はじめに
3DIMPVT 2024より、以下のまとめ
[1] Tomas Jakab, et. al. Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
paper
https://arxiv.org/pdf/2304.10535
project page
https://farm3d.github.io
評価に関するコードのgithub
https://github.com/tomasjakab/animodel
概要
- 牛や馬など動物のあるカテゴリーに特化して、その種の3D形状を復元するしくみ
- 1枚の画像を入力として、そこから3D形状、albedo、illumination、viewpointを推定する
- 学習データとして用いるのは、off-the-shelfなstable diffusionモデルから生成したもの、のみ
- 入力画像に対し、学習対象のencoderでshape, appearance, viewpoint(R, t), lightを推定し、それをrenderingロジックで再構築させ、reconstruction lossを求める
以下の図のでは、本論文のしくみで可能なことが明示されている。
図の左側では左側のinput画像1枚からその右側、shapeやそれにtextureを貼った3Dモデルが構築できている。さらにその右(Novel view)は、この3Dモデルを回転させたもの。

図の右側では推定した3Dモデルを変化させることにより可能となる応用例を表している。
一番上の例では、Input画像の馬に対し、その右、3D Assetと書かれた3D model が作成される。それに光源を変化させたものが右のRelitである。さらに、本3D model はposeも持っているので、その右のようなAnimatedのようにposeを変化させることが可能となる。
した2つの例は、Stable Diffusionに対して特定のpromptを与えて画像を生成し、その生成画像に対して3D modelを推定している。
モデル
全体像
以下がモデルの全体構造。
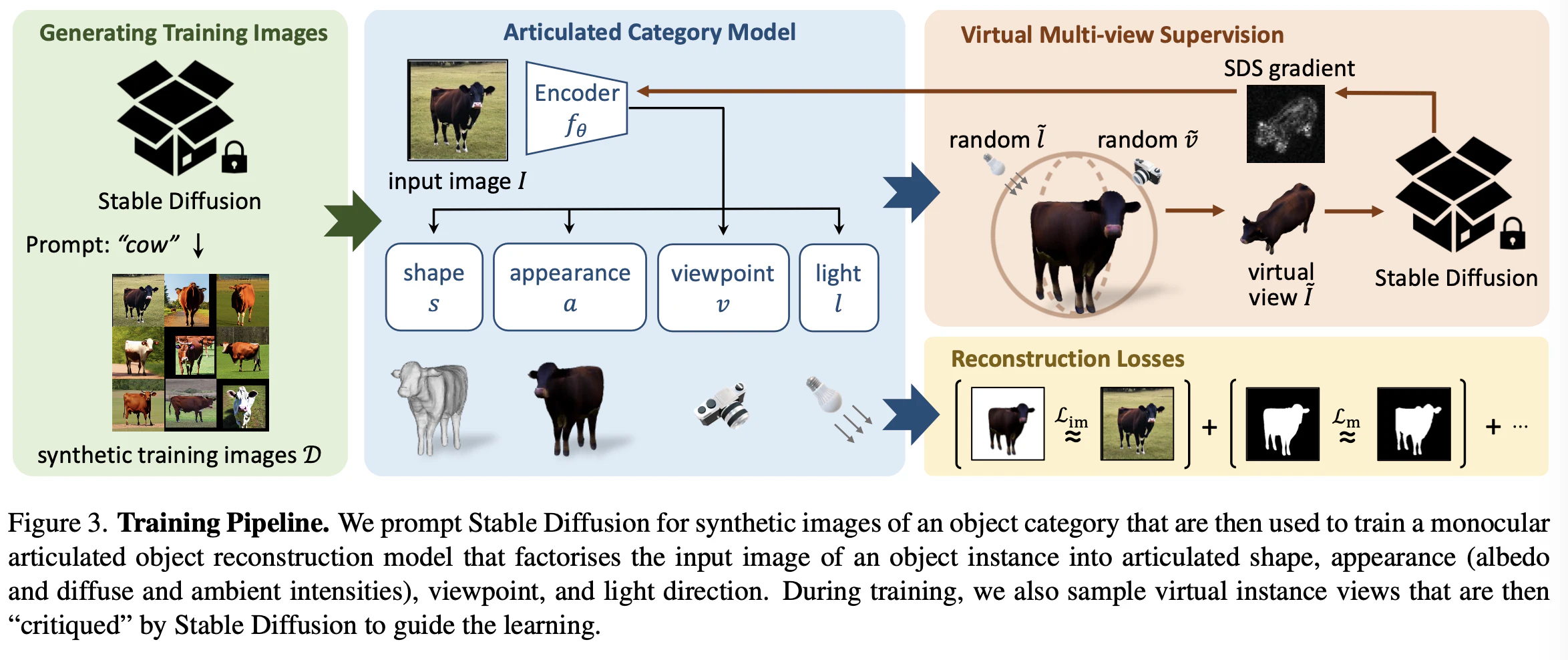
Generating Trainng Images
まず左の緑部分。
Stable Diffusionでtraining dataを生成させる。牛のカテゴリーなら、"cow"などのpromptを与える。"cow, walking away from the camera" などのpromptにすると、異なった向きの動物が得られる。
このStable Diffusion自体をカテゴリーで再学習させるか否かは明言されてないが、モデルの横に鍵マークがついてるので学習させないという意味か?
以下は生成したデータの例。

Articulated Category Model
次に真ん中の青い部分。
生成した入力画像をencoder $f_{\theta}$ に入れて、shape, appearance, viewpoint, lightを推定させる
入力画像:$I \in \mathbb{R}^{3 \times H \times W}$ として
(s, a, v, l) = f_\theta (I)
とそれぞれを推定させる。
Virtual Multi-view Supervision
次に右上のこの部分。ここが1番の特色か。
まず、encoderから出力されたviewpointとlightを変えた形でrendeingさせる。
\tilde{I} = R(s,a,\tilde{v}, \tilde{l}) = R \circ {\rm subst}_{\tilde{v}, \tilde{l}} \circ f_\theta (I).
以下の解釈に自信がないので、おかしいと思う方はコメントください。この向きと明かりを変えた3D modelをレンダリングしたものは、noiseを加えるとStable Diffusionで再構築できるはず。なぜなら、もともと同じStable Diffusionで生成されたものを変化させてるだけなので。ただし、その間 encoderを通っているので、encoderが正確に3D形状を復元できなければ、Stable Diffusionは再構築できないだろう。つまり、Stable Diffusionが再構築できるようにencoderを学習させれば、encoderは3D形状を正確に推定できるような学習をするだろう。
\nabla_\theta \mathcal{L}_{\rm SDS} (\theta | \tilde{v}, \tilde{l}, I, y) = \mathbb{E}_{t, \epsilon} \left[ w_t \cdot (\hat{\epsilon_t} (z_t | y) - \epsilon_t) \frac{\partial z_t}{\partial \theta} \right], \tag{2}
ここで
$z_t$:stable diffusionのdiffusion部分の t ステップの latent。
$\epsilon_t$:同 t ステップのノイズ
この(2)式は諸々省略されているが、以下で導かれるか?
\begin{eqnarray}
\nabla_\theta \mathcal{L}_{\rm SDS} (\theta | \tilde{v}, \tilde{l}, I, y) &=& \nabla_\theta \mathbb{E}_{t, \epsilon} \left[ w_t \cdot \| \hat{\epsilon_t} (z_t | y) - \epsilon_t \|^2_2 \right], \tag{2.1}\\
&=& \mathbb{E}_{t, \epsilon} \left[ w_t \cdot \frac{\partial}{\partial \hat{\epsilon_t}} \| \hat{\epsilon_t} (z_t | y) - \epsilon_t \|^2_2 \frac{\partial \hat{\epsilon_t}}{\partial z_t} \frac{\partial z_t}{\partial \theta} \right], \tag{2.2}\\
&=& \mathbb{E}_{t, \epsilon} \left[ w_t \cdot (\hat{\epsilon_t} (z_t | y) - \epsilon_t) \frac{\partial \hat{\epsilon_t}}{\partial z_t} \frac{\partial z_t}{\partial \theta} \right], \tag{2.3}\\
&=& \mathbb{E}_{t, \epsilon} \left[ w_t \cdot (\hat{\epsilon_t} (z_t | y) - \epsilon_t) \frac{\partial z_t}{\partial \theta} \right], \tag{2.4}\\
&=& \mathbb{E}_{t, \epsilon} \left[ w_t \cdot (\hat{\epsilon_t} (z_t | y) - \epsilon_t) \frac{\partial z_t}{\partial \theta} \right], \tag{2}
\end{eqnarray}
(2.2)式から(2.3)式において、2を $w_t$ に入れた。また(2.3)式から(2.4)式において、diffusionのUnetは学習させないので、$\frac{\partial \hat{\epsilon_t}}{\partial z_t}$ は $w_t$ に吸収。
Reconstruction losses
最後は右下のlossの部分。
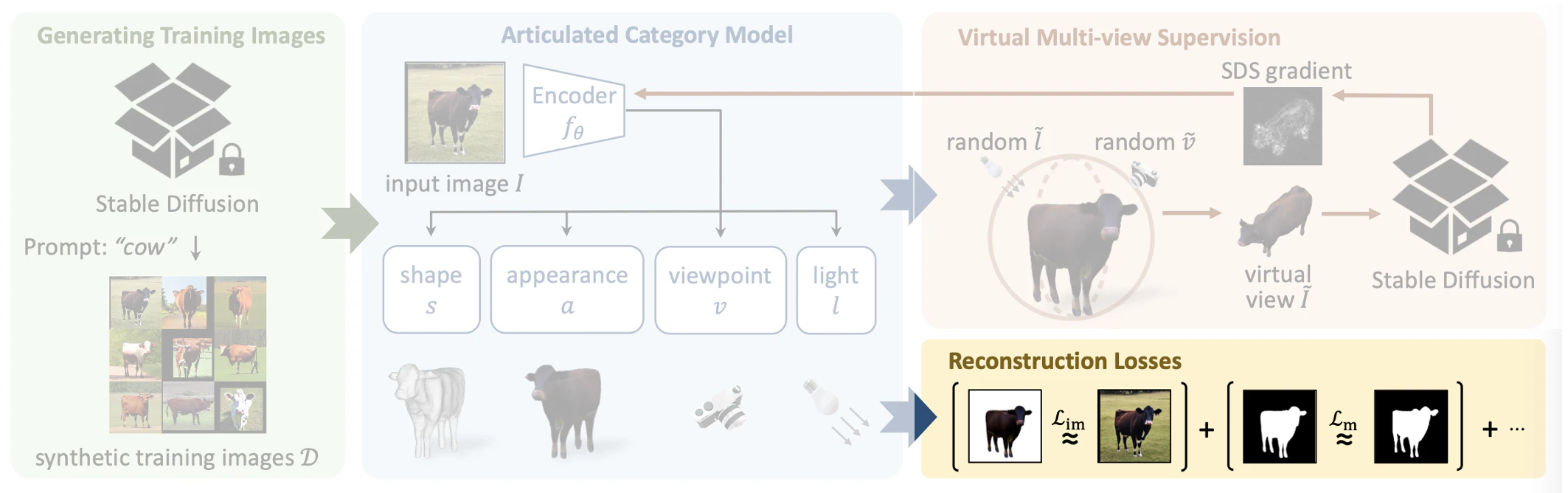
左側はinput imageと再構築したimageとをmask(PointRendというモデルで作成するらしい)に通したものをVit-DINOというモデルで特徴量をとり、その特徴量でのlossを計算する。
右側ではmask同士でlossをとるのか?
それとは別に(?)、正則化項があり、SDFのEikonal lossを用いる。以下は論文中のlossの式だが、右辺シグマ内の第1項が特徴量ベースとmaskのlossか(?)。第2項が正則化項。
\mathcal{L}(\theta | \mathcal{D}) = \frac{1}{|\mathcal{D}|} \sum_{(I,M) \in \mathcal{D}} \mathcal{L}(f_\theta (I) | I, M) + \mathcal{R}(f_\theta (I)),
定性的評価
3D再構築の結果
以下は動物ごとの推論結果。かなり正確かつリアルな3Dが生成されている。

他のモデルとの比較
以下はMagicPonyモデルとの比較。

MagicPony*はrealなimageを学習データに混ぜたもの。realなimageにはocculusionや体が切れているものが多いため、結果がnoisyになるとの見解。本論文のしくみではSDからの合成画像しかつかわないが、このようなocculusionや体が切れる画像はほとんど生成されないらしい。
定量的評価
2種類の定量的評価を用いている。
- keypoint transfer・・・Pascal datasetのようなkeypointがついてる画像を入力し、正解との差を求める
- Chamfer distance・・・3D articulated animal datasetを用いて、3D shapeの正確さを求める
結果は以下。下2行が本論文の手法であり、一番下はSDS lossを除いたもの。
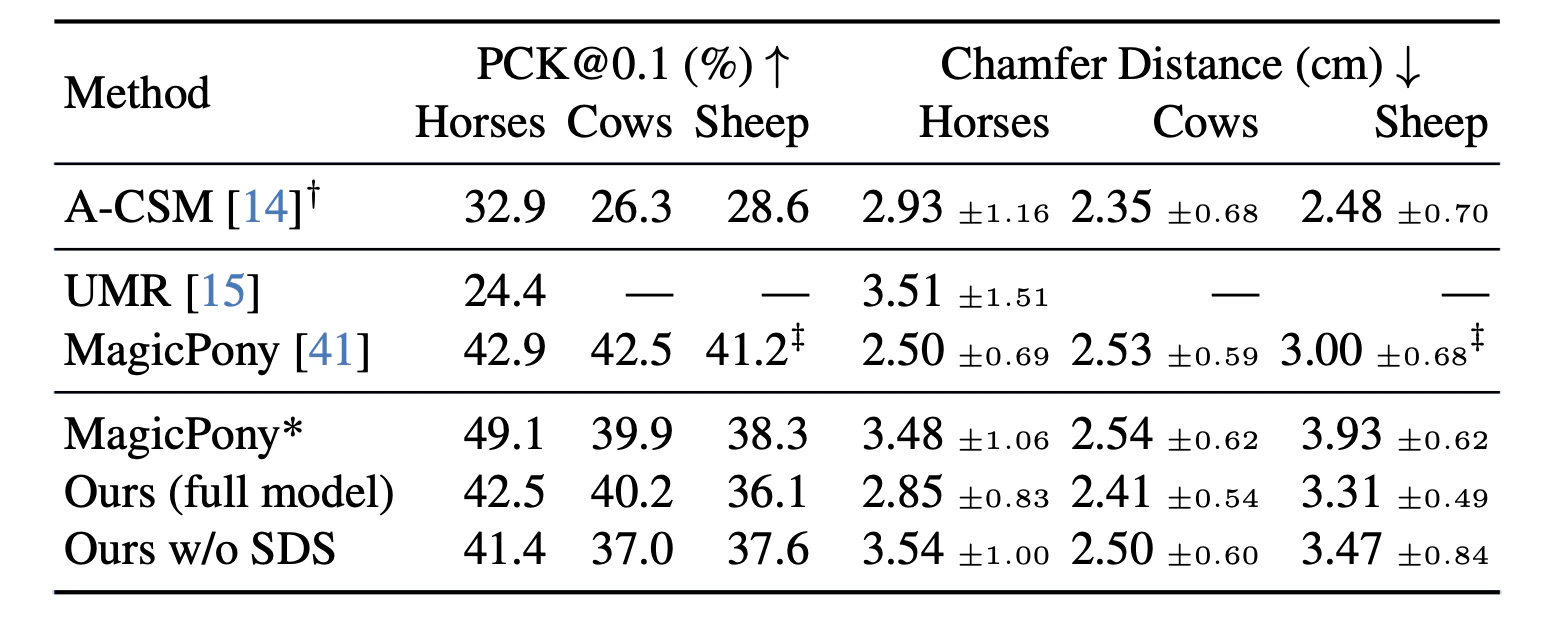
他のSOTAモデルと比肩し得る、という感じか。
この定量的評価のみを見ればSDS lossの効果は微妙〜。