はじめに
NIPs2017で採択されたPG2(Pose Guided Person Image Generation)という論文をまとめてみた。
NIPs上の該当ページはこちら。
https://nips.cc/Conferences/2017/Schedule?showEvent=8837
論文の本文はこちら。
http://papers.nips.cc/paper/6644-pose-guided-person-image-generation.pdf
解説用Videoはこちら。
https://www.youtube.com/watch?v=FBW6drMpK3U&feature=youtu.be
要点
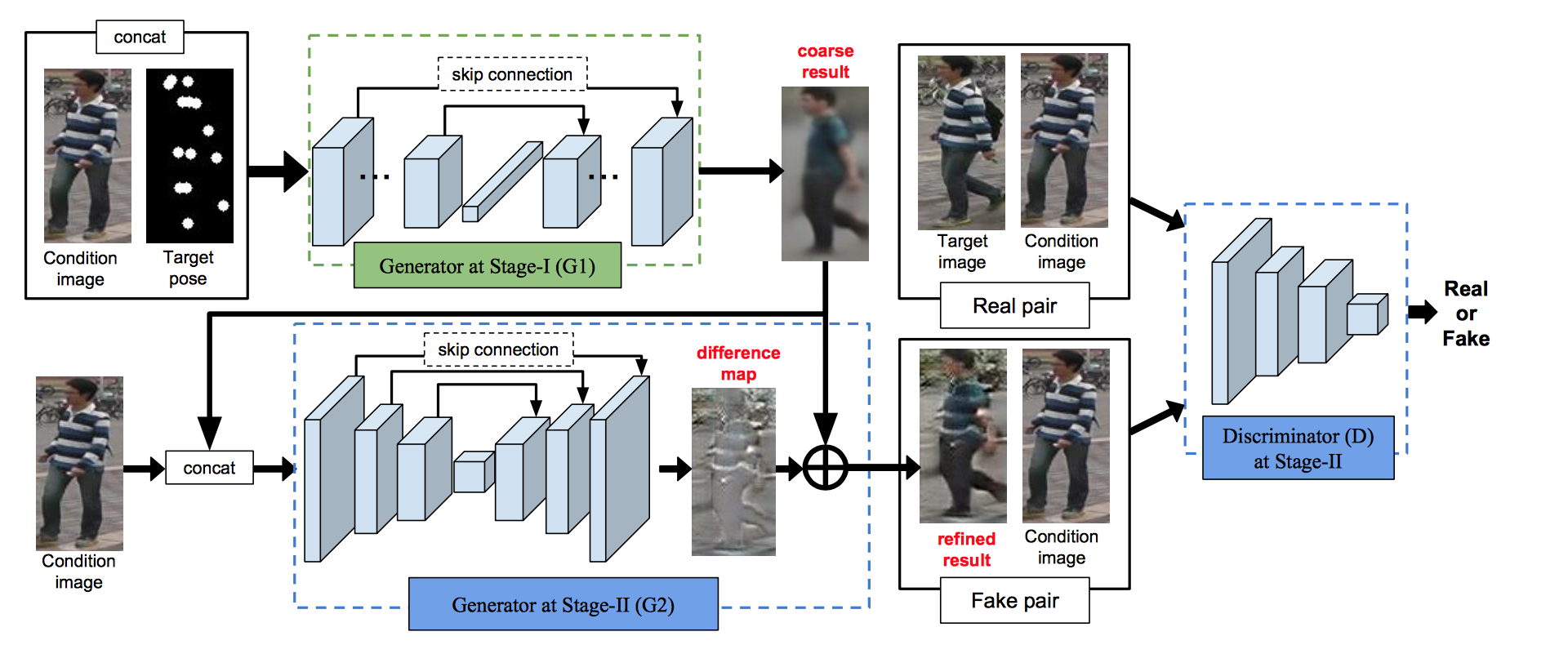
PG2はある人物の画像を任意のポーズに変換する仕組みである。具体的には、ある人物Aの画像(Condition Image)と、その画像にはない別のポーズB(Target Poses)を入力として、人物AがポーズBをした画像を生成するシステム。(下図参照)

(Supplementary materials Pose Guided Person Image Generation Figure4より)
モデルは2つのステージからなる。1つ目のステージ(G1)でCondition ImageとTarget PosesをU-netに似たネットワークに入力してtarget poseをしたCondition imageの人の粗い画像を出力する。
2つ目のステージ(G2)でその画像をやはりU-netに似た仕組みに入力し、GANsの学習方法でrefineする。(下図参照)
ステージ1(G1)
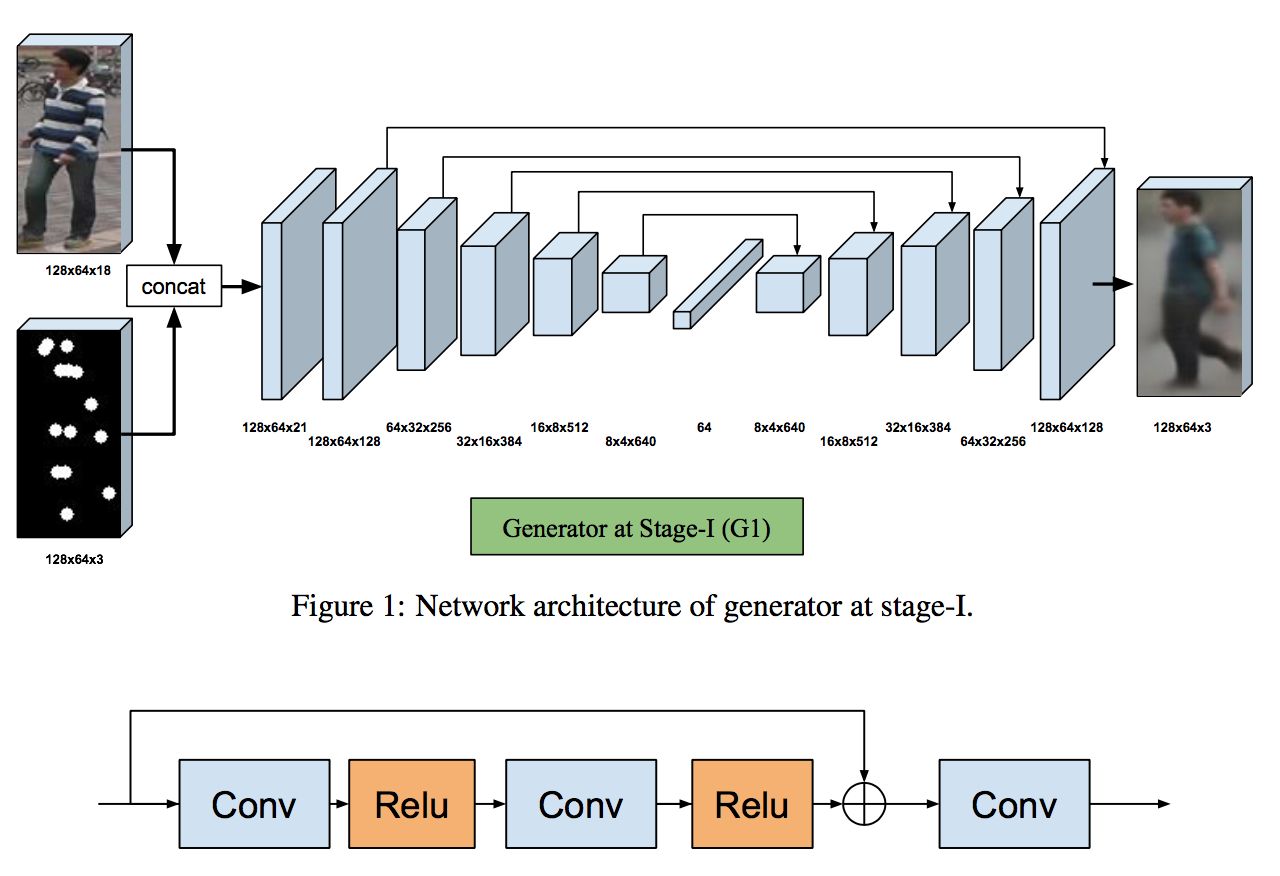
上述のように、ステージ1(G1)ではCondition Image $I_A$ とTarget Poses $P_B$ をネットワークに入力してtarget poseをしたCondition imageの人の粗い画像 $\hat{I} _{B1}$ を出力する。詳細は以下。
G1モデルのアーキテクチャ
以下のようにU-netを模している。
(Supplementary materials Pose Guided Person Image Generation Figure1,2より)
複数回畳み込んだ後に、全結合で64次元のベクトルまでencodeする。その後元のサイズまでup-conv(upsamplingした後にconv)する。U-netなので複数のskip connectionがある。
ただし、オリジナルなU-netと違い、上図下側のようにresidual blockを用いている。これにより精度をさらに上げている。
Pose mask loss
G1のLossとして、単に出力と実際のTarget画像 $I_B$ をL1ノルムなどで計算してもうまくいかないだろう。なぜなら人でない部分・・・back groundが違いすぎるため、そこのlossを縮めようとするだろうから。
そこでback groundの影響を少なくするため、Pose mask lossというものを用いる。これは以下の図のようにTarget Poseをもとに作成した、人の体を覆うようなmaskである。
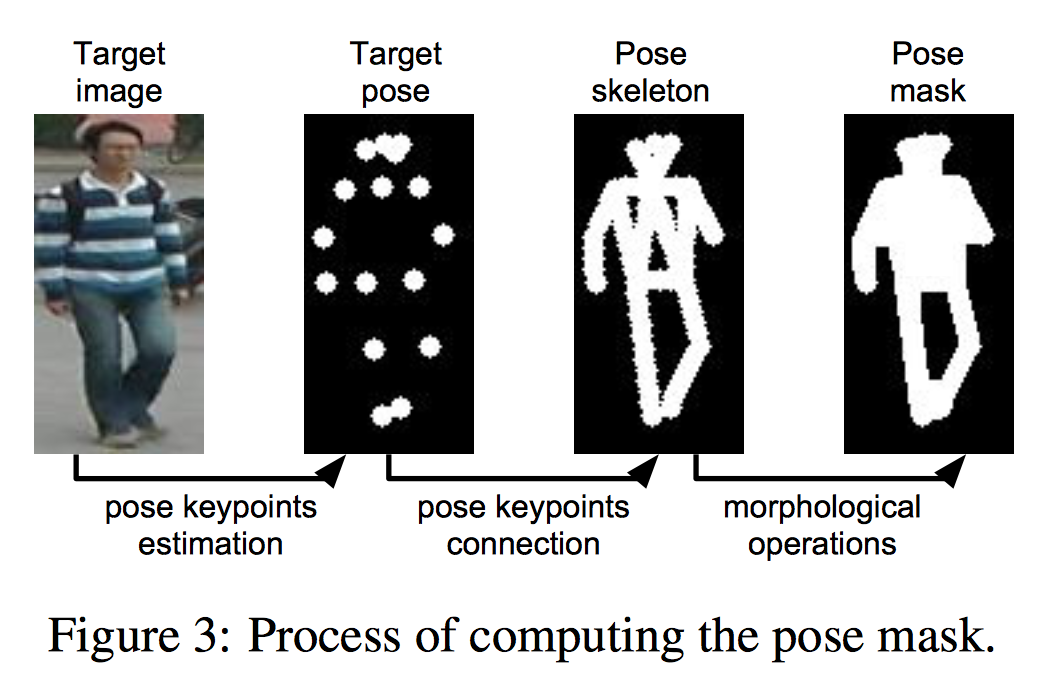
(Figure3より)
このmask $M_B$ を用いて、lossは以下のように計算する。
L_{G1}=||(G1(I_A,P_B)-I_B) \odot (1+M_B)||_1
hadamard積の左側はG1モデルからの出力 $G1(I_A,P_B)$ とTarget画像 $I_B$ とのpixel wiseな差。
hadamard積の右側がmaskの部分。mask $M_B$ は人の部分が1で他が0。これに1を加えるので、人の部分が2で他が1となり、人の部分の影響が他の部分の2倍となる。
ステージ2(G2)
G1で生成された画像はおおまかに目的のポーズを捉えているものの、画質が粗いものとなる。よってG2でこれをrefineする。
G2は上述の通り、generator部分とdiscriminator部分とからなる。
generator G2のアーキテクチャ
G2のgenerator部分も下図のようにU-netを模したものとなっている。
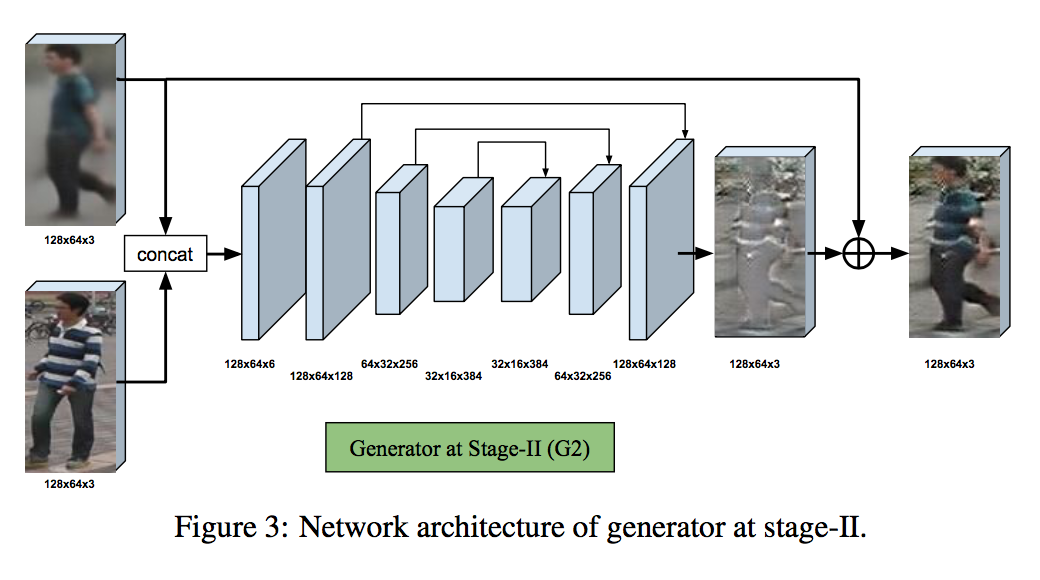
G1で生成した画像 $\hat{I} _{B1}$ とcondition image $I_A$ から $\hat{I} _{B1}$ をrefineするための差分を出力する。これを $\hat{I} _{B1}$ に加えることでrefineされた画像を得る。
U-netの構造でG1と大きく違う点は、全結合を用いていない点だ。これはcondition image $I_A$ のdetailをより用いるためだ。
Discriminator D
discriminatorはpix2pixモデルのように、本物のペア(condition imageとtarget image)か偽物のペア(condition imageとrefined result)かを識別する。具体的なアーキテクチャはDCGANとほぼ同じ。(下図参照)
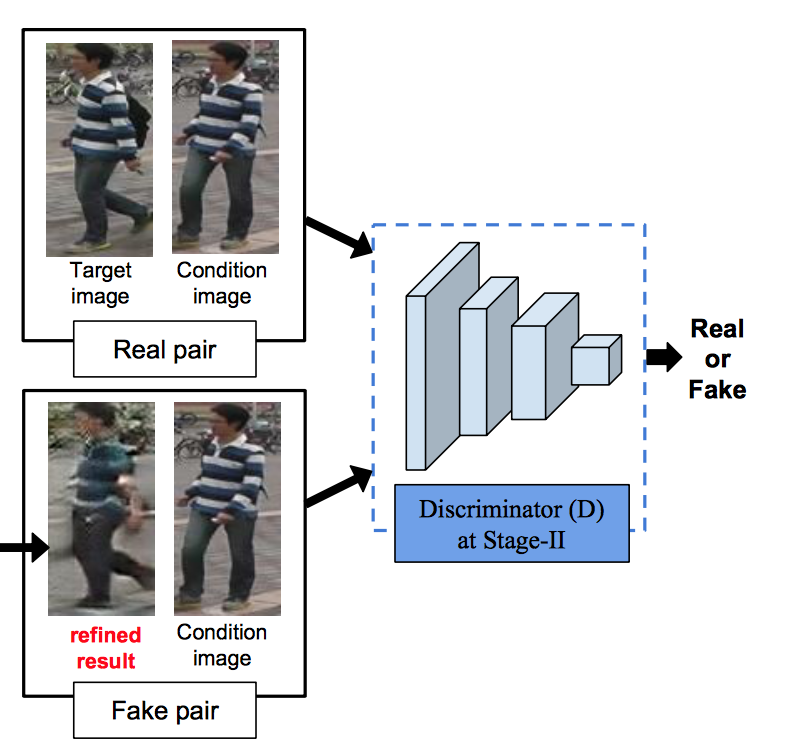
(Figure2より)
Lossの計算
lossは以下のようになる。まずdiscriminatorに関しては
L^D_{adv}=L_{bce}(D(I_A, I_B),1)+L_{bce}(D(I_A,G2(I_A,\hat{I}_{B1})),0)
となる。第1項は本物ペアを入れた時のbinary cross entropyで、第2項は偽物ペアを入れた時のbinary cross entropy。このへんは通常のGANsと同じ。
一方で、generatorの方はadversarialなlossとさきほどの $L_{G1}$ との和となる。まずadversarialなlossは
L^G_{adv}=L_{bce}(D(I_A,G2(I_A,\hat{I}_{B1})),1)
で、これを用いて
L_{G2}=L^G_{adv}+\lambda L_{G1}
となる。
個人的に面白いと思うところ
同じく学習用データの水増しモデルであるsimGANとかDA-GANなどと比較した場合、画像をsynthesizeするところも含めている点が興味深い。このsynthesizeを達成するために、着目物体以外の影響を小さくしたmaskの仕組みは他のtaskにも応用が利きそう。