はじめに
Deep Mindらが2024年にarXivに載せた以下の論文
[1] R. Gao, et. al. CAT3D: Create Anything in 3D with Multi-View Diffusion Models.
のまとめ
提出先は不明。
project page
arXiv
既に半年以上経っているので、以下のようなまとめ資料が存在
よって以下を中心にまとめる
- これまでの(CAT3D以前の)Diffusion系3D生成モデルの欠点
- 結局本手法はどのようなものか
1)これまでのDiffusion系3D生成モデルの分類とその欠点
1−1)SDS(score distillation sampling)を用いた手法
最初期のDiffusionモデルを用いる3Dモデル生成である
- DreamFusion
- DreamTime
などは学習済みdiffusionを用いてSDS(score distillation sampling)手法でNeRF等の空間を最適化させる。この手法は以下の欠点がある。
- SDSを用いる手法は推論時にNeRFを最適化させるので計算コストが高い
- text-to-imageの学習済みDiffusionモデルを用いるので、そのモデルが学習した時と異なるデータ分布の3Dは生成しにくい
1−2)Diffusionを再学習させて特定のcamera poseの画像を出力させる手法
- zero 1-to-3
- SV3D
などではtext-to-imageモデルを再学習させて特定のcamera poseに対して画像を1枚生成させる。この手法は以下の欠点がある。
- target の camera poseに基づいた単一の画像を生成するため、これを複数回繰り返した得た画像群は3Dの一貫性に欠ける
- 一方でこの一貫性を克服するために推論時でNeRFを用いた場合、計算コストがかかる
1−3)多視点からの画像を同時生成する手法
- zero123++
- ImageDream
など、text-to-imageモデルを再学習させて多視点の画像を同時に生成する。ImageDreamは3D-self attentionを使っているという点で本手法と似ている。しかし以下の欠点がある。
- 多視点画像生成と3D再構築のプロセスを同時に行なっているため精度が低い
1−4)video diffusionモデルを用いた3D生成モデル手法
- animate-Diff
- SV3D
などではvideo diffusionモデルを用いて3Dを生成する。これらの手法は以下の欠点がある。
- 定まったカメラ起動における画像を生成するので、3Dを生成する多様なシーンの画像を生成できない
1−5)一瞬で多視点画像を生成する手法
- LRM
- 3DGen
などの手法では数秒で新視点の画像を生成できる。しかし
- 往々にして精度が低い
2)結局本手法はどのようなものか
本手法はこれまでの手法の組み合わせである。具体的には速度と精度のバランスを保ちつつ、様々なテクニックを取り入れて改善したものである。
2−1)全体像
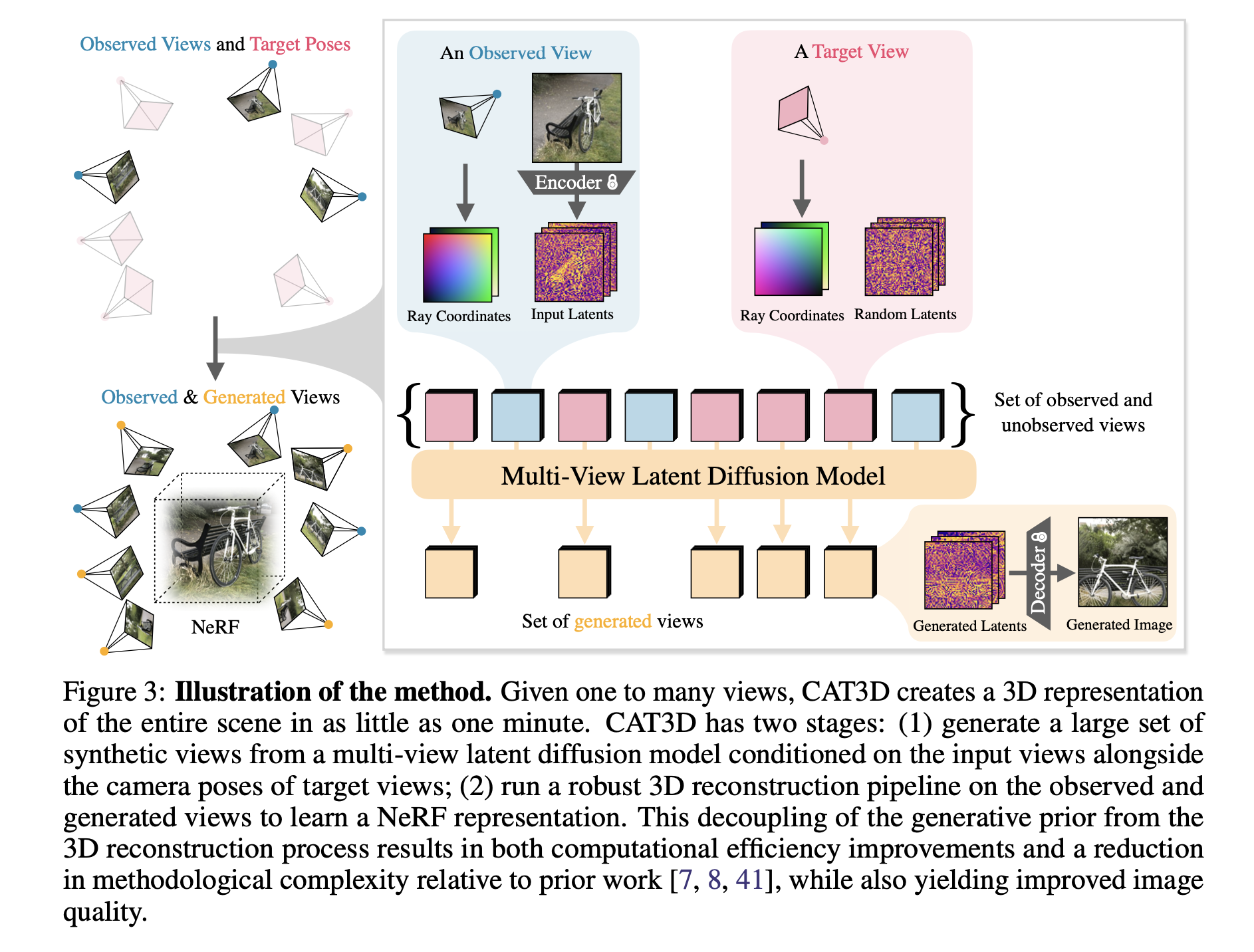
まず、学習フェーズと推論フェーズにわけると、
2−1−1)学習フェーズ
Diffusionモデルを再学習
2−1−2)推論フェーズ
上図の左側のように大きく分けて2ステップ。
- 再学習したDiffusionモデルを用いて多視点画像を生成
- 多視点画像を用いてNeRF空間を「高速に」最適化
2−2)Diffusionモデルの再学習
- stable diffusionのようなLDM(latent diffusion model)系アーキテクチャを用いる
- 2D画像で学習済みのDiffusionモデルを3D attentionに修正して再学習させる
- 入力画像と対応するカメラポーズを、レイマップ (raymap) としてエンコード
- Flash Attentionで学習を高速化(ここよくわからん)
- カメラの軌道は様々なものを用いるが、不自然な角度や物体を通過するものは避ける
- 初めにアンカーとなるビューを生成し、それを元に他のビューも生成することで全体の一貫性を維持する
2−3)NeRFを用いた最適化
全体の一貫性を保つために、生成した多視点画像からNeRF空間上で3Dモデルを粗く学習させる。
NeRFの最適化は通常多くの時間がかかるが、本手法ではZip-NeRFのように簡略化された手法を用いることで最適化の時間を削減する。この過程は数分で終わるらしい。
3)結果
以下、定性的評価の一例。

上段 input画像に対して、CAT3Dで生成した別角度画像が中央段、他のモデルによる同じ視点の生成画像が下段。
例えば右のワッフルの例では、DreamCraft3Dはヤヌス問題的なdistortionが発生しているが、CAT3Dでは一貫性が保たれている。