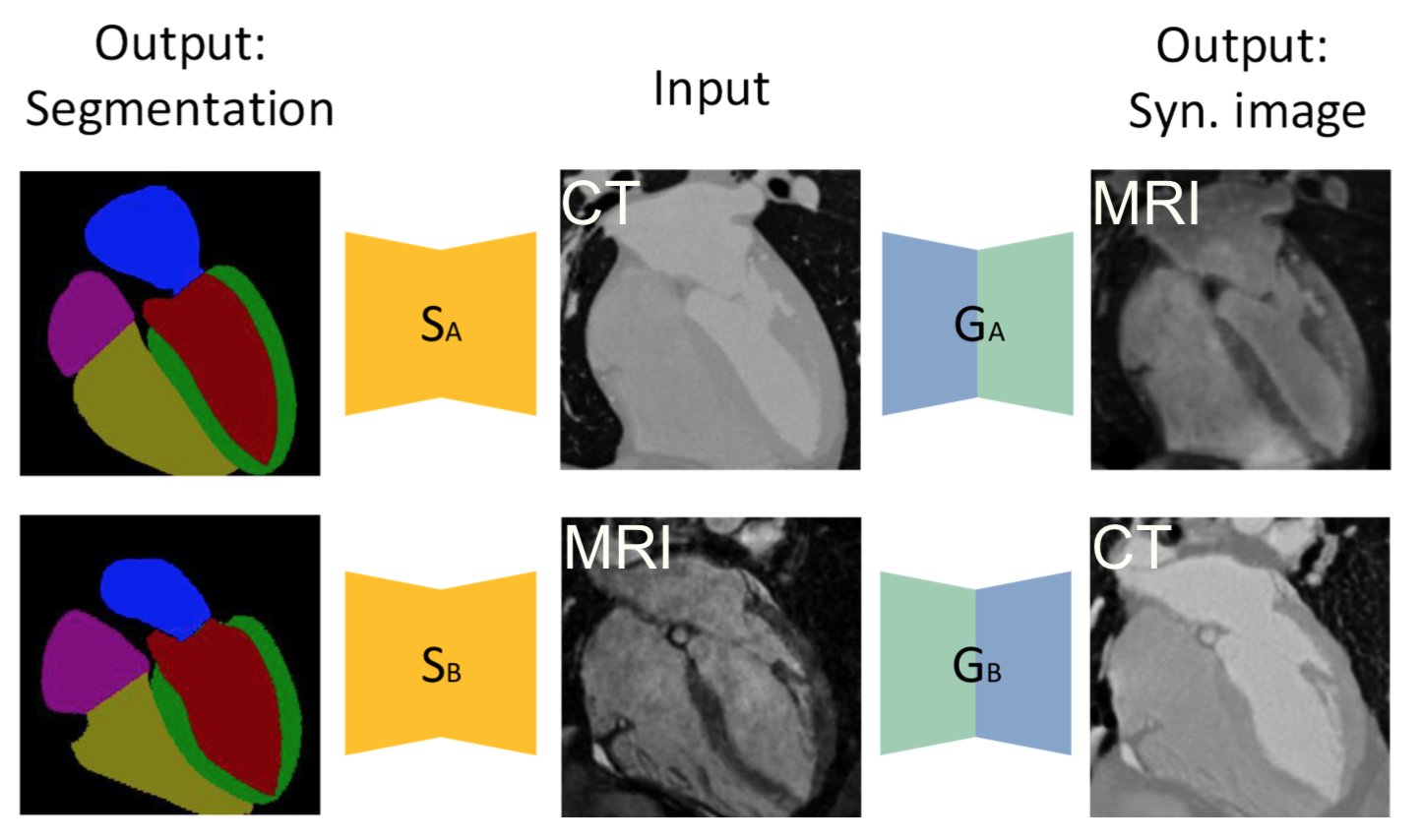
[1]Figure 1より
CT画像からMRI画像を作ったり、MRI画像からCT画像を作ったり、これら生成した画像を使ってsegmentationしたりする。
Cycle GAN風な構造を持っている。GeneratorとSegmentorがり、GeneratorはMRIからCT画像、あるいはCT画像からMRI画像を生成するように学習する。この時、1)adversarial loss、2)cycle-consistency loss、 3)shape-consistency lossを用いる。
一方、Segmentorはこれら生成画像や本物の画像からSegmentするように学習する。
アーキテクチャ
全体図
アーキテクチャの全体図は以下
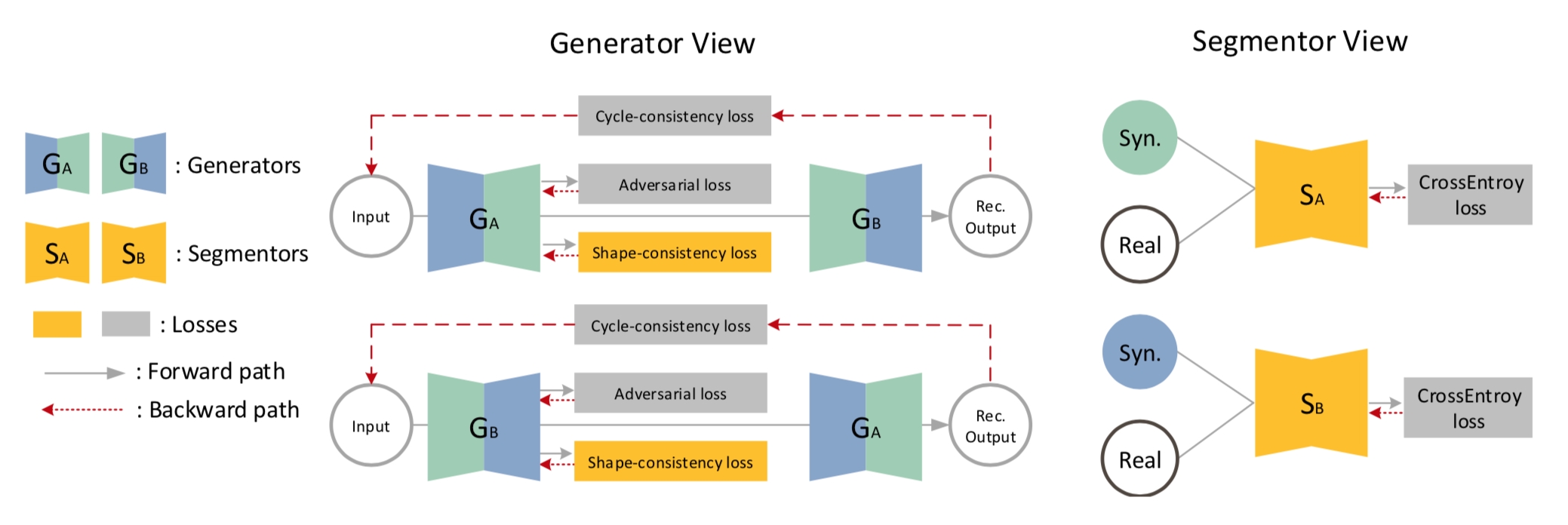
[1]Figure 2より
図中の各要素は左側の説明の通り。
中央はGenerator まわり。右側はSegmentor まわり。詳細は以下。
Generator まわり

$G_A$ はBの画像からAを生成するgenerator。左からinputとしてB画像を入れるとA画像が生成される。
これをDiscriminatorに送って Adversarial な lossをとるのが1つ。
さらにA画像をsegmentationするsegmentor に送って Shape-consistency lossをとるのが1つ。
さらにA画像からB画像を生成するgenerator $G_b$ にも送ってA画像を再構築させ
、元のA画像とCycle-consistency lossを取るのが1つ。
これら3つのlossで学習させる。
inputとして画像Bを使う場合も同様。

Segmentor まわり
SegmentorはA画像をsegmentする $S_A$とB画像をsegmentする $S_B$ がある。
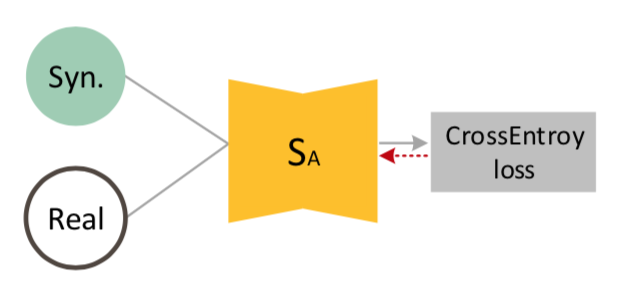
$S_A$ に関しては生成器で作成したA画像と、リアルなA画像の両方を入れて、boxel wiseな交差エントロピーで学習させる。
$S_B$ に関しても同様。

Loss
1. Cycle-consistency loss
cycle-GANと同様に以下のL1 norm。
\begin{eqnarray}
L_{cyc} (G_A, G_B) &=& \mathbb{E}_{x_A \sim p_d (x_A)} [\parallel G_A (G_B (x_A)) - x_A \parallel_{1} ] \\
&+& \mathbb{E}_{x_B \sim p_d (x_B)} [\parallel G_B (G_A (x_B)) - x_B \parallel_{1} ]
\end{eqnarray}
2. Cycle-GANを適用する際の問題点
上記の cycle-consistency lossで学習させた場合、例えば以下のように $G_A '$ では左右対称 $T$ のような変換が行われ、$G_B '$ ではさらに左右対称 $T^{-1}$ が行われた場合、cycle-consistency loss は0となる。
\begin{eqnarray}
G'_A &=& G_A \circ T \\
G'_B &=& G_B \circ T^{-1}
\end{eqnarray}
しかし $G_A ' = G_A \circ T$ は元の形状(例えば右側に胃、左側に肝臓)は失われている。これを防止するためには以下の Shape-consistencyが有効となる。
3. Shape-consistency loss
以下の loss を加えることで幾何学的な形状を維持する。
\begin{eqnarray}
L_{shape}(S_A, S_B, G_A, G_B) &=& \mathbb{E}_{x_B \sim p_d (x_B)}[-\frac{1}{N} \sum_i y^i_A log(S_A (G_A (x_B))_i)] \\
&+& \mathbb{E}_{x_A \sim p_d (x_A)}[-\frac{1}{N} \sum_i y^i_B log(S_B (G_B (x_A))_i)]
\end{eqnarray}
boxel wiseなクロスエントロピーをとっている。
4. Lossの全体像
adversarial な loss を加えると以下
\begin{eqnarray}
L_{shape}(S_A, S_B, G_A, G_B) &=& L_{GAN}(G_A, D_A) \\
&+& L_{GAN}(G_B, D_B) \\
&+& \lambda L_{cyc} (G_A, G_B) \\
&+& \gamma L_{shape} (S_A, S_B, G_A, G_B)
\end{eqnarray}
アーキテクチャ
ネットワークのアーキテクチャに関するポイント(特にcycle-GANとの比較)は以下。
- 3Dのconv
- batch normalizationではなくinstance normaliationを使う
- generatorではReLu、discriminatorではLeaky ReLuを使う
- generatorではcycle-GANのようなResNetベースではなく、U-Netベース
- transpose-convに替えてupsampling+convを用いる
- segmentorでもU-Net構造を用いる
学習方法
学習方法のポイントは以下。
- cycle-GANのようにAdamでlearning rateを下げていく
- $G_{A/B}$ 及び $D_{A/B}$ を別個に事前学習させる
実装例
こちらに実装した内容をまとめました。
https://qiita.com/masataka46/items/a496b3db0ba6b1ac4f68