はじめに
G. Ning氏らが2016年7月に発表した Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking をまとめてみた。
arXivのリンクはこちら
[1] https://arxiv.org/abs/1607.05781
著者らの解説サイトはこちら
[2] http://guanghan.info/projects/ROLO/
demo video が幾つかあります。
概要
- visual object tracking タスクで CNN と LSTM を用いた新しいアプローチ
- CNNからの特徴量と位置情報の履歴を利用する
- 既存の候補領域を用いた手法と比べた場合、CNN 部分と LSTM 部分両方において回帰問題として解くのが特徴的
- 結果、様々な data sets において低い演算コストながら state-of-the-art な精度となった
tracking タスクの定式化
Xtを t 時の input frame、Btを t時の object の位置とする。t-1までの位置とtまでの入力画像からt時の位置を推定する。
p(B_1, B_2, \cdot \cdot \cdot,B_T | X_1, X_2, \cdot \cdot \cdot,X_T) = \prod^T_{T=1} p(B_t | B_{<t}, X_{\leq t})
提案モデル(ROLO)
モデルの概略
ざっくり言うと以下の図。
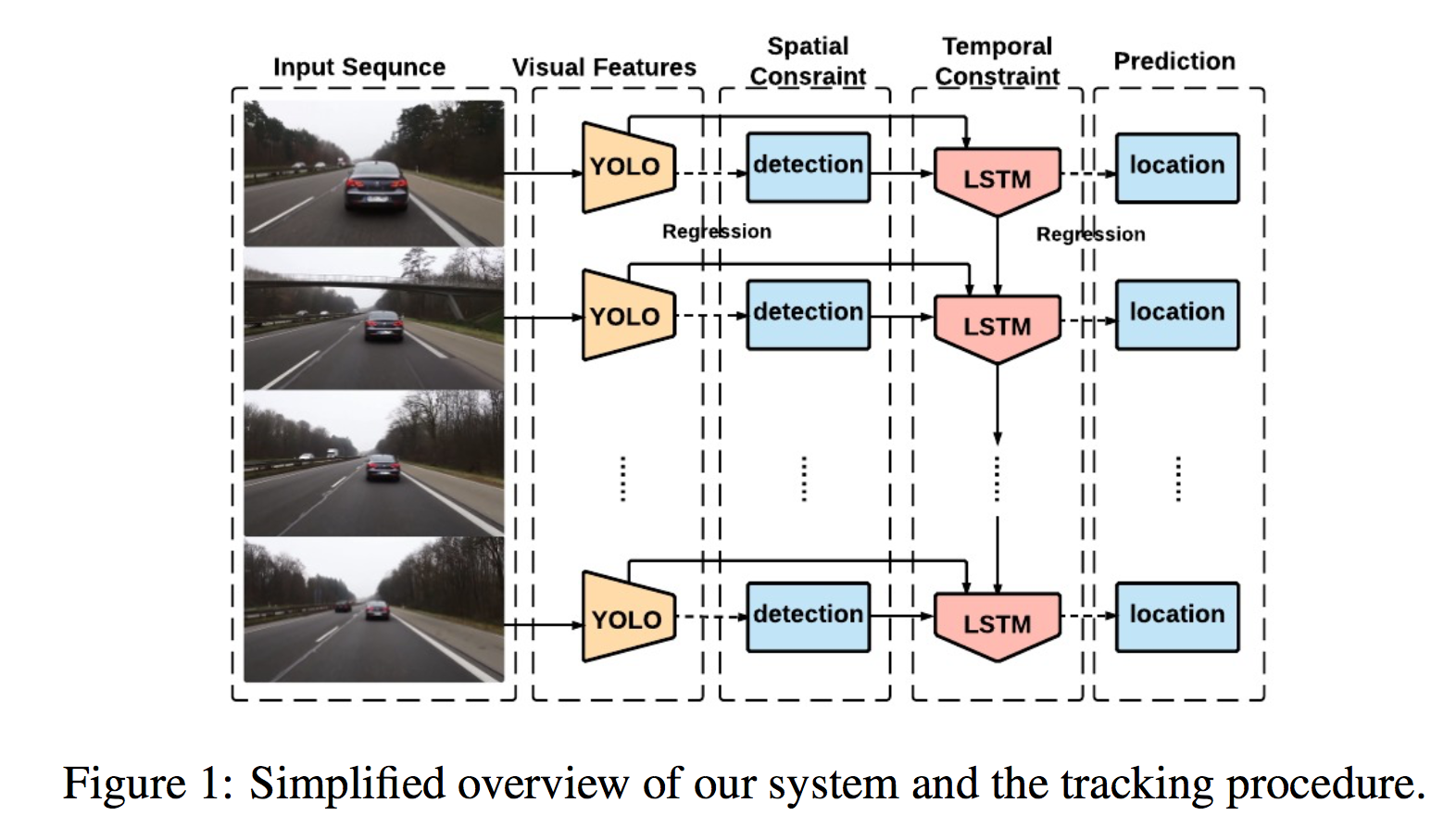
各時刻の frame を YOLO に入れ、中間層からの特徴量、および出力層からの矩形情報(位置)を取り出し、それを LSTM に入れる。
これにより現在の矩形情報(位置)を推測する。詳細のアーキテクチャは以下。
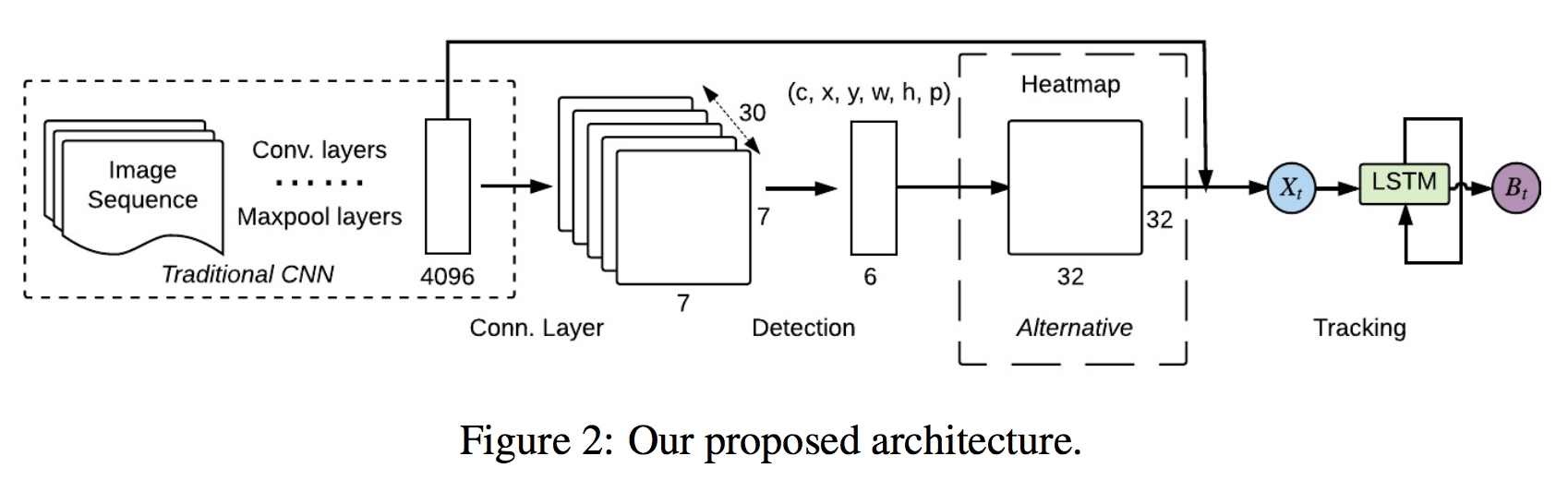
Phase 1 CNNで事前学習
最初に trditional な CNN(VGG-Netとか?)で事前学習させる。
具体的には ImageNet の 1,000クラス分類で学習させ、おおよその object に対して特徴量を検出できるようにする。(Figure 2 の点線の部分。)
Phase 2 YOLOで特徴量と矩形情報を抽出
次にこれを YOLO の architecture で学習させる。YOLO は S X S の各グリッドに対してB個の矩形を推定する。そのそれぞれが矩形のx座標、y座標、縦h、横w、確からしさcを有する。また各グリッドは C 個のクラスに対するチャンネルも有するので、結局 YOLO の出力は
S \times S \times (B \times 5 + C)
のテンソルとなる。しかし今回のモデルでは確からしさとクラスの部分は使わないので、
B_t = (0,x,y,w,h,0)
とする。
中間層から抜き出す特徴量Xtとしては、最初の全結合 4,096 次元を使用する。
LSTMで時系列処理
Xt と Bt をLSTMへ入れ、t時刻の矩形を推定させる。平均二乗誤差でLossを求め、Adamで学習させる。
L_{MSE} = \frac{1}{n} \sum^n_{i=1} ||B_{target} - B_{pred}||^2_2
Alternative Heatmap
例えば、オクルージョンがある場合、YOLOからの出力 (0,x,y,w,h,0) を直接 LSTM に放り込むと
(0,0.8,0.4,0.1,0.1),(0,0.81,0.41,0.1,0.1), \dots ,(0,0.83,0.42,0.1,0.1)
ときたものが急に(0,0,0,0,0)となったりするのでよろしくない。
そこで YOLO の出力を 32 x 32 の Heatmap に変換してから LSTM に放り込む。
LSTM からの出力および target も 32 x 32 の Heatmap とし、平均二乗誤差を計算する。
L_{MSE} = \frac{1}{n} \sum^n_{i=1} ||H_{target} - H_{pred}||^2_2
結果
汎化性能
まず以下の Figure 4 の (a) と (b) では、ground truth は顔の領域となっている。しかし YOLO の学習データである VOC には顔はない。よって、顔(を含む)領域を tracking していることから、ROLO は汎化性能があるといえる。
また YOLO に比べて ROLO モデルは安定的に領域を検出している。

occulution
次に occulution に対する頑健性の検証。Figure 5 の上側は途中で車が木に隠れてしまっている。YOLO は完全に見失っているが、ROLO は検出している。
下側は人の体の一部が車に隠れる場面。ROLO の方が検出領域がより ground truth に近い。

他のモデルと性能比較
AOS で他のモデルと比較。各データセットに対して最もよい結果が緑、2番目が赤。ROLO は総じて性能がいい。