はじめに
CVPR2018から以下の論文
[1] S. Tulyakov, et.al. MoCoGAN: Decomposing motion and content for video generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
のまとめ
ちょっと古いがその後の論文に対する影響も考慮してざっくりまとめ。
arXiv:
https://arxiv.org/abs/1707.04993
著者らのらしきコード:
https://github.com/sergeytulyakov/mocogan
pytorchっぽい。
松尾研のKei Akuzawa氏のまとめ:
https://www.slideshare.net/DeepLearningJP2016/dl-mocogan-79636540
概要
- 生成モデル GANs の一種。
- あるビデオに対し、その content(写ってるAさんとか)を維持しながらその動きを変えたり、逆に動きはそのままで contentを変えたりできる
- content と動き(motion)を分離するのが特徴的
以下のように同じ人や表情(content)に対して別の動き(motion)をさせることができる。

上2つの行でいうと、ある人の顔(content)は変わらないが、右にいくと表情が変わる。この場合、motionは顔の筋肉の動きのようなもの。
背景
著者らによると、画像の生成とは異なり動画の生成は以下の点で難しい。
- 物体の外見だけでなく動きも学習する必要があるが、その動きは物理的に可能なものでなければならない。
- 同じ動作を表現するにしても早く行うか遅く行うかなど、多様である
- 人は動きに対して敏感なので、人が見て不自然にならない動きにするのは困難である
アーキテクチャ
1. 定義
$Z_I \equiv \mathbb{R}^d$ ・・・画像の潜在空間
${\bf z} \in \mathbb{R}^d$ ・・・画像(もしくはビデオの1フレーム)
$[{\bf z}^{(1)}, \cdots , {\bf z}^{(K)}]$ ・・・動画。右上の添字はフレーム番号
2. 画像潜在空間を content と motion へ分離
$Z_C \in \mathbb{R}^{d_{C}}$ ・・・contentのsubspace
$Z_M \in \mathbb{R}^{d_{M}}$ ・・・motionのsubspace
として、
$Z_{I} = Z_{C} \times Z_M, \ \ d = d_{C} + d_{M}$
と分離する。
それぞれこんな感じ。

3. content subspace の詳細
content subspace は
\begin{eqnarray}
{\bf z}_C &\sim& p_{Z_C} \equiv \mathcal{N}({\bf z} | 0, I_{dc}) \\
\end{eqnarray}
$I_{dc}$ は $d_{C} \times d_{C} $ の分散共分散行列。
1つの video clip 中は content は変わらないと考えて ${\bf z}_C$ は一定とする。
4. motion subspace の詳細
まず各フレームにおいてガウス分布からベクトルをサンプリングする。
\epsilon^{(k)} \sim p_E \equiv \mathcal{N}(\epsilon | 0, I_{d_E})
これをRNN(本論文ではGRUを使用) $R_M$ に入力し、motion の subspace を得る。
{\bf z}^{(k)}_M = R_M(k)
$\epsilon^{(k)}$ は各フレームごとに独立にサンプリングされるが、 $R_M$ を通すことでそれが時間軸方向に意味ある繋がりを持つイメージ。以下の図がその部分。

5. generator
video clip 内で一定の ${\bf z}_C$ とフレームごとにRNNから生成される ${\bf z}^{(k)}_M$ を generator に入力する。つまり
[{\bf z}^{(1)}, \cdots , {\bf z}^{(K)}] = \left[ \left[\begin{array}{c}
{\bf z}_C \\
{\bf z}^{(1)}_M
\end{array}
\right], \cdots ,
\left[\begin{array}{c}
{\bf z}_C \\
{\bf z}^{(K)}_M
\end{array}
\right] \right]
を入力する。

generatorからはフレーム $k$ ごとに画像 $\tilde{\bf x}^{(k)}$ を生成する。
\tilde{\bf x}^{(k)} = G_I \left( \left[ \begin{array}{c}
{\bf z}_C \\
{\bf z}^{(k)}_M
\end{array}
\right] \right)

6. discriminator
discriminator は画像ベースでreal か fake かを判断する $D_I$ と動画ベースで real か fake かを判断する $D_V$
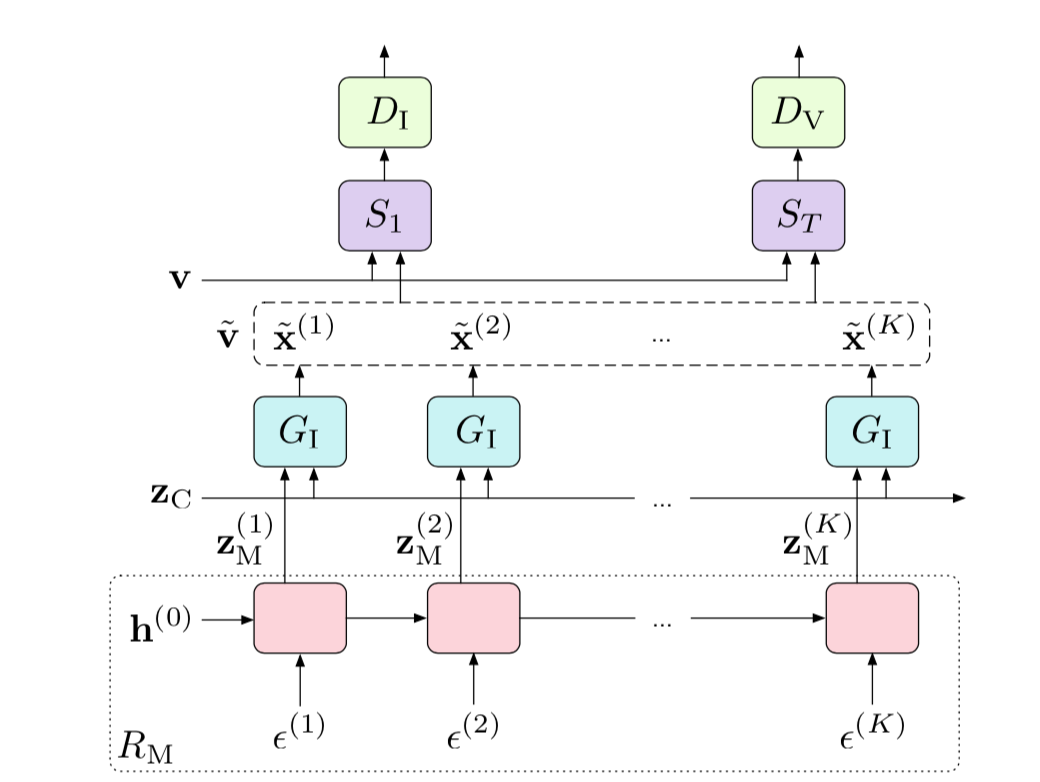
特に $D_V$ の方はシーケンスの長さを決めて(論文では16を使用)、3d-cnnで畳み込む。

loss
GANs loss
adversarial な loss は以下。
\begin{eqnarray}
&& \max_{G_I, R_M} \min_{D_I, D_V} \mathcal{F}_V (D_I, D_V, G_I, G_M)\\
&=& \mathbb{E}_{\bf V} [-\log D_I(S_I({\bf v}))] + \mathbb{E}_{\tilde{\bf v}} [-\log(1- D_I(S_I(\tilde{\bf v})))] +
\mathbb{E}_{\bf V} [-\log D_V(S_V({\bf v}))] + \mathbb{E}_{\tilde{\bf v}} [-\log(1- D_V(S_V(\tilde{\bf v})))] \\
\end{eqnarray}
右辺第1項はrealなimage(1フレーム)を入れた場合、第2項はgeneratorで生成したimageを入れた場合、第3項はrealなvideoのclipを入れた場合、第4項はgeneratorで生成したvideo の clipを入れた場合。
categorical な losss
infoGANのごとく相互情報量の変分下限 $L_I (G_I, Q)$ を最大化させることでカテゴリーごとに分かれるように仕向ける。
参照 自分のinfo-GANの記事:
https://qiita.com/masataka46/items/9d2c0167c334125a41a6
total の loss は両方たす
\max_{G_I, R_M} \min_{D_I, D_V} \mathcal{F}_V (D_I, D_V, G_I, G_M) + \lambda L_I (G_I, Q)
実験と結果
1. average content distance による定量的評価
content を固定して motionを変える場合、全てのフレームにおけるcontentは一致してほしい。
average content distance は例えば顔の表情タスクの場合、OpenFaceなど性能を認められたモデルで各フレームを推論させ、feature vectorを取り出してそれらが一致するかをL2 distannce で測定する。
結果は以下。
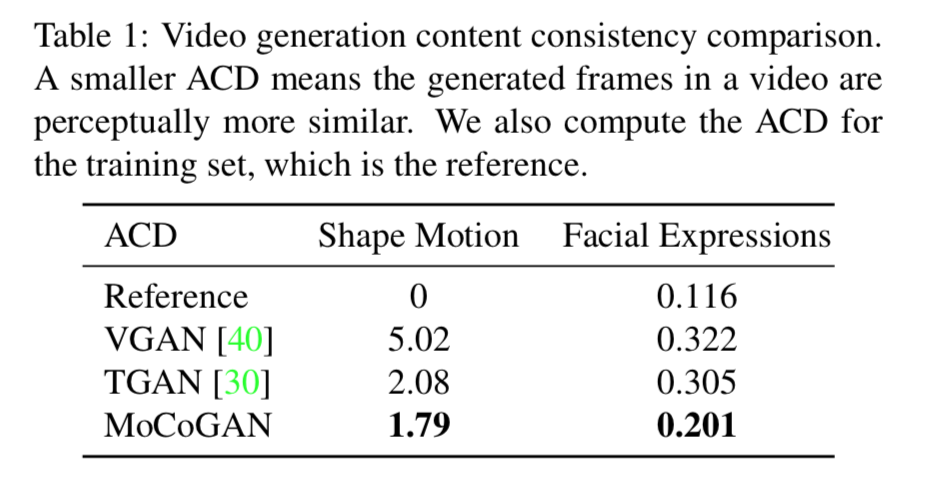
VGANやTGANよりdistanceが小さい(性能が良い)
2. 定性的評価
VGANやTGANと比較したらこんな感じ。
