はじめに
以下の論文
[1] Y. Zhang, et. al."A Simple Baseline for Multi-Object Tracking"
のまとめ
Journal等は不明。モデルの略称:FairMOT。
Multi-object trackingの分野ではいい結果を出してる。
https://paperswithcode.com/task/multi-object-tracking
-
githubの公式コード:
https://github.com/ifzhang/FairMOT
MIT license。
既にざっくりしたまとめ記事が存在する。
https://qiita.com/takoroy/items/db1247727805af1ee92a
ので、ここではモデルのアーキテクチャやロス等のロジックの詳細に焦点をあてる。
ネットワークのアーキテクチャ
1. 全体像
アーキテクチャの全体像は、こんな感じで
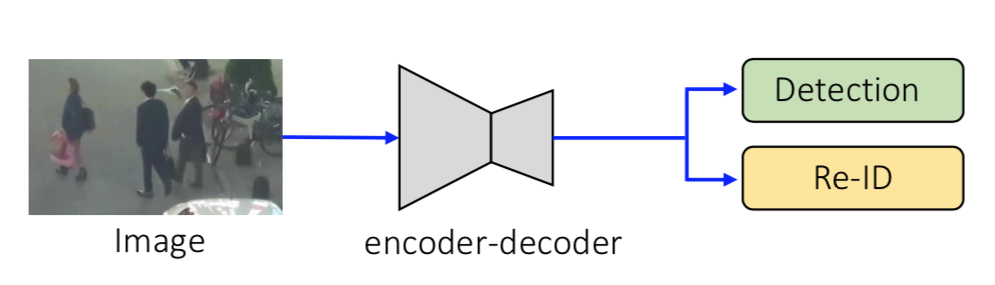
encodeしてdecodeする感じ。decoder部分が若干小さいことからわかるように、出力される画像の解像度は元の Image の 1/4。
また 1-shot 系(Detectionとその領域における特徴量をニューラルネットから同時に出力する)なので、右の出力は Detection と Re-ID。
2. Encoder-Decoderの詳細
encoder-decoderネットワークの詳細は以下。
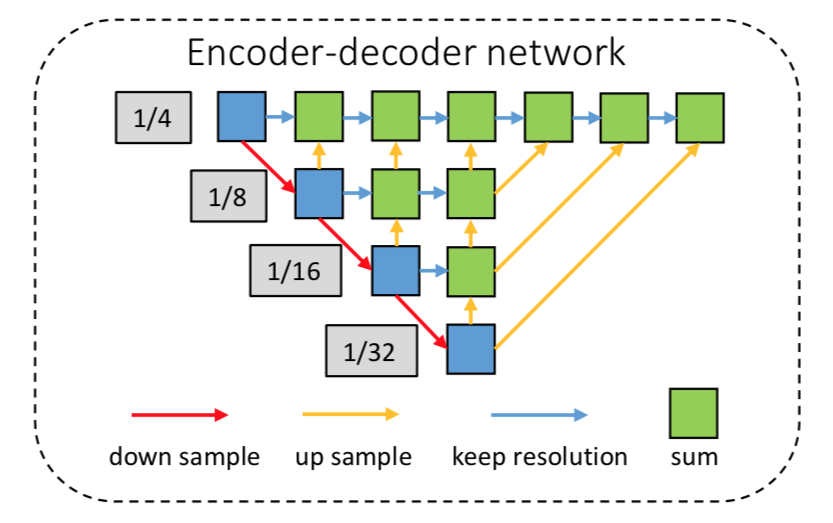
まず、backbornはresnet-34。全体構造としてはCenterNet[2]のDLA-34。
図中のUNet構造における青いブロックを赤い矢印に沿ってたどっていくと、down sampling しながら畳み込まれている。
これに対して青い矢印は同じ解像度での畳み込み経路。
黄色はupsamplingの経路だが、ここではdeformable comvolutionを使っているのだそう。CenterNetを踏襲しているということなので、deformable conv -> deconvolution の順と思われる。
(参考)CenterNetのアーキテクチャ
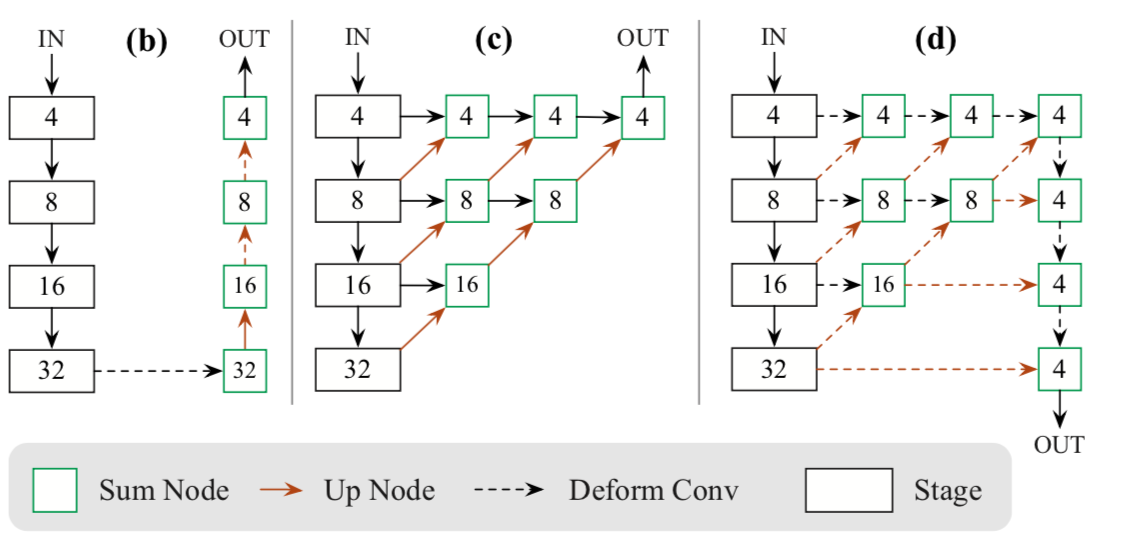
[2]Figure6より
(d)がDLA-34。表現の仕方が違うものの、よくよく見比べると構造は同じ。
さらに、Uの中身が密に詰まったU-Net++と比べた場合、U内の右半分が無く、short-cutも無く簡素な形。
(参考)U-Net++のアーキテクチャ
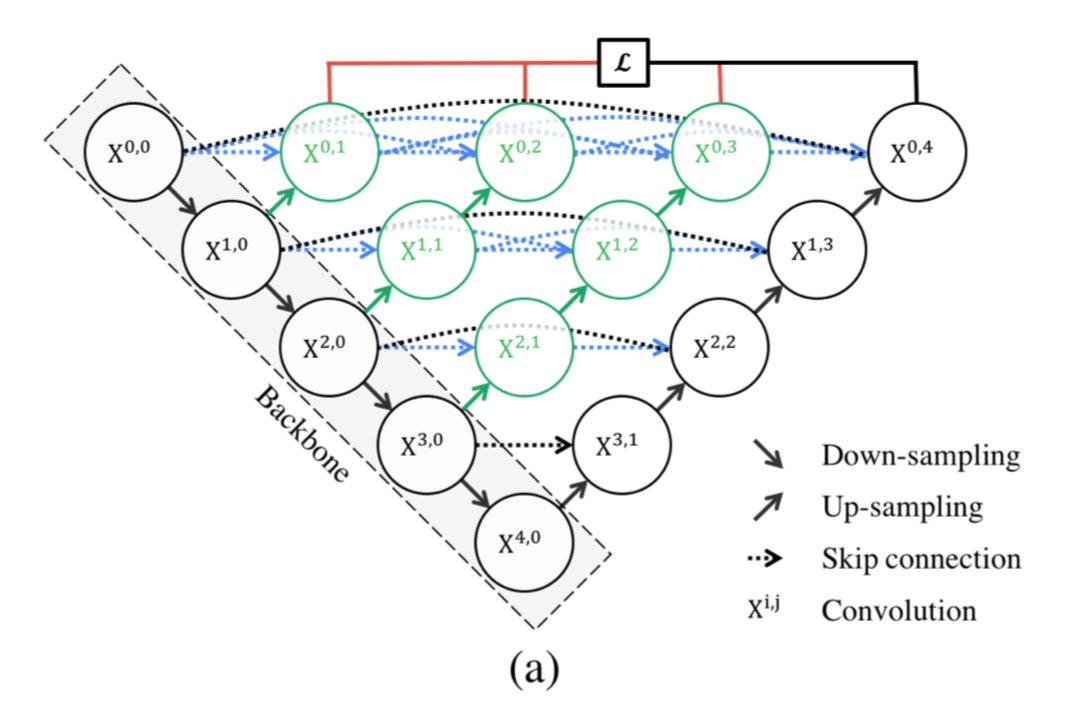
[3] Figure1より
3.出力のDetection Branch
2つあるBranchのうちのDetection BranchもCenterNetを踏襲してこんな感じ。
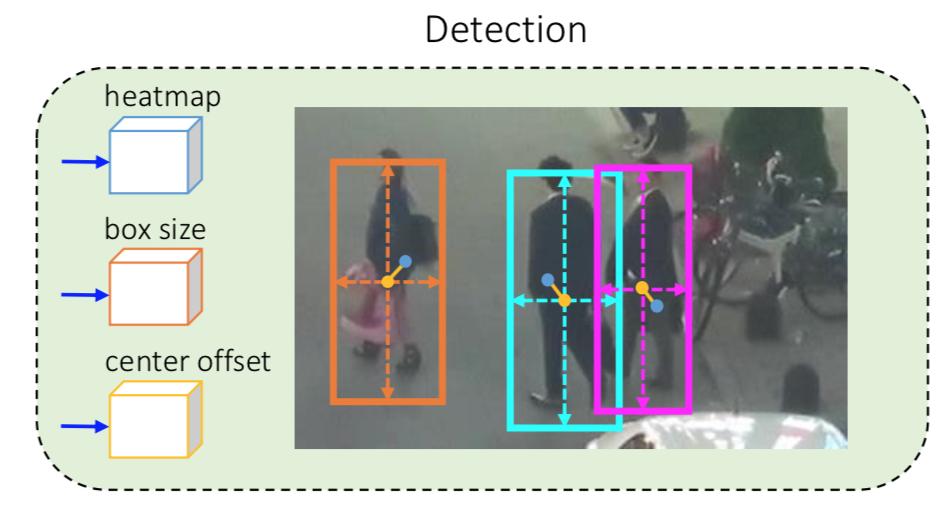
細かくは3種類の出力、1)boxの中心を表すheatmap、2)boxのサイズを表す値、3)中心位置のoffsetを表す値、からなる。
3.1 boxの中心を表すheatmap
骨格推定のごとくheatmapで物体の中心位置を推定する。
入力画像のbounding boxを ${\bf{b}}^i = (x_1^i, y_1^i,x_2^i, y_2^i)$ として、入力画像における物体の中心は
\begin{eqnarray*}
c^i_x &=& \frac{x^i_1 + x_2^i}{2} \\
c^i_y &=& \frac{y^i_1 + y_2^i}{2} \\
\end{eqnarray*}
であり、1/4に縮小された出力における位置は
(\tilde{c}_x^i, \tilde{c}_y^i) = (\lfloor \frac{c^i_x}{4} \rfloor , \lfloor \frac{c^i_y}{4} \rfloor)
である。これからガウシアンを用いてheatmap($M_{xy}$)を作成する。
M_{xy} = \Sigma_{i=1}^N \exp^{-\frac{(x-\tilde{c}_x^i)^2 + (y-\tilde{c}_y^i)^2}{2 \sigma_c^2}}
Nは物体の数。
3.2 boxのサイズを表す値
trackingには使わないが、object detectionの評価に用いる。
アノテーションの bounding box情報 ${\bf{b}}^i = (x_1^i, y_1^i,x_2^i, y_2^i)$ から幅と高さを計算してtargetとする。
{\bf{s}}^i = (x^i_2 - x^i_1, y_2^i - y_1^i)
3.3 boxの中心に対するオフセットを表す値
heatmapだけでもそこそこの精度で中心位置が推定できるが、いかんせん出力が元画像の1/4に縮小されてるので、元画像のサイズでいうと数ピクセルずれる。本手法のしくみだと中心位置の特徴量を抜いてくるので、ここがズレると隣の人の特徴量となってしまう可能性がある。よってより正確に中心位置を推定するため、このチャンネルでオフセットを推定する。
このオフセットは縮小分のズレを補正するためのもので、super pixel的なオフセットではなさそう。
出力画像におけるオフセットは
{\bf{o}}^i = (\frac{c^i_x}{4}, \frac{c^i_y}{4}) - (\lfloor \frac{c^i_x}{4} \rfloor , \lfloor \frac{c^i_y}{4} \rfloor)
4. 出力のRe-ID branch
マッチングに使う特徴量を出力する。
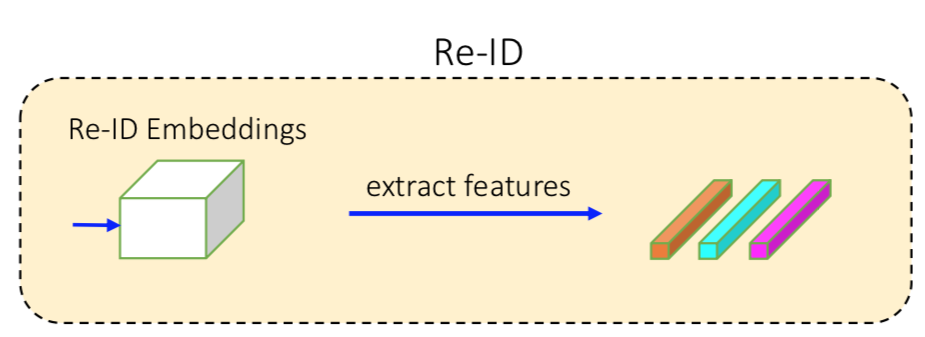
Detection Branchで求めた中心座標 $(\tilde{c}_x^i, \tilde{c}_y^i)$ の位置の特徴量( ${\bf{E}}_{x^i,y^i}$ )を抜く。
なので、こんな感じか。
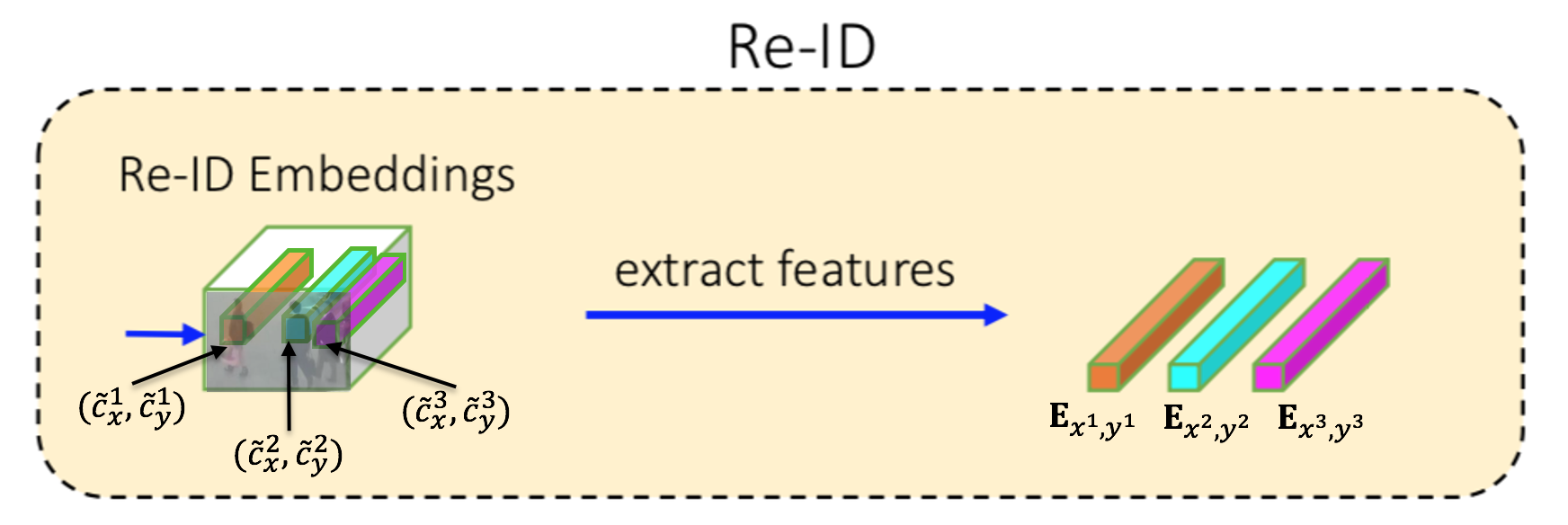
注意点としては、$\bf E$ は物体のインスタンス総数(つまり物体のIDの総数)だけ次元があるone-hotベクトルであること。例えば、ある人はvideo中常に $(0,0,0,1,0,0,0,....,0)$ であり、またある人は $(0,0,0,0,...,0,1,0)$ である。
Loss
上記4種類の出力それぞれに応じてLossがある
heatmapのLoss
focal lossを用いる。heatmapの推定値を $\hat{M}$ として
L_{heatmap} = -\frac{1}{N} \sum_{xy}
\begin{cases}
(1- \hat{M}_{xy})^\alpha \log(\hat{M}_{xy}), & if \ M_{xy} = 1; \\
(1- \hat{M}_{xy})^\beta (\hat{M}_{xy})^\alpha \log(1- \hat{M}_{xy}) & otherwise,
\end{cases}
boxサイズのlossとオフセットのloss
boxサイズの推論値を $\hat{s}^i$ 、オフセットの推論値を $\hat{o}^i$ として、targetとL1をとる。
L_{box} = \sum^N_{i=1} \| {\bf o}^i - \hat{\bf o}^i \|_1 + \| {\bf s}^i - \hat{\bf s}^i \|_1
Re-IDのloss
出力がone-hotベクトルなので、ソフトマックスで計算する。
L_{identity} = - \sum^N_{i=1} \sum^K_{k=1} {\bf L}^i (k) \log ({\bf p}(k))
その他気になる点
1 trackingのアルゴリズム
本論文では通常のKalman Filterを用いている。
また物体が急激に動く場合を想定して、fram間で対応する物体が遠い場合にはcorresponding costを無限に設定する -> ここよくわからん。第1段階ではkalman filterで予測した位置や特徴量を使い、それでマッチングしないものに対して第2段階で特徴量だけ使うって意味??
Reference
[2] X. Zhou, et. al."Objects as Points"
[3] Z. Zhou, et. al."UNet++: A Nested U-Net Architecture for Medical Image Segmentation"